
Bigtable
Scala le tue applicazioni sensibili alla latenza con il pioniere di NoSQL
Servizio di database NoSQL a bassa latenza, compatibile con HBase e Cassandra per machine learning, analisi operativa e applicazioni rivolte agli utenti.
Inizia con un'istanza di prova senza costi.

Funzionalità
Bassa latenza e velocità effettiva elevata
Bigtable è uno spazio di archiviazione a colonne con coppie chiave-valore, ideale per l'accesso rapido a dati strutturati, semistrutturati o non strutturati. Questo rende i workload sensibili alla latenza, come la personalizzazione, perfetti per Bigtable.
I contatori distribuiti, l'elevata portata di lettura e scrittura per dollaro lo rendono anche una soluzione ideale per i casi d'uso di clickstream e IoT, nonché per l'analisi batch per applicazioni HPC (computing ad alte prestazioni), incluso l'addestramento di modelli ML.
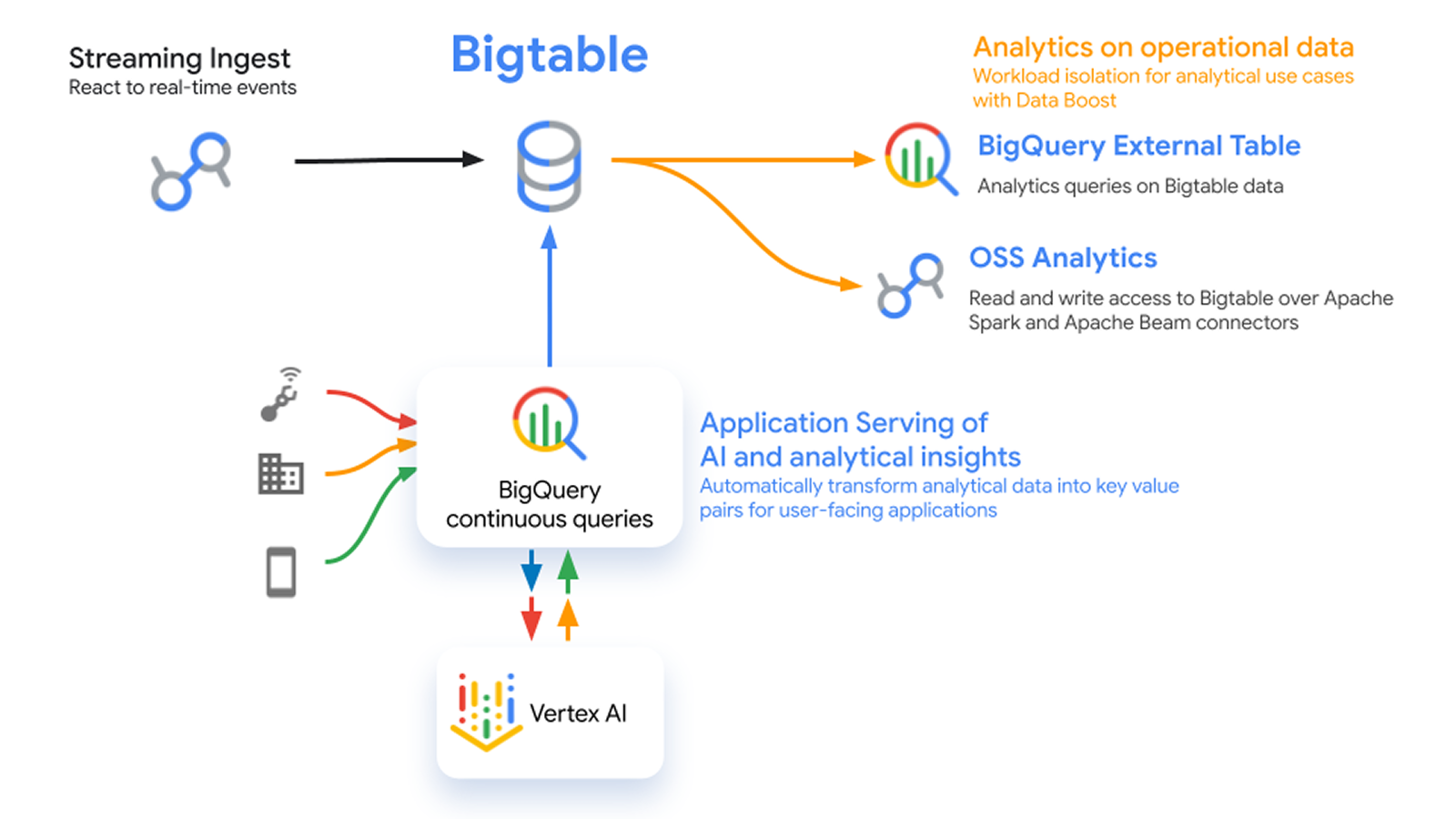
Architettura di archiviazione ibrida
Il tiering automatico e senza interruzioni dei dati di Bigtable tra RAM, SSD e HDD consente di offrire prestazioni elevate a costi contenuti. Fornisci latenze molto basse con la RAM ed elimina i problemi di hotspot senza bisogno di un livello di memorizzazione nella cache, esegui il tiering dei dati a cui si accede raramente su HDD per ottenere un notevole risparmio sui costi senza dover gestire le pipeline di dati e senza l'onere di mantenere i dati sincronizzati tra più sistemi.
SQL e viste materializzate continue
Bigtable SQL consente agli utenti di creare applicazioni completamente gestite e in tempo reale, utilizzando una sintassi SQL familiare, con funzionalità specializzate che preservano lo schema flessibile di Bigtable. Puoi anche utilizzare l'interfaccia SQL per creare viste materializzate incrementali che semplificano la creazione di metriche in tempo reale. Una vista materializzata Bigtable manterrà automaticamente i dati aggiornati elaborando le modifiche man mano che arrivano, senza influire sulle prestazioni di lettura e scrittura e ridimensionandosi automaticamente in risposta al traffico.
Flessibilità dei modelli di dati
Bigtable consente al tuo modello di dati di evolversi in modo organico. Archivia qualsiasi cosa, da valori scalari, JSON, buffer di protocollo, Avro, Arrow a incorporamenti, immagini, e aggiungi/rimuovi in modo dinamico nuove colonne in base alle tue esigenze. Fornisci gestione a bassa latenza o analisi in batch ad alte prestazioni su dati non strutturati e non elaborati in un unico database.
Migrazione facile dai database NoSQL
Bigtable offre le API Apache Cassandra e HBase e strumenti per la migrazione che consentono un onboarding più rapido e semplice, garantendo una migrazione dei dati accurata e con uno sforzo ridotto. La libreria di replica HBase di Bigtable e Cassandra Proxy consentono migrazioni live senza tempi di inattività, mentre Data Bridge di Bigtable e lo strumento di migrazione Aerospike semplificano le migrazioni rispettivamente da Amazon DynamoDB e Aerospike.

Da una singola zona fino a otto regioni contemporaneamente
Le app supportate da Bigtable possono offrire letture e scritture a bassa latenza con configurazioni multi-primary distribuite a livello globale, ovunque si trovino gli utenti. Le istanze di zona sono ideali per risparmiare sui costi e possono essere scalate senza problemi a deployment multiregionali con replica automatica. Quando esegui un'istanza multiregionale, il tuo database è protetto dagli errori a livello di regione e offre una disponibilità leader del settore del 99,999%.
Scalabilità di lettura e scrittura senza limiti
Bigtable disaccoppia le risorse di computing dall'archiviazione dei dati, consentendo di regolare in modo trasparente le risorse di elaborazione. Ogni nodo aggiuntivo è in grado di elaborare bene sia le letture che le scritture, fornendo scalabilità orizzontale senza sforzo. Bigtable ottimizza le prestazioni scalando automaticamente le risorse per adattarsi al traffico del server, gestendo lo sharding, la replica e l'elaborazione delle query.
Elaborazione dei dati ad alte prestazioni e isolata dai carichi di lavoro
Bigtable Data Boost consente agli utenti di eseguire query analitiche e processi ETL in batch, addestrare modelli ML o esportare i dati più velocemente senza influire sui workload transazionali. Data Boost non richiede gestione o pianificazione della capacità. Consente di eseguire query dirette sui dati archiviati nel sistema di archiviazione distribuito di Google Colossus, sfruttando la capacità on demand che consente agli utenti di gestire facilmente carichi di lavoro misti e condividere i dati senza preoccupazioni.
Supporto avanzato per applicazioni e strumenti
Connettiti facilmente all'ecosistema open source con l'API Apache HBase. Crea applicazioni basate sui dati più rapidamente con integrazioni perfette con Apache Spark, Hadoop, GKE, Dataflow, Dataproc, Vertex AI Vector Search e BigQuery. Vai incontro ai team di sviluppo con SQLe librerie client per Java, Go, Python, C#, Node.js, PHP, Ruby, C++, HBase e l'integrazione con LangChain.
Sviluppo agentico
Con il supporto MCP, Agent Development Kit (ADK) e l'integrazione con LangChain, puoi creare facilmente applicazioni agentiche per supportare l'automazione dei processi o le esperienze utente conversazionali. Utilizzando le skill dell'agente Bigtable con Antigravity, il tuo IDE preferito o l'interfaccia a riga di comando, porta la produttività degli sviluppatori a un livello superiore, creando di più e più velocemente con Bigtable.
Nessun costo nascosto
Nessun addebito per IOPS e per l'esecuzione o il ripristino dei backup, e nessun costo sproporzionato di lettura/scrittura che influisce sul budget man mano che i tuoi carichi di lavoro si evolvono.
Change Data Capture ed eventi dei dati in tempo reale
Utilizza le modifiche in tempo reale di Bigtable per acquisire i dati delle modifiche dai database Bigtable e integrarli con altri sistemi per analisi, trigger di eventi e conformità.
Sicurezza e controlli di livello aziendale
Chiavi di crittografia gestite dal cliente (CMEK) con supporto per Cloud External Key Manager, integrazione IAM per accesso e controlli, supporto per VPC-SC, Access Transparency, Access Approval e audit logging completo contribuiscono a garantire che i dati siano protetti e conformi alle normative. Il controllo dell'accesso granulare ti consente di autorizzare l'accesso a livello di tabella, colonna o riga.

Osservabilità
Monitora le prestazioni dei database Bigtable con le metriche lato server. Analizza i pattern di utilizzo con lo strumento di monitoraggio interattivo Key Visualizer. Usa le statistiche relative alle query e alle alle tabelle, nonché lo strumento per i tablet attivi per risolvere i problemi di prestazioni delle query e diagnosticare rapidamente i problemi di latenza con il monitoraggio lato client.
Disaster recovery
Esegui backup istantanei e incrementali del tuo database in modo conveniente e ripristina on demand. Archivia i backup in regioni diverse per una maggiore resilienza, esegui facilmente il ripristino tra istanze o progetti per scenari di test e di produzione.
Come funziona
Le istanze Bigtable forniscono computing e archiviazione in una o più regioni. Ogni cluster Bigtable può ricevere sia operazioni di lettura che di scrittura. I dati vengono automaticamente "suddivisi" per la scalabilità e replicati tra i cluster in modo asincrono. Un orologio distribuito denominato TrueTime garantisce che le transazioni vengano ordinate correttamente.
Le istanze Bigtable forniscono computing e archiviazione in una o più regioni. Ogni cluster Bigtable può ricevere sia operazioni di lettura che di scrittura. I dati vengono automaticamente "suddivisi" per la scalabilità e replicati tra i cluster in modo asincrono. Un orologio distribuito denominato TrueTime garantisce che le transazioni vengano ordinate correttamente.

Analisi in tempo reale
Aumenta la frequenza di aggiornamento dei dati e riduci la latenza delle query
MLB acquisisce tutti i movimenti della palla e di ogni giocatore in tempo reale con Bigtable
Scopri come creare una piattaforma di analisi in tempo reale con BigQuery e Bigtable
Scopri come utilizzare la trasformazione Enrichment (di arricchimento) di Apache Beam per arricchire gli eventi in modalità flusso in Dataflow
Risorse per l'apprendimento
Aumenta la frequenza di aggiornamento dei dati e riduci la latenza delle query
MLB acquisisce tutti i movimenti della palla e di ogni giocatore in tempo reale con Bigtable
Scopri come creare una piattaforma di analisi in tempo reale con BigQuery e Bigtable
Scopri come utilizzare la trasformazione Enrichment (di arricchimento) di Apache Beam per arricchire gli eventi in modalità flusso in Dataflow
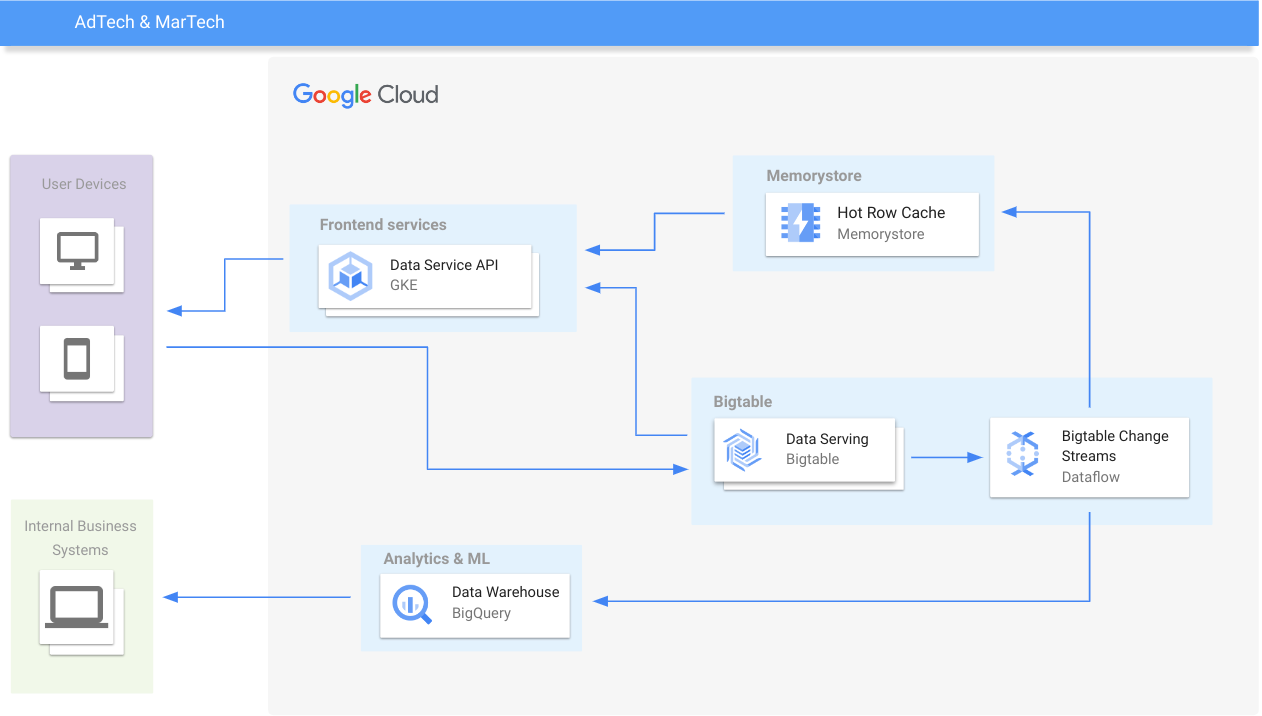
AdTech e vendita al dettaglio
Personalizza le esperienze in tempo reale
Risorse per l'apprendimento
Personalizza le esperienze in tempo reale
Data fabric e analisi operativa
Consolida i silos di dati e fai lo scale out dei sistemi legacy
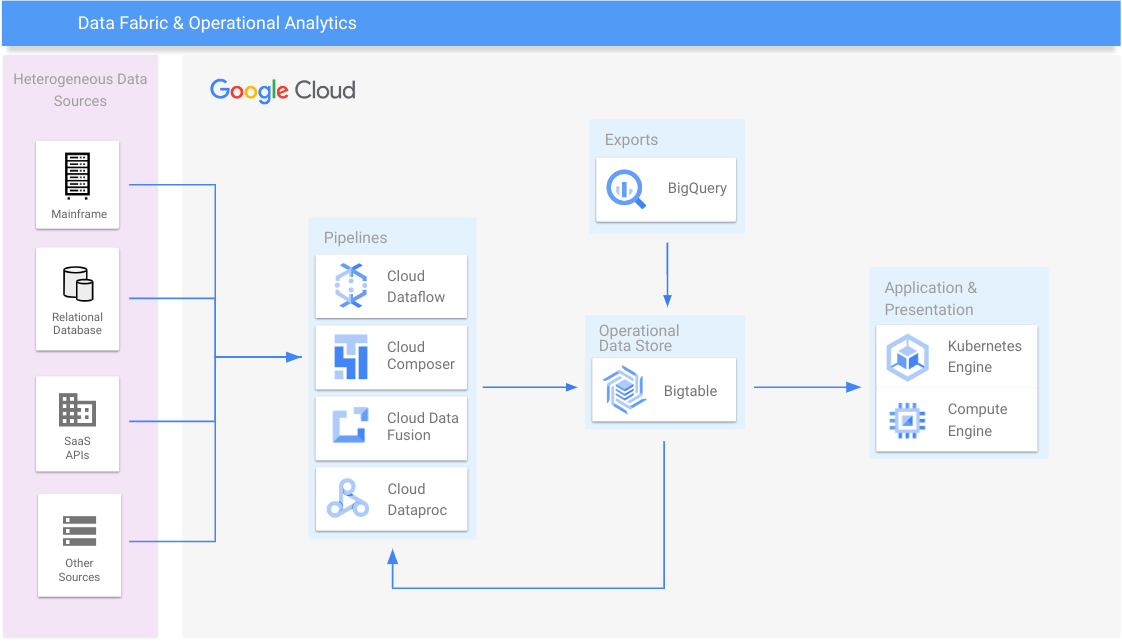
Risorse per l'apprendimento
Consolida i silos di dati e fai lo scale out dei sistemi legacy
Cybersicurezza
Rilevare malware, frodi nei pagamenti, bloccare spam e truffe
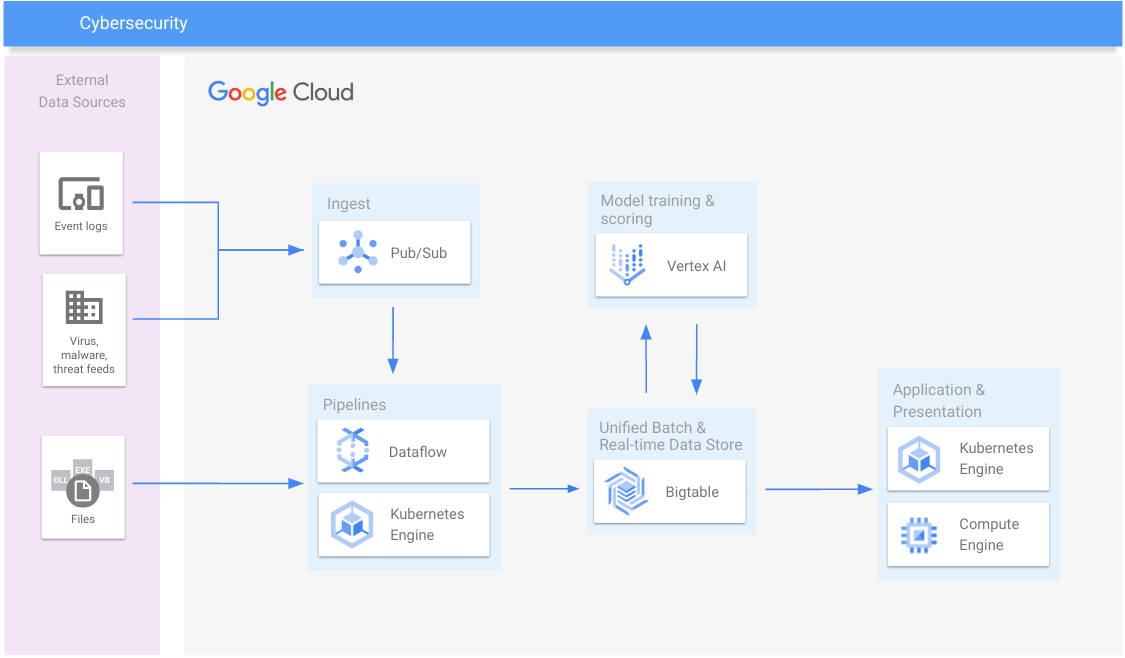
Risorse per l'apprendimento
Rilevare malware, frodi nei pagamenti, bloccare spam e truffe
Media
Fornisci analisi dei contenuti multimediali e del coinvolgimento
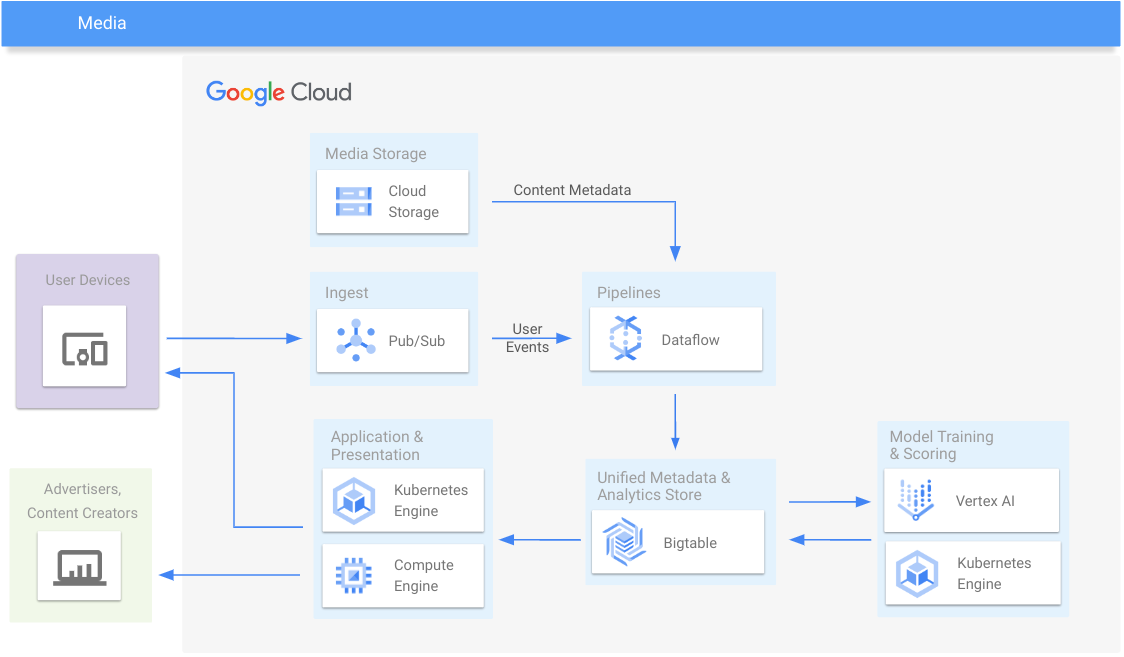
Risorse per l'apprendimento
Fornisci analisi dei contenuti multimediali e del coinvolgimento
Serie temporali e IoT
Gestisci i dati delle serie temporali su qualsiasi scala
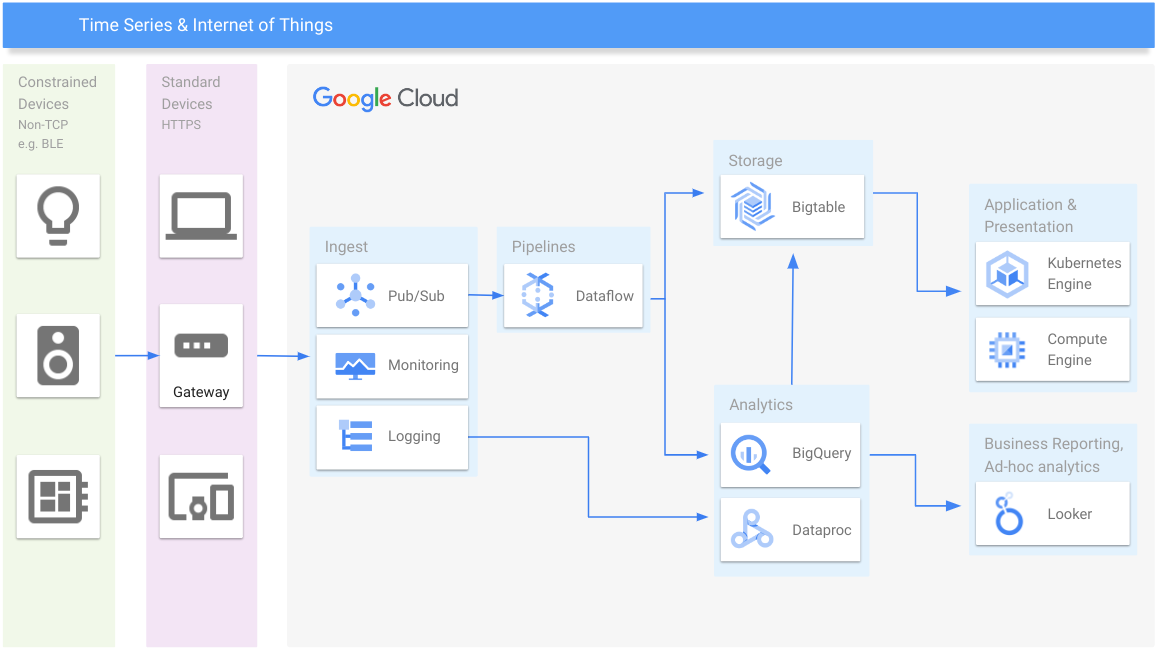
Risorse per l'apprendimento
Gestisci i dati delle serie temporali su qualsiasi scala
Infrastruttura di machine learning
Scala l'addestramento e l'erogazione dei modelli
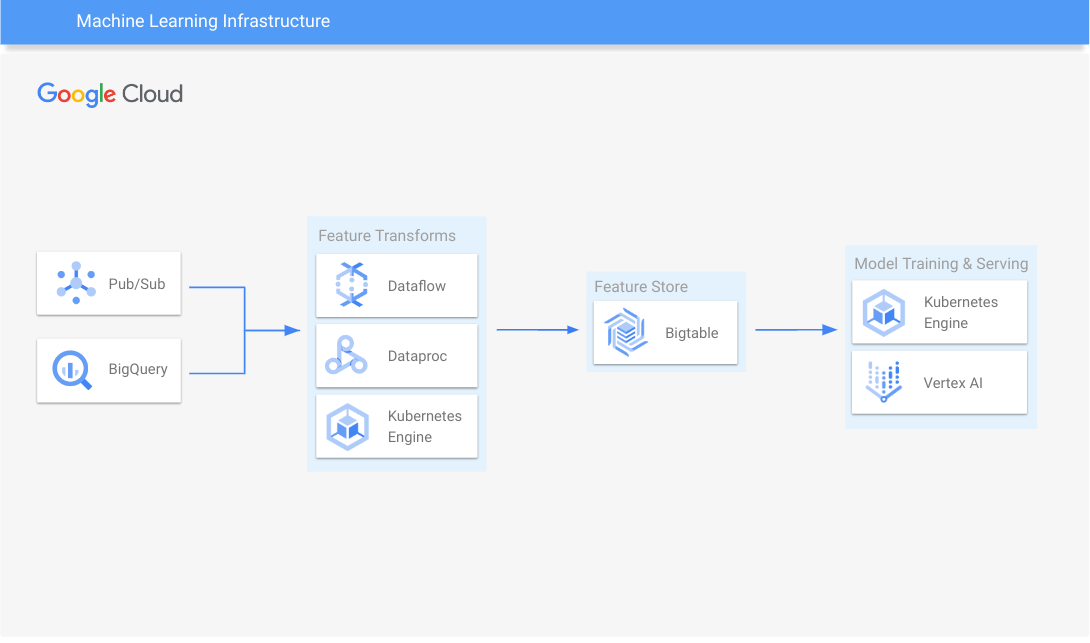
Scopri come utilizzare Bigtable con i più diffusi feature store open source.
Risorse per l'apprendimento
Scala l'addestramento e l'erogazione dei modelli
Scopri come utilizzare Bigtable con i più diffusi feature store open source.
Prezzi
| Come funzionano i prezzi di Bigtable | I prezzi di Bigtable si basano sulla capacità di calcolo, l'archiviazione dei database, l'archiviazione di backup e l'utilizzo della rete. Gli sconti per impegno di utilizzo riducono ulteriormente il prezzo. | |
|---|---|---|
| Servizio | Descrizione | Prezzo |
Capacità di calcolo | Versione Enterprise Dotata di funzionalità chiave per machine learning, serie temporali, analisi operative e applicazioni rivolte agli utenti su larga scala con una bassa latenza in millisecondi a singola cifra. Il provisioning della capacità di calcolo viene eseguito come nodi. | A partire da $ 0,65 per nodo all'ora |
Versione Enterprise Plus Supporta i workload più impegnativi con i massimi livelli di configurabilità, prestazioni, osservabilità e governance. Include tutte le funzionalità della versione Enterprise e può offrire una latenza inferiore al millisecondo. Il provisioning della capacità di calcolo viene eseguito come nodi. | A partire da 0,85 $ per nodo all'ora | |
Livello in memoria Capacità di throughput di lettura in memoria per letture a latenza molto bassa con elevata resistenza agli hotspot. Disponibile solo nella versione Enterprise Plus. Il throughput di lettura viene fornito in incrementi di 40.000 righe (1 KB) al secondo, fino a 120.000 righe al secondo per nodo. | A partire da $ 0,20 per 40.000 righe al secondo di capacità | |
Data Boost | Risorse di calcolo isolate e on demand per l'elaborazione batch | A partire da 0,000845 $ per unità di elaborazione serverless all'ora |
Archiviazione dei dati | SSD I prezzi si basano sulle dimensioni fisiche delle tabelle. Ogni replica viene fatturata separatamente. Opzione consigliata per la pubblicazione a bassa latenza. | A partire da $ 0,17 per GB/mese |
HDD I prezzi si basano sulle dimensioni fisiche delle tabelle. Ogni replica viene fatturata separatamente. L'accesso sporadico utilizza HDD e viene fatturato alla stessa tariffa. | A partire da $ 0,026 per GB/mese | |
Backup | Backup standard I prezzi si basano sulle dimensioni fisiche dei backup. I backup di Bigtable sono incrementali. | A partire da $ 0,026 per GB/mese |
Hot backup Ottimizzati per una riduzione significativa dei tempi di ripristino. I prezzi si basano sulle dimensioni fisiche dei backup. | A partire da $ 0,12 per GB/mese | |
Rete | In entrata | Senza costi |
In uscita nella stessa regione | Senza costi | |
In uscita tra aree geografiche | A partire da 0,10 $ per GB | |
Replica | All'interno della stessa regione | Senza costi |
Tra regioni | A partire da $ 0,01 per GB | |
Scopri di più sui prezzi e sugli sconti per impegno di utilizzo Bigtable.
Come funzionano i prezzi di Bigtable
I prezzi di Bigtable si basano sulla capacità di calcolo, l'archiviazione dei database, l'archiviazione di backup e l'utilizzo della rete. Gli sconti per impegno di utilizzo riducono ulteriormente il prezzo.
Capacità di calcolo
Versione Enterprise
Dotata di funzionalità chiave per machine learning, serie temporali, analisi operative e applicazioni rivolte agli utenti su larga scala con una bassa latenza in millisecondi a singola cifra.
Il provisioning della capacità di calcolo viene eseguito come nodi.
Starting at
$ 0,65
per nodo all'ora
Versione Enterprise Plus
Supporta i workload più impegnativi con i massimi livelli di configurabilità, prestazioni, osservabilità e governance. Include tutte le funzionalità della versione Enterprise e può offrire una latenza inferiore al millisecondo.
Il provisioning della capacità di calcolo viene eseguito come nodi.
Starting at
0,85 $
per nodo all'ora
Livello in memoria
Capacità di throughput di lettura in memoria per letture a latenza molto bassa con elevata resistenza agli hotspot. Disponibile solo nella versione Enterprise Plus.
Il throughput di lettura viene fornito in incrementi di 40.000 righe (1 KB) al secondo, fino a 120.000 righe al secondo per nodo.
Starting at
$ 0,20
per 40.000 righe al secondo di capacità
Data Boost
Risorse di calcolo isolate e on demand per l'elaborazione batch
Starting at
0,000845 $
per unità di elaborazione serverless all'ora
Archiviazione dei dati
SSD
I prezzi si basano sulle dimensioni fisiche delle tabelle. Ogni replica viene fatturata separatamente. Opzione consigliata per la pubblicazione a bassa latenza.
Starting at
$ 0,17
per GB/mese
HDD
I prezzi si basano sulle dimensioni fisiche delle tabelle. Ogni replica viene fatturata separatamente. L'accesso sporadico utilizza HDD e viene fatturato alla stessa tariffa.
Starting at
$ 0,026
per GB/mese
Backup
Backup standard
I prezzi si basano sulle dimensioni fisiche dei backup. I backup di Bigtable sono incrementali.
Starting at
$ 0,026
per GB/mese
Hot backup
Ottimizzati per una riduzione significativa dei tempi di ripristino. I prezzi si basano sulle dimensioni fisiche dei backup.
Starting at
$ 0,12
per GB/mese
Rete
In entrata
Senza costi
In uscita nella stessa regione
Senza costi
In uscita tra aree geografiche
Starting at
0,10 $
per GB
Replica
All'interno della stessa regione
Senza costi
Tra regioni
Starting at
$ 0,01
per GB
Scopri di più sui prezzi e sugli sconti per impegno di utilizzo Bigtable.
Business case
Scopri come altre aziende hanno creato app innovative per offrire customer experience straordinarie, ridurre i costi e aumentare il ROI con Bigtable
Scopri come Box ha modernizzato i suoi database NoSQL con Bigtable
Box ha migliorato scalabilità e disponibilità riducendo al contempo i costi di gestione, attraverso una migrazione senza interruzioni.
Contenuti correlati

Sabre offre risultati di ricerca relativi ai viaggi con latenza e TCO inferiori grazie a Bigtable

Scopri come Plaid ha creato la sua piattaforma di analisi in tempo reale su BigQuery e Bigtable

Airship raggiunge oltre un milione di scritture e 700.000 letture al secondo in modo conveniente con Bigtable
Vantaggi e clienti
Fai crescere la tua attività con applicazioni innovative che scalano senza limiti per soddisfare qualsiasi domanda.
Ottieni il miglior rapporto prezzo-prestazioni e paga solo per ciò che utilizzi.
Esegui facilmente la migrazione da altri database NoSQL e fai deployment ibridi o multi-cloud con API open source e strumenti di migrazione.















Partner e integrazione
Approfitta dei partner con competenze di Bigtable per aiutarti in ogni fase del percorso, dalle valutazioni e i casi aziendali fino alle migrazioni e alla creazione di nuove app su Bigtable.

































Integratori di sistemi
Vuoi maggiori dettagli su quale integrazione di partner o terze parti si adatta meglio alla tua attività? Vai alla directory di Partners.
Scopri di più
Domande frequenti
Che tipo di database è Bigtable?
Bigtable è un servizio di database NoSQL, in particolare un archivio chiave-valore che consente tabelle molto larghe con decine di migliaia di colonne, chiamate anche database a colonne larghe o mappa multidimensionale distribuita. Bigtable è un database NoSQL nel cluster in senso "Non solo SQL" piuttosto che "zero SQL". Supporta molte funzionalità oltre alle ricerche chiave-valore, tra cui aggregazioni e indici secondari globali.
Bigtable è più simile ai progetti open source più diffusi che ha ispirato, come Apache HBase e Cassandra, ed è quindi la destinazione più comune per i clienti che si occupano di grandi volumi di dati e cercano una soluzione di database NoSQL ad alte prestazioni, economicamente conveniente e completamente gestita su Google Cloud.
Bigtable supporta SQL?
Oltre alle API chiave-valore, Bigtable supporta anche le query SQL in tre modi diversi:
- Per lo sviluppo di applicazioni a bassa latenza, Bigtable offre un'API SQL Query basata su GoogleSQL con estensioni per il modello di dati a colonne larghe simile a Cassandra Query Language (CQL). Supporta oltre 200 funzioni, tra cui aggregazioni (GROUP BY), windowing, funzioni geospaziali e di elaborazione JSON e ricerca vettoriale (kNN). Bigtable supporta sia la sintassi delle query standard sia quella con pipe.
- Per i casi d'uso di data science o altri tipi di elaborazione batch ed ETL, Bigtable supporta SparkSQL utilizzando il suo client Spark.
- Per gli utenti che vogliono eseguire analisi esplorative post-hoc o combinare dati da più origini per l'analisi in batch, i dati Bigtable sono accessibili anche da BigQuery. È sufficiente registrare le tabelle Bigtable in BigQuery ed eseguire query come su qualsiasi altra tabella BigQuery senza alcun ETL o duplicazione di dati.
Come faccio a eseguire la migrazione dei database a Bigtable?
Bigtable offre le API Apache Cassandra e HBase e strumenti per la migrazione che consentono un onboarding più rapido e semplice, garantendo una migrazione dei dati accurata e con uno sforzo ridotto. La libreria di replica HBase di Bigtable e gli strumenti di migrazione Cassandra consentono migrazioni live senza tempi di inattività. Bigtable offre anche utilità per semplificare le migrazioni da DynamoDB e Aerospike.
Bigtable è serverless?
L'archiviazione di Bigtable viene fatturata in base ai GB utilizzati, in modo simile a quanto avviene con un modello serverless. Bigtable offre anche scalabilità lineare orizzontale e può fare automaticamente lo scale up e lo scale down delle risorse di computing in risposta alle fluttuazioni della domanda. Quindi non richiede un impegno di capacità a lungo termine per l'archiviazione o l'elaborazione. Tuttavia, i prezzi per il computing a bassa latenza si basano sulla capacità e vengono fatturati per nodo, non per richiesta, dove ogni nodo può gestire fino a 17.000 richieste al secondo. Ciò rende il prezzo di Bigtable più favorevole per carichi di lavoro più grandi, ma meno ideale per applicazioni di piccole dimensioni, che potrebbero essere più adatte per database Google Cloud come Firestore.
Per l'elaborazione dei dati batch, Bigtable offre Data Boost, che fattura le unità di elaborazione serverless (SPU, Serverless Processing Unit).
Bigtable è una cache persistente?
Bigtable è un database con prestazioni simili a quelle di una cache, non una cache con persistenza. Offre potenti funzionalità di elaborazione in-database, un'API SQL, viste materializzate continue e indici secondari asincroni, utilizzando al contempo la tecnologia RDMA per fornire accesso diretto alla RAM per un throughput elevato e prestazioni non vincolate dalla capacità della CPU del server di database. Sebbene sia possibile utilizzare Bigtable in sostituzione di soluzioni di memorizzazione nella cache durevoli come MemoryDB, il contrario non è sempre vero, poiché soluzioni come Redis sono state progettate come cache, non come database.


















