
Bigtable
Faites évoluer vos applications sensibles à la latence avec le pionnier de NoSQL
Service de base de données NoSQL à faible latence, compatible avec Cassandra et HBase, pour le machine learning, les analyses opérationnelles et les applications destinées aux utilisateurs.
Se lancer avec une instance d'essai sans frais.
Points forts du produit
Gérez facilement des charges de travail opérationnelles et analytiques dans une même base de données.
Opérations de lecture et d'écriture hautes performances, même dans des déploiements distribués à l'échelle mondiale
Migrez facilement les charges de travail NoSQL avec des API et des outils de migration compatibles

Fonctionnalités
Faible latence et débit élevé
Bigtable est un magasin de clés-valeurs orienté colonnes, idéal pour un accès rapide à des données structurées, semi-structurées ou non structurées. Ainsi, les charges de travail sensibles à la latence, comme la personnalisation, sont parfaitement adaptées à Bigtable.
Grâce à ses compteurs distribués et à son débit élevé en lecture et en écriture par dollar, Bigtable est parfaitement adapté aux cas d'utilisation liés aux flux de clics et à l'IoT, et même aux analyses par lots pour les applications de calcul hautes performances (HPC), y compris l'entraînement de modèles de ML.
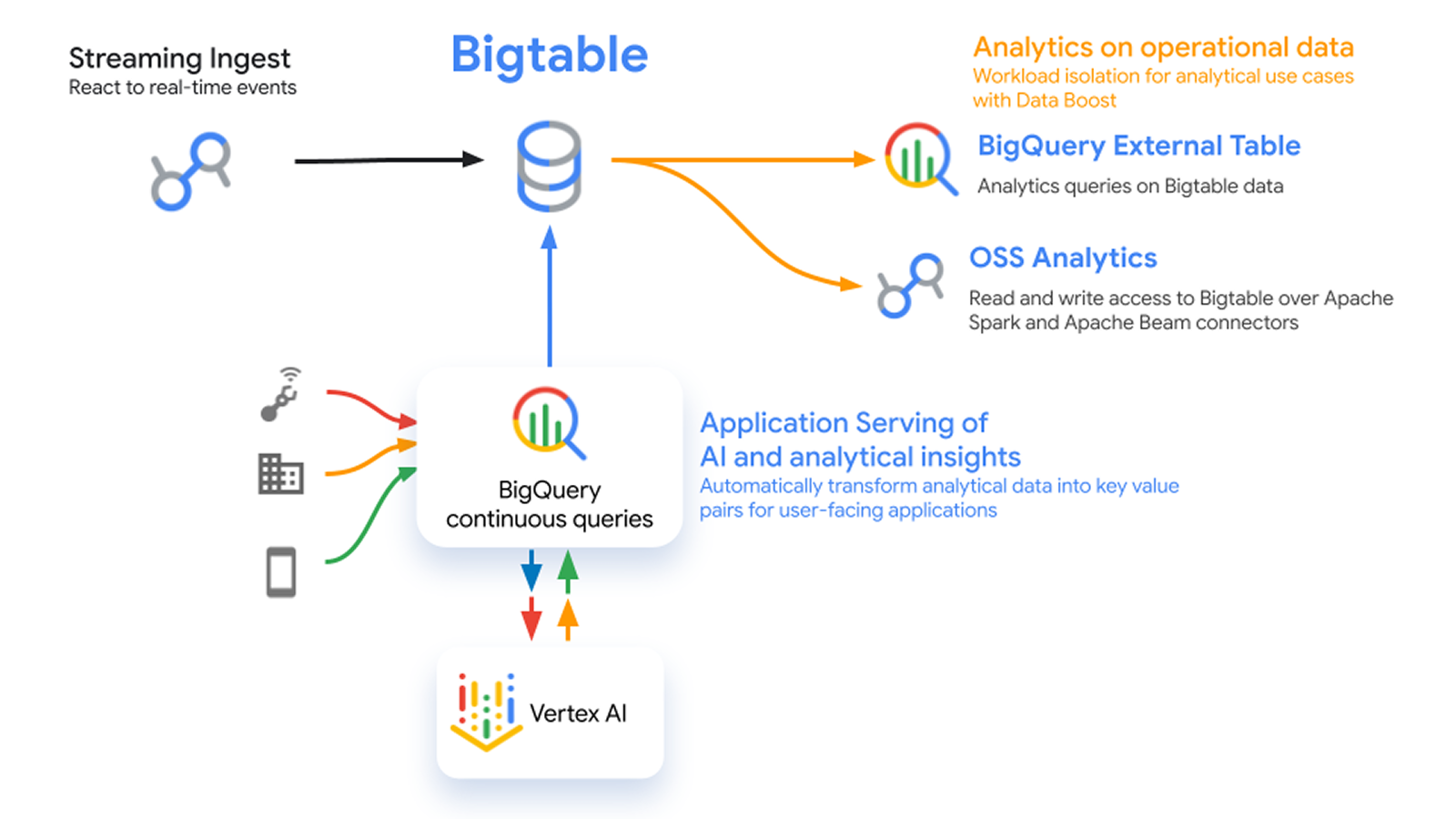
Architecture de stockage hybride
Le classement automatique et transparent des données de Bigtable entre la RAM, les SSD et les HDD permet d'obtenir des performances élevées à moindre coût. Profitez de latences ultrafaibles grâce à la RAM tout en éliminant les problèmes de hotspotting sans avoir besoin d'une couche de mise en cache. Hiérarchisez les données rarement consultées sur des HDD pour réaliser des économies considérables sans avoir à gérer les pipelines de données ni à vous soucier de la synchronisation des données entre plusieurs systèmes.
Vues matérialisées SQL et continues
SQL Bigtable permet aux utilisateurs de créer des applications entièrement gérées en temps réel à l'aide de la syntaxe SQL familière, avec des fonctionnalités spécialisées qui préservent le schéma flexible de Bigtable. Vous pouvez également utiliser l'interface SQL pour créer des vues matérialisées incrémentielles qui simplifient la création de métriques en temps réel. Une vue matérialisée Bigtable met automatiquement à jour les données en traitant les modifications au fur et à mesure de leur arrivée, sans affecter les performances de lecture et d'écriture. Elle effectue également un scaling automatique en fonction du trafic.
Flexibilité des modèles de données
Bigtable permet à votre modèle de données d'évoluer naturellement. Stockez n'importe quels embeddings, images et données scalaires, JSON, Protocol Buffer, Avro et Arrow, et ajoutez ou supprimez de nouvelles colonnes de manière dynamique si nécessaire. Proposez une diffusion à faible latence ou des analyses par lot hautes performances sur des données brutes non structurées dans une seule base de données.
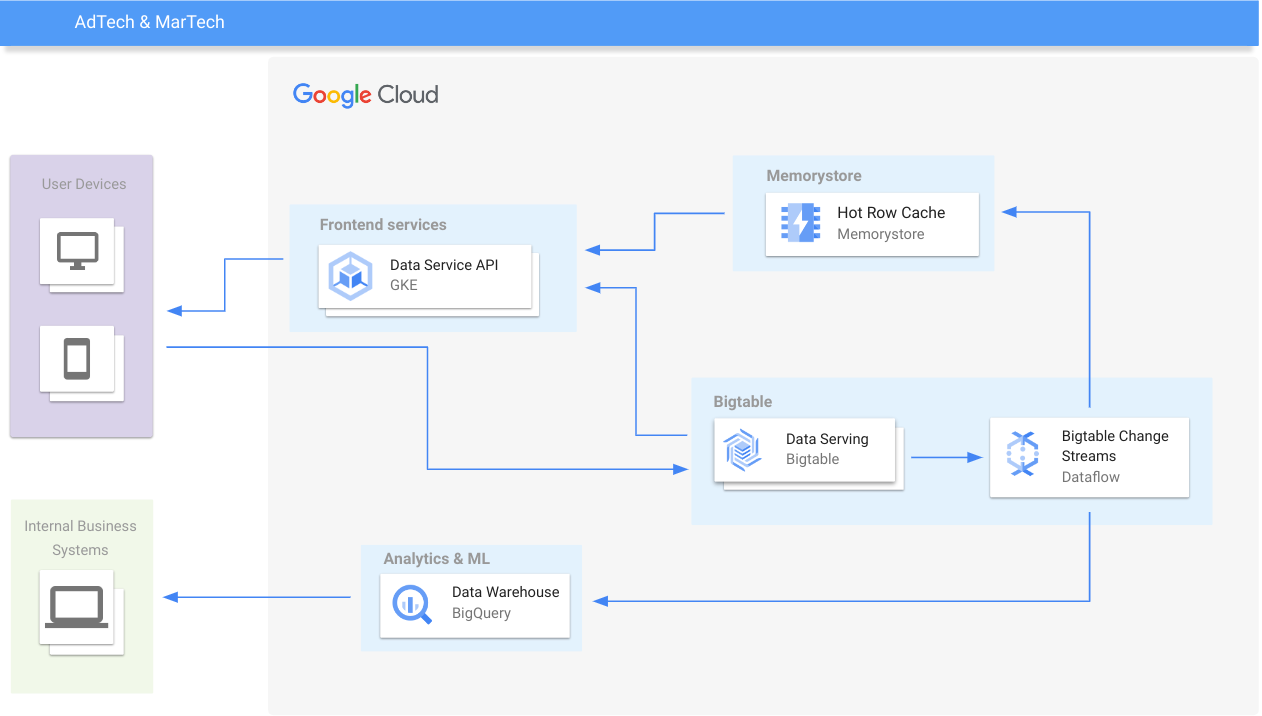
Migration facile à partir de bases de données NoSQL
Bigtable propose des API Apache Cassandra et HBase, ainsi que des outils de migration qui accélèrent et simplifient l'intégration en assurant une migration précise des données sans effort. La bibliothèque de réplications Bigtable HBase et le proxy Cassandra permettent des migrations à chaud sans temps d'arrêt, tandis que Bigtable Data Bridge et l'outil de migration Aerospike simplifient les migrations depuis Amazon DynamoDB et Aerospike, respectivement.

D'une seule zone jusqu'à 8 régions à la fois
Les applications reposant sur Bigtable peuvent fournir des lectures et des écritures à faible latence avec des configurations multiprincipales distribuées à l'échelle mondiale, quel que soit l'endroit où se trouvent vos utilisateurs. Les instances zonales sont idéales pour faire des économies et peuvent facilement être adaptées aux déploiements multirégionaux grâce à la réplication automatique. Lorsque vous exécutez une instance multirégionale, votre base de données est protégée contre les défaillances régionales et offre une disponibilité de premier ordre de 99,999 %.
Évolutivité sans limites, en lecture comme en écriture
Bigtable dissocie les ressources de calcul du stockage des données, ce qui permet d'ajuster de manière transparente les ressources de traitement. Chaque nœud supplémentaire peut traiter aussi bien les lectures et les écritures, ce qui permet une évolutivité horizontale sans effort. Bigtable optimise les performances en effectuant un scaling automatique des ressources pour qu'elles s'adaptent au trafic du serveur, ainsi qu'en gérant la segmentation, la réplication et le traitement des requêtes.
Traitement des données hautes performances et isolé des charges de travail
L'outil Bigtable Data Boost permet aux utilisateurs d'exécuter des requêtes analytiques, d'exécuter des processus ETL par lot, d'entraîner des modèles de ML ou d'exporter des données plus rapidement sans affecter les charges de travail transactionnelles. Data Boost ne nécessite aucune planification ni gestion de la capacité. Il permet d'interroger directement les données stockées dans le système de stockage distribué de Google, Colossus, à l'aide de la capacité à la demande, ce qui permet aux utilisateurs de gérer facilement des charges de travail mixtes et de partager des données en toute sérénité.
Compatibilité avec de nombreux outils et applications
Connectez-vous facilement à l'écosystème Open Source grâce à l'API Apache HBase. Créez plus rapidement des applications basées sur les données grâce à des intégrations parfaites avec Apache Spark, Hadoop, GKE, Dataflow, Dataproc, Vertex AI Vector Search et BigQuery. Rencontrez les équipes de développement où qu'elles se trouvent grâce à SQL et aux bibliothèques clientes pour Java, Go, Python, C#, Node.js, PHP, Ruby, C++, HBase et l'intégration à LangChain.
Développement agentique
Grâce à la compatibilité avec MCP et à l'intégration d'Agent Development Kit (ADK) et de LangChain, créez des applications agentiques pour automatiser les processus ou proposer des expériences utilisateur conversationnelles en toute simplicité. En utilisant les compétences agentiques de Bigtable avec Antigravity, votre IDE préféré ou la CLI, vous pouvez améliorer votre productivité en tant que développeur, et créer plus de contenu plus rapidement avec Bigtable.
Aucuns frais cachés
Aucuns frais d'IOPS, aucuns frais de création ou de restauration de sauvegardes, ni de tarification disproportionnée en lecture/écriture qui affectent votre budget à mesure que vos charges de travail évoluent.
Capture et événements des données modifiées en temps réel
Utilisez les flux de modifications Bigtable pour capturer les données modifiées des bases de données Bigtable et les intégrer à d'autres systèmes à des fins d'analyse, de déclenchement d'événements et de conformité.
Sécurité et contrôles de niveau professionnel
Les clés de chiffrement gérées par le client (CMEK) compatibles avec Cloud External Key Manager, l'intégration IAM pour les accès et les contrôles, VPC-SC, Access Transparency, Access Approval et les journaux d'audit complets vous aident à protéger vos données et à assurer leur conformité vis-à-vis de la réglementation. Le contrôle des accès ultraprécis vous permet d'autoriser l'accès au niveau des tables, des colonnes ou des lignes.

Observabilité
Surveillez les performances des bases de données Bigtable à l'aide de métriques côté serveur. Analysez les schémas d'utilisation avec l'outil de surveillance interactif Key Visualizer. Utilisez les statistiques sur les requêtes, les statistiques des tableaux et l'outil de tablettes populaires pour résoudre les problèmes de performances des requêtes et diagnostiquer rapidement les problèmes de latence grâce à la surveillance côté client.
Reprise après sinistre
Effectuez des sauvegardes incrémentielles instantanées de votre base de données, à moindre coût et à la demande. Stockez les sauvegardes dans différentes régions pour plus de résilience et effectuez facilement des restaurations entre des instances ou des projets pour des scénarios de test ou de production.
Fonctionnement
Les instances Bigtable fournissent des capacités de calcul et de stockage dans une ou plusieurs régions. Chaque cluster Bigtable peut recevoir des lectures et des écritures. Les données sont automatiquement "divisées" pour plus d'évolutivité et répliquées entre les clusters de manière asynchrone. Une horloge distribuée appelée TrueTime garantit que les transactions sont correctement ordonnées.
Les instances Bigtable fournissent des capacités de calcul et de stockage dans une ou plusieurs régions. Chaque cluster Bigtable peut recevoir des lectures et des écritures. Les données sont automatiquement "divisées" pour plus d'évolutivité et répliquées entre les clusters de manière asynchrone. Une horloge distribuée appelée TrueTime garantit que les transactions sont correctement ordonnées.

Analyse en temps réel
Améliorez la fraîcheur des données et réduisez la latence des requêtes
MLB capture tous les mouvements de la balle et chaque joueur en temps réel avec Bigtable
Découvrez comment créer une plate-forme d'analyse en temps réel avec BigQuery et Bigtable.
Découvrez comment utiliser la transformation d'enrichissement Apache Beam pour enrichir les événements de traitement en flux continu dans Dataflow.
Ressources de formation
Améliorez la fraîcheur des données et réduisez la latence des requêtes
MLB capture tous les mouvements de la balle et chaque joueur en temps réel avec Bigtable
Découvrez comment créer une plate-forme d'analyse en temps réel avec BigQuery et Bigtable.
Découvrez comment utiliser la transformation d'enrichissement Apache Beam pour enrichir les événements de traitement en flux continu dans Dataflow.
AdTech et commerce
Personnalisez les expériences en temps réel
Ressources de formation
Personnalisez les expériences en temps réel
Data fabric et analyses opérationnelles
Consolider les silos de données et effectuer un scaling horizontal des anciens systèmes
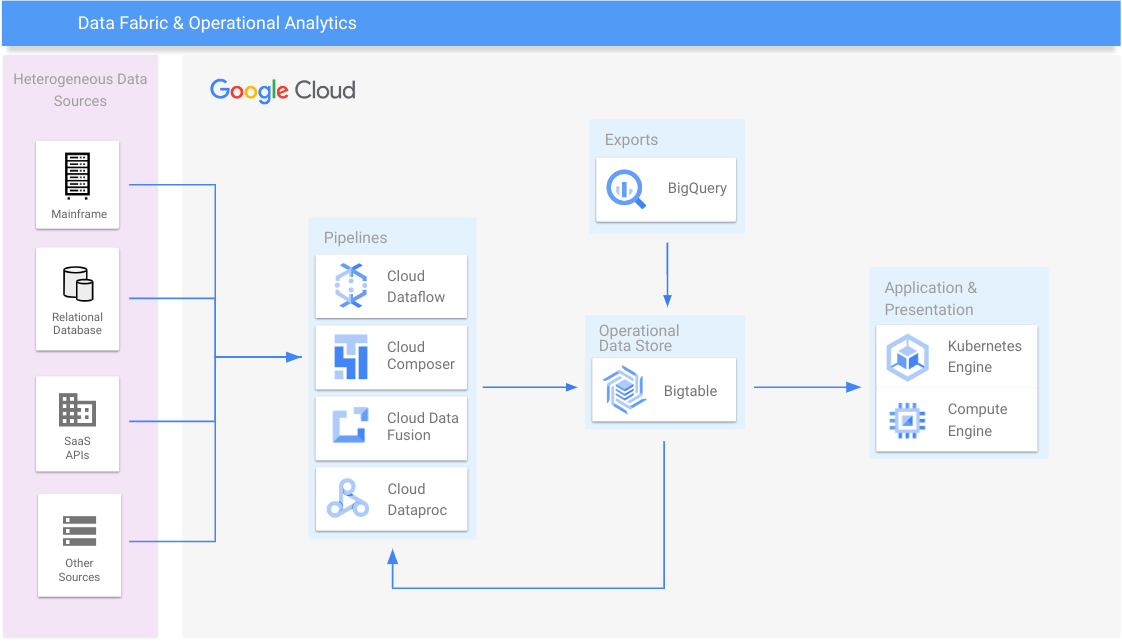
Ressources de formation
Consolider les silos de données et effectuer un scaling horizontal des anciens systèmes
Cybersécurité
Détectez les logiciels malveillants, la fraude au paiement, le spam et les escroqueries
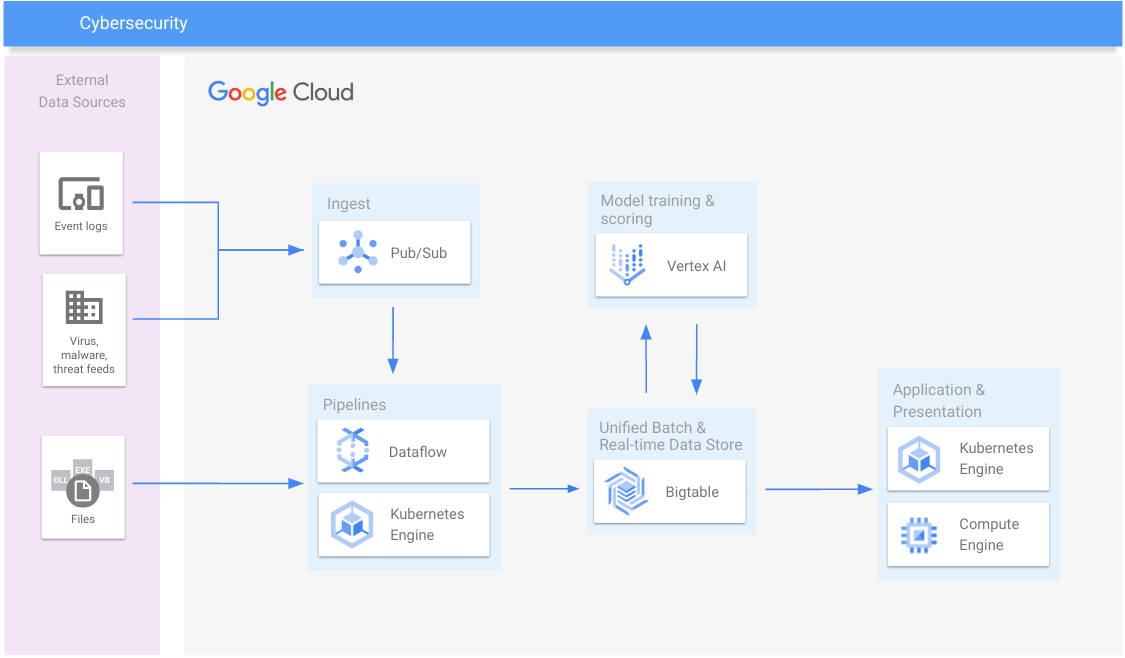
Ressources de formation
Détectez les logiciels malveillants, la fraude au paiement, le spam et les escroqueries
Média
Fournissez des données analytiques sur l'engagement et le contenu multimédia
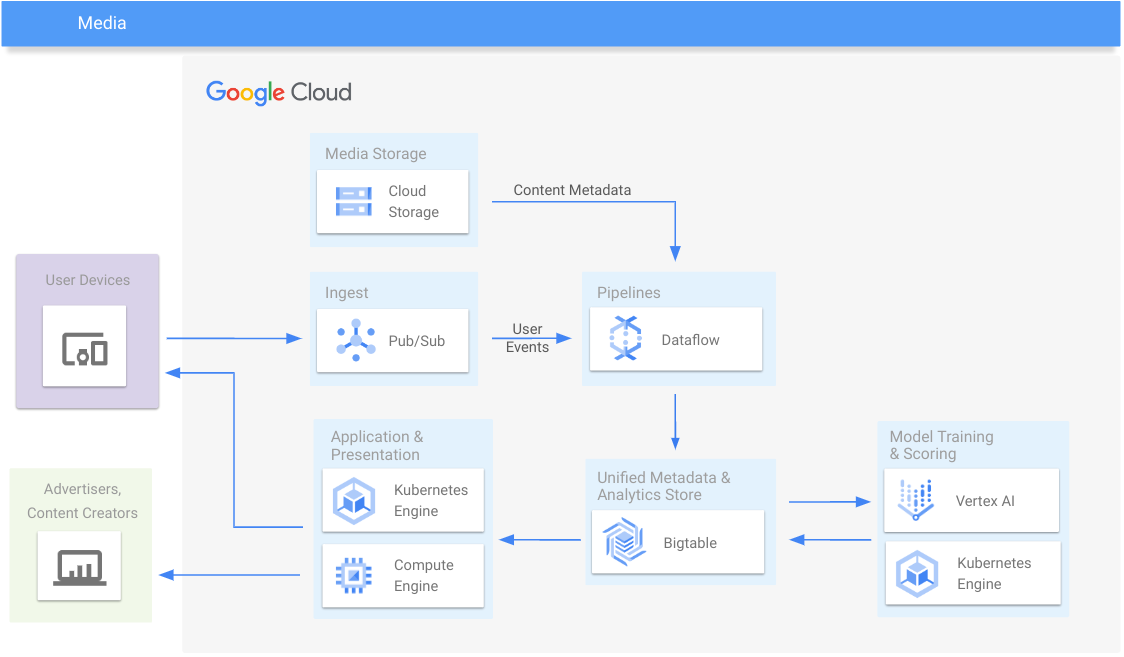
Ressources de formation
Fournissez des données analytiques sur l'engagement et le contenu multimédia
Séries temporelles et IoT
Gérer les données de séries temporelles à n'importe quelle échelle
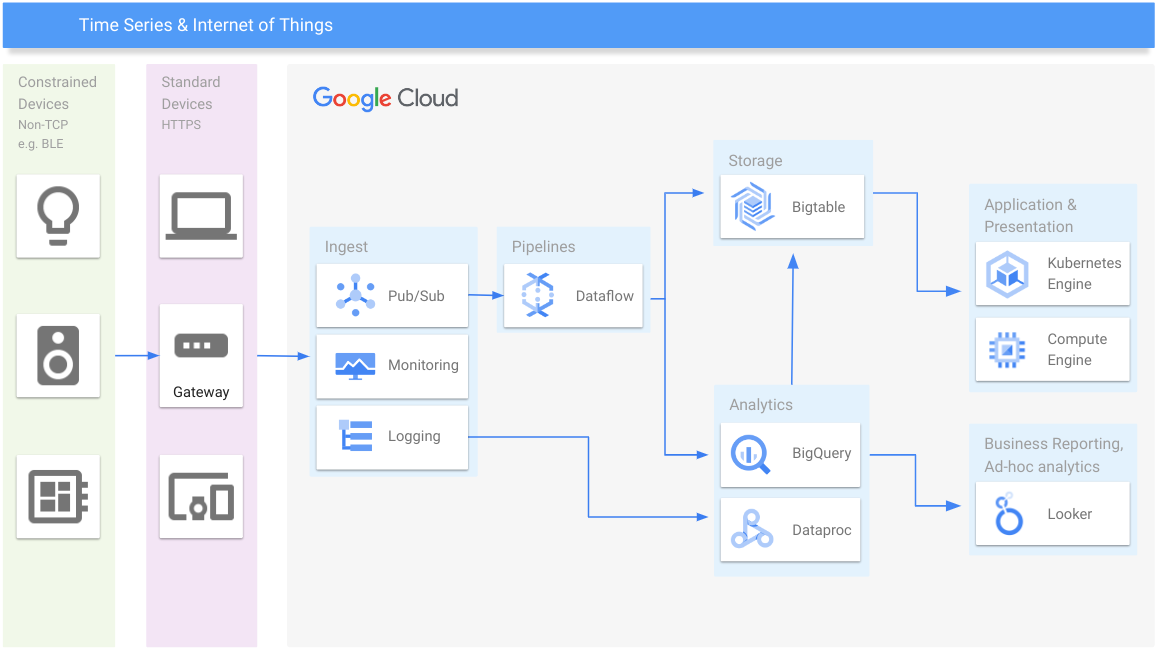
Ressources de formation
Gérer les données de séries temporelles à n'importe quelle échelle
Infrastructure de machine learning
Entraîner un modèle et effectuer des inférences à grande échelle
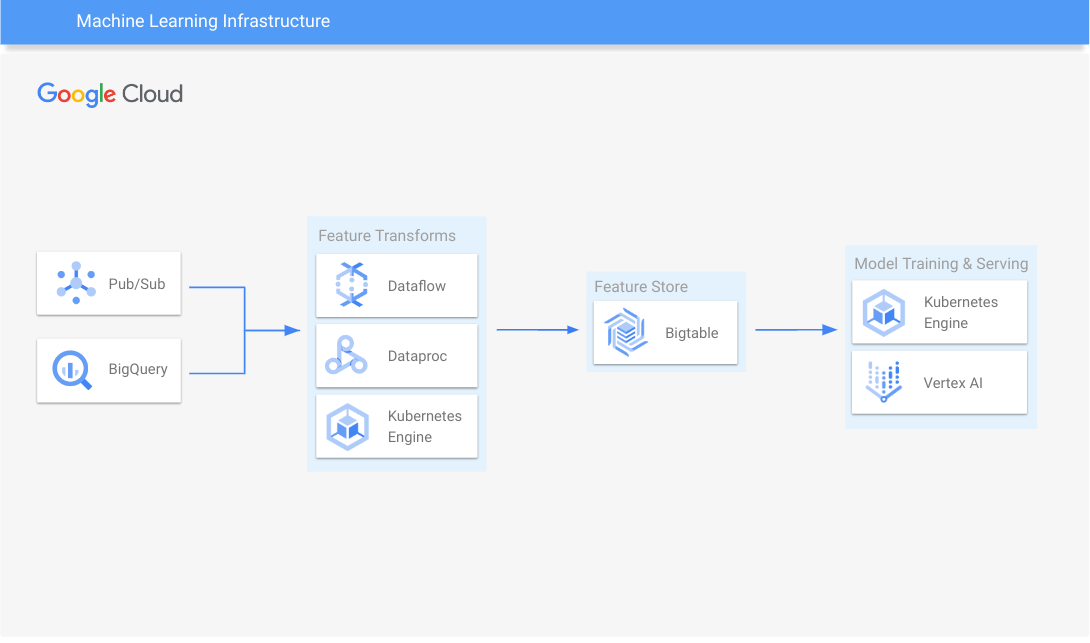
Découvrez comment utiliser Bigtable avec les principaux magasins de fonctionnalités Open Source.
Ressources de formation
Entraîner un modèle et effectuer des inférences à grande échelle
Découvrez comment utiliser Bigtable avec les principaux magasins de fonctionnalités Open Source.
Tarification
| Fonctionnement des tarifs de Bigtable | Les tarifs de Bigtable sont basés sur la capacité de calcul, le stockage de base de données, le stockage de sauvegarde et l'utilisation du réseau. Les remises sur engagement d'utilisation réduisent davantage le prix. | |
|---|---|---|
| Service | Description | Prix |
Capacité de calcul | Édition Enterprise Il offre des fonctionnalités clés pour le machine learning, les séries temporelles, l'analyse opérationnelle et les applications visibles par l'utilisateur à grande échelle, avec une latence de quelques millisecondes. La capacité de calcul est provisionnée en tant que nœuds. | À partir de 0,65 $ par nœud et par heure |
Édition Enterprise Plus Gérez les charges de travail les plus exigeantes avec les plus hauts niveaux de configurabilité, de performances, d'observabilité et de gouvernance. Inclut toutes les fonctionnalités de l'édition Enterprise et peut offrir une latence inférieure à une milliseconde. La capacité de calcul est provisionnée en tant que nœuds. | À partir de 0,85 $ par nœud et par heure | |
Niveau en mémoire Capacité de débit de lecture en mémoire pour des lectures à latence ultra-faible avec une résistance élevée aux hotspotting. Disponible uniquement dans l'édition Enterprise Plus. Le débit de lecture est provisionné par incréments de 40 000 lignes (1 Ko) par seconde, jusqu'à 120 000 lignes par seconde par nœud. | À partir de 0,20 $ par capacité de 40 000 lignes par seconde | |
Data Boost | Ressources de calcul isolées et à la demande pour le traitement par lot | À partir de 0,000845 $ par unité de traitement sans serveur et par heure |
Stockage de données | SSD La tarification est basée sur la taille physique des tables. Chaque instance répliquée est facturée séparément. Cette option est recommandée pour la mise en service à faible latence. | À partir de 0,17 $ par Go/mois |
HDD La tarification est basée sur la taille physique des tables. Chaque instance répliquée est facturée séparément. Infrequent Access (IA) utilise des HDD et est facturé au même tarif. | À partir de 0,026 $ par Go/mois | |
Sauvegardes | Sauvegardes standards Les tarifs sont basés sur la taille physique des sauvegardes. Les sauvegardes Bigtable sont incrémentielles. | À partir de 0,026 $ par Go/mois |
Sauvegardes à chaud Optimisé pour réduire considérablement le délai de restauration. Les tarifs sont basés sur la taille physique des sauvegardes. | À partir de 0,12 $ par Go/mois | |
Réseau | Entrée | Sans frais |
Sortie dans la même région | Sans frais | |
Sortie entre régions | À partir de 0,10 $ par Go | |
Réplication | Dans la même région | Sans frais |
Entre des régions | À partir de 0,01 $ par Go | |
En savoir plus sur les tarifs de Bigtable et les remises sur engagement d'utilisation.
Fonctionnement des tarifs de Bigtable
Les tarifs de Bigtable sont basés sur la capacité de calcul, le stockage de base de données, le stockage de sauvegarde et l'utilisation du réseau. Les remises sur engagement d'utilisation réduisent davantage le prix.
Capacité de calcul
Édition Enterprise
Il offre des fonctionnalités clés pour le machine learning, les séries temporelles, l'analyse opérationnelle et les applications visibles par l'utilisateur à grande échelle, avec une latence de quelques millisecondes.
La capacité de calcul est provisionnée en tant que nœuds.
Starting at
0,65 $
par nœud et par heure
Édition Enterprise Plus
Gérez les charges de travail les plus exigeantes avec les plus hauts niveaux de configurabilité, de performances, d'observabilité et de gouvernance. Inclut toutes les fonctionnalités de l'édition Enterprise et peut offrir une latence inférieure à une milliseconde.
La capacité de calcul est provisionnée en tant que nœuds.
Starting at
0,85 $
par nœud et par heure
Niveau en mémoire
Capacité de débit de lecture en mémoire pour des lectures à latence ultra-faible avec une résistance élevée aux hotspotting. Disponible uniquement dans l'édition Enterprise Plus.
Le débit de lecture est provisionné par incréments de 40 000 lignes (1 Ko) par seconde, jusqu'à 120 000 lignes par seconde par nœud.
Starting at
0,20 $
par capacité de 40 000 lignes par seconde
Data Boost
Ressources de calcul isolées et à la demande pour le traitement par lot
Starting at
0,000845 $
par unité de traitement sans serveur et par heure
Stockage de données
SSD
La tarification est basée sur la taille physique des tables. Chaque instance répliquée est facturée séparément. Cette option est recommandée pour la mise en service à faible latence.
Starting at
0,17 $
par Go/mois
HDD
La tarification est basée sur la taille physique des tables. Chaque instance répliquée est facturée séparément. Infrequent Access (IA) utilise des HDD et est facturé au même tarif.
Starting at
0,026 $
par Go/mois
Sauvegardes
Sauvegardes standards
Les tarifs sont basés sur la taille physique des sauvegardes. Les sauvegardes Bigtable sont incrémentielles.
Starting at
0,026 $
par Go/mois
Sauvegardes à chaud
Optimisé pour réduire considérablement le délai de restauration. Les tarifs sont basés sur la taille physique des sauvegardes.
Starting at
0,12 $
par Go/mois
Réseau
Entrée
Sans frais
Sortie dans la même région
Sans frais
Sortie entre régions
Starting at
0,10 $
par Go
Réplication
Dans la même région
Sans frais
Entre des régions
Starting at
0,01 $
par Go
En savoir plus sur les tarifs de Bigtable et les remises sur engagement d'utilisation.
Cas d'utilisation métier
Découvrez comment d'autres entreprises ont créé des applications innovantes pour offrir une expérience client de qualité, réduire les coûts et augmenter le ROI avec Bigtable.
Découvrez comment Box a modernisé ses bases de données NoSQL avec Bigtable
Box a amélioré l'évolutivité et la disponibilité tout en réduisant les coûts de gestion, grâce à une migration fluide.
Contenu associé

Sabre fournit des résultats de recherche de voyages avec une latence et un coût total de possession réduits avec Bigtable

Découvrez comment Plaid a développé sa plate-forme d'analyse en temps réel sur BigQuery et Bigtable

Airship atteint plus d'un million d'écritures et 700 000 lectures par seconde à moindre coût avec Bigtable
Avantages et clients
Développez votre activité grâce à des applications innovantes qui évoluent sans limites pour répondre à n'importe quel niveau de demande.
Bénéficiez d'un rapport prix-performances exceptionnel et payez à l'usage.
Migrez facilement depuis d'autres bases de données NoSQL, et exécutez des déploiements hybrides ou multicloud avec des API et des outils de migration Open Source.















Partenaires et intégration
Faites appel à des partenaires disposant de l'expertise Bigtable pour vous aider à chaque étape de votre parcours, des évaluations aux analyses de rentabilisation en passant par les migrations et la création d'applications sur Bigtable.

































Intégrateurs système
Vous souhaitez en savoir plus sur l'intégration partenaire ou tierce la plus adaptée à votre entreprise ? Accédez à l'annuaire des partenaires.
En savoir plus
Questions fréquentes
De quel type de base de données est Bigtable ?
Bigtable est un service de base de données NoSQL, en particulier un magasin de clés-valeurs qui permet d'utiliser des tables très larges comportant des dizaines de milliers de colonnes. Il est donc également appelé base de données à colonnes larges ou carte multidimensionnelle distribuée. Il s'agit d'une base de données NoSQL dans le sens "pas uniquement SQL". Il prend en charge de nombreuses fonctionnalités au-delà des recherches clé-valeur, y compris les agrégations et les index secondaires globaux.
Bigtable ressemble le plus aux projets Open Source populaires qu'il a inspirés, tels qu'Apache HBase et Cassandra. Il s'agit donc de la destination la plus courante pour les clients qui traitent d'importants volumes de données et qui recherchent une solution de base de données NoSQL hautes performances, économique et entièrement gérée sur Google Cloud.
Bigtable est-il compatible avec SQL ?
En plus de ses API clé-valeur, Bigtable accepte les requêtes SQL de trois façons différentes :
- Pour le développement d'applications à faible latence, Bigtable propose une API de requête SQL qui s'appuie sur GoogleSQL avec des extensions pour le modèle de données orienté colonnes, semblable à Cassandra Query Language (CQL). Il est compatible avec plus de 200 fonctions, y compris les agrégations (GROUP BY), le fenêtrage, les fonctions de traitement géospatial et JSON, et la recherche vectorielle (kNN). Bigtable est compatible avec la syntaxe de requête standard et la syntaxe de requête redirigée.
- Pour les cas d'utilisation de la data science ou d'autres types de traitement par lot et d'ETL, Bigtable est compatible avec SparkSQL à l'aide de son client Spark.
- Les utilisateurs qui souhaitent effectuer une analyse exploratoire post-hoc ou combiner des données provenant de plusieurs sources à des fins d'analyse par lot peuvent également accéder aux données Bigtable depuis BigQuery. Il vous suffit d'enregistrer vos tables Bigtable dans BigQuery et de les interroger comme n'importe quelle autre table BigQuery, sans aucun processus ETL ni duplication de données.
Comment migrer des bases de données vers Bigtable ?
Bigtable propose des API Apache Cassandra et HBase, ainsi que des outils de migration qui accélèrent et simplifient l'intégration en assurant une migration précise des données sans effort. La bibliothèque de réplications HBase de Bigtable et les outils de migration Cassandra permettent des migrations à chaud sans temps d'arrêt. Bigtable propose également des utilitaires pour simplifier les migrations depuis DynamoDB et Aerospike.
Bigtable est-il sans serveur ?
Le stockage Bigtable est facturé au Go utilisé, comme dans un modèle sans serveur. Bigtable offre également un scaling horizontal linéaire et peut automatiquement effectuer un scaling à la hausse ou à la baisse des ressources de calcul en fonction des fluctuations de la demande. Par conséquent, aucun engagement de capacité à long terme n'est requis pour le stockage ou le calcul. Cependant, la tarification du calcul à faible latence est basée sur la capacité et facturée par nœud, et non par requête, où chaque nœud peut traiter jusqu'à 17 000 requêtes par seconde. Ainsi, le prix de Bigtable est plus avantageux pour les charges de travail importantes, mais moins adapté aux petites applications, qui peuvent être plus adaptés aux bases de données Google Cloud telles que Firestore.
Pour le traitement de données par lot, Bigtable propose Data Boost, qui est facturé en unités de traitement sans serveur (SPU, Serverless Processing Units).
Bigtable est-il un cache persistant ?
Bigtable est une base de données offrant des performances de type cache, et non un cache avec persistance. Il offre de puissantes capacités de traitement intégrées à la base de données, une API SQL, des vues matérialisées continues et des index secondaires asynchrones. Il utilise la technologie RDMA pour fournir un accès direct à la RAM, ce qui permet d'obtenir un débit et des performances élevés qui ne sont pas limités par la capacité du processeur du serveur de base de données. Bien qu'il soit possible d'utiliser Bigtable en remplacement de solutions de mise en cache durables telles que MemoryDB, l'inverse n'est pas toujours vrai, car des solutions telles que Redis ont été conçues comme un cache, et non comme une base de données.


















