Migrazione da DynamoDB a Bigtable
Bigtable e DynamoDB sono archivi chiave-valore distribuiti che possono supportare milioni di query al secondo (QPS), fornire spazio di archiviazione scalabile fino a petabyte di dati e tollerare gli errori dei nodi.
Questo documento è rivolto agli sviluppatori DynamoDB e agli amministratori di database che vogliono eseguire la migrazione a Bigtable. È utile anche quando vuoi progettare applicazioni da utilizzare con Bigtable come datastore.
Per iniziare, utilizza uno strumento di migrazione fornito da Google che ti aiuti a eseguire la migrazione da DynamoDB a Bigtable. Questa pagina descrive lo strumento di migrazione, confronta i due sistemi di database e descrive l'architettura sottostante e i dettagli di interazione che differiscono e che è importante comprendere prima della migrazione.
Inizia a utilizzare lo strumento di migrazione da DynamoDB a Bigtable
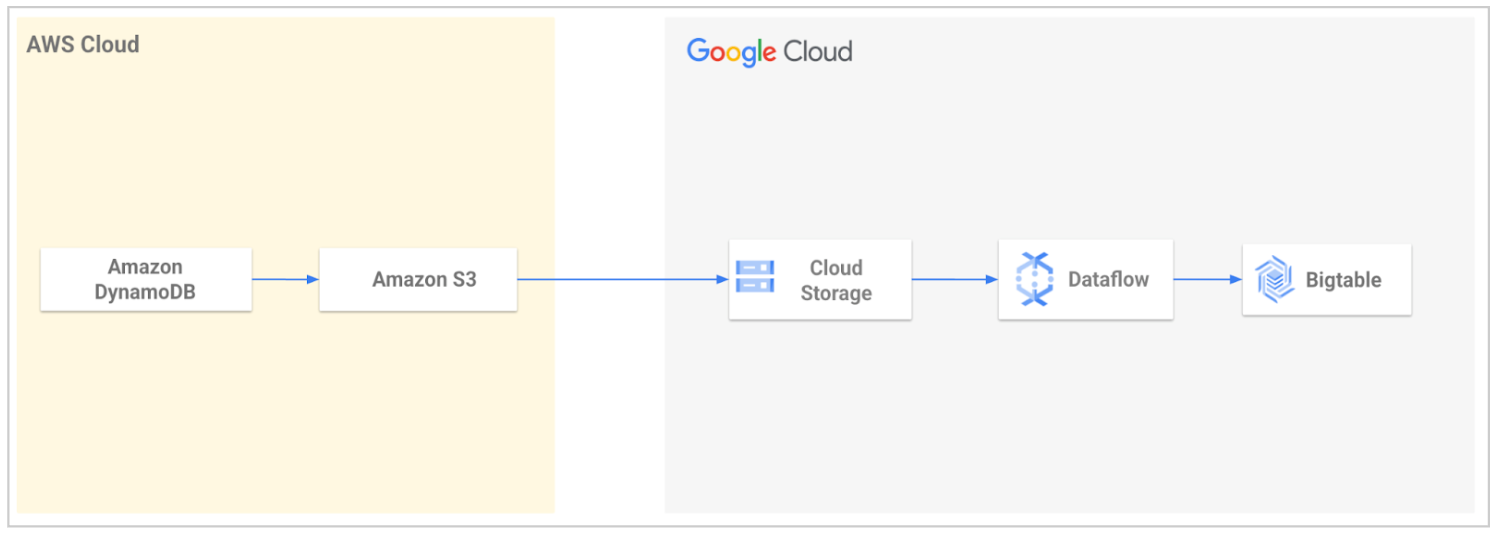
Google Cloud Professional Services fornisce uno strumento di migrazione open source per semplificare la migrazione dei dati da DynamoDB a Bigtable. Lo strumento automatizza il processo di importazione dei dati in Google Cloud e poi il caricamento in Bigtable.
Utilizzando lo strumento, esporti la tabella DynamoDB e poi la trasferisci a Cloud Storage. Lo strumento legge i file esportati dal bucket Cloud Storage e utilizza un modello Dataflow per trasformare i dati in modo che siano compatibili con Bigtable. Questa trasformazione include la mappatura degli attributi DynamoDB alle righe Bigtable. Il job Dataflow scrive quindi i dati trasformati nella tabella Bigtable.
Per maggiori informazioni o per iniziare, consulta Utilità di migrazione da DynamoDB a Bigtable.
Confronto tra DynamoDB e Bigtable
Questa sezione esamina le somiglianze e le differenze tra DynamoDB e Bigtable.
Piano di controllo
In DynamoDB e Bigtable, il control plane ti consente di configurare la capacità e impostare e gestire le risorse. DynamoDB è un prodotto serverless e il livello più alto di interazione con DynamoDB è il livello della tabella. Nella modalità di capacità di provisioning, qui esegui il provisioning delle unità di richiesta di lettura e scrittura, selezioni le regioni e la replica e gestisci i backup. Bigtable non è un prodotto serverless. Devi creare un'istanza con uno o più cluster, la cui capacità è determinata dal numero di nodi che contengono. Per informazioni dettagliate su queste risorse, consulta Istanze, cluster e nodi.
La seguente tabella confronta le risorse del control plane per DynamoDB e Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tabella : una raccolta di elementi con una chiave primaria definita. Le tabelle hanno impostazioni per backup, replica e capacità. | Istanza:un gruppo di cluster Bigtable in diverse zone o regioni, tra cui si verificano la replica e il routing delle connessioni. Google Cloud Le norme di replica vengono impostate a livello di istanza. Cluster:un gruppo di nodi nella stessa zona geografica Google Cloud , idealmente collocati insieme al server delle applicazioni per motivi di latenza e replica. La capacità viene gestita modificando il numero di nodi in ogni cluster. Tabella: un'organizzazione logica di valori indicizzati per chiave di riga. I backup sono controllati a livello di tabella. |
| Unità di capacità di lettura (RCU) e unità di capacità di scrittura (WCU):
unità che consentono letture o scritture al secondo con dimensioni del payload fisse. Ti vengono addebitate unità di lettura o scrittura per ogni operazione con dimensioni del payload maggiori. Le operazioni UpdateItem utilizzano la capacità di scrittura per le dimensioni maggiori di un elemento aggiornato, prima o dopo l'aggiornamento, anche se l'aggiornamento riguarda un sottoinsieme degli attributi dell'elemento. |
Nodo: una risorsa di calcolo virtuale responsabile della lettura e della scrittura dei dati. Il numero di nodi di un cluster si traduce in limiti di throughput per letture, scritture e scansioni. Puoi
modificare il numero di nodi in base alla combinazione di
obiettivi di latenza, conteggio delle richieste e dimensioni del payload. I nodi SSD offrono lo stesso throughput per le letture e le scritture, a differenza della differenza significativa tra RCU e WCU. Per saperne di più, consulta Prestazioni per carichi di lavoro tipici. |
| Partizione : un blocco di righe contigue, supportato da
unità a stato solido (SSD) collocate con i nodi. Ogni partizione è soggetta a un limite fisso di 1000 WCU, 3000 RCU e 10 GB di dati. |
Tablet : un blocco di righe contigue supportate dal
supporto di archiviazione scelto (SSD o HDD). Le tabelle vengono partizionate orizzontalmente in tablet per bilanciare il carico di lavoro. I tablet non vengono archiviati sui nodi di Bigtable, ma nel file system distribuito di Google, che consente una rapida ridistribuzione dei dati durante lo scaling e offre una maggiore durabilità mantenendo più copie. |
| Tabelle globali: un modo per aumentare la disponibilità e la durabilità dei dati propagando automaticamente le modifiche ai dati in più regioni. | Replica: un modo per aumentare la disponibilità e la durabilità dei dati propagando automaticamente le modifiche ai dati in più regioni o più zone all'interno della stessa regione. |
| Non applicabile (N/A) | Profilo dell'applicazione: impostazioni che indicano a Bigtable come instradare una chiamata API client al cluster appropriato nell'istanza. Puoi anche utilizzare un profilo app come tag per segmentare le metriche per l'attribuzione. |
Replica geografica
La replica viene utilizzata per soddisfare i requisiti dei clienti per quanto riguarda:
- Alta disponibilità per la continuità operativa in caso di guasto a livello di zona o regione.
- Posizionamento dei dati del servizio in prossimità degli utenti finali per la pubblicazione a bassa latenza ovunque si trovino nel mondo.
- Isolamento del carico di lavoro quando devi implementare un carico di lavoro batch su un cluster e fare affidamento sulla replica per i cluster di servizio.
Bigtable supporta i cluster replicati in tutte le zone disponibili in un massimo di 8 Google Cloud regioni in cui Bigtable è disponibile. La maggior parte delle regioni ha tre zone. Per saperne di più, consulta Regioni e zone.
Bigtable replica automaticamente i dati tra i cluster in una topologia multi-primary, il che significa che puoi leggere e scrivere in qualsiasi cluster. La replica di Bigtable è a coerenza finale. Per maggiori dettagli, vedi la Panoramica della replica.
DynamoDB fornisce tabelle globali per supportare la replica delle tabelle in più regioni. Le tabelle globali sono multi-primarie e vengono replicate automaticamente tra le regioni. La replica è a coerenza finale.
La seguente tabella elenca i concetti di replica e descrive la loro disponibilità in DynamoDB e Bigtable.
| Proprietà | DynamoDB | Bigtable |
|---|---|---|
| Replica multi-primaria | Sì. Puoi leggere e scrivere in qualsiasi tabella globale. |
Sì. Puoi leggere e scrivere in qualsiasi cluster Bigtable. |
| Modello di coerenza | A coerenza finale. Coerenza read-your-writes a livello regionale per le tabelle globali. |
A coerenza finale. Coerenza Read-your-writes a livello di cluster per tutte le tabelle, a condizione che invii sia le letture che le scritture allo stesso cluster. |
| Latenza di replica | Nessun accordo sul livello del servizio (SLA). Secondi |
Nessuno SLA. Secondi |
| Granularità della configurazione | Livello della tabella. | Livello di istanza. Un'istanza può contenere più tabelle. |
| Implementazione | Crea una tabella globale con una replica della tabella in ogni regione selezionata. A livello di regione. Replica automatica tra le repliche convertendo una tabella in una tabella globale. Le tabelle devono avere DynamoDB Streams abilitato, con lo stream contenente sia le immagini nuove che quelle precedenti dell'elemento. Elimina una regione per rimuovere la tabella globale in quella regione. |
Crea un'istanza con più di un cluster. La replica è automatica tra i cluster di quell'istanza. Livello zonale. Aggiungi e rimuovi cluster da un'istanza Bigtable. |
| Opzioni di replica | Per tabella. | Per istanza. |
| Routing e disponibilità del traffico | Il traffico viene instradato alla replica geografica più vicina. In caso di errore, applichi una logica di business personalizzata per determinare quando reindirizzare le richieste ad altre regioni. |
Utilizza i profili delle applicazioni per configurare
i criteri di routing del traffico del cluster. Utilizza il routing multi-cluster per indirizzare automaticamente il traffico al cluster integro più vicino. In caso di errore, Bigtable supporta il failover automatico tra i cluster per l'alta disponibilità. |
| Scalabilità | La capacità di scrittura in unità di richiesta di scrittura replicate (R-WRU) viene
sincronizzata tra le repliche. La capacità di lettura in unità di capacità di lettura replicate (R-RCU) è per replica. |
Puoi scalare i cluster in modo indipendente aggiungendo o rimuovendo nodi da ogni cluster replicato in base alle esigenze. |
| Costo | Le R-WRU costano il 50% in più rispetto alle WRU normali. | Ti viene addebitato il costo dei nodi e dello spazio di archiviazione di ogni cluster. Non sono previsti costi di replica di rete per la replica regionale tra zone. I costi vengono sostenuti quando la replica avviene tra regioni o continenti. |
| SLA (accordo sul livello del servizio) | 99,999% | 99,999% |
Piano dati
La tabella seguente confronta i concetti del modello dei dati per DynamoDB e Bigtable. Ogni riga della tabella descrive funzionalità analoghe. Ad esempio, un elemento in DynamoDB è simile a una riga in Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Elemento : un gruppo di attributi identificabile in modo univoco tra tutti gli altri elementi tramite la chiave primaria. La dimensione massima consentita è 400 KB. | Riga : una singola entità identificata dalla chiave di riga. La dimensione massima consentita è 256 MB. |
| N/D | Famiglia di colonne: uno spazio dei nomi specificato dall'utente che raggruppa le colonne. |
| Attributo: un raggruppamento di un nome e un valore. Un valore dell'attributo può essere di tipo scalare, insieme o documento. Non esiste un limite esplicito alle dimensioni dell'attributo. Tuttavia, poiché ogni elemento è limitato a 400 KB, per un elemento che ha un solo attributo, l'attributo può occupare fino a 400 KB meno la dimensione occupata dal nome dell'attributo. | Qualificatore di colonna: l'identificatore univoco all'interno di una
famiglia di colonne per una colonna. L'identificatore completo di una colonna è
espresso come famiglia di colonne:qualificatore di colonna. I qualificatori di colonna sono
ordinati lessicograficamente all'interno della famiglia di colonne. La dimensione massima consentita per un qualificatore di colonna è 16 kB. Cella: una cella contiene i dati per una determinata riga, colonna e timestamp. Una cella contiene un valore che può raggiungere i 100 MB. |
| Chiave primaria: un identificatore univoco per un elemento in una
tabella. Può essere una chiave di partizione o una chiave composita. Chiave di partizione: una chiave primaria semplice, composta da un attributo. Determina la partizione fisica in cui si trova l'articolo. La dimensione massima consentita è 2 kB. Chiave di ordinamento: una chiave che determina l'ordine delle righe all'interno di una partizione. La dimensione massima consentita è 1 kB. Chiave composita: una chiave primaria composta da due proprietà, la chiave di partizione e una chiave di ordinamento o un attributo di intervallo. |
Chiave di riga : un identificatore univoco per un elemento in una tabella.
In genere rappresentato da una concatenazione di valori e delimitatori.
La dimensione massima consentita è 4 kB. I qualificatori di colonna possono essere utilizzati per fornire un comportamento equivalente a quello della chiave di ordinamento di DynamoDB. Le chiavi composite possono essere create utilizzando chiavi di riga concatenate e qualificatori di colonna. Per ulteriori dettagli, consulta l'esempio di traduzione dello schema nella sezione Progettazione dello schema di questo documento. |
| Time to live: i timestamp per elemento determinano quando un elemento non è più necessario. Dopo la data e l'ora del timestamp specificato, l'elemento viene eliminato dalla tabella senza consumare alcuna velocità effettiva di scrittura. | Garbage collection : i timestamp per cella determinano quando un elemento non è più necessario. La garbage collection elimina gli elementi scaduti durante un processo in background chiamato compattazione. Le norme di raccolta dei rifiuti vengono impostate a livello di famiglia di colonne e possono eliminare elementi non solo in base alla loro età, ma anche in base al numero di versioni che l'utente vuole mantenere. Non è necessario tenere conto della capacità di compattazione durante il dimensionamento dei cluster. |
| Indice secondario globale : una tabella che contiene attributi selezionati della tabella di base, organizzati in base a una chiave primaria diversa da quella della tabella. La chiave dell'indice non deve includere nessuno degli attributi chiave della tabella. Non deve avere lo stesso schema di chiavi della tabella. DynamoDB aggiorna gli indici secondari globali in modo asincrono. | Indice secondario asincrono : per eseguire query sugli stessi dati utilizzando attributi o pattern di ricerca diversi, puoi creare un indice secondario asincrono. Questo tipo di indice contiene gli attributi selezionati della tabella di base. Questi attributi sono organizzati in base a una chiave diversa dalla chiave della tabella. Il comportamento è simile a quello degli indici secondari globali di DynamoDB. |
Operazioni
Le operazioni del piano dati consentono di eseguire azioni di creazione, lettura, aggiornamento ed eliminazione (CRUD) sui dati di una tabella. La seguente tabella confronta operazioni simili del piano dati per DynamoDB e Bigtable.
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsBigtable considera le operazioni di scrittura come upsert. |
UpdateItem
|
Bigtable considera le operazioni di scrittura come upsert. |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows` (range, prefix, reverse scan)Bigtable supporta la scansione efficiente per prefisso della chiave di riga, pattern di espressione regolare o intervallo di chiavi di riga in avanti o indietro. |
Tipi di dati
Bigtable e DynamoDB sono entrambi senza schema. Le colonne possono essere definite in fase di scrittura senza alcuna applicazione a livello di tabella per l'esistenza di colonne o tipi di dati. Allo stesso modo, un determinato tipo di dati di colonna o attributo può variare da una riga o da un elemento all'altro. Tuttavia, le API DynamoDB e Bigtable gestiscono i tipi di dati in modi diversi.
Ogni richiesta di scrittura DynamoDB include una definizione del tipo per ogni attributo, che viene restituita con la risposta per le richieste di lettura.
Bigtable considera tutto come byte e si aspetta che il codice client conosca il tipo e la codifica in modo che possa analizzare correttamente le risposte. Fanno eccezione le operazioni di incremento, che interpretano i valori come numeri interi con segno big-endian a 64 bit.
La seguente tabella mette a confronto le differenze nei tipi di dati tra DynamoDB e Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tipi scalari : restituiti come token descrittore del tipo di dati nella risposta del server. | Byte : i byte vengono convertiti nei tipi previsti nell'applicazione client. Increment interpreta il valore come un numero intero con segno big-endian a 64 bit |
| Set: una raccolta non ordinata di elementi univoci. | Famiglia di colonne: puoi utilizzare i qualificatori di colonna come nomi dei membri del set e per ciascuno fornire un singolo byte zero come valore della cella. I membri del set sono ordinati lessicograficamente all'interno della famiglia di colonne. |
| Mappa: una raccolta non ordinata di coppie chiave-valore con chiavi uniche. | Famiglia di colonne Utilizza il qualificatore di colonna come chiave della mappa e il valore della cella per il valore. Le chiavi della mappa sono ordinate lessicograficamente. |
| Elenco : una raccolta ordinata di elementi. | Qualificatore di colonna Utilizza il timestamp di inserimento per ottenere l'equivalente del comportamento di list_append e l'inverso del timestamp di inserimento per l'anteposizione. |
Progettazione dello schema
Un aspetto importante da considerare nella progettazione dello schema è la modalità di archiviazione dei dati. Tra le principali differenze tra Bigtable e DynamoDB c'è il modo in cui gestiscono quanto segue:
- Aggiornamenti ai singoli valori
- Ordinamento dei dati
- Controllo delle versioni dei dati
- Archiviazione di valori elevati
Aggiornamenti ai singoli valori
Le operazioni UpdateItem in DynamoDB consumano la capacità di scrittura per le dimensioni maggiori degli elementi "prima" e "dopo", anche se l'aggiornamento riguarda un sottoinsieme degli attributi dell'elemento. Ciò significa che in DynamoDB puoi inserire colonne aggiornate di frequente in righe separate, anche se logicamente appartengono alla stessa riga con altre colonne.
Bigtable può aggiornare una cella con la stessa efficienza, che sia l'unica colonna di una determinata riga o una tra molte migliaia. Per maggiori dettagli, vedi Scritture semplici.
Ordinamento dei dati
DynamoDB esegue l'hashing e distribuisce in modo casuale le chiavi di partizione, mentre Bigtable archivia le righe in ordine lessicografico in base alla chiave di riga e lascia all'utente l'hashing.
La distribuzione casuale delle chiavi non è ottimale per tutti i pattern di accesso. Riduce il rischio di intervalli di righe attive, ma rende costosi e inefficienti i pattern di accesso che comportano scansioni che attraversano i limiti delle partizioni. Queste scansioni senza limiti sono comuni, soprattutto per i casi d'uso che hanno una dimensione temporale.
La gestione di questo tipo di pattern di accesso, ovvero le scansioni che attraversano i limiti delle partizioni, richiede un indice secondario in DynamoDB, ma non in Bigtable. Anche se puoi progettare la chiave di riga lessicografica in Bigtable per gestire in modo efficiente molti pattern di scansione, Bigtable supporta anche gli indici secondari asincroni che implementi come viste materializzate continue per fornire ricerche efficienti e coerenti per pattern di query alternativi. Analogamente, in DynamoDB, le operazioni di query e scansione sono limitate a 1 MB di dati scansionati, il che richiede la paginazione oltre questo limite. Bigtable non ha questo limite.
Nonostante le chiavi di partizione distribuite in modo casuale, DynamoDB può comunque avere partizioni hot se una chiave di partizione scelta non distribuisce uniformemente il traffico che influisce negativamente sul throughput. Per risolvere questo problema, DynamoDB consiglia lo sharding di scrittura, ovvero la suddivisione casuale delle scritture in più valori della chiave di partizione logica.
Per applicare questo pattern di progettazione, devi creare un numero casuale da un insieme fisso (ad esempio, da 1 a 10) e poi utilizzarlo come chiave di partizione logica. Poiché la chiave di partizione viene randomizzata, le scritture nella tabella vengono distribuite uniformemente su tutti i valori della chiave di partizione.
Bigtable si riferisce a questa procedura come salatura delle chiavi, e può essere un modo efficace per evitare le tabelle attive.
Controllo delle versioni dei dati
Ogni cella Bigtable ha un timestamp e il timestamp più recente è sempre il valore predefinito per una determinata colonna. Un caso d'uso comune per i timestamp è il controllo delle versioni: scrivere una nuova cella in una colonna che si differenzia dalle versioni precedenti dei dati per quella riga e colonna per il suo timestamp.
DynamoDB non ha un concetto simile e richiede
progettazioni di schemi complessi
per supportare il controllo delle versioni. Questo approccio prevede la creazione di due copie di ogni elemento:
una copia con un prefisso del numero di versione pari a zero, ad esempio v0_, all'inizio
della chiave di ordinamento e un'altra copia con un prefisso del numero di versione pari a uno, ad esempio
v1_. Ogni volta che l'elemento viene aggiornato, utilizzi il prefisso di versione successivo più alto nella chiave di ordinamento della versione aggiornata e copi i contenuti aggiornati nell'elemento con prefisso di versione zero. In questo modo, è possibile individuare l'ultima versione di qualsiasi elemento
utilizzando il prefisso zero. Questa strategia non solo richiede
la logica lato applicazione da gestire, ma rende anche le scritture di dati molto costose e
lente, perché ogni scrittura richiede una lettura del valore precedente più due
scritture.
Transazioni su più righe e capacità di righe di grandi dimensioni
Bigtable non supporta le transazioni multiriga. Tuttavia, poiché consente di archiviare righe molto più grandi rispetto agli elementi in DynamoDB, spesso puoi ottenere la transazionalità prevista progettando gli schemi in modo da raggruppare gli elementi pertinenti in una chiave di riga condivisa. Per un esempio che illustra questo approccio, consulta Pattern di progettazione di una singola tabella.
Memorizzazione di valori elevati
Poiché un elemento DynamoDB, analogo a una riga Bigtable, è limitato a 400 KB, l'archiviazione di valori di grandi dimensioni richiede di dividere il valore tra gli elementi o di archiviarlo in altri supporti come S3. Entrambi questi approcci aggiungono complessità alla tua applicazione. Al contrario, una cella Bigtable può archiviare fino a 100 MB e una riga Bigtable può supportare fino a 256 MB.
Esempi di traduzione dello schema
Gli esempi in questa sezione traducono gli schemi da DynamoDB a Bigtable tenendo conto delle differenze di progettazione dello schema delle chiavi.
Migrazione degli schemi di base
I cataloghi di prodotti sono un buon esempio per dimostrare il pattern chiave-valore di base. Di seguito è riportato un esempio di schema in DynamoDB.
| Chiave primaria | Attributi | |||
|---|---|---|---|---|
| Chiave di partizionamento | Chiave di ordinamento | Descrizione | Prezzo | Miniatura |
| cappelli | fedoras#brandA | Realizzata in lana premium… | 30 | https://storage… |
| cappelli | fedora#brandB | Tela resistente all'acqua progettata per… | 28 | https://storage… |
| cappelli | newsboy#brandB | Aggiungi un tocco di fascino vintage al tuo look quotidiano. | 25 | https://storage… |
| scarpe | sneakers#brandA | Esci con stile e comodità con… | 40 | https://storage… |
| scarpe | sneakers#brandB | Funzionalità classiche con materiali contemporanei… | 50 | https://storage… |
Per questa tabella, il mapping da DynamoDB a Bigtable è semplice: converti la chiave primaria composita di DynamoDB in una chiave di riga composita di Bigtable. Crea una famiglia di colonne (SKU) che contenga lo stesso insieme di colonne.
| SKU | |||
|---|---|---|---|
| Chiave di riga | Descrizione | Prezzo | Miniatura |
| cappelli#fedora#brandA | Realizzata in lana premium… | 30 | https://storage… |
| cappelli#fedora#brandB | Tela resistente all'acqua progettata per… | 28 | https://storage… |
| cappelli#newsboy#brandB | Aggiungi un tocco di fascino vintage al tuo look quotidiano. | 25 | https://storage… |
| scarpe#sneaker#brandA | Esci con stile e comodità con… | 40 | https://storage… |
| scarpe#sneaker#brandB | Funzionalità classiche con materiali contemporanei… | 50 | https://storage… |
Pattern di progettazione di una singola tabella
Un singolo pattern di progettazione di tabelle riunisce quelle che sarebbero più tabelle in un database relazionale in un'unica tabella in DynamoDB. Puoi adottare l'approccio dell'esempio precedente e duplicare questo schema così com'è in Bigtable. Tuttavia, è meglio risolvere i problemi dello schema durante la procedura.
In questo schema, la chiave di partizione contiene l'ID univoco di un video, che
consente di raggruppare tutti gli attributi correlati al video per un accesso più rapido. Date le limitazioni delle dimensioni degli elementi di DynamoDB, non puoi inserire un numero illimitato di commenti in formato libero in una singola riga. Pertanto, viene utilizzata una chiave di ordinamento con il pattern
VideoComment#reverse-timestamp per fare in modo che ogni commento sia una riga separata
all'interno della partizione, ordinata in ordine cronologico inverso.
Supponiamo che questo video abbia 500 commenti e che il proprietario voglia rimuoverlo. Ciò significa che devono essere eliminati anche tutti i commenti e gli attributi del video. Per farlo in DynamoDB, devi scansionare tutte le chiavi all'interno di questa partizione e poi inviare più richieste di eliminazione, eseguendo l'iterazione di ciascuna. DynamoDB supporta le transazioni su più righe, ma questa richiesta di eliminazione è troppo grande per essere eseguita in una singola transazione.
| Chiave primaria | Attributi | |||
|---|---|---|---|---|
| Chiave di partizionamento | Chiave di ordinamento | UploadDate | Formati | |
| 0123 | Video | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | Contenuti | |||
| Mi piace molto. Gli effetti speciali sono incredibili. | ||||
| VideoComment#86751345 | Contenuti | |||
| Sembra esserci un problema audio a 1:05. | ||||
| VideoStatsLikes | Conteggio | |||
| 3 | ||||
| VideoStatsViews | Conteggio | |||
| 156 | ||||
| 0124 | Video | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | Contenuti | |||
| Ho condiviso questo video con tutti i miei amici. | ||||
| VideoComment#87616471 | Contenuti | |||
| Lo stile mi ricorda un regista di film, ma non riesco a capire chi sia. | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
Modifica questo schema durante la migrazione in modo da semplificare il codice e rendere le richieste di dati più rapide ed economiche. Le righe Bigtable hanno una capacità molto maggiore rispetto agli elementi DynamoDB e possono gestire un numero elevato di commenti. Per gestire un caso in cui un video riceve milioni di commenti, puoi impostare un criterio di raccolta dei rifiuti per conservare solo un numero fisso dei commenti più recenti.
Poiché i contatori possono essere aggiornati senza l'overhead dell'aggiornamento dell'intera riga, non devi nemmeno suddividerli. Inoltre, non devi utilizzare una colonna UploadDate né calcolare un timestamp inverso e impostarlo come chiave di ordinamento, perché i timestamp Bigtable forniscono automaticamente i commenti in ordine cronologico inverso. Ciò semplifica notevolmente lo schema e, se un video viene rimosso, puoi rimuovere in modo transazionale la riga del video, inclusi tutti i commenti, in un'unica richiesta.
Infine, poiché le colonne in Bigtable sono ordinate lessicograficamente, come ottimizzazione, puoi rinominare le colonne in modo da consentire una scansione rapida dell'intervallo, dalle proprietà del video ai primi N commenti più recenti, in una singola richiesta di lettura, che è quello che vorresti fare quando il video viene caricato. In un secondo momento, potrai sfogliare il resto dei commenti mentre lo spettatore scorre la pagina.
| Attributi | ||||
|---|---|---|---|---|
| Chiave di riga | Formati | Mi piace | Visualizzazioni | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | Mi piace molto. Gli effetti speciali sono incredibili. @
2023-09-10T19:01:15 Sembra che ci sia un problema audio a 1:05. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | Lo stile mi ricorda un regista di film, ma non riesco a capire chi sia. @2023-10-12T07:08:51 | |
Pattern di progettazione dell'elenco di adiacenza
Prendi in considerazione una versione leggermente diversa di questo design, che DynamoDB spesso definisce pattern di progettazione dell'elenco di adiacenza.
| Chiave primaria | Attributi | |||
|---|---|---|---|---|
| Chiave di partizionamento | Chiave di ordinamento | DateCreated | Dettagli | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
In questa tabella, le chiavi di ordinamento non si basano sul tempo, ma sugli ID pagamento, quindi puoi utilizzare un pattern di colonne larghe diverso e rendere questi ID colonne separate in Bigtable, con vantaggi simili all'esempio precedente.
| Fattura | Pagamento | |||
|---|---|---|---|---|
| chiave di riga | Dettagli | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| chiave di riga | Dettagli | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
Come puoi vedere negli esempi precedenti, con la giusta progettazione dello schema, il modello a colonne larghe di Bigtable può essere molto efficace e offrire molti casi d'uso che richiederebbero costose transazioni multiriga, indicizzazione secondaria o comportamento a cascata di eliminazione in altri database.
Passaggi successivi
- Scopri di più sulla progettazione dello schema Bigtable.
- Scopri di più sull'emulatore Bigtable.
- Esplora architetture di riferimento, diagrammi e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.