Um die Leistung Ihrer Datenpipelines zu verbessern, können Sie einige Transformationsvorgänge an BigQuery anstelle von Apache Spark übergeben. Der Transformations-Push-down bezieht sich auf eine Einstellung, mit der ein Vorgang in einer Cloud Data Fusion-Datenpipeline an BigQuery als Ausführungs-Engine übertragen werden kann. Der Vorgang und die zugehörigen Daten werden dann in BigQuery übertragen und dort ausgeführt.
Durch die Pushdown-Transformation wird die Leistung von Pipelines mit mehreren komplexen JOIN-Vorgängen oder anderen unterstützten Transformationen verbessert. Die Ausführung einiger Transformationen in BigQuery ist möglicherweise schneller als in Spark.
Nicht unterstützte Transformationen und alle Vorschautransformationen werden in Spark ausgeführt.
Unterstützte Transformationen
Transformations-Push-down ist in Cloud Data Fusion Version 6.5.0 und höher verfügbar. Einige der folgenden Transformationen werden jedoch erst in höheren Versionen unterstützt.
JOIN Vorgänge
Transformations-Push-down ist für
JOIN-Vorgänge in Cloud Data Fusion Version 6.5.0 und höher verfügbar.Es werden grundlegende (On-Tasten) und erweiterte
JOIN-Vorgänge unterstützt.Joins müssen genau zwei Eingabephasen haben, damit die Ausführung in BigQuery erfolgen kann.
Joins, die so konfiguriert sind, dass eine oder mehrere Eingaben in den Speicher geladen werden, werden in Spark statt in BigQuery ausgeführt, mit folgenden Ausnahmen:
- Wenn eine der Eingaben für die Zusammenführung bereits nach unten geschoben wurde.
- Wenn Sie die Ausführung des Joins in der SQL-Engine konfiguriert haben (siehe Option Phasen zur Erzwingung der Ausführung).
BigQuery-Senke
Transformations-Push-down ist für den BigQuery-Sink in Cloud Data Fusion Version 6.7.0 und höher verfügbar.
Wenn der BigQuery-Sink auf eine Phase folgt, die in BigQuery ausgeführt wurde, wird der Vorgang, bei dem Datensätze in BigQuery geschrieben werden, direkt in BigQuery ausgeführt.
Um die Leistung mit diesem Sink zu verbessern, benötigen Sie Folgendes:
- Das Dienstkonto muss die Berechtigung zum Erstellen und Aktualisieren von Tabellen im Dataset haben, das vom BigQuery-Sink verwendet wird.
- Die für die Transformations-Pushdown-Funktion verwendeten Datasets und der BigQuery-Sink müssen sich am selben Speicherort befinden.
- Der Vorgang muss einer der folgenden sein:
Insert(die OptionTruncate Tablewird nicht unterstützt)UpdateUpsert
GROUP BY Aggregationen
Transformations-Push-down ist für GROUP BY-Aggregationen in Cloud Data Fusion Version 6.7.0 und höher verfügbar.
GROUP BY-Aggregationen in BigQuery sind für die folgenden Vorgänge verfügbar:
AvgCollect List(Nullwerte werden aus dem Ausgabearray entfernt)Collect Set(Nullwerte werden aus dem Ausgabearray entfernt)ConcatConcat DistinctCountCount DistinctCount NullsLogical AndLogical OrMaxMinStandard DeviationSumSum of SquaresCorrected Sum of SquaresVarianceShortest StringLongest String
GROUP BY-Aggregationen werden in BigQuery in den folgenden Fällen ausgeführt:
- Es folgt einer Phase, die bereits nach unten geschoben wurde.
- Sie haben die Ausführung in der SQL-Engine konfiguriert (siehe Option Phasen für erzwungene Ausführung).
Aggregationen deduplizieren
Transformations-Push-down ist für die Deduplizierung von Aggregationen in Cloud Data Fusion Version 6.7.0 und höher für die folgenden Vorgänge verfügbar:
- Es wurde kein Filtervorgang angegeben.
ANY(ein nicht nullwertiger Wert für das gewünschte Feld)MIN(Minimalwert für das angegebene Feld)MAX(der Maximalwert für das angegebene Feld)
Die folgenden Vorgänge werden nicht unterstützt:
FIRSTLAST
In den folgenden Fällen werden Deduplizierungsaggregationen in der SQL-Engine ausgeführt:
- Es folgt einer Phase, die bereits nach unten geschoben wurde.
- Sie haben die Ausführung in der SQL-Engine konfiguriert (siehe Option Phasen für erzwungene Ausführung).
BigQuery-Quellen-Pushdown
BigQuery-Quell-Push-down ist in Cloud Data Fusion Version 6.8.0 und höher verfügbar.
Wenn auf eine BigQuery-Quelle eine Phase folgt, die mit BigQuery-Pushdown kompatibel ist, kann die Pipeline alle kompatiblen Phasen in BigQuery ausführen.
Cloud Data Fusion kopiert die Datensätze, die für die Ausführung der Pipeline in BigQuery erforderlich sind.
Wenn Sie BigQuery Source Pushdown verwenden, bleiben die Eigenschaften für die Tabellenpartitionierung und -gruppierung erhalten. So können Sie diese Eigenschaften verwenden, um weitere Vorgänge wie Joins zu optimieren.
Zusätzliche Anforderungen
Für die Verwendung von BigQuery-Quell-Pushdown müssen die folgenden Anforderungen erfüllt sein:
Das für BigQuery Transformation Pushdown konfigurierte Dienstkonto muss Berechtigungen zum Lesen von Tabellen im Dataset der BigQuery-Quelle haben.
Die in der BigQuery-Quelle verwendeten Datasets und das für die Transformations-Pushdown konfigurierte Dataset müssen sich am selben Speicherort befinden.
Fensteraggregationen
Transformations-Push-down ist für Fensteraggregationen in Cloud Data Fusion Version 6.9 und höher verfügbar. Fensteraggregationen in BigQuery werden für die folgenden Vorgänge unterstützt:
RankDense RankPercent RankN tileRow NumberMedianContinuous PercentileLeadLagFirstLastCumulative distributionAccumulate
In den folgenden Fällen werden Fensteraggregationen in BigQuery ausgeführt:
- Es folgt einer Phase, die bereits nach unten geschoben wurde.
- Sie haben sie so konfiguriert, dass sie in der SQL-Engine ausgeführt wird (siehe Option Phasen für erzwungenes Pushdown).
Wrangler-Filter-Pushdown
Wrangler-Filter-Push-down ist in Cloud Data Fusion Version 6.9 und höher verfügbar.
Mit dem Wrangler-Plug-in können Sie Filter, sogenannte Precondition-Vorgänge, an BigQuery übergeben, damit sie dort anstelle von Spark ausgeführt werden.
Filter-Pushdowns werden nur mit dem SQL-Modus für Voraussetzungen unterstützt, der ebenfalls in Version 6.9 veröffentlicht wurde. In diesem Modus akzeptiert das Plug-in einen Bedingungsausdruck in ANSI-Standard-SQL.
Wenn der SQL-Modus für Vorbedingungen verwendet wird, sind Richtlinien und Benutzerdefinierte Richtlinien für das Wrangler-Plug-in deaktiviert, da sie im SQL-Modus nicht mit Vorbedingungen unterstützt werden.
Der SQL-Modus für Vorbedingungen wird für Wrangler-Plug-ins mit mehreren Eingaben nicht unterstützt, wenn die Transformations-Pushdown-Funktion aktiviert ist. Wenn diese Wrangler-Phase mit mehreren Eingaben verwendet wird, wird sie mit SQL-Filterbedingungen in Spark ausgeführt.
In den folgenden Fällen werden Filter in BigQuery ausgeführt:
- Es folgt einer Phase, die bereits nach unten geschoben wurde.
- Sie haben sie so konfiguriert, dass sie in der SQL-Engine ausgeführt wird (siehe Option Phasen für erzwungenes Pushdown).
Messwerte
Weitere Informationen zu den Messwerten, die Cloud Data Fusion für den Teil der Pipeline bereitstellt, der in BigQuery ausgeführt wird, finden Sie unter BigQuery-Pushdown-Pipeline-Messwerte.
Einsatzmöglichkeiten für den Transformations-Push-down
Die Ausführung von Transformationen in BigQuery umfasst Folgendes:
- Es werden Einträge für unterstützte Phasen in Ihrer Pipeline in BigQuery geschrieben.
- Ausführen unterstützter Phasen in BigQuery
- Datensätze werden nach Ausführung der unterstützten Transformationen aus BigQuery gelesen, es sei denn, es folgt ein BigQuery-Sink.
Je nach Größe Ihrer Datasets kann es zu einem erheblichen Netzwerkaufwand kommen, der sich negativ auf die Gesamtausführungszeit der Pipeline auswirken kann, wenn das Transformations-Push-down aktiviert ist.
Aufgrund des Netzwerkoverheads empfehlen wir die Transformations-Pushdown-Funktion in den folgenden Fällen:
- Mehrere unterstützte Vorgänge werden nacheinander ausgeführt (ohne Schritte zwischen den Phasen).
- Die Leistungssteigerung durch die Ausführung der Transformationen in BigQuery im Vergleich zu Spark überwiegt die Latenz der Datenübertragung in BigQuery und möglicherweise auch wieder aus BigQuery heraus.
So funktioniert es
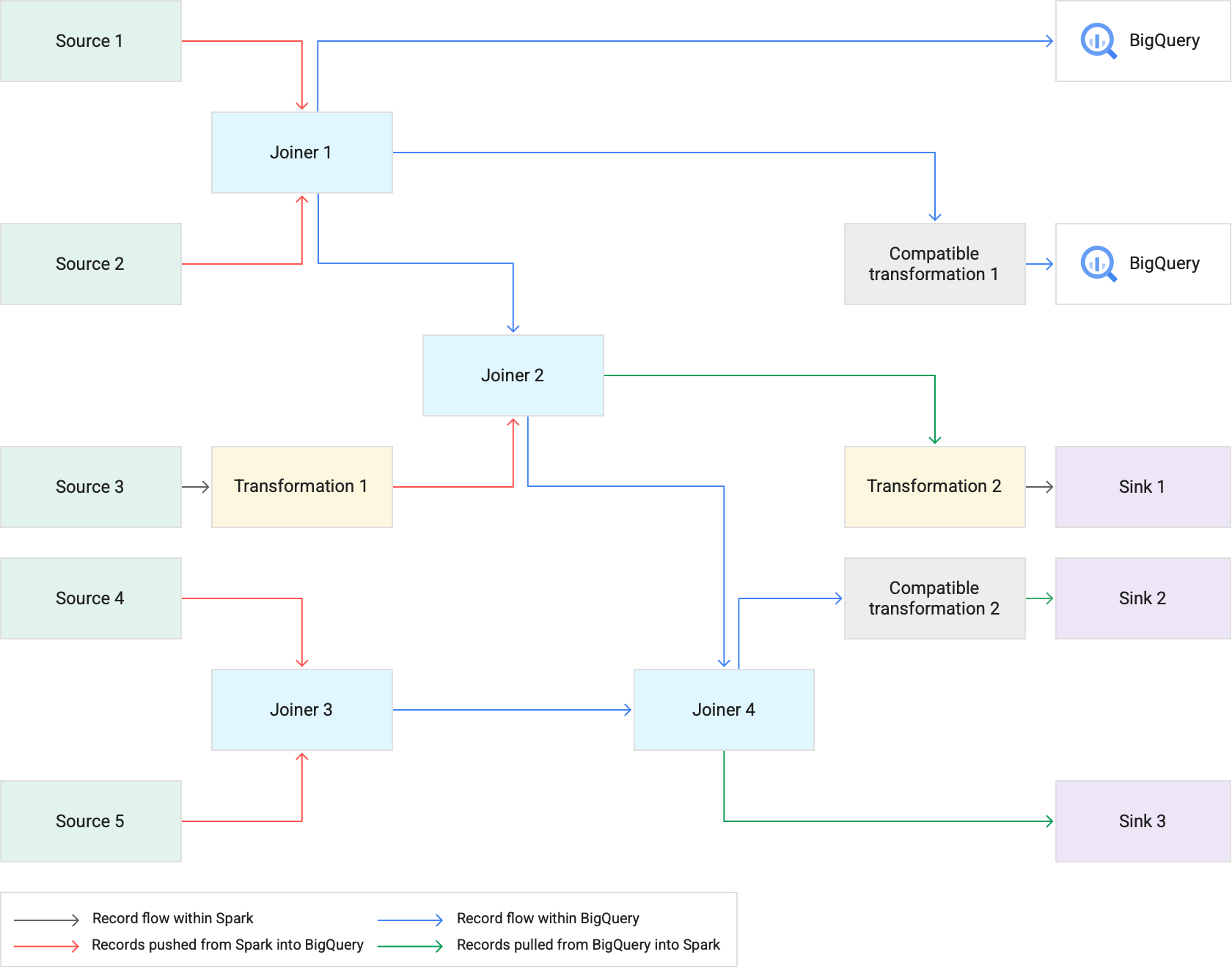
Wenn Sie eine Pipeline mit Transformations-Push-down ausführen, führt Cloud Data Fusion unterstützte Transformationsphasen in BigQuery aus. Alle anderen Phasen der Pipeline werden in Spark ausgeführt.
Beim Ausführen von Transformationen:
Cloud Data Fusion lädt die Eingabe-Datasets in BigQuery. Dazu werden Datensätze in Cloud Storage geschrieben und dann ein BigQuery-Ladejob ausgeführt.
JOIN-Vorgänge und unterstützte Transformationen werden dann als BigQuery-Jobs mithilfe von SQL-Anweisungen ausgeführt.Wenn nach der Ausführung der Jobs eine weitere Verarbeitung erforderlich ist, können Datensätze aus BigQuery nach Spark exportiert werden. Wenn jedoch die Option Direkte Kopie in BigQuery-Senke versuchen aktiviert ist und der BigQuery-Senke eine Phase folgt, die in BigQuery ausgeführt wurde, werden Datensätze direkt in die BigQuery-Senke geschrieben.
Das folgende Diagramm zeigt, wie unterstützte Transformationen mit Transformations-Push-down in BigQuery anstelle von Spark ausgeführt werden.
Best Practices
Cluster- und Executor-Größen anpassen
So optimieren Sie die Ressourcenverwaltung in Ihrer Pipeline:
Verwenden Sie die richtige Anzahl an Cluster-Workern (Knoten) für eine Arbeitslast. Anders gesagt: Sie können den bereitgestellten Dataproc-Cluster optimal nutzen, indem Sie die verfügbare CPU und den verfügbaren Arbeitsspeicher für Ihre Instanz vollständig nutzen und gleichzeitig von der Ausführungsgeschwindigkeit von BigQuery für große Jobs profitieren.
Verbessern Sie die Parallelität in Ihren Pipelines mithilfe von Autoscaling-Clustern.
Passen Sie Ihre Ressourcenkonfigurationen in den Phasen Ihrer Pipeline an, in denen Datensätze während Ihrer Pipelineausführung per Push übertragen oder aus BigQuery abgerufen werden.
Empfohlen: Experimentieren Sie mit der Erhöhung der Anzahl der CPU-Kerne für Ihre Executor-Ressourcen (bis zur Anzahl der von Ihrem Worker-Knoten verwendeten CPU-Kerne). Die Executors optimieren die CPU-Nutzung während der Serialisierungs- und Deserialisierungsschritte, wenn Daten in BigQuery ein- und aus BigQuery herausgelesen werden. Weitere Informationen finden Sie unter Clustergröße.
Ein Vorteil der Ausführung von Transformationen in BigQuery besteht darin, dass Ihre Pipelines in kleineren Dataproc-Clustern ausgeführt werden können. Wenn Joins die ressourcenintensivsten Vorgänge in Ihrer Pipeline sind, können Sie mit kleineren Clustergrößen experimentieren, da die komplexen JOIN-Operationen nun in BigQuery verwendet werden, sodass Sie möglicherweise die Computing-Gesamtkosten reduzieren können.
Mit der BigQuery Storage Read API schneller Daten abrufen
Nachdem BigQuery die Transformationen ausgeführt hat, sind in Ihrer Pipeline möglicherweise zusätzliche Phasen in Spark auszuführen. In Cloud Data Fusion-Version 6.7.0 und höher wird bei Transformations-Pushdown die BigQuery Storage Read API unterstützt. Dadurch wird die Latenz verringert und die Lesevorgänge in Spark werden beschleunigt. So lässt sich die Gesamtausführungszeit der Pipeline reduzieren.
Die API liest Einträge parallel. Wir empfehlen daher, die Größe der Ausführenden entsprechend anzupassen. Wenn ressourcenintensive Vorgänge in BigQuery ausgeführt werden, reduzieren Sie die Speicherzuweisung für die Executors, um den Parallelismus bei der Ausführung der Pipeline zu verbessern. Weitere Informationen finden Sie unter Cluster- und Executor-Größen anpassen.
Die BigQuery Storage Read API ist standardmäßig deaktiviert. Sie können es in Ausführungsumgebungen aktivieren, in denen Scala 2.12 installiert ist, einschließlich Dataproc 2.0 und Dataproc 1.5.
Dataset-Größe berücksichtigen
Berücksichtigen Sie die Größen der Datasets in den JOIN-Vorgängen. Bei JOIN-Vorgängen, die eine erhebliche Anzahl von Ausgabedatensätzen generieren (z. B. etwas, das einem Kreuz-JOIN-Vorgang ähnelt), kann die resultierende Dataset-Größe um ein Vielfaches größer sein als das Eingabe-Dataset. Beachten Sie auch den Mehraufwand, um diese Datensätze wieder in Spark abzurufen, wenn eine zusätzliche Spark-Verarbeitung für diese Datensätze (z. B. eine Transformation oder eine Senke) im Kontext der gesamten Pipelineleistung erfolgt.
Verzerrte Daten minimieren
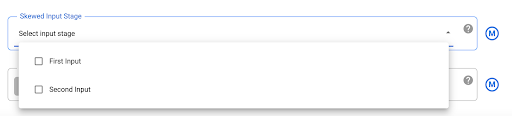
JOIN-Vorgänge mit stark verzerrten Daten können dazu führen, dass der BigQuery-Job die Limits für die Ressourcennutzung überschreitet. Dies führt dazu, dass der JOIN-Vorgang fehlschlägt. Um dies zu vermeiden, rufen Sie die Joiner-Plug-in-Einstellungen auf und identifizieren Sie die verzerrte Eingabe im Feld Skewed Input Stage (Phase mit verzerrter Eingabe). So kann Cloud Data Fusion die Eingaben so anordnen, dass das Risiko verringert wird, dass die BigQuery-Anweisung die Limits überschreitet.