Migrazione da Apache Cassandra a Bigtable
Questo documento ti guida nella procedura di migrazione dei dati da Apache Cassandra a Bigtable con un'interruzione minima. Descrive come utilizzare strumenti open source, come l'adattatore proxy da Cassandra a Bigtable o il client da Cassandra a Bigtable per Java, per eseguire la migrazione. Prima di iniziare, assicurati di conoscere Bigtable per gli utenti Cassandra.
Scegliere un approccio di migrazione
Puoi eseguire la migrazione da Apache Cassandra a Bigtable utilizzando uno dei seguenti approcci:
- L'adattatore proxy da Cassandra a Bigtable ti consente di connettere applicazioni basate su Cassandra a Bigtable senza modificare i driver Cassandra. Questo approccio è ideale per le applicazioni che richiedono modifiche minime al codice.
- Il client Cassandra to Bigtable per Java ti consente di integrarti direttamente con Bigtable e sostituire i driver Cassandra. Questo approccio è ideale per le applicazioni che richiedono prestazioni e flessibilità elevate.
Adattatore proxy da Cassandra a Bigtable
L'adattatore proxy da Cassandra a Bigtable consente di connettere le applicazioni basate su Cassandra a Bigtable. L'adattatore proxy funge da interfaccia Cassandra compatibile con il cavo e consente all'applicazione di interagire con Bigtable utilizzando Cassandra Query Language (CQL). L'utilizzo dell'adattatore proxy non richiede la modifica dei driver Cassandra e le modifiche alla configurazione sono minime.
Per configurare l'adattatore proxy, vedi Adattatore proxy da Cassandra a Bigtable.
Per scoprire quali versioni di Cassandra supportano l'adattatore proxy, consulta Versioni di Cassandra supportate.
Limitazioni
L'adattatore proxy da Cassandra a Bigtable fornisce un supporto limitato per determinati tipi di dati, funzioni, query e clausole. Per ulteriori informazioni, vedi Cassandra to Bigtable Proxy - Limitations.
Keyspace Cassandra
Uno spazio delle chiavi Cassandra archivia le tabelle e gestisce le risorse in modo simile a un'istanza Bigtable. L'adattatore proxy da Cassandra a Bigtable gestisce la denominazione dello spazio delle chiavi in modo trasparente, in modo che tu possa eseguire query utilizzando gli stessi spazi delle chiavi. Tuttavia, devi creare una nuova istanza Bigtable per ottenere il raggruppamento logico delle tue tabelle. Devi anche configurare la replica Bigtable separatamente.
Supporto DDL
L'adattatore proxy da Cassandra a Bigtable supporta le operazioni DDL (Data Definition Language). Le operazioni DDL ti consentono di creare e gestire tabelle direttamente tramite i comandi CQL. Ti consigliamo questo approccio per configurare lo schema perché è simile a SQL, ma non devi definire lo schema nei file di configurazione ed eseguire script per creare tabelle.
I seguenti esempi mostrano come l'adattatore proxy da Cassandra a Bigtable supporta le operazioni DDL:
Per creare una tabella Cassandra utilizzando CQL, esegui il comando
CREATE TABLE:CREATE TABLE keyspace.table ( id bigint, name text, age int, PRIMARY KEY ((id), name) );Per aggiungere una nuova colonna alla tabella, esegui il comando
ALTER TABLE:ALTER TABLE keyspace.table ADD email text;Per eliminare una tabella, esegui il comando
DROP TABLE:DROP TABLE keyspace.table;
Per ulteriori informazioni, consulta Supporto DDL per la creazione di schemi (metodo consigliato).
Supporto DML
L'adattatore proxy da Cassandra a Bigtable supporta le operazioni DML (Data Manipulation Language) come INSERT, DELETE, UPDATE e SELECT.
Per eseguire le query DML non elaborate, tutti i valori, tranne quelli numerici, devono essere racchiusi tra virgolette singole, come mostrato negli esempi seguenti:
SELECT * FROM keyspace.table WHERE name='john doe';INSERT INTO keyspace.table (id, name) VALUES (1, 'john doe');
Eseguire la migrazione senza tempi di inattività
Puoi utilizzare l'adattatore proxy da Cassandra a Bigtable con lo strumento proxy Zero Downtime Migration (ZDM) e lo strumento Cassandra Data Migrator per eseguire la migrazione dei dati con tempi di inattività minimi.
Il seguente diagramma mostra i passaggi per la migrazione da Cassandra a Bigtable utilizzando l'adattatore proxy:
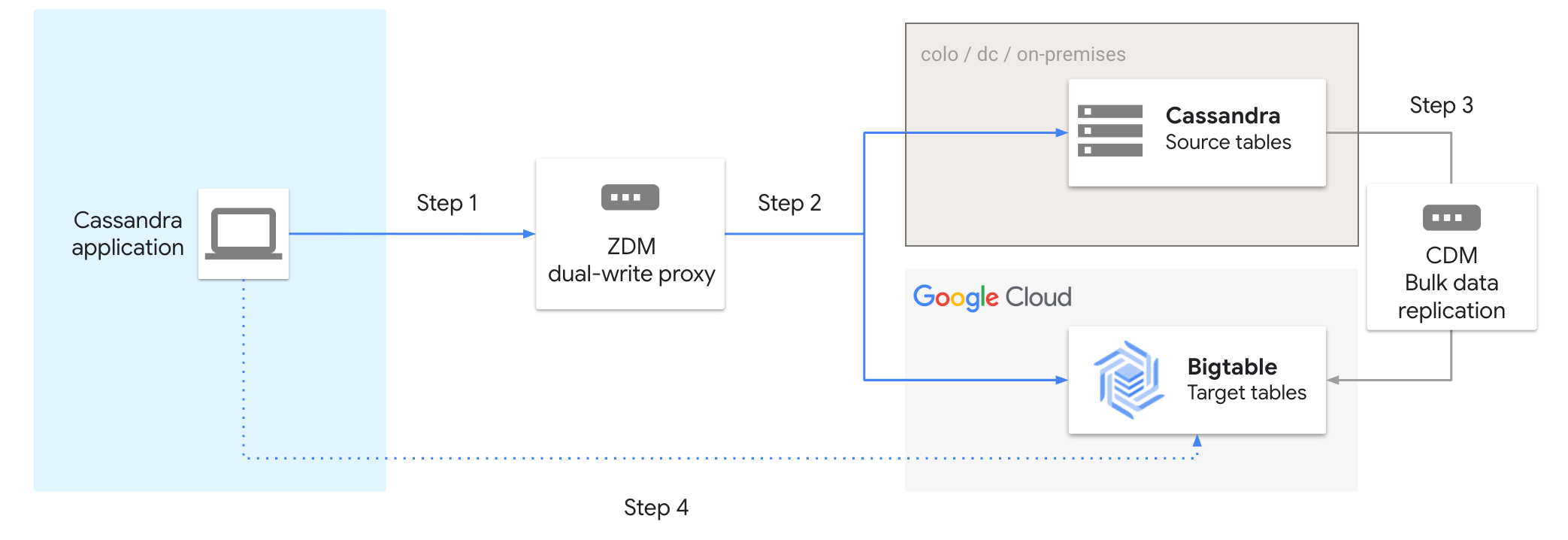
Per eseguire la migrazione di Cassandra a Bigtable:
- Collega l'applicazione Cassandra allo strumento proxy ZDM.
- Attiva la doppia scrittura in Cassandra e Bigtable.
- Sposta i dati in blocco utilizzando lo strumento Cassandra data migrator.
- Convalida la migrazione. Una volta convalidata, puoi terminare la connessione a Cassandra e connetterti direttamente a Bigtable.
Quando utilizzi l'adattatore proxy con lo strumento proxy ZDM, sono supportate le seguenti funzionalità di migrazione:
- Scritture doppie: mantieni la disponibilità dei dati durante la migrazione
- Letture asincrone: scalare ed eseguire test di stress dell'istanza Bigtable
- Verifica e generazione di report automatici sui dati: garantisci l'integrità dei dati durante l'intero processo
- Mappatura dei dati: mappa i campi e i tipi di dati in modo che soddisfino gli standard di produzione
Per esercitarti nella migrazione da Cassandra a Bigtable, consulta il codelab Migrazione da Cassandra a Bigtable con un proxy dual-write.
Client Cassandra a Bigtable per Java
Puoi eseguire l'integrazione direttamente con Bigtable e sostituire i driver Cassandra. La libreria client Cassandra to Bigtable per Java ti consente di integrare le applicazioni Java basate su Cassandra con Bigtable utilizzando CQL.
Per istruzioni sulla creazione della libreria e sull'inclusione della dipendenza nel codice dell'applicazione, consulta Cassandra to Bigtable Client per Java.
L'esempio seguente mostra come configurare l'applicazione con il client Cassandra a Bigtable per Java:
Altri strumenti open source di Cassandra
Grazie alla compatibilità del proxy adapter da Cassandra a Bigtable con CQL, puoi utilizzare strumenti aggiuntivi nell'ecosistema open source di Cassandra. Questi strumenti includono:
- Cqlsh: La shell CQL ti consente di connetterti direttamente a Bigtable tramite l'adattatore proxy. Puoi utilizzarlo per il debug e le ricerche rapide di dati utilizzando CQL.
- Cassandra Data Migrator (CDM): questo strumento basato su Spark è adatto per la migrazione di grandi volumi (fino a miliardi di righe) di dati storici. Lo strumento fornisce funzionalità di convalida, report sulle differenze e riproduzione ed è completamente compatibile con l'adattatore proxy.