このページでは、Apache HBase クラスタからGoogle Cloudの Bigtable インスタンスにデータを移行する際の考慮事項とプロセスについて説明します。
このページで説明するプロセスでは、アプリケーションをオフラインにする必要があります。ダウンタイムなしで移行する場合は、HBase から Bigtable へのレプリケーションのオンライン移行のガイダンスをご覧ください。
Dataproc や Compute Engine などの Google Cloud サービスでホストされている HBase クラスタから Bigtable にデータを移行するには、 Google Cloud でホストされている HBase を Bigtable に移行するをご覧ください。
この移行を開始する前に、パフォーマンスへの影響、Bigtable のスキーマ設計、認証と認可の方法、Bigtable の機能セットについて検討する必要があります。
移行前の考慮事項
このセクションでは、移行の開始前に確認し、検討すべき事項について説明します。
パフォーマンス
通常のワークロードの場合、Bigtable は、極めて予測可能性の高いパフォーマンスを実現します。データを移行する前に、Bigtable のパフォーマンスに影響を与える要因を理解しておいてください。
Bigtable のスキーマ設計
ほとんどの場合、Bigtable では HBase と同じスキーマ設計を使用できます。スキーマを変更する場合やユースケースを変更する場合は、データを移行する前にスキーマの設計で説明されているコンセプトを確認してください。
認証と認可
Bigtable のアクセス制御を設計する際は、あらかじめ既存の HBase の認証と認可に関するプロセスを確認しておきます。
Bigtable は、 Google Cloudの標準の認証メカニズムと Identity and Access Management を使用してアクセス制御を行うため、HBase 上の既存の認可を IAM に変換します。HBase のアクセス制御メカニズムを備えた既存の Hadoop グループを、異なるサービス アカウントにマッピングできます。
Bigtable では、プロジェクト、インスタンス、テーブルのレベルでアクセスを制御できます。詳しくは、アクセス制御をご覧ください。
ダウンタイムの要件
このページで説明する移行アプローチでは、移行期間中にアプリケーションをオフラインにする必要があります。Bigtable への移行中にダウンタイムが発生するとビジネスに影響する場合は、HBase から Bigtable へのレプリケーションのオンライン移行に関するガイダンスをご覧ください。
HBase から Bigtable への移行
HBase から Bigtable にデータを移行するには、各テーブルの HBase スナップショットを Cloud Storage にエクスポートし、そのデータを Bigtable にインポートします。次の手順は、単一の HBase クラスタを対象としたものです。各手順については、以降のセクションで詳しく説明します。
- HBase クラスタへの書き込み送信を停止します。
- HBase クラスタのテーブルのスナップショットを作成します。
- スナップショット ファイルを Cloud Storage にエクスポートします。
- ハッシュを計算し、Cloud Storage にエクスポートします。
- Bigtable に宛先テーブルを作成します。
- HBase データを Cloud Storage から Bigtable にインポートします。
- インポートされたデータを検証します。
- Bigtable への書き込みをルーティングします。
始める前に
スナップショットを保存する Cloud Storage バケットを作成します。Dataflow ジョブを実行するロケーションにバケットを作成します。
Bigtable インスタンスを作成して新しいテーブルを保存します。
エクスポートする Hadoop クラスタを特定します。移行ジョブは、HBase クラスタ上で直接実行することも、HBase クラスタの Namenode および Datanode とネットワーク接続されている別の Hadoop クラスタで実行することもできます。
Hadoop クラスタ内のすべてのノードと、ジョブが開始されるホストに、Cloud Storage コネクタをインストールして構成します。インストール手順の詳細については、Cloud Storage コネクタのインストールをご覧ください。
HBase クラスタと Bigtable プロジェクトに接続できるホストでコマンドシェルを開きます。ここで、次の手順に沿って操作します。
スキーマ変換ツールを取得します。
wget BIGTABLE_HBASE_TOOLS_URLBIGTABLE_HBASE_TOOLS_URLは、ツールの Maven リポジトリで利用可能な最新のJAR with dependenciesの URL に置き換えます。ファイル名はhttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jarのようになります。URL の確認方法と JAR を手動でダウンロードする方法は次のとおりです。
- リポジトリに移動します。
- 最新のバージョン番号をクリックします。
JAR with dependencies fileを特定します(通常は先頭にあります)。- URL を右クリックしてコピーするか、ファイルをクリックしてダウンロードします。
インポート ツールを取得します。
wget BIGTABLE_BEAM_IMPORT_URLBIGTABLE_BEAM_IMPORT_URLは、ツールの Maven リポジトリで利用可能な最新のshaded JARの URL に置き換えます。ファイル名はhttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jarのようになります。URL の確認方法と JAR を手動でダウンロードする方法は次のとおりです。
- リポジトリに移動します。
- 最新のバージョン番号をクリックします。
- [Downloads] をクリックします。
- [shaded.jar] にカーソルを合わせます。
- URL を右クリックしてコピーするか、ファイルをクリックしてダウンロードします。
次の環境変数を設定します。
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORY以下を置き換えます。
PROJECT_ID: インスタンスが存在する Google Cloud プロジェクトINSTANCE_ID: データのインポート先の Bigtable インスタンスの識別子REGION: Bigtable インスタンス内のクラスタの一つを含むリージョン。例:northamerica-northeast2CLUSTER_NUM_NODES: Bigtable インスタンス内のノード数TRANSLATE_JAR: Maven からダウンロードしたbigtable hbase toolsJAR ファイルの名前とバージョン番号。値はbigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jarのようになります。IMPORT_JAR: Maven からダウンロードしたbigtable-beam-importJAR ファイルの名前とバージョン番号。値はbigtable-beam-import-1.24.0-shaded.jarのようになります。BUCKET_NAME: スナップショットを保存する Cloud Storage バケットの名前ZOOKEEPER_QUORUM: ツールで接続する Zookeeper ホスト(host1.myownpersonaldomain.comの形式)MIGRATION_SOURCE_DIRECTORY: 移行するデータを保持する HBase ホスト上のディレクトリ(hdfs://host1.myownpersonaldomain.com:8020/hbaseの形式)
(省略可)変数が正しく設定されていることを確認するには、
printenvコマンドを実行して、すべての環境変数を表示します。
HBase への書き込み送信を停止する
HBase テーブルのスナップショットを取得する前に、HBase クラスタへの書き込み送信を停止します。
HBase テーブルのスナップショットを作成する
HBase クラスタがデータをそれ以上取り込まなくなったら、Bigtable に移行する各テーブルのスナップショットを作成します。
最初の段階では、HBase クラスタのスナップショットのストレージ フットプリントは最小限ですが、時間の経過とともに、元のテーブルと同じサイズにまで増加する場合があります。スナップショットは CPU リソースを消費しません。
各スナップショットに一意の名前を指定して、テーブルごとに次のコマンドを実行します。
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
次のように置き換えます。
TABLE_NAME: データのエクスポート元の HBase テーブルの名前SNAPSHOT_NAME: 新しいスナップショットの名前
HBase スナップショットを Cloud Storage にエクスポートする
スナップショットを作成したら、スナップショットをエクスポートする必要があります。本番環境の HBase クラスタでエクスポート ジョブを実行する場合は、クラスタと他の HBase リソースをモニタリングして、クラスタが良好な状態を維持していることを確認します。
エクスポートするスナップショットごとに、次のコマンドを実行します。
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
SNAPSHOT_NAME は、エクスポートするスナップショットの名前に置き換えます。
ハッシュを計算してエクスポートする
次に、移行の完了後に、検証のために使用するハッシュを作成します。HashTable は HBase が提供する検証ツールで、行範囲のハッシュを計算してファイルにエクスポートします。宛先テーブルで sync-table ジョブを実行することで、ハッシュと照合され、移行されるデータの整合性を確保できます。
エクスポートしたテーブルごとに次のコマンドを実行します。
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
次のように置き換えます。
TABLE_NAME: スナップショットを作成してエクスポートした HBase テーブルの名前
目的地テーブルを作成する
次のステップでは、エクスポートしたスナップショットごとに、Bigtable インスタンスに宛先テーブルを作成します。インスタンスに対する bigtable.tables.create 権限を持つアカウントを使用します。
このガイドでは、Bigtable スキーマ変換ツールを使用して、テーブルを自動的に作成します。Bigtable スキーマと HBase スキーマが完全に一致する場合は、cbt コマンドライン ツールまたは Google Cloud コンソールでテーブルを作成できます。
Bigtable スキーマ変換ツールは、テーブル名、列ファミリー、ガベージ コレクション ポリシー、スプリットなど、HBase テーブルのスキーマをキャプチャします。次に、Bigtable に同様のテーブルを作成します。
インポートするテーブルごとに、次のコマンドを実行して HBase から Bigtable にスキーマをコピーします。
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
TABLE_NAME は、インポートする HBase テーブルの名前に置き換えます。スキーマ変換ツールは、この名前を新しい Bigtable テーブルに使用します。
必要に応じて、TABLE_NAME の代わりに、作成するテーブルをすべてキャプチャするための正規表現(「.*」など)を指定すると、このコマンドを 1 回実行するだけで済みます。
Dataflow を使用して HBase データを Bigtable にインポートする
データの移行先とするテーブルを用意したら、データをインポートして検証できます。
非圧縮テーブル
HBase テーブルが圧縮されていない場合は、移行するテーブルごとに次のコマンドを実行します。
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
次のように置き換えます。
TABLE_NAME: インポートする HBase テーブルの名前。スキーマ変換ツールは、この名前を新しい Bigtable テーブルに使用します。新しいテーブル名は使用できません。SNAPSHOT_NAME: インポートするテーブルのスナップショットに割り当てた名前
このコマンドを実行すると、ツールによって HBase スナップショットが Cloud Storage バケットに復元され、インポート ジョブが開始されます。スナップショットのサイズによっては、この復元プロセスが完了するまで数分かかることがあります。
インポートする際には、次の点に留意してください。
- データ読み込みのパフォーマンスを向上させるには、必ず
maxNumWorkersを設定してください。この値によって、Cloud Bigtable クラスタを圧迫するほどではないものの、インポート ジョブを妥当な時間内に完了できるだけの十分なコンピューティング能力を使用できるようになります。- 別のワークロードに Bigtable インスタンスを使用していない場合は、Bigtable インスタンスのノード数に 3 を掛けた数値を
maxNumWorkersに使用します。 - HBase データのインポートと同時に、別のワークロードにもこのインスタンスを使用している場合は、
maxNumWorkersの値を適度に小さくしてください。
- 別のワークロードに Bigtable インスタンスを使用していない場合は、Bigtable インスタンスのノード数に 3 を掛けた数値を
- デフォルトのワーカータイプを使用します。
- インポート中は、Bigtable インスタンスの CPU 使用率をモニタリングする必要があります。Bigtable インスタンス全体の CPU 使用率が高すぎる場合は、ノードの追加が必要になる可能性があります。クラスタが追加ノード分のパフォーマンスを発揮するまでには、最大 20 分かかることがあります。
Bigtable インスタンスのモニタリングの詳細については、モニタリングをご覧ください。
Snappy 圧縮テーブル
Snappy で圧縮されたテーブルをインポートする場合は、Dataflow パイプラインでカスタム コンテナ イメージを使用する必要があります。圧縮データを Bigtable にインポートするために使用するカスタム コンテナ イメージは、Hadoop ネイティブ圧縮ライブラリをサポートしています。Dataflow Runner v2 を使用するには、Apache Beam SDK バージョン 2.30.0 以降が必要です。また、Java 用 HBase クライアント ライブラリのバージョン 2.3.0 以降も必要です。
Snappy 圧縮テーブルをインポートするには、非圧縮テーブルに対して実行したのと同じコマンドを実行しますが、次のオプションを追加します。
--enableSnappy=true
Bigtable にインポートされたデータを検証する
インポートしたデータを検証するには、sync-table ジョブを実行する必要があります。sync-table ジョブは、Bigtable の行範囲のハッシュを計算し、それを以前に計算した HashTable の出力と照合します。
sync-table ジョブを実行するには、コマンドシェルで次のコマンドを実行します。
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
TABLE_NAME は、インポートする HBase テーブルの名前に置き換えます。
sync-table ジョブが完了したら、Dataflow ジョブの詳細ページを開き、ジョブのカスタム カウンタ セクションを確認します。インポート ジョブですべてのデータが正常にインポートされると、ranges_matched に値が表示され、ranges_not_matched の値は 0 になります。
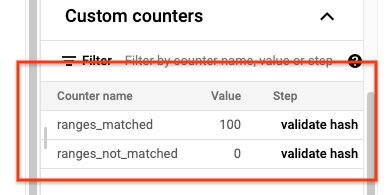
ranges_not_matched に値が表示される場合は、[ログ] ページを開き、[ワーカーログ] を選択して、[Mismatch on range] でフィルタします。機械で読み取り可能なこれらのログ出力は、sync-table outputPrefix オプションで作成した出力先の Cloud Storage に保存されています。
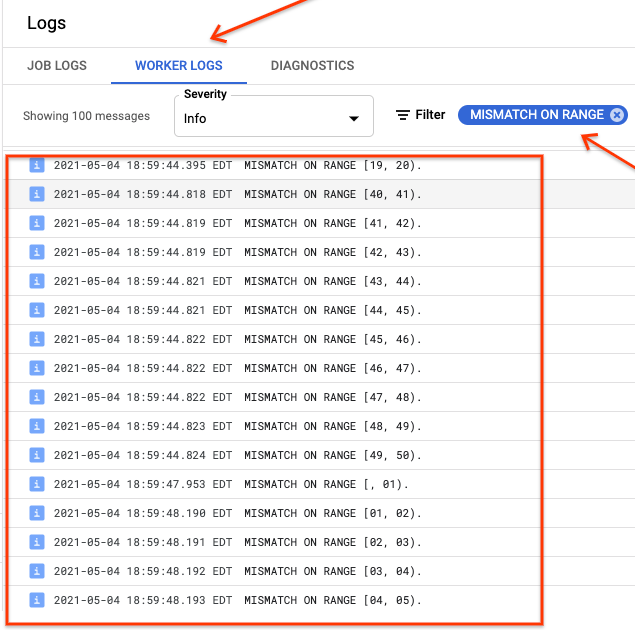
インポート ジョブを再試行するか、または、出力ファイルを読み取るスクリプトを記述して、不一致の発生場所を特定します。出力ファイルの各行は、一致しない範囲のシリアル化された JSON レコードです。
Bigtable への書き込みをルーティングする
クラスタ内の各テーブルのデータを検証したら、すべてのトラフィックが Bigtable にルーティングされるようにアプリケーションを構成し、その後、HBase クラスタを非推奨にします。
移行が完了したら、HBase インスタンスのスナップショットを削除できます。
次のステップ
- Cloud Storage に関する詳細