Dokumen ini ditujukan bagi developer software dan administrator database yang ingin memigrasikan aplikasi yang ada atau mendesain aplikasi baru untuk digunakan dengan Bigtable sebagai penyimpanan data. Dokumen ini menerapkan pengetahuan Anda tentang Apache Cassandra untuk menggunakan Bigtable dalam menjelaskan konsep yang harus Anda pahami sebelum melakukan migrasi. Untuk mengetahui informasi tentang alat open source yang dapat Anda gunakan untuk menyelesaikan migrasi, lihat Bermigrasi dari Cassandra ke Bigtable.
Bigtable dan Cassandra adalah database terdistribusi. Layanan ini mengimplementasikan penyimpanan nilai kunci multidimensional yang dapat mendukung puluhan ribu kueri per detik (QPS), penyimpanan yang dapat diskalakan hingga petabyte data, dan toleransi terhadap kegagalan node.
Kapan Bigtable menjadi tujuan yang tepat untuk workload Cassandra
Layanan Google Cloud terbaik untuk workload Cassandra Anda bergantung pada tujuan migrasi dan fungsi Cassandra yang Anda perlukan setelah migrasi.
Jika satu atau beberapa kondisi berikut berlaku, Bigtable adalah pilihan yang optimal:
- Anda menginginkan layanan terkelola sepenuhnya tanpa masa pemeliharaan dan ketersediaan tinggi.
- Anda memerlukan penskalaan elastis yang merespons perubahan traffic server secara otomatis.
- Anda menggunakan jenis koleksi, penghitung, atau tampilan terwujud Cassandra selain jenis skalar.
- Anda memiliki aplikasi yang menggunakan parameter
USING TIMESTAMP. - Throughput dan latensi tulis Anda sama pentingnya dengan pembacaan.
- Anda mengandalkan salah satu model replikasi Cassandra yang memiliki konsistensi tertunda.
- Kasus penggunaan Anda memerlukan penyimpanan yang hemat biaya.
Untuk memigrasikan aplikasi tanpa mengubah kode apa pun, Anda dapat memilih untuk mengelola sendiri Cassandra di GKE atau menggunakan partner seperti DataStax atau ScyllaDB. Google CloudJika aplikasi Anda banyak melakukan operasi baca dan Anda bersedia memfaktorkan ulang kode untuk mendapatkan kemampuan database relasional dan konsistensi yang kuat, Anda dapat mempertimbangkan Spanner.
Dokumen ini memberikan tips tentang hal-hal yang perlu dipertimbangkan saat memfaktorkan ulang aplikasi Anda, jika Anda memilih Bigtable sebagai target migrasi untuk workload Cassandra Anda.
Cara menggunakan dokumen ini
Anda tidak perlu membaca dokumen ini dari awal hingga akhir. Meskipun dokumen ini memberikan perbandingan kedua database, Anda juga dapat berfokus pada topik yang berlaku untuk kasus penggunaan atau minat Anda.
Untuk membantu Anda membandingkan Bigtable dan Cassandra, dokumen ini melakukan hal berikut:
- Membandingkan terminologi, yang dapat berbeda antara kedua database.
- Memberikan ringkasan tentang kedua sistem database.
- Melihat cara setiap database menangani pemodelan data untuk memahami pertimbangan desain yang berbeda.
- Membandingkan jalur yang diambil oleh data selama penulisan dan pembacaan.
- Memeriksa tata letak data fisik untuk memahami aspek arsitektur database.
- Menjelaskan cara mengonfigurasi replikasi geografis untuk memenuhi persyaratan Anda, dan cara menentukan ukuran cluster.
- Meninjau detail tentang pengelolaan, pemantauan, dan keamanan cluster.
Perbandingan terminologi
Meskipun banyak konsep yang digunakan di Bigtable dan Cassandra serupa, setiap database memiliki konvensi penamaan yang sedikit berbeda dan perbedaan yang tidak terlalu mencolok.
Salah satu elemen penyusun inti dari kedua database adalah tabel string yang diurutkan (SSTable). Dalam kedua arsitektur, SSTable dibuat untuk mempertahankan data yang digunakan untuk merespons kueri baca.
Dalam postingan blog (2012), Ilya Grigorik menulis sebagai berikut: "SSTable adalah abstraksi sederhana untuk menyimpan sejumlah besar pasangan nilai kunci secara efisien sekaligus mengoptimalkan throughput tinggi, beban kerja baca atau tulis berurutan."
Tabel berikut menguraikan dan menjelaskan konsep bersama serta terminologi yang sesuai yang digunakan setiap produk:
| Cassandra | Bigtable |
|---|---|
|
kunci utama: nilai satu atau multi-bidang unik yang menentukan penempatan dan pengurutan data. kunci partisi: nilai satu atau multi-bidang yang menentukan penempatan data dengan hash yang konsisten. kolom pengelompokan: nilai satu atau multi-bidang yang menentukan pengurutan data leksikografis dalam partisi. |
kunci baris: string byte tunggal unik yang menentukan penempatan data dengan pengurutan leksikografis. Kunci komposit ditiru dengan menggabungkan data beberapa kolom menggunakan pembatas umum—misalnya, simbol hash (#) atau persen (%). |
| node: mesin yang bertanggung jawab untuk membaca dan menulis data yang terkait dengan serangkaian rentang hash partisi kunci primer. Di Cassandra, data disimpan di penyimpanan tingkat blok yang terlampir ke server node. | node: resource komputasi virtual yang bertanggung jawab untuk membaca dan menulis data yang terkait dengan serangkaian rentang kunci baris. Di Bigtable, data tidak ditempatkan bersama dengan node komputasi. Sebagai gantinya, data disimpan di Colossus, sistem file terdistribusi Google. Node diberi tanggung jawab sementara untuk menyajikan berbagai rentang data berdasarkan beban operasi dan kesehatan node lain dalam cluster. |
|
pusat data: mirip dengan cluster Bigtable, kecuali beberapa aspek topologi dan strategi replikasi dapat dikonfigurasi di Cassandra. rak: pengelompokan node di pusat data yang memengaruhi penempatan replika. |
cluster: sekelompok node di zona geografisGoogle Cloud yang sama, yang ditempatkan bersama untuk mengatasi masalah latensi dan replikasi. |
| cluster: deployment Cassandra yang terdiri dari kumpulan pusat data. | instance: sekelompok cluster Bigtable di zona atau region Google Cloud berbeda yang di antaranya terjadi replikasi dan perutean koneksi. |
| vnode: rentang tetap nilai hash yang ditetapkan ke node fisik tertentu. Data dalam vnode disimpan secara fisik di node Cassandra dalam serangkaian SSTable. | tablet: SSTable yang berisi semua data untuk rentang berurutan dari kunci baris yang diurutkan secara leksikografis. Tablet tidak disimpan di node di Bigtable, tetapi disimpan dalam serangkaian SSTable di Colossus. |
| faktor replikasi: jumlah replika vnode yang dipertahankan di semua node di pusat data. Faktor replikasi dikonfigurasi secara independen untuk setiap pusat data. | replikasi: proses mereplikasi data yang disimpan di Bigtable ke semua cluster dalam instance. Replikasi dalam cluster zonal ditangani oleh lapisan penyimpanan Colossus. |
| tabel (sebelumnya grup kolom): organisasi nilai logis yang diindeks oleh kunci utama unik. | table: organisasi nilai logis yang diindeks oleh kunci baris unik. |
| keyspace: namespace tabel logis yang menentukan faktor replikasi untuk tabel yang dikandungnya. | Tidak berlaku. Bigtable menangani masalah ruang kunci secara transparan. |
| map: jenis koleksi Cassandra yang menyimpan key-value pair. | keluarga kolom: ruang nama yang ditentukan pengguna yang mengelompokkan penentu kolom untuk pembacaan dan penulisan yang lebih efisien. Saat membuat kueri Bigtable menggunakan SQL, kelompok kolom diperlakukan seperti peta Cassandra. |
| kunci peta: kunci yang secara unik mengidentifikasi entri nilai kunci dalam peta Cassandra | penentu kolom: label untuk nilai yang disimpan dalam tabel yang diindeks oleh kunci baris unik. Saat membuat kueri Bigtable menggunakan SQL, kolom diperlakukan seperti kunci peta. |
| kolom: label untuk nilai yang disimpan dalam tabel yang diindeks oleh kunci utama unik. | kolom: label untuk nilai yang disimpan dalam tabel yang diindeks oleh kunci baris unik. Nama kolom dibuat dengan menggabungkan grup kolom dengan penentu kolom. |
| sel: nilai stempel waktu dalam tabel yang terkait dengan persimpangan kunci utama dengan kolom. | sel: nilai stempel waktu dalam tabel yang terkait dengan persimpangan kunci baris dengan nama kolom. Beberapa versi yang diberi stempel waktu dapat disimpan dan diambil untuk setiap sel. |
| counter: jenis kolom yang dapat di-increment dan dioptimalkan untuk operasi penjumlahan bilangan bulat. | penghitung: sel yang menggunakan jenis data khusus untuk operasi penjumlahan bilangan bulat Untuk mengetahui informasi selengkapnya, lihat Membuat dan memperbarui penghitung. |
| kebijakan load balancing: kebijakan yang Anda konfigurasi dalam logika aplikasi untuk merutekan operasi ke node yang sesuai di cluster. Kebijakan mempertimbangkan topologi pusat data dan rentang token vnode. | profil aplikasi: setelan yang menginstruksikan Bigtable cara merutekan panggilan API klien ke cluster yang sesuai dalam instance. Anda juga dapat menggunakan profil aplikasi sebagai tag untuk menyegmentasikan metrik. Anda mengonfigurasi profil aplikasi di layanan. |
| CQL: Cassandra Query Language, bahasa seperti SQL yang digunakan untuk pembuatan tabel, perubahan skema, mutasi baris, dan kueri. | Klien Cassandra ke Bigtable untuk Java adalah pengganti yang lancar untuk driver Cassandra Anda. Klien Java memahami kueri CQL Anda, dan memungkinkan Anda menggunakan Bigtable secara transparan dengan aplikasi berbasis Cassandra yang ada tanpa menulis ulang kode. Cassandra to Bigtable proxy adapter adalah lapisan mandiri yang dapat Anda jalankan secara paralel dengan aplikasi Anda dan terhubung ke Bigtable sebagai node Cassandra lainnya. Adaptor proxy menyediakan kompatibilitas dengan CQL dan mendukung penulisan ganda dan migrasi massal. Fungsi ini mirip dengan yang ditawarkan oleh klien Cassandra ke Bigtable untuk Java. Bigtable API adalah library klien dan gRPC API yang digunakan untuk pembuatan instance dan cluster, pembuatan tabel dan keluarga kolom, mutasi baris, dan eksekusi kueri. SQL API Bigtable sudah tidak asing bagi pengguna CQL. |
tampilan terwujud: pernyataan SELECT yang menentukan serangkaian
baris yang sesuai dengan baris dalam tabel sumber pokok. Saat tabel sumber berubah, Cassandra akan memperbarui tampilan terwujud secara otomatis.
|
tampilan terwujud berkelanjutan: hasil kueri SQL yang telah dihitung sebelumnya dan dikelola sepenuhnya yang diupdate secara inkremental dan otomatis dari tabel sumber. Untuk mengetahui informasi selengkapnya, lihat Tampilan terwujud berkelanjutan. |
Ringkasan Produk
Bagian berikut memberikan ringkasan filosofi desain dan atribut utama Bigtable dan Cassandra.
Bigtable
Bigtable menyediakan banyak fitur inti yang dijelaskan dalam makalah Bigtable: A Distributed Storage System for Structured Data. Bigtable memisahkan node komputasi, yang melayani permintaan klien, dari pengelolaan penyimpanan yang mendasarinya. Data disimpan di Colossus. Lapisan penyimpanan secara otomatis mereplikasi data untuk memberikan keandalan yang melampaui tingkat yang diberikan oleh replikasi tiga arah Hadoop Distributed File System (HDFS) standar.
Arsitektur ini memberikan operasi baca dan tulis yang konsisten dalam cluster, menskalakan naik dan turun tanpa biaya redistribusi penyimpanan, dan dapat menyeimbangkan ulang workload tanpa mengubah cluster atau skema. Jika ada node pemrosesan data yang terganggu, layanan Bigtable akan menggantinya secara transparan. Bigtable juga mendukung replikasi asinkron.
Selain gRPC dan library klien untuk berbagai bahasa pemrograman, Bigtable mempertahankan kompatibilitas dengan HBase HBase open source, implementasi mesin database open source alternatif dari dokumen Bigtable.
Diagram berikut menunjukkan cara Bigtable memisahkan node pemrosesan dari lapisan penyimpanan secara fisik:
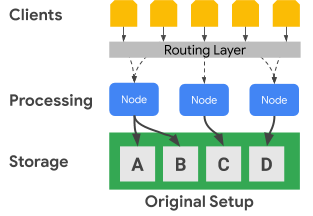
Dalam diagram sebelumnya, node pemrosesan tengah hanya bertanggung jawab untuk menayangkan permintaan data untuk set data C di lapisan penyimpanan. Jika Bigtable mengidentifikasi bahwa penyeimbangan ulang penetapan rentang diperlukan untuk set data, rentang data untuk node pemrosesan mudah diubah karena lapisan penyimpanan dipisahkan dari lapisan pemrosesan.
Diagram berikut menunjukkan, dalam istilah yang disederhanakan, penyeimbangan ulang rentang kunci dan pengubahan ukuran cluster:
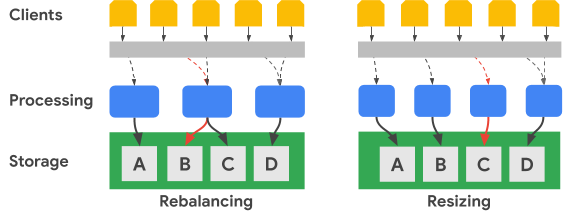
Gambar Penyeimbangan Ulang menggambarkan status cluster Bigtable setelah node pemrosesan paling kiri menerima peningkatan jumlah permintaan untuk set data A. Setelah penyeimbangan ulang terjadi, node tengah, bukan node paling kiri, bertanggung jawab untuk melayani permintaan data untuk set data B. Node paling kiri terus melayani permintaan untuk set data A.
Bigtable dapat mengatur ulang rentang kunci baris untuk menyeimbangkan rentang set data di sejumlah node pemrosesan yang tersedia. Gambar Mengubah Ukuran menunjukkan status cluster Bigtable setelah Anda menambahkan node.
Cassandra
Apache Cassandra adalah database open source yang sebagian dipengaruhi oleh konsep dari dokumen Bigtable. Layanan ini menggunakan arsitektur node terdistribusi, di mana penyimpanan ditempatkan bersama server yang merespons operasi data. Serangkaian node virtual (vnode) ditetapkan secara acak ke setiap server untuk melayani sebagian keyspace cluster.
Data disimpan di vnode berdasarkan kunci partisi. Biasanya, fungsi hash yang konsisten digunakan untuk membuat token guna menentukan penempatan data. Seperti Bigtable, Anda dapat menggunakan pemartisi yang mempertahankan urutan untuk pembuatan token, dan dengan demikian juga untuk penempatan data. Namun, dokumentasi Cassandra tidak menganjurkan pendekatan ini karena cluster kemungkinan akan menjadi tidak seimbang, kondisi yang sulit diperbaiki. Oleh karena itu, dokumen ini mengasumsikan bahwa Anda menggunakan strategi hashing yang konsisten untuk menghasilkan token yang menghasilkan distribusi data di seluruh node.
Cassandra menyediakan fault tolerance melalui tingkat ketersediaan yang berkorelasi dengan tingkat konsistensi yang dapat disesuaikan, sehingga cluster dapat melayani klien saat satu atau beberapa node terganggu. Anda menentukan replikasi geografis melalui strategi topologi replikasi data yang dapat dikonfigurasi.
Anda menentukan tingkat konsistensi untuk setiap operasi. Setelan umum adalah
QUORUM (atau LOCAL_QUORUM dalam topologi beberapa pusat data tertentu). Setelan tingkat konsistensi ini memerlukan sebagian besar node replika untuk merespons node koordinator agar operasi dianggap berhasil. Faktor replikasi, yang Anda konfigurasi untuk setiap keyspace, menentukan jumlah replika data yang disimpan di setiap pusat data dalam cluster. Misalnya, nilai faktor replikasi 3 biasanya digunakan untuk memberikan keseimbangan praktis antara daya tahan dan volume penyimpanan.
Diagram berikut menunjukkan secara sederhana cluster enam node dengan rentang kunci setiap node dibagi menjadi lima vnode. Dalam praktiknya, Anda dapat memiliki lebih banyak node, dan kemungkinan akan memiliki lebih banyak vnode.

Dalam diagram sebelumnya, Anda dapat melihat jalur operasi tulis, dengan
tingkat konsistensi QUORUM, yang berasal dari aplikasi atau
layanan klien (Klien). Untuk tujuan diagram ini, rentang kunci ditampilkan sebagai rentang alfabet. Pada kenyataannya, token yang dihasilkan oleh hash
kunci utama adalah bilangan bulat bertanda yang sangat besar.
Dalam contoh ini, hash kuncinya adalah M, dan vnode untuk M ada di node 2, 4, dan 6. Koordinator harus menghubungi setiap node tempat rentang hash kunci
disimpan secara lokal agar penulisan dapat diproses. Karena tingkat konsistensi adalah QUORUM, dua replika (mayoritas) harus merespons node koordinator sebelum klien diberi tahu bahwa penulisan telah selesai.
Berbeda dengan Bigtable, memindahkan atau mengubah rentang kunci di Cassandra mengharuskan Anda menyalin data secara fisik dari satu node ke node lainnya. Jika satu node kelebihan beban dengan permintaan untuk rentang hash token tertentu, penambahan pemrosesan untuk rentang token tersebut lebih rumit di Cassandra dibandingkan dengan Bigtable.
Replikasi dan konsistensi geografis
Bigtable dan Cassandra menangani replikasi dan konsistensi geografis (juga dikenal sebagai multi-region) secara berbeda. Cluster Cassandra terdiri dari node pemrosesan yang dikelompokkan ke dalam rak, dan rak dikelompokkan ke dalam pusat data. Cassandra menggunakan strategi topologi jaringan yang Anda konfigurasi untuk menentukan cara replika vnode didistribusikan di seluruh host di pusat data. Strategi ini mengungkapkan asal-usul Cassandra sebagai database yang awalnya di-deploy di pusat data fisik lokal. Konfigurasi ini juga menentukan faktor replikasi untuk setiap pusat data di cluster.
Cassandra menggunakan konfigurasi pusat data dan rak untuk meningkatkan toleransi kesalahan replika data. Selama operasi baca dan tulis, topologi menentukan node peserta yang diperlukan untuk memberikan jaminan konsistensi. Anda harus mengonfigurasi node, rak, dan pusat data secara manual saat membuat atau memperluas cluster. Dalam lingkungan cloud, deployment Cassandra standar memperlakukan zona cloud sebagai rak dan region cloud sebagai pusat data.
Anda dapat menggunakan kontrol kuorum Cassandra untuk menyesuaikan jaminan konsistensi untuk setiap operasi baca atau tulis. Tingkat kekuatan konsistensi pada akhirnya dapat bervariasi, termasuk opsi yang memerlukan satu node replika (ONE), mayoritas node replika satu pusat data (LOCAL_QUORUM), atau mayoritas semua node replika di semua pusat data (QUORUM).
Di Bigtable, cluster adalah resource zona. Instance Bigtable dapat berisi satu cluster, atau dapat berupa grup cluster yang direplikasi sepenuhnya. Anda dapat menempatkan cluster instance dalam kombinasi zona di seluruh region yang ditawarkan Google Cloud . Anda dapat menambahkan dan menghapus cluster dari instance dengan dampak minimal pada cluster lain dalam instance.
Di Bigtable, penulisan dilakukan (dengan konsistensi baca-tulis Anda) pada satu cluster dan akan konsisten pada akhirnya di cluster instance lainnya. Karena setiap sel diberi versi berdasarkan stempel waktu, tidak ada operasi tulis yang hilang, dan setiap cluster menayangkan sel yang memiliki stempel waktu terbaru.
Layanan ini menampilkan status konsistensi cluster. Cloud Bigtable API menyediakan mekanisme untuk mendapatkan token konsistensi tingkat tabel. Anda dapat menggunakan token ini untuk memastikan apakah semua perubahan yang dilakukan pada tabel tersebut sebelum token dibuat direplikasi sepenuhnya.
Dukungan transaksi
Meskipun kedua database tidak mendukung transaksi multi-baris yang kompleks, masing-masing memiliki beberapa dukungan transaksi.
Cassandra memiliki metode lightweight transaction (LWT) yang menyediakan atomisitas untuk update nilai kolom dalam satu partisi. Cassandra juga memiliki semantik bandingkan dan tetapkan yang menyelesaikan operasi baca baris dan perbandingan nilai sebelum penulisan dimulai.
Bigtable mendukung penulisan baris tunggal yang sepenuhnya konsisten dalam cluster. Transaksi baris tunggal diaktifkan lebih lanjut melalui operasi baca-ubah-tulis dan periksa-dan-ubah. Profil aplikasi perutean multi-cluster tidak mendukung transaksi baris tunggal.
Model data
Bigtable dan Cassandra mengatur data ke dalam tabel yang mendukung pencarian dan pemindaian rentang menggunakan ID unik baris. Kedua sistem diklasifikasikan sebagai penyimpanan kolom lebar NoSQL.
Di Cassandra, Anda harus menggunakan CQL untuk membuat skema tabel lengkap terlebih dahulu, termasuk definisi kunci utama beserta nama kolom dan jenisnya. Kunci utama di Cassandra adalah nilai gabungan unik yang terdiri dari kunci partisi wajib dan kunci pengelompokan opsional. Kunci partisi menentukan penempatan node baris, dan kunci pengelompokan menentukan urutan pengurutan dalam partisi. Saat membuat skema, Anda harus menyadari potensi kompromi antara menjalankan pemindaian yang efisien dalam partisi tunggal dan biaya sistem yang terkait dengan mempertahankan partisi besar.
Di Bigtable, Anda hanya perlu membuat tabel dan menentukan grup kolomnya terlebih dahulu. Kolom tidak dideklarasikan saat tabel dibuat, tetapi kolom dibuat saat panggilan API aplikasi menambahkan sel ke baris tabel.
Kunci baris diurutkan secara leksikografis di seluruh cluster Bigtable. Node dalam Bigtable secara otomatis menyeimbangkan tanggung jawab node untuk rentang kunci, yang sering disebut sebagai tablet dan terkadang sebagai pemisahan. Kunci baris Bigtable sering kali terdiri dari beberapa nilai kolom yang digabungkan menggunakan karakter pemisah yang umum digunakan yang Anda pilih (seperti tanda persen). Jika dipisahkan, setiap komponen string akan serupa dengan kolom kunci utama Cassandra.
Desain kunci baris
Di Bigtable, ID unik baris tabel adalah kunci baris. Kunci baris harus berupa satu nilai unik di seluruh tabel. Anda dapat membuat kunci multi-bagian dengan menggabungkan elemen berbeda yang dipisahkan oleh pembatas umum. Kunci baris menentukan urutan pengurutan data global dalam tabel. Layanan Bigtable secara dinamis menentukan rentang kunci yang ditetapkan ke setiap node.
Berbeda dengan Cassandra, yang hash kunci partisi menentukan penempatan baris dan kolom pengelompokan menentukan pengurutan, kunci baris Bigtable menyediakan penetapan dan pengurutan nodal. Seperti Cassandra, Anda harus mendesain kunci baris di Bigtable sehingga baris yang ingin Anda ambil bersama disimpan bersama. Namun, di Bigtable, Anda tidak perlu mendesain kunci baris untuk penempatan dan pengurutan sebelum menggunakan tabel.
Jenis data
Layanan Bigtable tidak menerapkan jenis data kolom yang dikirim klien. Library klien menyediakan metode bantuan untuk menulis nilai sel sebagai byte, string berenkode UTF-8, dan bilangan bulat 64-bit berenkode big-endian (bilangan bulat berenkode big-endian diperlukan untuk operasi penambahan atomik).
Grup kolom
Di Bigtable, grup kolom menentukan kolom mana dalam tabel yang disimpan dan diambil bersama. Setiap tabel memerlukan minimal satu grup kolom, meskipun tabel sering kali memiliki lebih banyak (batasnya adalah 100 grup kolom untuk setiap tabel). Anda harus membuat family kolom secara eksplisit sebelum aplikasi dapat menggunakannya dalam operasi.
Penentu kolom
Setiap nilai yang disimpan dalam tabel pada kunci baris dikaitkan dengan label yang disebut penentu kolom. Karena penentu kolom hanya berupa label, tidak ada batasan praktis untuk jumlah kolom yang dapat Anda miliki dalam grup kolom. Penentu kolom sering digunakan di Bigtable untuk merepresentasikan data aplikasi.
Sel
Di Bigtable, sel adalah persimpangan antara kunci baris dan nama kolom (grup kolom yang dikombinasikan dengan penentu kolom). Setiap sel berisi satu atau beberapa nilai berstempel waktu yang dapat diberikan oleh klien atau diterapkan secara otomatis oleh layanan. Nilai sel lama diklaim kembali berdasarkan kebijakan pengumpulan sampah yang dikonfigurasi di tingkat grup kolom.
Indeks sekunder
Anda dapat menggunakan tampilan terwujud berkelanjutan sebagai indeks sekunder asinkron untuk tabel guna membuat kueri data yang sama menggunakan pola atau atribut penelusuran yang berbeda. Untuk mengetahui informasi selengkapnya, lihat Membuat indeks sekunder asinkron.
Load balancing dan failover klien
Di Cassandra, klien mengontrol load balancing permintaan. Driver klien menetapkan kebijakan yang ditentukan sebagai bagian dari konfigurasi atau secara terprogram selama pembuatan sesi. Cluster memberi tahu kebijakan tentang pusat data yang paling dekat dengan aplikasi, dan klien mengidentifikasi node dari pusat data tersebut untuk melayani operasi.
Layanan Bigtable merutekan panggilan API ke cluster tujuan berdasarkan parameter (ID profil aplikasi) yang diberikan dengan setiap operasi. Profil aplikasi dikelola dalam layanan Bigtable; operasi klien yang tidak memilih profil akan menggunakan profil default.
Bigtable memiliki dua jenis kebijakan perutean profil aplikasi: cluster tunggal dan multi-cluster. Profil multi-cluster merutekan operasi ke cluster terdekat yang tersedia. Cluster di region yang sama dianggap berjarak sama dari perspektif perute operasi. Jika node yang bertanggung jawab atas rentang kunci yang diminta kelebihan beban atau tidak tersedia untuk sementara di cluster, jenis profil ini menyediakan failover otomatis.
Dalam hal Cassandra, kebijakan multi-cluster memberikan manfaat failover dari kebijakan load balancing yang mengetahui pusat data.
Profil aplikasi yang memiliki perutean cluster tunggal mengarahkan semua traffic ke satu cluster. Konsistensi baris yang kuat dan transaksi baris tunggal hanya tersedia di profil yang memiliki perutean cluster tunggal.
Kelemahan pendekatan cluster tunggal adalah bahwa dalam failover, aplikasi harus dapat mencoba ulang dengan menggunakan ID profil aplikasi alternatif, atau Anda harus melakukan failover secara manual profil perutean cluster tunggal yang terpengaruh.
Perutean operasi
Cassandra dan Bigtable menggunakan metode yang berbeda untuk memilih node pemrosesan untuk operasi baca dan tulis. Di Cassandra, kunci partisi diidentifikasi, sedangkan di Bigtable, kunci baris digunakan.
Di Cassandra, klien terlebih dahulu memeriksa kebijakan load balancing. Objek sisi klien ini menentukan pusat data tempat operasi dirutekan.
Setelah pusat data diidentifikasi, Cassandra menghubungi node koordinator untuk mengelola operasi. Jika kebijakan mengenali token, koordinator adalah node yang menyajikan data dari partisi vnode target; jika tidak, koordinator adalah node acak. Node koordinator mengidentifikasi node tempat replika data untuk kunci partisi operasi berada, lalu menginstruksikan node tersebut untuk melakukan operasi.
Di Bigtable, seperti yang dibahas sebelumnya, setiap operasi mencakup ID profil aplikasi. Profil aplikasi ditentukan di tingkat layanan. Lapisan perutean Bigtable memeriksa profil untuk memilih cluster tujuan yang sesuai untuk operasi. Lapisan perutean kemudian menyediakan jalur bagi operasi untuk mencapai node pemrosesan yang benar dengan menggunakan kunci baris operasi.
Proses penulisan data
Kedua database dioptimalkan untuk penulisan cepat dan menggunakan proses yang serupa untuk menyelesaikan penulisan. Namun, langkah-langkah yang dilakukan database sedikit berbeda, terutama untuk Cassandra, yang bergantung pada tingkat konsistensi operasi, komunikasi dengan node peserta tambahan mungkin diperlukan.
Setelah permintaan penulisan dirutekan ke node yang sesuai (Cassandra) atau node (Bigtable), penulisan akan dipertahankan terlebih dahulu ke disk secara berurutan dalam log commit (Cassandra) atau log bersama (Bigtable). Selanjutnya, penulisan dimasukkan ke dalam tabel dalam memori (juga dikenal sebagai memtable) yang diurutkan seperti SSTable.
Setelah kedua langkah ini, node akan merespons untuk menunjukkan bahwa penulisan telah selesai. Di Cassandra, beberapa replika (bergantung pada tingkat konsistensi yang ditentukan untuk setiap operasi) harus merespons sebelum koordinator memberi tahu klien bahwa penulisan telah selesai. Di Bigtable, karena setiap kunci baris hanya ditetapkan ke satu node pada waktu tertentu, respons dari node adalah semua yang diperlukan untuk mengonfirmasi bahwa penulisan berhasil.
Selanjutnya, jika perlu, Anda dapat menghapus memtable ke disk dalam bentuk SSTable baru. Di Cassandra, flush terjadi saat log commit mencapai ukuran maksimum, atau saat memtable melebihi nilai minimum yang Anda konfigurasi. Di Bigtable, flush dimulai untuk membuat SSTable immutable baru saat memtable mencapai ukuran maksimum yang ditentukan oleh layanan. Secara berkala, proses pemadatan menggabungkan SSTable untuk rentang kunci tertentu menjadi satu SSTable.
Pembaruan data
Kedua database menangani pembaruan data dengan cara yang serupa. Namun, Cassandra hanya mengizinkan satu nilai untuk setiap sel, sedangkan Bigtable dapat menyimpan sejumlah besar nilai berversi untuk setiap sel.
Saat nilai di persimpangan ID baris dan kolom unik diubah, pembaruan akan dipertahankan seperti yang dijelaskan sebelumnya di bagian proses penulisan data. Stempel waktu penulisan disimpan bersama nilai dalam struktur SSTable.
Jika Anda belum menghapus sel yang diperbarui ke SSTable, Anda hanya dapat menyimpan nilai sel di memtable, tetapi database berbeda dalam hal apa yang disimpan. Cassandra hanya menyimpan nilai terbaru dalam memtable, sedangkan Bigtable menyimpan semua versi dalam memtable.
Atau, jika Anda telah menghapus setidaknya satu versi nilai sel ke disk dalam SSTable terpisah, database akan menangani permintaan untuk data tersebut secara berbeda. Saat sel diminta dari Cassandra, hanya nilai terbaru menurut stempel waktu yang ditampilkan; dengan kata lain, penulisan terakhir yang menang. Di Bigtable, Anda menggunakan filter untuk mengontrol versi sel yang ditampilkan oleh permintaan baca.
Penghapusan baris
Karena kedua database menggunakan file SSTable yang tidak dapat diubah untuk menyimpan data ke disk, baris tidak dapat dihapus secara langsung. Untuk memastikan kueri menampilkan hasil yang benar setelah baris dihapus, kedua database menangani penghapusan menggunakan mekanisme yang sama. Penanda (disebut tombstone di Cassandra) ditambahkan terlebih dahulu ke memtable. Pada akhirnya, SSTable yang baru ditulis berisi penanda berstempel waktu yang menunjukkan bahwa ID baris unik dihapus dan tidak boleh ditampilkan dalam hasil kueri.
Time to live (TTL)
Kemampuan time to live (TTL) di kedua database serupa, kecuali satu perbedaan. Di Cassandra, Anda dapat menetapkan TTL untuk kolom atau tabel, sedangkan di Bigtable, Anda hanya dapat menetapkan TTL untuk grup kolom. Ada metode untuk Bigtable yang dapat mensimulasikan TTL tingkat sel.
Pengumpulan sampah
Karena pembaruan atau penghapusan data secara langsung tidak dapat dilakukan dengan SSTable yang tidak dapat diubah, seperti yang dibahas sebelumnya, pengumpulan sampah terjadi selama proses yang disebut pemadatan. Proses ini akan menghapus sel atau baris yang tidak boleh ditampilkan dalam hasil kueri.
Proses pengumpulan sampah mengecualikan baris atau sel saat penggabungan SSTable terjadi. Jika penanda atau batu nisan ada untuk baris, baris tersebut tidak disertakan dalam SSTable yang dihasilkan. Kedua database dapat mengecualikan sel dari SSTable yang digabungkan. Jika stempel waktu sel melampaui kualifikasi TTL, database akan mengecualikan sel. Jika ada dua versi yang diberi stempel waktu untuk sel tertentu, Cassandra hanya menyertakan nilai terbaru dalam SSTable yang digabungkan.
Jalur baca data
Saat operasi baca mencapai node pemrosesan yang sesuai, proses baca untuk mendapatkan data guna memenuhi hasil kueri sama untuk kedua database.
Untuk setiap SSTable di disk yang mungkin berisi hasil kueri, filter Bloom diperiksa untuk menentukan apakah setiap file berisi baris yang akan ditampilkan. Karena filter Bloom dijamin tidak akan pernah memberikan negatif palsu, semua SSTable yang memenuhi syarat ditambahkan ke daftar kandidat untuk disertakan dalam pemrosesan hasil baca lebih lanjut.
Operasi baca dilakukan menggunakan tampilan gabungan yang dibuat dari memtable dan SSTable kandidat di disk. Karena semua kunci diurutkan secara leksikografis, tampilan gabungan yang dipindai untuk mendapatkan hasil kueri dapat diperoleh secara efisien.
Di Cassandra, serangkaian node pemrosesan yang ditentukan oleh tingkat konsistensi operasi harus berpartisipasi dalam operasi. Di Bigtable, hanya node yang bertanggung jawab atas rentang kunci yang perlu dikonsultasikan. Untuk Cassandra, Anda perlu mempertimbangkan implikasi untuk penskalaan komputasi karena kemungkinan beberapa node akan memproses setiap pembacaan.
Hasil baca dapat dibatasi di node pemrosesan dengan cara yang sedikit berbeda.
Di Cassandra, klausa WHERE dalam kueri CQL membatasi baris yang ditampilkan. Batasan ini adalah kolom dalam kunci utama atau kolom yang disertakan dalam indeks sekunder dapat digunakan untuk membatasi hasil.
Bigtable menawarkan berbagai macam filter yang kaya yang memengaruhi baris atau sel yang diambil oleh kueri baca.
Ada tiga kategori filter:
- Membatasi filter, yang mengontrol baris atau sel yang disertakan dalam respons.
- Mengubah filter, yang memengaruhi data atau metadata untuk setiap sel.
- Menyusun filter, yang memungkinkan Anda menggabungkan beberapa filter menjadi satu filter.
Filter pembatas adalah yang paling umum digunakan—misalnya, ekspresi reguler family kolom dan ekspresi reguler penentu kolom.
Penyimpanan data fisik
Bigtable dan Cassandra menyimpan data dalam SSTable, yang digabungkan secara rutin selama fase pemadatan. Kompresi data SSTable menawarkan manfaat serupa untuk mengurangi ukuran penyimpanan. Namun, kompresi diterapkan secara otomatis di Bigtable dan merupakan opsi konfigurasi di Cassandra.
Saat membandingkan kedua database, Anda harus memahami cara setiap database menyimpan data secara fisik dengan cara yang berbeda dalam aspek berikut:
- Strategi distribusi data
- Jumlah versi sel yang tersedia
- Jenis disk penyimpanan
- Mekanisme ketahanan dan replikasi data
Distribusi data
Di Cassandra, hash yang konsisten dari kolom partisi kunci utama adalah metode yang direkomendasikan untuk menentukan distribusi data di berbagai SSTable yang ditayangkan oleh node cluster.
Bigtable menggunakan awalan variabel ke kunci baris lengkap untuk menempatkan data secara leksikografis di SSTable.
Versi sel
Cassandra hanya menyimpan satu versi nilai sel aktif. Jika dua operasi tulis dilakukan ke sel, kebijakan penulisan terakhir yang menang memastikan bahwa hanya satu nilai yang ditampilkan.
Bigtable tidak membatasi jumlah versi yang diberi stempel waktu untuk setiap sel. Batasan ukuran baris lainnya mungkin berlaku. Jika tidak ditetapkan oleh permintaan klien, stempel waktu ditentukan oleh layanan Bigtable pada saat node pemrosesan menerima mutasi. Versi sel dapat dipangkas menggunakan kebijakan pengumpulan sampah yang dapat berbeda untuk setiap family kolom tabel, atau dapat difilter dari kumpulan hasil kueri melalui API.
Penyimpanan disk
Cassandra menyimpan SSTable pada disk yang terpasang ke setiap node cluster. Untuk menyeimbangkan kembali data di Cassandra, file harus disalin secara fisik antar-server.
Bigtable menggunakan Colossus untuk menyimpan SSTable. Karena Bigtable menggunakan sistem file terdistribusi ini, layanan Bigtable dapat hampir secara instan menetapkan ulang SSTable ke node yang berbeda.
Ketahanan dan replikasi data
Cassandra memberikan daya tahan data melalui setelan faktor replikasi. Faktor replikasi menentukan jumlah salinan SSTable yang disimpan di node yang berbeda dalam cluster. Setelan umum untuk faktor replikasi adalah
3, yang tetap memungkinkan jaminan konsistensi yang lebih kuat dengan QUORUM atau
LOCAL_QUORUM meskipun terjadi kegagalan node.
Dengan Bigtable, jaminan durabilitas data yang tinggi diberikan melalui replikasi yang disediakan Colossus.
Diagram berikut menggambarkan tata letak data fisik, node pemrosesan komputasi, dan lapisan perutean untuk Bigtable:

Di lapisan penyimpanan Colossus, setiap node ditetapkan untuk menyajikan data yang disimpan dalam serangkaian SSTable. SSTable tersebut berisi data untuk rentang kunci baris yang ditetapkan secara dinamis ke setiap node. Meskipun diagram menampilkan tiga SSTable untuk setiap node, kemungkinan ada lebih banyak karena SSTable terus dibuat saat node menerima perubahan data baru.
Setiap node memiliki log bersama. Penulisan yang diproses oleh setiap node akan langsung dipertahankan ke log bersama sebelum klien menerima konfirmasi penulisan. Karena penulisan ke Colossus direplikasi beberapa kali, daya tahan dipastikan meskipun terjadi kegagalan hardware node sebelum data dipertahankan ke SSTable untuk rentang baris.
Antarmuka aplikasi
Awalnya, akses database Cassandra diekspos melalui Thrift API, tetapi metode akses ini tidak digunakan lagi. Interaksi klien yang direkomendasikan adalah melalui CQL.
Mirip dengan Thrift API asli Cassandra, akses database Bigtable disediakan melalui API yang membaca dan menulis data berdasarkan kunci baris yang diberikan.
Seperti Cassandra, Bigtable memiliki antarmuka command line,
yang disebut
CLI cbt
, dan library klien yang mendukung banyak bahasa pemrograman umum. Library ini dibangun di atas API gRPC dan REST. Aplikasi yang ditulis untuk Hadoop dan mengandalkan library Apache HBase open source untuk Java dapat terhubung tanpa perubahan signifikan ke Bigtable. Untuk aplikasi yang tidak memerlukan kompatibilitas HBase, sebaiknya gunakan klien Java Bigtable bawaan.
Kontrol Identity and Access Management (IAM) Bigtable terintegrasi sepenuhnya dengan Google Cloud, dan tabel juga dapat digunakan sebagai sumber data eksternal dari BigQuery.
Penyiapan database
Saat menyiapkan cluster Cassandra, Anda harus membuat beberapa keputusan konfigurasi dan menyelesaikan beberapa langkah. Pertama, Anda harus mengonfigurasi node server untuk menyediakan kapasitas komputasi dan menyediakan penyimpanan lokal. Saat menggunakan faktor replikasi tiga, yang merupakan setelan yang direkomendasikan dan paling umum, Anda harus menyediakan penyimpanan untuk menyimpan data tiga kali lebih banyak dari yang Anda harapkan untuk disimpan di cluster Anda. Anda juga harus menentukan dan menetapkan konfigurasi untuk vnode, rak, dan replikasi.
Pemisahan komputasi dari penyimpanan di Bigtable menyederhanakan penskalaan kluster ke atas dan ke bawah dibandingkan dengan Cassandra. Dalam cluster yang berjalan normal, Anda biasanya hanya perlu memperhatikan total penyimpanan yang digunakan oleh tabel terkelola, yang menentukan jumlah minimum node, dan memiliki cukup banyak node untuk mempertahankan QPS saat ini.
Anda dapat menyesuaikan ukuran cluster Bigtable dengan cepat jika cluster disediakan secara berlebihan atau kurang berdasarkan beban produksi.
Penyimpanan Bigtable
Selain lokasi geografis cluster awal, satu-satunya pilihan yang perlu Anda buat saat membuat instance Bigtable adalah jenis penyimpanan. Bigtable menawarkan dua opsi untuk penyimpanan: solid-state drive (SSD) atau hard disk drive (HDD). Semua cluster dalam instance harus menggunakan jenis penyimpanan yang sama.
Saat memperhitungkan kebutuhan penyimpanan dengan Bigtable, Anda tidak perlu memperhitungkan replika penyimpanan seperti yang Anda lakukan saat menentukan ukuran cluster Cassandra. Tidak ada penurunan kepadatan penyimpanan untuk mencapai fault tolerance seperti yang terlihat di Cassandra. Selain itu, karena penyimpanan tidak perlu disediakan secara eksplisit, Anda hanya ditagih untuk penyimpanan yang digunakan.
SSD
Kapasitas node SSD sebesar 5 TB, yang lebih disukai untuk sebagian besar beban kerja, memberikan kepadatan penyimpanan yang lebih tinggi dibandingkan dengan konfigurasi yang direkomendasikan untuk mesin Cassandra, yang memiliki kepadatan penyimpanan maksimum praktis kurang dari 2 TB untuk setiap node. Saat menilai kebutuhan kapasitas penyimpanan, ingatlah bahwa Bigtable hanya menghitung satu salinan data; sebagai perbandingan, Cassandra perlu memperhitungkan tiga salinan data dalam sebagian besar konfigurasi.
Meskipun QPS tulis untuk SSD hampir sama dengan HDD, SSD memberikan QPS baca yang jauh lebih tinggi daripada HDD. Penyimpanan SSD dihargai sama atau mendekati biaya penyediaan persistent disk SSD dan bervariasi menurut region.
HDD
Jenis penyimpanan HDD memungkinkan kepadatan penyimpanan yang cukup besar—16 TB untuk setiap node. Sebagai gantinya, pembacaan acak jauh lebih lambat, hanya mendukung 500 baris yang dibaca per detik untuk setiap node. HDD lebih disukai untuk beban kerja yang intensif dalam penulisan dan pembacaan diharapkan berupa pemindaian rentang yang terkait dengan pemrosesan batch. Penyimpanan HDD dihargai sama atau mendekati biaya yang terkait dengan Cloud Storage dan bervariasi menurut region.
Pertimbangan ukuran cluster
Saat Anda menentukan ukuran instance Bigtable untuk bersiap memigrasikan workload Cassandra, ada beberapa pertimbangan saat Anda membandingkan cluster Cassandra pusat data tunggal dengan instance Bigtable cluster tunggal, dan cluster Cassandra multi-pusat data dengan instance Bigtable multi-cluster. Panduan di bagian berikut mengasumsikan bahwa tidak ada perubahan model data yang signifikan yang diperlukan untuk migrasi, dan ada kompresi penyimpanan yang setara antara Cassandra dan Bigtable.
Cluster pusat data tunggal
Saat membandingkan cluster pusat data tunggal dengan instance Bigtable
cluster tunggal, Anda harus mempertimbangkan terlebih dahulu persyaratan
penyimpanan. Anda dapat memperkirakan ukuran yang tidak direplikasi dari setiap keyspace menggunakan
perintah
tablestats nodetool
dan membagi total ukuran penyimpanan yang di-flush dengan faktor replikasi keyspace. Kemudian, Anda membagi jumlah penyimpanan yang tidak direplikasi dari semua keyspace dengan
3,5 TB
(5 TB * 0,70)
untuk menentukan jumlah node SSD yang disarankan untuk menangani penyimpanan saja. Seperti yang telah dibahas, Bigtable menangani replikasi dan daya tahan penyimpanan dalam tingkat terpisah yang transparan bagi pengguna.
Selanjutnya, Anda harus mempertimbangkan persyaratan komputasi untuk jumlah node. Anda dapat melihat metrik aplikasi klien dan server Cassandra untuk mendapatkan perkiraan jumlah pembacaan dan penulisan berkelanjutan yang telah dieksekusi. Untuk memperkirakan jumlah node SSD minimum untuk menjalankan workload Anda, bagi metrik tersebut dengan 10.000. Anda mungkin memerlukan lebih banyak node untuk aplikasi yang memerlukan hasil kueri latensi rendah. Google merekomendasikan agar Anda menguji performa Bigtable dengan data dan kueri yang representatif untuk menetapkan metrik QPS per node yang dapat dicapai untuk beban kerja Anda.
Jumlah node yang diperlukan untuk cluster harus sama dengan kebutuhan penyimpanan dan komputasi yang lebih besar. Jika Anda ragu tentang kebutuhan penyimpanan atau throughput, Anda dapat mencocokkan jumlah node Bigtable dengan jumlah mesin Cassandra umum. Anda dapat menskalakan cluster Bigtable ke atas atau ke bawah agar sesuai dengan kebutuhan beban kerja dengan upaya minimal dan tanpa periode nonaktif.
Cluster multi-pusat data
Dengan cluster multi-pusat data, konfigurasi instance Bigtable lebih sulit ditentukan. Idealnya, Anda harus memiliki cluster di instance untuk setiap pusat data dalam topologi Cassandra. Setiap cluster Bigtable dalam instance harus menyimpan semua data dalam instance dan harus dapat menangani total kecepatan penyisipan di seluruh cluster. Cluster dalam instance dapat dibuat di region cloud yang didukung di seluruh dunia.
Teknik untuk memperkirakan kebutuhan penyimpanan serupa dengan pendekatan untuk
cluster pusat data tunggal. Anda menggunakan nodetool untuk merekam ukuran penyimpanan
setiap keyspace di cluster Cassandra, lalu membagi ukuran tersebut dengan jumlah
replika. Anda harus ingat bahwa keyspace tabel mungkin memiliki faktor replikasi yang berbeda untuk setiap pusat data.
Jumlah node di setiap cluster dalam instance harus dapat menangani semua penulisan di seluruh cluster dan semua pembacaan ke setidaknya dua pusat data untuk mempertahankan tujuan tingkat layanan (SLO) selama gangguan cluster. Pendekatan umum adalah memulai dengan semua cluster yang memiliki kapasitas node yang setara dengan pusat data tersibuk di cluster Cassandra. Cluster Bigtable dalam instance dapat ditingkatkan atau diturunkan skalanya secara individual agar sesuai dengan kebutuhan workload tanpa periode nonaktif.
Administrasi
Bigtable menyediakan komponen yang terkelola sepenuhnya untuk fungsi administrasi umum yang dilakukan di Cassandra.
Pencadangan dan pemulihan
Bigtable menyediakan dua metode untuk memenuhi kebutuhan pencadangan umum: pencadangan Bigtable dan ekspor data terkelola.
Anda dapat menganggap cadangan Bigtable sebagai analog dengan fitur snapshot nodetool Cassandra versi terkelola.
Cadangan Bigtable membuat salinan tabel yang dapat dipulihkan, yang disimpan sebagai objek anggota cluster. Anda dapat memulihkan cadangan sebagai tabel baru di cluster yang memulai pencadangan. Pencadangan dirancang untuk membuat titik pemulihan jika terjadi kerusakan tingkat aplikasi. Cadangan yang Anda buat melalui utilitas ini tidak menggunakan resource node dan harganya sama atau mendekati harga Cloud Storage. Anda dapat memanggil pencadangan Bigtable secara terprogram atau melalui konsol Bigtable. Google Cloud
Cara lain untuk mencadangkan Bigtable adalah dengan menggunakan ekspor data terkelola ke Cloud Storage. Anda dapat mengekspor ke format file Avro, Parquet, atau Hadoop Sequence. Dibandingkan dengan cadangan Bigtable, ekspor memerlukan waktu lebih lama untuk dieksekusi dan menimbulkan biaya komputasi tambahan karena ekspor menggunakan Dataflow. Namun, ekspor ini membuat file data portabel yang dapat Anda kueri secara offline atau impor ke sistem lain.
Mengubah ukuran
Karena Bigtable memisahkan penyimpanan dan komputasi, Anda dapat menambahkan atau menghapus node Bigtable sebagai respons terhadap permintaan kueri dengan lebih lancar daripada di Cassandra. Arsitektur homogen Cassandra mengharuskan Anda menyeimbangkan ulang node (atau vnode) di seluruh mesin dalam cluster.
Anda dapat mengubah ukuran cluster secara manual di konsol Google Cloud atau secara terprogram menggunakan Cloud Bigtable API. Menambahkan node ke cluster dapat menghasilkan peningkatan performa yang terlihat dalam hitungan menit. Beberapa pelanggan telah berhasil menggunakan penskala otomatis open source yang dikembangkan oleh Spotify.
Pemeliharaan internal
Layanan Bigtable menangani tugas pemeliharaan internal Cassandra umum dengan lancar seperti patching OS, pemulihan node, perbaikan node, pemantauan pemadatan penyimpanan, dan rotasi sertifikat SSL.
Pemantauan
Menghubungkan Bigtable ke visualisasi atau pemberitahuan metrik tidak memerlukan upaya administrasi atau pengembangan. Halaman konsol Bigtable Google Cloud dilengkapi dengan dasbor bawaan untuk melacak metrik throughput dan pemakaian di tingkat instance, cluster, dan tabel. Tampilan dan pemberitahuan kustom dapat dibuat di dasbor Cloud Monitoring, tempat metrik tersedia secara otomatis.
Key Visualizer Bigtable, fitur pemantauan di konsol Google Cloud , memungkinkan Anda melakukan penyesuaian performa tingkat lanjut.
IAM dan keamanan
Di Bigtable, otorisasi terintegrasi sepenuhnya ke dalam Google Cloud's framework IAM dan hanya memerlukan penyiapan dan pemeliharaan minimal. Akun dan sandi pengguna lokal tidak dibagikan dengan aplikasi klien; sebagai gantinya, izin dan peran terperinci diberikan kepada pengguna tingkat organisasi dan akun layanan.
Bigtable otomatis mengenkripsi semua data dalam penyimpanan dan saat transit. Tidak ada opsi untuk menonaktifkan fitur ini. Semua akses administratif dicatat sepenuhnya. Anda dapat menggunakan Kontrol Layanan VPC untuk mengontrol akses ke instance Bigtable dari luar jaringan yang disetujui.
Langkah berikutnya
- Baca tentang desain skema Bigtable.
- Coba codelab Bigtable untuk pengguna Cassandra.
- Pelajari emulator Bigtable.
- Pelajari arsitektur referensi, diagram, dan praktik terbaik tentang Google Cloud. Lihat Cloud Architecture Center kami.