Bermigrasi dari DynamoDB ke Bigtable
Bigtable dan DynamoDB adalah penyimpanan nilai kunci terdistribusi yang dapat mendukung jutaan kueri per detik (QPS), menyediakan penyimpanan yang dapat diskalakan hingga petabyte data, dan mentoleransi kegagalan node.
Dokumen ini ditujukan bagi developer DynamoDB dan administrator database yang ingin bermigrasi ke Bigtable. Hal ini juga berguna saat Anda ingin mendesain aplikasi untuk digunakan dengan Bigtable sebagai datastore.
Untuk memulai, gunakan alat migrasi yang disediakan Google yang membantu Anda bermigrasi dari DynamoDB ke Bigtable. Halaman ini menjelaskan alat migrasi, membandingkan kedua sistem database, dan menjelaskan arsitektur dasar serta detail interaksi yang berbeda dan penting untuk dipahami sebelum melakukan migrasi.
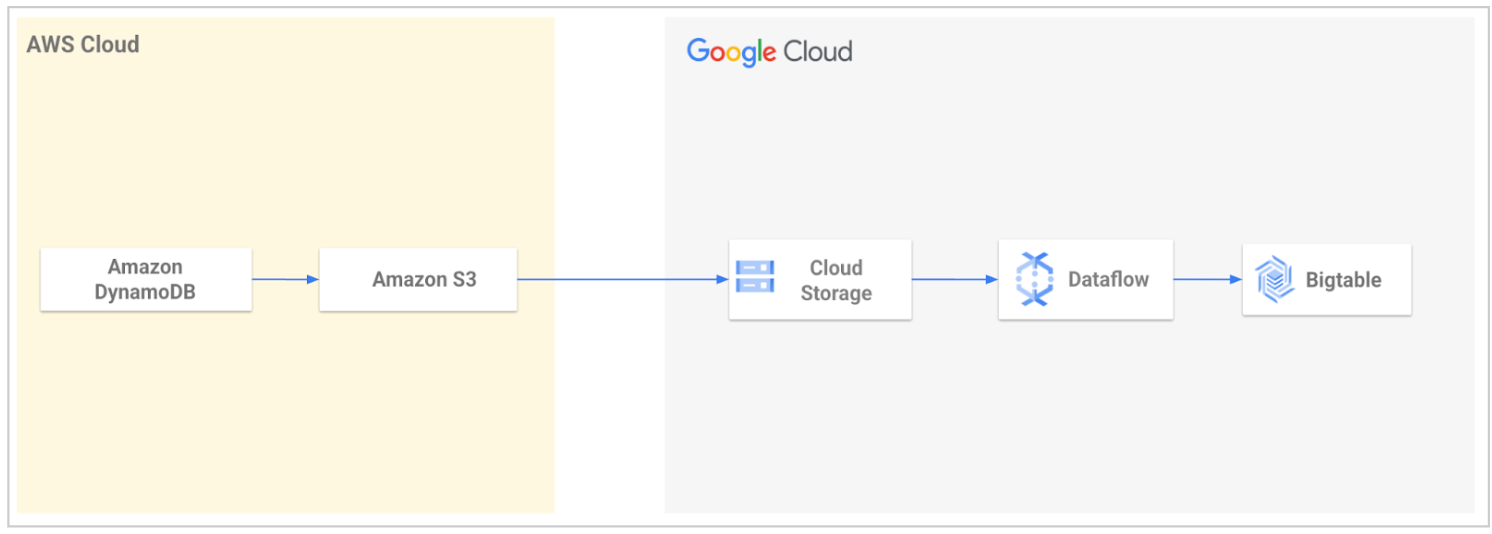
Mulai menggunakan alat migrasi DynamoDB ke Bigtable
Alat migrasi open source disediakan oleh Google Cloud Professional Services untuk menyederhanakan migrasi data dari DynamoDB ke Bigtable. Alat ini mengotomatiskan proses mengimpor data Anda ke Google Cloud , lalu memuatnya ke Bigtable.
Dengan menggunakan alat ini, Anda dapat mengekspor tabel DynamoDB, lalu mentransfernya ke Cloud Storage. Alat ini membaca file yang diekspor dari bucket Cloud Storage Anda dan menggunakan template Dataflow untuk mengubah data agar kompatibel dengan Bigtable. Transformasi ini mencakup pemetaan atribut DynamoDB ke baris Bigtable. Tugas Dataflow kemudian menulis data yang telah diubah ke tabel Bigtable Anda.
Untuk mengetahui informasi selengkapnya atau memulai, lihat Utilitas Migrasi DynamoDB ke Bigtable.
Perbandingan DynamoDB dan Bigtable
Bagian ini membahas persamaan dan perbedaan antara DynamoDB dan Bigtable.
Bidang kontrol
Di DynamoDB dan Bigtable, bidang kontrol memungkinkan Anda mengonfigurasi kapasitas dan menyiapkan serta mengelola resource. DynamoDB adalah produk serverless, dan tingkat interaksi tertinggi dengan DynamoDB adalah tingkat tabel. Dalam mode kapasitas yang disediakan, di sinilah Anda menyediakan unit permintaan baca dan tulis, memilih wilayah dan replikasi, serta mengelola cadangan. Bigtable bukan produk serverless; Anda harus membuat instance dengan satu atau beberapa cluster, yang kapasitasnya ditentukan oleh jumlah node yang dimilikinya. Untuk mengetahui detail tentang resource ini, lihat Instance, cluster, dan node.
Tabel berikut membandingkan resource bidang kontrol untuk DynamoDB dan Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tabel: Kumpulan item dengan kunci utama yang ditentukan. Tabel memiliki setelan untuk pencadangan, replikasi, dan kapasitas. | Instance: Sekelompok cluster Bigtable
di berbagai Google Cloud zona atau region, yang di antaranya terjadi replikasi
dan perutean koneksi. Kebijakan replikasi ditetapkan di tingkat instance. Cluster: Sekelompok node di zona geografis Google Cloud yang sama, idealnya ditempatkan bersama dengan server aplikasi Anda karena alasan latensi dan replikasi. Kapasitas dikelola dengan menyesuaikan jumlah node di setiap cluster. Tabel: Pengorganisasian nilai logis yang diindeks oleh kunci baris. Cadangan dikontrol di tingkat tabel. |
Unit kapasitas baca (RCU) dan unit kapasitas tulis (WCU):
Unit yang memungkinkan pembacaan atau penulisan per detik dengan ukuran
payload tetap. Anda akan dikenai biaya untuk unit baca atau tulis untuk setiap
operasi dengan ukuran payload yang lebih besar.Operasi UpdateItem menggunakan kapasitas penulisan yang digunakan untuk
ukuran terbesar item yang diperbarui – baik sebelum atau setelah pembaruan –
meskipun pembaruan melibatkan subset atribut item. |
Node: Resource komputasi virtual yang bertanggung jawab untuk membaca dan menulis data. Jumlah node yang dimiliki cluster
diterjemahkan ke batas throughput untuk pembacaan, penulisan, dan pemindaian. Anda dapat
menyesuaikan jumlah node, bergantung pada kombinasi
target latensi, jumlah permintaan, dan ukuran payload. Node SSD memberikan throughput yang sama untuk operasi baca dan tulis, tidak seperti perbedaan signifikan antara RCU dan WCU. Untuk mengetahui informasi selengkapnya, lihat Performa untuk beban kerja standar. |
| Partisi: Blok baris yang berdekatan, didukung oleh
solid state drive (SSD) yang ditempatkan bersama dengan node. Setiap partisi tunduk pada batas ketat 1.000 WCU, 3.000 RCU, dan data 10 GB. |
Tablet: Blok baris berdekatan yang didukung oleh
media penyimpanan pilihan (SSD atau HDD). Tabel di-sharding menjadi tablet untuk menyeimbangkan beban kerja. Tablet tidak disimpan di node di Bigtable, tetapi di sistem file terdistribusi Google, yang memungkinkan pendistribusian ulang data yang cepat saat melakukan penskalaan, dan yang memberikan daya tahan tambahan dengan mempertahankan beberapa salinan. |
| Tabel global: Cara untuk meningkatkan ketersediaan dan ketahanan data Anda dengan otomatis menyebarkan perubahan data di beberapa region. | Replikasi: Cara untuk meningkatkan ketersediaan dan ketahanan data Anda dengan menyebarkan perubahan data secara otomatis di beberapa region atau beberapa zona dalam region yang sama. |
| Tidak berlaku (T/A) | Profil aplikasi: Setelan yang menginstruksikan Bigtable cara merutekan panggilan API klien ke cluster yang sesuai dalam instance. Anda juga dapat menggunakan profil aplikasi sebagai tag untuk menyegmentasikan metrik untuk atribusi. |
Replikasi geografis
Replikasi digunakan untuk mendukung persyaratan pelanggan berikut:
- Ketersediaan tinggi untuk kelangsungan bisnis jika terjadi kegagalan di zona atau region.
- Menempatkan data layanan Anda dekat dengan pengguna akhir untuk penayangan dengan latensi rendah di mana pun mereka berada di dunia.
- Isolasi workload saat Anda perlu menerapkan workload batch di satu cluster dan mengandalkan replikasi ke cluster penayangan.
Bigtable mendukung cluster yang direplikasi di sebanyak mungkin zona yang tersedia di hingga 8 region tempat Bigtable tersedia. Google Cloud Sebagian besar region memiliki tiga zona. Untuk mengetahui informasi selengkapnya, lihat Region dan zona.
Bigtable otomatis mereplikasi data di seluruh cluster dalam topologi multi-primer, yang berarti Anda dapat membaca dan menulis ke cluster mana pun. Replikasi Bigtable memiliki konsistensi tertunda. Untuk mengetahui detailnya, lihat Ringkasan replikasi.
DynamoDB menyediakan tabel global untuk mendukung replikasi tabel di beberapa region. Tabel global bersifat multi-primer dan direplikasi secara otomatis di seluruh region. Replikasi memiliki konsistensi tertunda.
Tabel berikut mencantumkan konsep replikasi dan menjelaskan ketersediaannya di DynamoDB dan Bigtable.
| Properti | DynamoDB | Bigtable |
|---|---|---|
| Replikasi multi-primer | Ya. Anda dapat membaca dan menulis ke tabel global mana pun. |
Ya. Anda dapat membaca dan menulis ke cluster Bigtable mana pun. |
| Model konsistensi | Konsistensi tertunda. Konsistensi read-your-write di tingkat regional untuk tabel global. |
Konsistensi tertunda. Konsistensi read-your-write di tingkat cluster untuk semua tabel asalkan Anda mengirim operasi baca dan tulis ke cluster yang sama. |
| Latensi replikasi | Tidak ada perjanjian tingkat layanan (SLA). Detik |
Tidak ada SLA. Detik |
| Perincian konfigurasi | Tingkat tabel. | Tingkat instance. Sebuah instance dapat berisi beberapa tabel. |
| Penerapan | Buat tabel global dengan replika tabel di setiap region yang dipilih. Tingkat regional. Replikasi otomatis di seluruh replika dengan mengonversi tabel menjadi tabel global. Tabel harus mengaktifkan DynamoDB Streams, dengan stream yang berisi gambar item baru dan lama. Hapus region untuk menghapus tabel global di region tersebut. |
Membuat instance dengan lebih dari satu cluster. Replikasi bersifat otomatis di seluruh cluster dalam instance tersebut. Tingkat zona. Menambahkan dan menghapus cluster dari instance Bigtable. |
| Opsi replikasi | Per tabel. | Per instance. |
| Pemilihan rute dan ketersediaan traffic | Traffic dirutekan ke replika geografis terdekat. Jika terjadi kegagalan, Anda menerapkan logika bisnis kustom untuk menentukan kapan harus mengalihkan permintaan ke region lain. |
Gunakan profil aplikasi untuk mengonfigurasi kebijakan perutean traffic cluster. Gunakan pemilihan rute multi-cluster untuk merutekan traffic secara otomatis ke cluster responsif terdekat. Jika terjadi kegagalan, Bigtable mendukung failover otomatis antar-cluster untuk HA. |
| Penskalaan | Kapasitas tulis dalam unit permintaan tulis yang direplikasi (R-WRU) disinkronkan di seluruh replika. Kapasitas baca dalam unit kapasitas baca yang direplikasi (R-RCU) adalah per replika. |
Anda dapat menskalakan cluster secara independen dengan menambahkan atau menghapus node dari setiap cluster yang direplikasi sesuai kebutuhan. |
| Biaya | R-WRU berharga 50% lebih mahal daripada WRU reguler. | Anda akan ditagih untuk node dan penyimpanan setiap cluster. Tidak ada biaya replikasi jaringan untuk replikasi regional di seluruh zona. Biaya dikenakan saat replikasi dilakukan di seluruh wilayah atau benua. |
| SLA | 99,999% | 99,999% |
Bidang data
Tabel berikut membandingkan konsep model data untuk DynamoDB dan Bigtable. Setiap baris dalam tabel menjelaskan fitur serupa. Misalnya, item di DynamoDB mirip dengan baris di Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Item: Sekelompok atribut yang dapat diidentifikasi secara unik di antara semua item lainnya berdasarkan kunci utamanya. Ukuran maksimum yang diizinkan adalah 400 KB. | Baris: Satu entity yang diidentifikasi oleh kunci baris. Ukuran maksimum yang diizinkan adalah 256 MB. |
| T/A | Grup kolom: Ruang nama yang ditentukan pengguna yang mengelompokkan kolom. |
| Atribut: Pengelompokan nama dan nilai. Nilai atribut dapat berupa skalar, set, atau jenis dokumen. Tidak ada batas eksplisit pada ukuran atribut itu sendiri. Namun, karena setiap item dibatasi hingga 400 KB, untuk item yang hanya memiliki satu atribut, atribut dapat berukuran hingga 400 KB dikurangi ukuran yang ditempati oleh nama atribut. | Penentu kolom: ID unik dalam
grup kolom untuk kolom. ID lengkap kolom dinyatakan sebagai column-family:column-qualifier. Penentu kolom diurutkan secara leksikografis dalam grup kolom. Ukuran maksimum yang diizinkan untuk pengontrol kualitas kolom adalah 16 KB. Sel: Sel menyimpan data untuk baris, kolom, dan stempel waktu tertentu. Sel berisi satu nilai yang dapat berukuran hingga 100 MB. |
| Kunci utama: ID unik untuk item dalam tabel. Kunci ini dapat berupa kunci partisi atau kunci gabungan. Kunci partisi: Kunci utama sederhana, yang terdiri dari satu atribut. Ini menentukan partisi fisik tempat item berada. Ukuran maksimum yang diizinkan adalah 2 KB. Kunci pengurutan: Kunci yang menentukan urutan baris dalam partisi. Ukuran maksimum yang diizinkan adalah 1 KB. Kunci gabungan: Kunci utama yang terdiri dari dua properti, yaitu kunci partisi dan kunci pengurutan atau atribut rentang. |
Kunci baris: ID unik untuk item dalam tabel.
Biasanya direpresentasikan oleh gabungan nilai dan pembatas.
Ukuran maksimum yang diizinkan adalah 4 KB. Penentu kolom dapat digunakan untuk memberikan perilaku yang setara dengan kunci pengurutan DynamoDB. Kunci komposit dapat dibuat menggunakan kunci baris dan penentu kolom yang digabungkan. Untuk mengetahui detail selengkapnya, lihat contoh terjemahan skema di bagian Desain skema dalam dokumen ini. |
| Waktu aktif: Stempel waktu per item menentukan kapan item tidak lagi diperlukan. Setelah tanggal dan waktu stempel waktu yang ditentukan, item akan dihapus dari tabel Anda tanpa menggunakan throughput tulis. | Pengumpulan sampah: Stempel waktu per sel menentukan kapan item tidak lagi diperlukan. Pengumpulan sampah menghapus item yang sudah tidak berlaku selama proses latar belakang yang disebut pemadatan. Kebijakan pengumpulan sampah ditetapkan di tingkat family kolom dan dapat menghapus item tidak hanya berdasarkan usianya, tetapi juga sesuai dengan jumlah versi yang ingin dipertahankan pengguna. Anda tidak perlu mengakomodasi kapasitas untuk pemadatan saat menentukan ukuran cluster. |
| Indeks sekunder global: Tabel yang berisi atribut yang dipilih dari tabel dasar, yang diatur oleh kunci utama yang berbeda dari tabel tersebut. Kunci indeks tidak perlu menyertakan atribut kunci apa pun dari tabel. Tidak harus memiliki skema kunci yang sama dengan tabel. DynamoDB memperbarui indeks sekunder global secara asinkron. | Indeks sekunder asinkron: Untuk membuat kueri data yang sama menggunakan pola atau atribut penelusuran yang berbeda, Anda dapat membuat indeks sekunder asinkron. Jenis indeks ini berisi atribut yang dipilih dari tabel dasar. Atribut ini diatur berdasarkan kunci yang berbeda dari kunci tabel itu sendiri. Perilakunya mirip dengan indeks sekunder global DynamoDB. |
Operasi
Operasi bidang data memungkinkan Anda melakukan tindakan buat, baca, perbarui, dan hapus (CRUD) pada data dalam tabel. Tabel berikut membandingkan operasi bidang data serupa untuk DynamoDB dan Bigtable.
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsBigtable memperlakukan operasi tulis sebagai operasi upsert. |
UpdateItem
|
Bigtable memperlakukan operasi tulis sebagai operasi upsert. |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows` (range, prefix, reverse scan)Bigtable mendukung pemindaian yang efisien berdasarkan awalan kunci baris, pola ekspresi reguler, atau rentang kunci baris maju atau mundur. |
Jenis data
Bigtable dan DynamoDB tidak memiliki skema. Kolom dapat ditentukan pada waktu penulisan tanpa penegakan di seluruh tabel untuk keberadaan kolom atau jenis data. Demikian pula, jenis data kolom atau atribut tertentu dapat berbeda dari satu baris atau item ke item lainnya. Namun, DynamoDB dan Bigtable API menangani jenis data dengan cara yang berbeda.
Setiap permintaan penulisan DynamoDB mencakup definisi jenis untuk setiap atribut, yang ditampilkan dengan respons untuk permintaan baca.
Bigtable memperlakukan semuanya sebagai byte dan mengharapkan kode klien mengetahui jenis dan encoding sehingga klien dapat mengurai respons dengan benar. Pengecualian adalah operasi increment, yang menafsirkan nilai sebagai bilangan bulat bertanda big-endian 64-bit.
Tabel berikut membandingkan perbedaan jenis data antara DynamoDB dan Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Jenis skalar: Ditampilkan sebagai token deskriptor jenis data dalam respons server. | Byte: Byte dikonversi ke jenis yang diinginkan dalam aplikasi klien. Increment menafsirkan nilai sebagai bilangan bulat 64-bit bertanda big-endian |
| Set: Kumpulan elemen unik yang tidak diurutkan. | Grup kolom: Anda dapat menggunakan penentu kolom sebagai nama anggota set dan untuk setiap penentu kolom, berikan satu byte 0 sebagai nilai sel. Set anggota diurutkan secara leksikografis dalam kolom keluarga mereka. |
| Peta: Kumpulan pasangan nilai kunci yang tidak diurutkan dengan kunci unik. | Grup kolom Gunakan penentu kolom sebagai kunci peta dan nilai sel untuk nilai. Kunci peta diurutkan secara leksikografis. |
| Daftar: Kumpulan item yang diurutkan. | Penentu kolom Gunakan stempel waktu penyisipan untuk mencapai perilaku list_append yang setara, kebalikan dari stempel waktu penyisipan untuk penambahan di awal. |
Desain skema
Pertimbangan penting dalam desain skema adalah cara data disimpan. Perbedaan utama antara Bigtable dan DynamoDB adalah cara keduanya menangani hal berikut:
- Pembaruan pada nilai tunggal
- Penyortiran data
- Pembuatan versi data
- Penyimpanan nilai besar
Pembaruan pada nilai tunggal
Operasi UpdateItem di DynamoDB menggunakan kapasitas penulisan untuk ukuran item "sebelum" dan "sesudah" yang lebih besar, meskipun pembaruan melibatkan subset atribut item. Artinya, di DynamoDB, Anda dapat menempatkan kolom yang sering diperbarui dalam baris terpisah, meskipun secara logis kolom tersebut berada dalam baris yang sama dengan kolom lainnya.
Bigtable dapat memperbarui sel seefisien mungkin, baik sel tersebut merupakan satu-satunya kolom dalam baris tertentu atau salah satu dari ribuan kolom. Untuk mengetahui detailnya, lihat Penulisan sederhana.
Penyortiran data
DynamoDB melakukan hashing dan mendistribusikan kunci partisi secara acak, sedangkan Bigtable menyimpan baris dalam urutan leksikografis berdasarkan kunci baris dan menyerahkan hashing kepada pengguna.
Distribusi kunci acak tidak optimal untuk semua pola akses. Hal ini mengurangi risiko rentang baris panas, tetapi membuat pola akses yang melibatkan pemindaian yang melintasi batas partisi menjadi mahal dan tidak efisien. Pemindaian tanpa batas ini umum, terutama untuk kasus penggunaan yang memiliki dimensi waktu.
Menangani jenis pola akses ini — pemindaian yang melintasi batas partisi — memerlukan indeks sekunder di DynamoDB, tetapi tidak di Bigtable. Meskipun Anda dapat mendesain kunci baris leksikografis di Bigtable untuk menangani banyak pola pemindaian secara efisien, Bigtable juga mendukung indeks sekunder asinkron yang Anda terapkan sebagai tampilan terwujud berkelanjutan untuk menyediakan pencarian yang efisien dan konsisten pada akhirnya untuk pola kueri alternatif. Demikian pula, di DynamoDB, operasi kueri dan pemindaian dibatasi hingga 1 MB data yang dipindai, yang memerlukan penomoran halaman di luar batas ini. Bigtable tidak memiliki batasan tersebut.
Meskipun memiliki kunci partisi yang didistribusikan secara acak, DynamoDB masih dapat memiliki partisi panas jika kunci partisi yang dipilih tidak mendistribusikan traffic secara merata sehingga memengaruhi throughput secara negatif. Untuk mengatasi masalah ini, DynamoDB menyarankan penulisan-sharding, yang membagi penulisan secara acak di beberapa nilai kunci partisi logis.
Untuk menerapkan pola desain ini, Anda perlu membuat angka acak dari set tetap (misalnya, 1 hingga 10), lalu menggunakan angka ini sebagai kunci partisi logis. Karena Anda mengacak kunci partisi, penulisan ke tabel akan didistribusikan secara merata di semua nilai kunci partisi.
Bigtable menyebut prosedur ini sebagai pengasinan kunci, dan ini dapat menjadi cara yang efektif untuk menghindari tablet panas.
Pembuatan versi data
Setiap sel Bigtable memiliki stempel waktu, dan stempel waktu terbaru selalu menjadi nilai default untuk kolom tertentu. Kasus penggunaan umum untuk stempel waktu adalah pemberian versi — menulis sel baru ke kolom yang dibedakan dari versi data sebelumnya untuk baris dan kolom tersebut berdasarkan stempel waktunya.
DynamoDB tidak memiliki konsep tersebut dan memerlukan desain skema yang kompleks untuk mendukung pembuatan versi. Pendekatan ini melibatkan pembuatan dua salinan setiap item:
satu salinan dengan awalan nomor versi nol, seperti v0_, di awal
kunci pengurutan, dan salinan lainnya dengan awalan nomor versi satu, seperti
v1_. Setiap kali item diperbarui, Anda menggunakan awalan versi yang lebih tinggi berikutnya di
kunci pengurutan versi yang diperbarui, dan menyalin konten yang diperbarui ke dalam item
dengan awalan versi nol. Hal ini memastikan bahwa versi terbaru dari item apa pun dapat ditemukan menggunakan awalan nol. Strategi ini tidak hanya memerlukan
logika sisi aplikasi untuk dipertahankan, tetapi juga membuat penulisan data menjadi sangat mahal dan
lambat, karena setiap penulisan memerlukan pembacaan nilai sebelumnya ditambah dua
penulisan.
Transaksi multi-baris versus kapasitas baris besar
Bigtable tidak mendukung transaksi multi-baris. Namun, karena memungkinkan Anda menyimpan baris yang jauh lebih besar daripada item di DynamoDB, Anda sering kali dapat memperoleh transaksionalitas yang diinginkan dengan mendesain skema untuk mengelompokkan item yang relevan berdasarkan kunci baris bersama. Untuk contoh yang menggambarkan pendekatan ini, lihat Pola desain tabel tunggal.
Menyimpan nilai besar
Karena item DynamoDB, yang analog dengan baris Bigtable, dibatasi hingga 400 KB, penyimpanan nilai besar memerlukan pemisahan nilai di seluruh item atau penyimpanan di media lain seperti S3. Kedua pendekatan ini menambah kompleksitas pada aplikasi Anda. Sebaliknya, sel Bigtable dapat menyimpan hingga 100 MB, dan baris Bigtable dapat mendukung hingga 256 MB.
Contoh terjemahan skema
Contoh di bagian ini menerjemahkan skema dari DynamoDB ke Bigtable dengan mempertimbangkan perbedaan desain skema kunci.
Memigrasikan skema dasar
Katalog produk adalah contoh yang baik untuk menunjukkan pola key-value dasar. Berikut adalah tampilan skema tersebut di DynamoDB.
| Kunci Utama | Atribut | |||
|---|---|---|---|---|
| Kunci partisi | Kunci pengurutan | Deskripsi | Harga | Thumbnail |
| topi | fedoras#brandA | Dibuat dari wol premium… | 30 | https://storage… |
| topi | fedoras#brandB | Kanvas tahan air yang tahan lama dibuat untuk.. | 28 | https://storage… |
| topi | newsboy#brandB | Tambahkan sentuhan pesona vintage pada penampilan sehari-hari Anda. | 25 | https://storage… |
| sepatu | sneakers#brandA | Tampil penuh gaya dan nyaman dengan… | 40 | https://storage… |
| sepatu | sneakers#brandB | Fitur klasik dengan bahan kontemporer… | 50 | https://storage… |
Untuk tabel ini, pemetaan dari DynamoDB ke Bigtable sangatlah mudah: Anda mengonversi kunci utama gabungan DynamoDB menjadi kunci baris gabungan Bigtable. Anda membuat satu grup kolom (SKU) yang berisi set kolom yang sama.
| SKU | |||
|---|---|---|---|
| Kunci baris | Deskripsi | Harga | Thumbnail |
| topi#fedora#brandA | Dibuat dari wol premium… | 30 | https://storage… |
| topi#fedora#brandB | Kanvas tahan air yang tahan lama dibuat untuk.. | 28 | https://storage… |
| topi#newsboy#brandB | Tambahkan sentuhan pesona vintage pada penampilan sehari-hari Anda. | 25 | https://storage… |
| sepatu#sneaker#brandA | Tampil penuh gaya dan nyaman dengan… | 40 | https://storage… |
| sepatu#sepatu kets#brandB | Fitur klasik dengan bahan kontemporer… | 50 | https://storage… |
Pola desain tabel tunggal
Pola desain satu tabel menggabungkan beberapa tabel dalam database relasional menjadi satu tabel di DynamoDB. Anda dapat menggunakan pendekatan dalam contoh sebelumnya dan menduplikasi skema ini apa adanya di Bigtable. Namun, sebaiknya atasi masalah skema dalam prosesnya.
Dalam skema ini, kunci partisi berisi ID unik untuk video, yang membantu mengelompokkan semua atribut yang terkait dengan video tersebut untuk akses yang lebih cepat. Mengingat batasan ukuran item DynamoDB, Anda tidak dapat memasukkan komentar teks bebas dalam jumlah tak terbatas dalam satu baris. Oleh karena itu, kunci pengurutan dengan pola
VideoComment#reverse-timestamp digunakan untuk membuat setiap komentar menjadi baris terpisah
dalam partisi, yang diurutkan dalam urutan kronologis terbalik.
Asumsikan video ini memiliki 500 komentar dan pemiliknya ingin menghapus video tersebut. Artinya, semua komentar dan atribut video juga harus dihapus. Untuk melakukannya di DynamoDB, Anda harus memindai semua kunci dalam partisi ini, lalu mengeluarkan beberapa permintaan penghapusan, dengan melakukan iterasi melalui setiap kunci. DynamoDB mendukung transaksi multi-baris, tetapi permintaan penghapusan ini terlalu besar untuk dilakukan dalam satu transaksi.
| Kunci Utama | Atribut | |||
|---|---|---|---|---|
| Kunci partisi | Kunci pengurutan | UploadDate | Format | |
| 0123 | Video | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | Konten | |||
| Saya sangat menyukainya. Efek khusus sangat mengagumkan. | ||||
| VideoComment#86751345 | Konten | |||
| Sepertinya ada gangguan audio pada 1:05. | ||||
| VideoStatsLikes | Jumlah | |||
| 3 | ||||
| VideoStatsViews | Jumlah | |||
| 156 | ||||
| 0124 | Video | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | Konten | |||
| Saya membagikan ini kepada semua teman saya. | ||||
| VideoComment#87616471 | Konten | |||
| Gaya ini mengingatkan saya pada seorang sutradara film, tetapi saya tidak bisa mengingatnya. | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
Ubah skema ini saat Anda melakukan migrasi sehingga Anda dapat menyederhanakan kode dan membuat permintaan data lebih cepat dan lebih murah. Baris Bigtable memiliki kapasitas yang jauh lebih besar daripada item DynamoDB dan dapat menangani sejumlah besar komentar. Untuk menangani kasus ketika video mendapatkan jutaan komentar, Anda dapat menetapkan kebijakan pengumpulan sampah agar hanya menyimpan sejumlah tetap komentar terbaru.
Karena penghitung dapat diperbarui tanpa overhead untuk memperbarui seluruh baris, Anda juga tidak perlu membaginya. Anda tidak perlu menggunakan kolom UploadDate atau menghitung stempel waktu terbalik dan menjadikannya sebagai kunci pengurutan, karena stempel waktu Bigtable memberikan komentar yang diurutkan secara terbalik kronologis secara otomatis. Hal ini menyederhanakan skema secara signifikan, dan jika video dihapus, Anda dapat menghapus baris video secara transaksional, termasuk semua komentar, dalam satu permintaan.
Terakhir, karena kolom di Bigtable diurutkan secara leksikografis, sebagai pengoptimalan, Anda dapat mengganti nama kolom sedemikian rupa sehingga memungkinkan pemindaian rentang cepat – dari properti video hingga N komentar terbaru teratas – dalam satu permintaan baca, yang sebaiknya Anda lakukan saat video dimuat. Kemudian, Anda dapat melihat-lihat komentar lainnya saat penonton men-scroll.
| Atribut | ||||
|---|---|---|---|---|
| Kunci baris | Format | Suka | Tabel Virtual | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | Saya sangat menyukainya. Efek khusus sangat mengagumkan. @
2023-09-10T19:01:15 Sepertinya ada gangguan audio pada 1:05. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | Gaya ini mengingatkan saya pada seorang sutradara film, tetapi saya tidak bisa mengingatnya. @2023-10-12T07:08:51 | |
Pola desain daftar ketetanggaan
Pertimbangkan versi desain ini yang sedikit berbeda, yang sering disebut DynamoDB sebagai pola desain daftar kebertetanggaan.
| Kunci Utama | Atribut | |||
|---|---|---|---|---|
| Kunci partisi | Kunci pengurutan | DateCreated | Detail | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
Dalam tabel ini, kunci pengurutan tidak didasarkan pada waktu, melainkan pada ID pembayaran, sehingga Anda dapat menggunakan pola kolom lebar yang berbeda dan membuat ID tersebut menjadi kolom terpisah di Bigtable, dengan manfaat yang serupa dengan contoh sebelumnya.
| Invoice | Pembayaran | |||
|---|---|---|---|---|
| kunci baris | Detail | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| kunci baris | Detail | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
Seperti yang dapat Anda lihat dalam contoh sebelumnya, dengan desain skema yang tepat, model kolom lebar Bigtable dapat sangat efektif dan mendukung banyak kasus penggunaan yang memerlukan transaksi multi-baris yang mahal, pengindeksan sekunder, atau perilaku cascade saat penghapusan di database lain.
Langkah berikutnya
- Baca tentang desain skema Bigtable.
- Pelajari emulator Bigtable.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.