Cette page décrit les éléments à prendre en compte et les processus à suivre pour migrer des données d'un cluster Apache HBase vers une instance Bigtable surGoogle Cloud.
Le processus décrit sur cette page nécessite que vous mettiez votre application hors connexion. Si vous souhaitez migrer sans temps d'arrêt, consultez les conseils de migration en ligne sur la page Répliquer de HBase vers Bigtable.
Pour migrer des données vers Bigtable à partir d'un cluster HBase hébergé sur un service Google Cloud , tel que Dataproc ou Compute Engine, consultez Migrer des données de HBase hébergé sur Google Cloud vers Bigtable.
Avant de commencer cette migration, vous devez prendre en compte les implications en termes de performances, la conception de schéma Bigtable, les conséquences pour votre approche en matière d'authentification et d'autorisation, et les fonctionnalités de Bigtable.
Remarques sur la prémigration
Cette section suggère considérations à prendre en compte avant de commencer votre migration.
Performances
Avec une charge de travail type, Bigtable offre des performances hautement prévisibles. Assurez-vous de bien comprendre les facteurs qui affectent les performances de Bigtable avant de migrer vos données.
Conception de schéma Bigtable
Dans la plupart des cas, vous pouvez utiliser la même conception de schéma dans Bigtable que dans HBase. Si vous souhaitez modifier votre schéma ou si votre cas d'utilisation évolue, consultez les concepts exposés dans la section Concevoir votre schéma avant de migrer vos données.
Authentification et autorisation
Avant de concevoir le contrôle des accès pour Bigtable, passez en revue les processus d'authentification et d'autorisation HBase existants.
Bigtable utilise les mécanismes d'authentification standards de Google Cloud, ainsi que la gestion de l'authentification et des accès (IAM) pour assurer le contrôle des accès. Vous pouvez donc convertir votre autorisation existante sur HBase en IAM. et mapper les groupes Hadoop existants qui fournissent des mécanismes de contrôle des accès pour HBase à différents comptes de service.
Bigtable vous permet de contrôler les accès au niveau du projet, de l'instance et de la table. Pour plus d'informations, consultez la section Contrôle des accès.
Exigences concernant les temps d'arrêt
L'approche de migration décrite sur cette page implique de mettre votre application hors connexion pendant toute la durée de la migration. Si votre entreprise ne peut pas tolérer de temps d'arrêt pendant la migration vers Bigtable, consultez les conseils pour la migration en ligne sur la page Répliquer de HBase vers Bigtable.
Migrer HBase vers Bigtable
Pour migrer vos données de HBase vers Bigtable, vous devez exporter un instantané HBase pour chaque table vers Cloud Storage, puis importer les données dans Bigtable. Ces étapes concernent un seul cluster HBase et sont décrites en détail dans les sections suivantes.
- Arrêter l'envoi d'écritures vers votre cluster HBase
- Prendre des instantanés des tables du cluster HBase
- Exporter les fichiers d'instantanés vers Cloud Storage
- Calculer les hachages et exportez-les vers Cloud Storage
- Créer des tables de destination dans Bigtable
- Importer les données HBase depuis Cloud Storage dans Bigtable
- Valider les données importées
- Acheminer les écritures vers Bigtable.
Avant de commencer
Créez un bucket Cloud Storage pour stocker vos instantanés. Créez le bucket dans la même zone que celle dans laquelle vous prévoyez d'exécuter votre tâche Dataflow.
Créez une instance Bigtable pour stocker vos nouvelles tables.
Identifiez le cluster Hadoop que vous exportez. Vous pouvez exécuter les tâches pour votre migration directement sur le cluster HBase ou sur un cluster Hadoop distinct disposant d'une connectivité réseau au Namenode et aux Datanodes du cluster HBase.
Installez et configurez le connecteur Cloud Storage sur chaque nœud du cluster Hadoop, ainsi que sur l'hôte à partir duquel la tâche est lancée. Pour découvrir la procédure d'installation détaillée, consultez la page Installer le connecteur Cloud Storage.
Ouvrez une interface système de commande sur un hôte pouvant se connecter à votre cluster HBase et à votre projet Bigtable. C'est à ce stade que vous allez effectuer les étapes suivantes.
Obtenez l'outil de traduction de schéma :
wget BIGTABLE_HBASE_TOOLS_URLRemplacez
BIGTABLE_HBASE_TOOLS_URLpar l'URL de la dernière version deJAR with dependenciesdisponible dans le dépôt Maven de l'outil. Le nom du fichier est semblable àhttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.Pour trouver l'URL ou télécharger manuellement le fichier JAR, procédez comme suit :
- Accéder au dépôt
- Cliquez sur le numéro de version le plus récent.
- Identifiez la valeur
JAR with dependencies file(généralement en haut). - Effectuez un clic droit et copiez l'URL, ou cliquez pour télécharger le fichier.
Obtenez l'outil d'importation :
wget BIGTABLE_BEAM_IMPORT_URLRemplacez
BIGTABLE_BEAM_IMPORT_URLpar l'URL de la dernière version deshaded JARdisponible dans le dépôt Maven de l'outil. Le nom du fichier est semblable àhttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.Pour trouver l'URL ou télécharger manuellement le fichier JAR, procédez comme suit :
- Accéder au dépôt
- Cliquez sur le numéro de version le plus récent.
- Cliquez sur Téléchargements.
- Passez la souris sur shaded.jar.
- Effectuez un clic droit et copiez l'URL, ou cliquez pour télécharger le fichier.
Définissez les variables d'environnement suivantes :
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYRemplacez les éléments suivants :
PROJECT_ID: projet Google Cloud dans lequel se trouve votre instanceINSTANCE_ID: identifiant de l'instance Bigtable dans laquelle vous importez vos donnéesREGION: région contenant l'un des clusters de votre instance Bigtable. Exemple :northamerica-northeast2CLUSTER_NUM_NODES: nombre de nœuds dans votre instance BigtableTRANSLATE_JAR: nom et numéro de version du fichier JARbigtable hbase toolsque vous avez téléchargé à partir de Maven. La valeur doit être semblable à :bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: nom et numéro de version du fichier JARbigtable-beam-importque vous avez téléchargé à partir de Maven. La valeur doit être semblable à :bigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: nom du bucket Cloud Storage dans lequel vous stockez vos instantanés.ZOOKEEPER_QUORUM: hôte Zookeeper auquel l'outil se connectera, au formathost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: répertoire de votre hôte HBase contenant les données que vous souhaitez migrer, au formathdfs://host1.myownpersonaldomain.com:8020/hbase.
(Facultatif) Pour vérifier que les variables ont été correctement définies, exécutez la commande
printenvpour afficher toutes les variables d'environnement.
Arrêter l'envoi d'écritures à HBase
Avant de prendre des instantanés de vos tables HBase, arrêtez d'envoyer des écritures vers votre cluster HBase.
Prendre des instantanés de table HBase
Lorsque votre cluster HBase n'ingère plus de données, prenez un instantané de chaque table que vous prévoyez de migrer vers Bigtable.
Au départ, un instantané a une empreinte de stockage minimale sur le cluster HBase, mais au fil du temps, il peut atteindre la même taille que la table d'origine. L'instantané ne consomme aucune ressource de processeur.
Exécutez la commande suivante pour chaque table, en utilisant un nom unique pour chaque instantané :
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Remplacez les éléments suivants :
TABLE_NAME: nom de la table HBase à partir de laquelle vous exportez des données.SNAPSHOT_NAME: nom du nouvel instantané
Exporter des instantanés HBase vers Cloud Storage
Une fois les instantanés créés, vous devez les exporter. Lorsque vous exécutez des tâches d'exportation sur un cluster HBase de production, surveillez le cluster et les autres ressources HBase pour vous assurer que les clusters restent en bon état.
Pour chaque instantané que vous souhaitez exporter, exécutez la commande suivante :
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Remplacez SNAPSHOT_NAME par le nom de l'instantané à exporter.
Calculer et exporter des hachages
Créez ensuite les hachages à utiliser pour la validation une fois la migration terminée.
HashTable est un outil de validation fourni par HBase qui calcule les hachages pour les plages de lignes et les exporte dans des fichiers. Vous pouvez exécuter une tâche sync-table sur la table de destination pour faire correspondre les hachages et garantir l'intégrité des données migrées.
Exécutez la commande suivante pour chaque table que vous avez exportée :
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Remplacez les éléments suivants :
TABLE_NAME: nom de la table HBase pour laquelle vous avez créé un instantané et que vous avez exporté
Créer des tables de destination
L'étape suivante consiste à créer une table de destination dans votre instance Bigtable pour chaque instantané que vous avez exporté. Utilisez un compte disposant de l'autorisation bigtable.tables.create pour l'instance.
Ce guide utilise l'outil de traduction de schéma Bigtable, qui crée automatiquement la table pour vous. Toutefois, si vous ne souhaitez pas que votre schéma Bigtable corresponde exactement au schéma HBase, vous pouvez créer une table à l'aide de l'outil de ligne de commande cbt ou de la console Google Cloud .
L'outil de traduction de schéma Bigtable capture le schéma de la table HBase, y compris le nom de la table, les familles de colonnes, les règles de récupération de mémoire et les divisions. Une table similaire est ensuite créée dans Bigtable.
Pour chaque table que vous souhaitez importer, exécutez la commande suivante pour copier le schéma de HBase vers Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Remplacez TABLE_NAME par le nom de la table HBase que vous importez. L'outil de traduction de schéma utilise ce nom pour votre nouvelle table Bigtable.
Vous pouvez également remplacer TABLE_NAME par une expression régulière (telle que ".*"), qui capture toutes les tables que vous souhaitez créer, puis n'exécuter la commande qu'une seule fois.
Importer les données HBase dans Bigtable avec Dataflow
Une fois que vous disposez d'une table prête à migrer vos données, vous pouvez importer et valider vos données.
Tables non compressées
Si vos tables HBase ne sont pas compressées, exécutez la commande suivante pour chaque table que vous souhaitez migrer :
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Remplacez les éléments suivants :
TABLE_NAME: nom de la table HBase que vous importez. L'outil de traduction de schéma attribue ce nom à votre nouvelle table Bigtable. Les nouveaux noms de table ne sont pas acceptés.SNAPSHOT_NAME: nom que vous avez attribué à l'instantané de la table que vous importez.
Une fois la commande exécutée, l'outil restaure l'instantané HBase sur votre bucket Cloud Storage, puis lance la tâche d'importation. La restauration de l'instantané peut prendre plusieurs minutes, en fonction de sa taille.
Pour l'importation, tenez compte des conseils suivants :
- Pour améliorer les performances du chargement des données, veillez à définir
maxNumWorkers. Cette valeur permet de garantir que la tâche d'importation dispose de la puissance de calcul nécessaire pour être terminée dans un délai raisonnable, mais pas au point de surcharger le cluster Bigtable.- Si vous n'utilisez pas également l'instance Bigtable pour une autre charge de travail, multipliez le nombre de nœuds de votre instance Bigtable par 3, et utilisez ce nombre pour
maxNumWorkers. - Si vous utilisez l'instance pour une autre charge de travail en même temps que vous importez vos données HBase, réduisez la valeur de
maxNumWorkersde manière appropriée.
- Si vous n'utilisez pas également l'instance Bigtable pour une autre charge de travail, multipliez le nombre de nœuds de votre instance Bigtable par 3, et utilisez ce nombre pour
- Utilisez le type de nœud de calcul par défaut.
- Pendant l'importation, vous devez surveiller l'utilisation du processeur sur l'instance Bigtable. Si l'utilisation du processeur sur l'instance Bigtable est trop élevée, vous devrez peut-être ajouter des nœuds supplémentaires. L'amélioration des performances liée à l'ajout de nœuds peut prendre jusqu'à 20 minutes pour se manifester.
Pour en savoir plus sur la surveillance de l'instance Bigtable, consultez Surveillance.
Tables compressées Snappy
Si vous importez des tables compressées Snappy, vous devez utiliser une image de conteneur personnalisée dans le pipeline Dataflow. L'image de conteneur personnalisé que vous utilisez pour importer des données compressées dans Bigtable est compatible avec la bibliothèque de compression native Hadoop. Vous devez disposer du SDK Apache Beam version 2.30.0 ou ultérieure pour utiliser l'exécuteur Dataflow v2, et vous devez disposer de la version 2.3.0 ou ultérieure de la bibliothèque cliente HBase pour Java.
Pour importer des tables compressées Snappy, exécutez la même commande que celle utilisée pour les tables non compressées, en ajoutant l'option suivante :
--enableSnappy=true
Valider les données importées dans Bigtable
Pour valider les données importées, vous devez exécuter la tâche sync-table. La tâche sync-table calcule les hachages pour les plages de lignes dans Bigtable, puis les met en correspondance avec la sortie HashTable que vous avez calculée précédemment.
Pour exécuter la tâche sync-table, exécutez la commande suivante dans l'interface système :
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Remplacez TABLE_NAME par le nom de la table HBase que vous importez.
Une fois la tâche sync-table terminée, ouvrez la page Informations sur la tâche Dataflow et consultez la section Compteurs personnalisés de la tâche. Si la tâche d'importation parvient à importer toutes les données, la valeur de ranges_matched possède une valeur et celle de ranges_not_matched est 0.
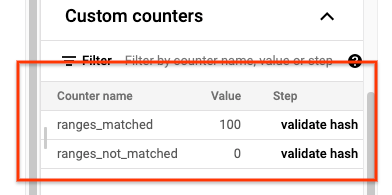
Si ranges_not_matched affiche une valeur, ouvrez la page des journaux, sélectionnez Journaux de nœud de calcul, puis filtrez par Non-concordance de plage. Le résultat lisible par un ordinateur de ces journaux est stocké dans Cloud Storage à l'emplacement de sortie que vous créez dans l'option outputPrefix de la table de synchronisation.
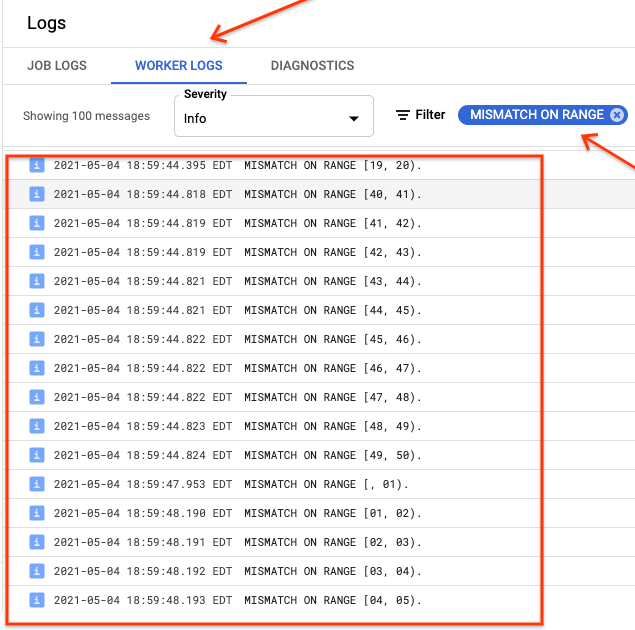
Vous pouvez essayer de nouveau la tâche d'importation ou écrire un script pour lire les fichiers de sortie afin de déterminer où les incohérences se sont produites. Chaque ligne du fichier de sortie est un enregistrement JSON sérialisé d'une plage non concordante.
Acheminer les écritures vers Bigtable
Après avoir validé les données de chaque table du cluster, vous pouvez configurer vos applications pour qu'elles acheminent tout leur trafic vers Bigtable, puis abandonner l'instance HBase.
Une fois la migration terminée, vous pouvez supprimer les instantanés sur votre instance HBase.
Étapes suivantes
- Obtenez davantage d'informations sur Cloud Storage.