Auf dieser Seite wird beschrieben, wie Sie in Cloud Data Fusion Transformationen in BigQuery statt in Spark ausführen.
Weitere Informationen finden Sie in der Übersicht über den Transformations-Push-down.
Hinweis
Transformations-Push-down ist ab Version 6.5.0 verfügbar. Wenn Ihre Pipeline in einer früheren Umgebung ausgeführt wird, können Sie ein Upgrade Ihrer Instanz auf die neueste Version durchführen.
Transformations-Push-down in Ihrer Pipeline aktivieren
Console
So aktivieren Sie Transformations-Push-down für eine bereitgestellte Pipeline:
Rufen Sie Ihre Instanz auf:
Rufen Sie in der Google Cloud Console die Seite „Cloud Data Fusion“ auf.
Wenn Sie die Instanz in Cloud Data Fusion Studio öffnen möchten, klicken Sie auf Instanzen und dann auf Instanz anzeigen.
Klicken Sie auf Menü > Liste.
Der Tab „Bereitgestellte Pipeline“ wird geöffnet.
Klicken Sie auf die gewünschte bereitgestellte Pipeline, um sie in Pipeline Studio zu öffnen.
Klicken Sie auf Konfigurieren > Transformations-Push-down.
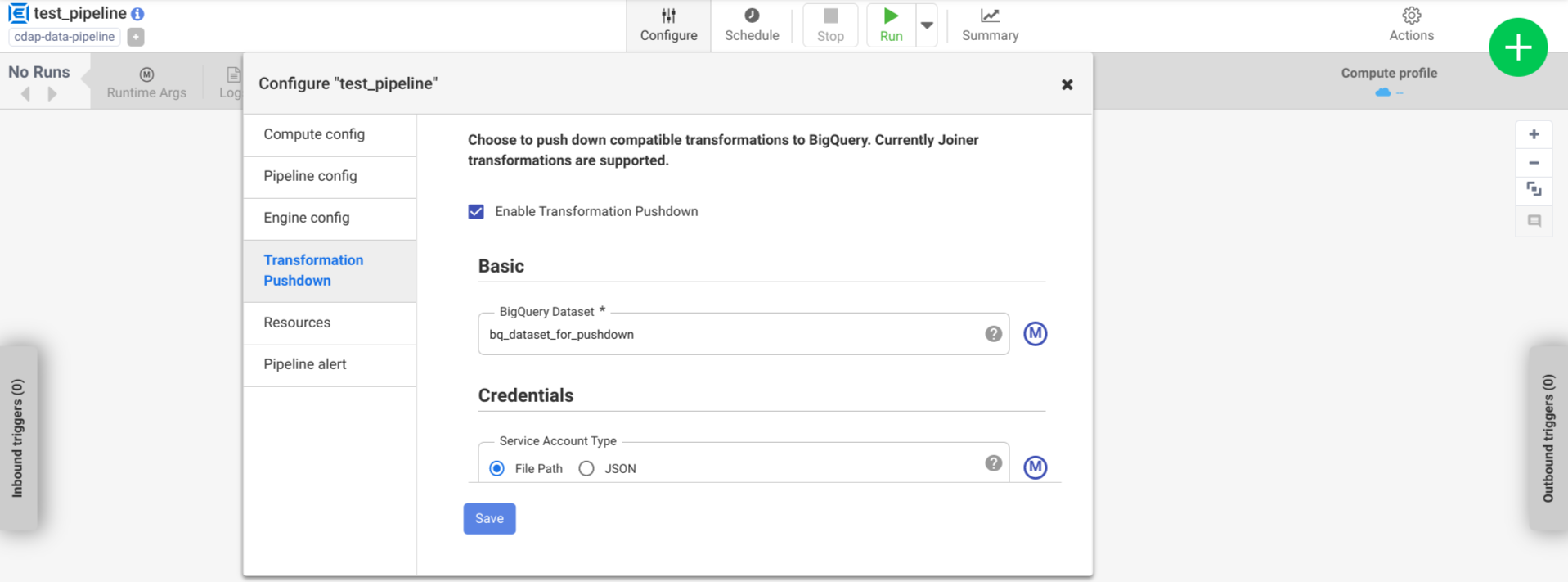
Klicken Sie auf Transformations-Push-down aktivieren.
Geben Sie im Feld Dataset den Namen eines BigQuery-Datasets ein.
Optional: Wenn Sie ein Makro verwenden möchten, klicken Sie auf die Taste M. Weitere Informationen finden Sie unter Datasets.
Optional: Konfigurieren Sie bei Bedarf die Optionen.
Klicken Sie auf Speichern.
Optionale Konfigurationen
.| Attribut | Unterstützt Makros | Unterstützte Cloud Data Fusion-Versionen | Beschreibung |
|---|---|---|---|
| Verbindung verwenden | Nein | 6.7.0 und höher | Ob eine vorhandene Verbindung verwendet werden soll. |
| Verbindung | Ja | 6.7.0 und höher | Der Name der Verbindung. Diese Verbindung enthält Informationen zum Projekt und zum Dienstkonto. Optional: Verwenden Sie die Makrofunktion ${conn(connection_name)}. |
| Dataset-Projekt-ID | Ja | 6.5.0 | Wenn sich das Dataset in einem anderen Projekt als dem befindet, in dem der BigQuery-Job ausgeführt wird, geben Sie die Projekt-ID des Datasets ein. Wenn kein Wert angegeben ist, wird standardmäßig die Projekt-ID verwendet, in der der Job ausgeführt wird. |
| Projekt-ID | Ja | 6.5.0 | Die Google Cloud Projekt-ID. |
| Dienstkontotyp | Ja | 6.5.0 | Wählen Sie eine der folgenden Optionen aus:
|
| Dateipfad des Dienstkontos | Ja | 6.5.0 | Der Pfad im lokalen Dateisystem zum Dienstkontoschlüssel, der für die Autorisierung verwendet wird. Wenn die Ausführung in einem Dataproc-Cluster erfolgt, ist es auf auto-detect festgelegt. Bei der Ausführung in anderen Clustern muss die Datei auf jedem Knoten im Cluster vorhanden sein. Der Standardwert ist auto-detect. |
| JSON-Dienstkonto | Ja | 6.5.0 | Der Inhalt der JSON-Datei des Dienstkontos. |
| Name des temporären Buckets | Ja | 6.5.0 | Der Cloud Storage-Bucket, in dem die temporären Daten gespeichert werden. Es wird automatisch erstellt, wenn es nicht vorhanden ist, aber nicht automatisch gelöscht. Die Cloud Storage-Daten werden gelöscht, nachdem sie in BigQuery geladen wurden. Wenn dieser Wert nicht angegeben wird, wird ein eindeutiger Bucket erstellt und nach Abschluss der Pipelineausführung gelöscht. Das Dienstkonto muss die Berechtigung zum Erstellen von Buckets im konfigurierten Projekt haben. |
| Standort | Ja | 6.5.0 | Der Speicherort, an dem das BigQuery-Dataset erstellt wird.
Dieser Wert wird ignoriert, wenn das Dataset oder der temporäre Bucket bereits vorhanden ist. Standardmäßig ist der multiregionale Standort US festgelegt. |
| Name des Verschlüsselungsschlüssels | Ja | 6.5.1/0.18.1 | Der vom Kunden verwaltete Verschlüsselungsschlüssel (Customer-Managed Encryption Key, CMEK), mit dem Daten verschlüsselt werden, die in einen vom Plug-in erstellten Bucket, Dataset oder eine vom Plug-in erstellte Tabelle geschrieben werden. Wenn der Bucket, das Dataset oder die Tabelle bereits vorhanden ist, wird dieser Wert ignoriert. |
| BigQuery-Tabellen nach Abschluss speichern | Ja | 6.5.0 | Gibt an, ob alle temporären BigQuery-Tabellen, die während der Pipelineausführung erstellt werden, zu Debug- und Validierungszwecken beibehalten werden sollen. Der Standardwert ist Nein. |
| TTL für temporäre Tabellen (in Stunden) | Ja | 6.5.0 | Legen Sie die Tabellen-TTL für temporäre BigQuery-Tabellen in der Anzahl der Stunden fest. Dies ist nützlich als Sicherheitsmaßnahme, falls die Pipeline abgebrochen und der Bereinigungsprozess unterbrochen wird (z. B. wenn der Ausführungscluster abrupt heruntergefahren wird). Wenn Sie diesen Wert auf 0 setzen, wird die Tabellen-TTL deaktiviert. Der Standardwert ist 72 (3 Tage). |
| Priorität des Jobs | Ja | 6.5.0 | Die Priorität, mit der BigQuery-Jobs ausgeführt werden. Wählen Sie eine der folgenden Optionen aus:
|
| Phasen für erzwungenes Pushdown | Ja | 6.7.0 | Unterstützte Phasen, die immer in BigQuery ausgeführt werden. Jeder Stufenname muss in einer separaten Zeile stehen. |
| Phasen, bei denen das Pushdown übersprungen werden soll | Ja | 6.7.0 | Unterstützte Phasen, die niemals in BigQuery ausgeführt werden. Jeder Stufenname muss in einer separaten Zeile stehen. |
| BigQuery Storage Read API verwenden | Ja | 6.7.0 | Gibt an, ob die BigQuery Storage Read API beim Extrahieren von Einträgen aus BigQuery während der Pipelineausführung verwendet werden soll. Mit dieser Option lässt sich die Leistung der Transformations-Pushdown-Funktion verbessern, es entstehen jedoch zusätzliche Kosten. Dazu muss Scala 2.12 in der Ausführungsumgebung installiert sein. |
Leistungsänderungen in den Logs überwachen
Die Laufzeitlogs der Pipeline enthalten Nachrichten, in denen die in BigQuery ausgeführten SQL-Abfragen angezeigt werden. Sie können kontrollieren, welche Phasen in der Pipeline per Push an BigQuery übertragen werden.
Das folgende Beispiel zeigt die Logeinträge, wenn die Pipelineausführung beginnt. Die Logs geben an, dass die JOIN-Vorgänge in Ihrer Pipeline zur Ausführung in BigQuery übertragen wurden:
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'Users' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'Users'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'UserPurchases' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'Purchases'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'UserPurchases'
INFO [Driver:i.c.p.g.b.s.BigQuerySQLEngine@190] - Validating join for stage 'MostPopularNames' can be executed on BigQuery: true
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@131] - Starting push for dataset 'FirstNameCounts'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@292] - Starting join for dataset 'MostPopularNames'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@193] - Starting pull for dataset 'MostPopularNames'
Das folgende Beispiel zeigt die Tabellennamen, die für jedes der Datasets zugewiesen werden, die an der Push-Ausführung beteiligt sind:
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset Purchases stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserDetails stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset FirstNameCounts stored in table <TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@145] - Executing Push operation for dataset UserProfile stored in table <TABLE_ID>
Während die Ausführung fortgesetzt wird, zeigen die Logs den Abschluss der Push-Phasen und schließlich die Ausführung der JOIN-Vorgänge an. Beispiel:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserProfile'
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@133] - Completed push for dataset 'UserDetails'
DEBUG [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@235] - Executing join operation for dataset Users
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@118] - Creating table `<TABLE_ID>` using job: <JOB_ID> with SQL statement: SELECT `UserDetails`.id AS `id` , `UserDetails`.first_name AS `first_name` , `UserDetails`.last_name AS `last_name` , `UserDetails`.email AS `email` , `UserProfile`.phone AS `phone` , `UserProfile`.profession AS `profession` , `UserProfile`.age AS `age` , `UserProfile`.address AS `address` , `UserProfile`.score AS `score` FROM `your_project.your_dataset.<DATASET_ID>` AS `UserProfile` LEFT JOIN `your_project.your_dataset.<DATASET_ID>` AS `UserDetails` ON `UserProfile`.id = `UserDetails`.id
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQueryJoinDataset@151] - Created BigQuery table `<TABLE_ID>
INFO [batch-sql-engine-adapter:i.c.p.g.b.s.BigQuerySQLEngine@245] - Executed join operation for dataset Users
Wenn alle Phasen abgeschlossen sind, wird eine Meldung angezeigt, dass der Pull-Vorgang abgeschlossen wurde. Dies gibt an, dass der BigQuery-Exportprozess ausgelöst wurde und die Datensätze nach Beginn dieses Exportjobs in die Pipeline gelesen werden. Beispiel:
DEBUG [batch-sql-engine-adapter:i.c.c.e.s.b.BatchSQLEngineAdapter@196] - Completed pull for dataset 'MostPopularNames'
Wenn bei der Pipelineausführung Fehler auftreten, werden diese in den Logs beschrieben.
Details zur Ausführung der BigQuery-JOIN-Vorgänge, z. B. Ressourcennutzung, Ausführungszeit und Fehlerursachen, finden Sie in den BigQuery-Jobdaten. Verwenden Sie dazu die Job-ID, die in den Jobprotokollen angezeigt wird.
Pipelinemesswerte überprüfen
Weitere Informationen zu den Messwerten, die Cloud Data Fusion für den Teil der Pipeline bereitstellt, der in BigQuery ausgeführt wird, finden Sie unter BigQuery-Pushdown-Pipeline-Messwerte.
Nächste Schritte
- Transformations-Push-down in Cloud Data Fusion