
Bigtable
Latenzsensitive Anwendungen mit dem NoSQL-Pionier skalieren
Latenzarmer Cassandra- und HBase-kompatibler NoSQL-Datenbankdienst für maschinelles Lernen, operative Analysen und für Nutzer sichtbare Anwendungen.
Jetzt kostenlos testen.

Features
Niedrige Latenz und hoher Durchsatz
Bigtable ist ein spaltenorientierter Speicher für Schlüssel/Wert-Paare, der sich ideal für den schnellen Zugriff auf strukturierte, semistrukturierte oder unstrukturierte Daten eignet. Dies macht Bigtable zu einer perfekten Lösung für latenzempfindliche Arbeitslasten wie z. B. die Personalisierung.
Dank verteilter Zähler und eines hohen Lese- und Schreibdurchsatzes pro Dollar eignet sich Bigtable auch hervorragend für Clickstream- und IoT-Anwendungsfälle und sogar für Batchanalysen in Hochleistungs-Computing-Anwendungen (HPC), einschließlich des Trainings von ML-Modellen.
Hybride Speicherarchitektur
Bigtable bietet automatisches, nahtloses Data Tiering zwischen RAM, SSD und HDD, was zu hoher Leistung und Kosteneffizienz beiträgt. Mit RAM lassen sich extrem niedrige Latenzen erzielen und Hotspot-Probleme ohne Caching-Ebene vermeiden. Selten abgerufene Daten können auf Festplatten verschoben werden, um Kosten zu sparen. Datenpipelines müssen nicht verwaltet werden und die Synchronisierung von Daten zwischen mehreren Systemen entfällt.
SQL und kontinuierlich aktualisierte materialisierte Ansichten
Bigtable-SQL ermöglicht Nutzern, vollständig verwaltete Echtzeitanwendungen mit vertrauter SQL-Syntax zu erstellen. Dabei wird das flexible Schema von Bigtable mithilfe spezieller Funktionen beibehalten. Sie können die SQL-Schnittstelle auch zum Erstellen inkrementeller materialisierter Ansichten verwenden, mit denen sich Echtzeitmesswerte leichter erstellen lassen. Eine materialisierte Bigtable-Ansicht hält Daten automatisch auf dem neuesten Stand, da Änderungen sofort bei ihrem Eingang ohne Auswirkungen auf die Schreib- und Leseleistung verarbeitet werden. Außerdem wird die Ansicht entsprechend dem Traffic automatisch skaliert.
Flexibilität des Datenmodells
Mit Bigtable kann sich Ihr Datenmodell organisch weiterentwickeln. Sie können alles speichern, von Skalaren, JSON, Protokollzwischenspeichern, Avro und Arrow bis hin zu Einbettungen und Bildern. Außerdem lassen sich bei Bedarf neue Spalten dynamisch hinzufügen oder entfernen. Sorgen Sie für Bereitstellungen mit niedriger Latenz oder leistungsstarke Batchanalysen für unstrukturierte Rohdaten in einer einzigen Datenbank.
Einfache Migration von NoSQL-Datenbanken
Bigtable bietet Apache Cassandra- und HBase-APIs sowie Migrationstools, die ein schnelleres und einfacheres Onboarding ermöglichen, da eine genaue Datenmigration mit geringerem Aufwand gewährleistet ist. Die HBase Bigtable Replikationsbibliothek und der Cassandra-Proxy ermöglichen Live-Migrationen ohne Ausfallzeiten, während die Bigtable Data Bridge und das Aerospike Migration Tool die Migration von Amazon DynamoDB bzw. Aerospike vereinfachen.

Aus einer einzelnen Zone bis zu acht Regionen gleichzeitig
Von Bigtable unterstützte Anwendungen können Lese- und Schreibvorgänge mit niedriger Latenz und global verteilten Multi-Primary-Konfigurationen ausführen, unabhängig davon, wo sich Ihre Nutzer befinden. Zonale Instanzen sind eine kostengünstige Lösung und lassen sich nahtlos auf multiregionale Bereitstellungen mit automatischer Replikation skalieren. Beim Ausführen einer multiregionalen Instanz kann Ihre Datenbank außerdem einen regionalen Ausfall überstehen und bietet eine branchenführende Verfügbarkeit von 99,999 %.
Unbegrenzte Schreib- und Leseskalierbarkeit
Bigtable entkoppelt Rechenressourcen vom Datenspeicher, was die transparente Anpassung von Verarbeitungsressourcen ermöglicht. Jeder zusätzliche Knoten kann Lese- und Schreibvorgänge gleichermaßen gut verarbeiten und bietet so eine mühelose horizontale Skalierbarkeit. Bigtable optimiert die Leistung durch automatische Skalierung von Ressourcen zur Anpassung an den Server-Traffic, die Fragmentierung, Replikation und Abfrageverarbeitung.
Von Arbeitslasten isolierte Datenverarbeitung mit hoher Leistung
Mit Data Boost für Bigtable können Nutzer analytische Abfragen und ETL-Batchprozesse ausführen, ML-Modelle trainieren oder Daten schneller exportieren, ohne die transaktionalen Arbeitslasten zu beeinträchtigen. Data Boost erfordert keine Kapazitätsplanung oder ‑verwaltung. Damit lassen sich Daten, die im verteilten Speichersystem von Google, Colossus, gespeichert sind, direkt mit On-Demand-Kapazität abfragen. Nutzer können so problemlos gemischte Arbeitslasten bewältigen und Daten zuverlässig freigeben.
Umfassender Support für Anwendungen und Tools
Stellen Sie über die Apache HBase API eine einfache Verbindung zur Open-Source-Umgebung her. Datengestützte Anwendungen dank nahtloser Einbindung schneller mit Apache Spark, Hadoop, GKE, Dataflow, Dataproc, Vertex AI Vector Search und BigQuery. Holen Sie Entwicklungsteams dort ab, wo sie sich befinden mit SQL und Clientbibliotheken für Java, Go, Python, C#, Node.js, PHP, Ruby, C++, HBase und Einbindung in LangChain.
Agentische Entwicklung
Durch die Einbindung von MCP-Unterstützung, dem Agent Development Kit (ADK) und LangChain können Sie ganz einfach Agentenanwendungen erstellen, um die Prozessautomatisierung oder dialogorientierte Nutzererfahrungen zu unterstützen. Mit Bigtable Agent Skills und Antigravity, Ihrer bevorzugten IDE oder CLI können Sie Ihre Entwicklerproduktivität auf die nächste Stufe heben und mit Bigtable mehr und schneller entwickeln.
Keine versteckten Kosten
Keine IOPS-Gebühren, keine Kosten für das Erstellen oder Wiederherstellen von Sicherungen, keine unverhältnismäßigen Lese-/Schreibpreise, die sich auf Ihr Budget auswirken, wenn sich Ihre Arbeitslasten weiterentwickeln.
Veränderung von Daten in Echtzeit erfassen und Eventing
Mit Bigtable-Änderungsstreams lassen sich Änderungsdaten aus Bigtable-Datenbanken erfassen und in andere Systeme zur Analyse, Auslösung von Ereignissen und Compliance einbinden.
Sicherheit und Kontrolle für Unternehmen
Kundenverwaltete Verschlüsselungsschlüssel (CMEK) mit Unterstützung für Cloud External Key Manager, IAM-Integration für Zugriff und Steuerung, Unterstützung für VPC-SC, Access Transparency, Access Approval und ein umfassendes Audit-Logging tragen dazu bei, dass Ihre Daten geschützt sind und den Vorschriften entsprechen. Mit der detaillierten Zugriffssteuerung können Sie den Zugriff auf Tabellen-, Spalten- oder Zeilenebene autorisieren.

Beobachtbarkeit
Überwachen Sie die Leistung von Bigtable-Datenbanken mit serverseitigen Messwerten. Analysieren Sie Nutzungsmuster mit dem interaktiven Monitoring-Tool von Key Visualizer. Use Abfragestatistiken, Tabellenstatistiken und das Hot Tablets-Tool zum Beheben von Problemen mit der Abfrageleistung und zur schnellen Diagnose von Latenzproblemen mit dem clientseitigen Monitoring.
Notfallwiederherstellung
Inkrementelle Sicherungen Ihrer Datenbank sind kostengünstig und können bei Bedarf wiederhergestellt werden. Speichern Sie Sicherungen an verschiedenen Regionen, um die Ausfallsicherheit zu erhöhen, und stellen Sie mühelos zwischen Instanzen oder Projekten für Test- und Produktionsszenarien wieder her.
Funktionsweise
Bigtable-Instanzen bieten Rechen- und Speicherressourcen in einer oder mehreren Regionen. Jeder Bigtable-Cluster kann sowohl Lese- als auch Schreibvorgänge empfangen. Daten werden aus Gründen der Skalierbarkeit automatisch „geteilt“ und asynchron zwischen Clustern repliziert. Eine verteilte Uhr namens TrueTime sorgt dafür, dass Transaktionen in der richtigen Reihenfolge ausgeführt werden.
Bigtable-Instanzen bieten Rechen- und Speicherressourcen in einer oder mehreren Regionen. Jeder Bigtable-Cluster kann sowohl Lese- als auch Schreibvorgänge empfangen. Daten werden aus Gründen der Skalierbarkeit automatisch „geteilt“ und asynchron zwischen Clustern repliziert. Eine verteilte Uhr namens TrueTime sorgt dafür, dass Transaktionen in der richtigen Reihenfolge ausgeführt werden.

Echtzeitanalysen
Datenaktualität erhöhen und Abfragelatenz reduzieren
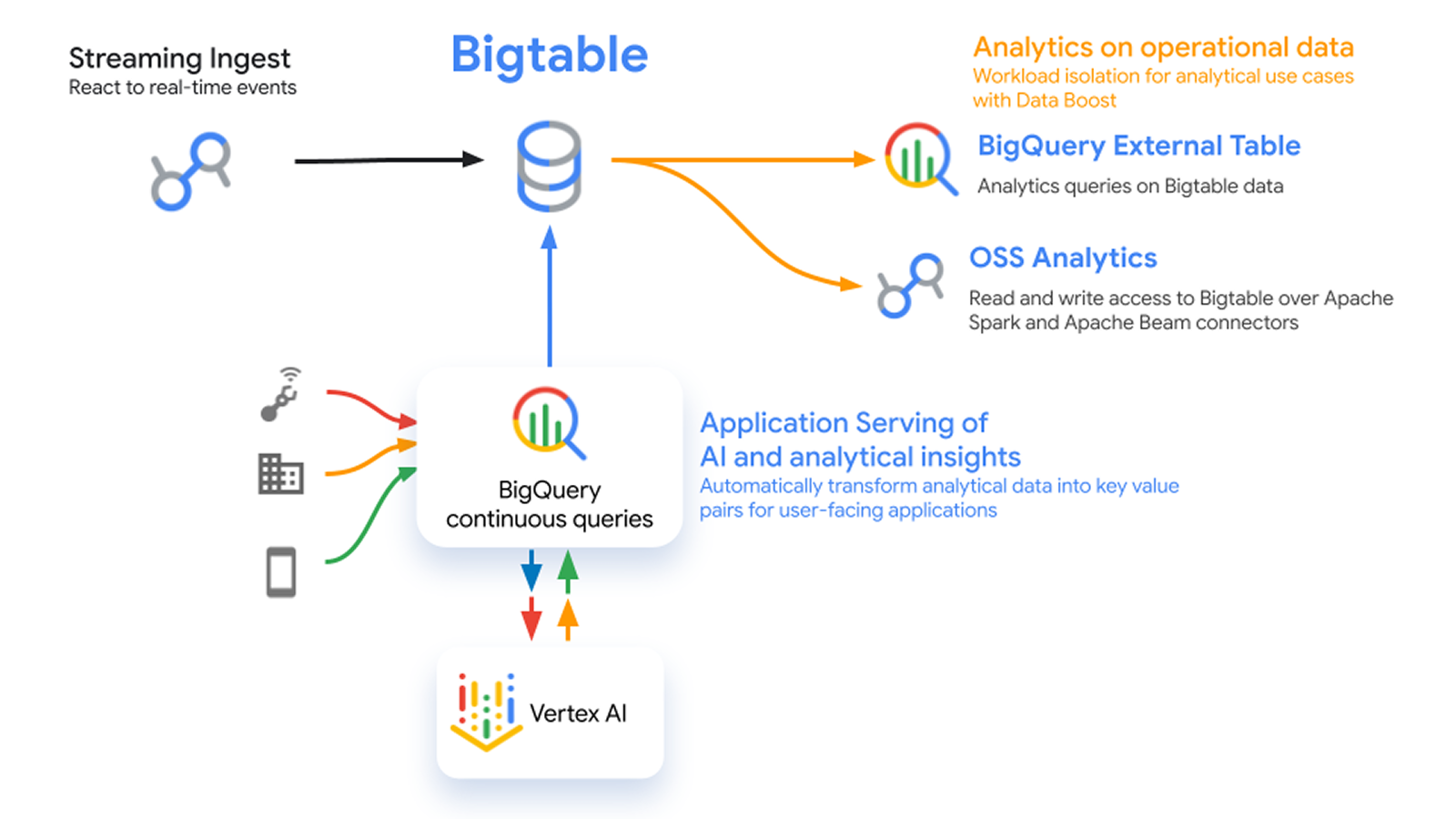
Die MLB erfasst die Bewegungen des Balls und aller Spieler in Echtzeit mit Bigtable
Hier erfahren Sie, wie Sie mit BigQuery und Bigtable eine Echtzeit-Analyseplattform erstellen.
Informationen zur Verwendung der Apache Beam-Anreicherungstransformation zum Anreichern von Streamingereignissen in Dataflow
Lernressourcen
Datenaktualität erhöhen und Abfragelatenz reduzieren
Die MLB erfasst die Bewegungen des Balls und aller Spieler in Echtzeit mit Bigtable
Hier erfahren Sie, wie Sie mit BigQuery und Bigtable eine Echtzeit-Analyseplattform erstellen.
Informationen zur Verwendung der Apache Beam-Anreicherungstransformation zum Anreichern von Streamingereignissen in Dataflow
AdTech und Einzelhandel
Personalisierte Erlebnisse in Echtzeit
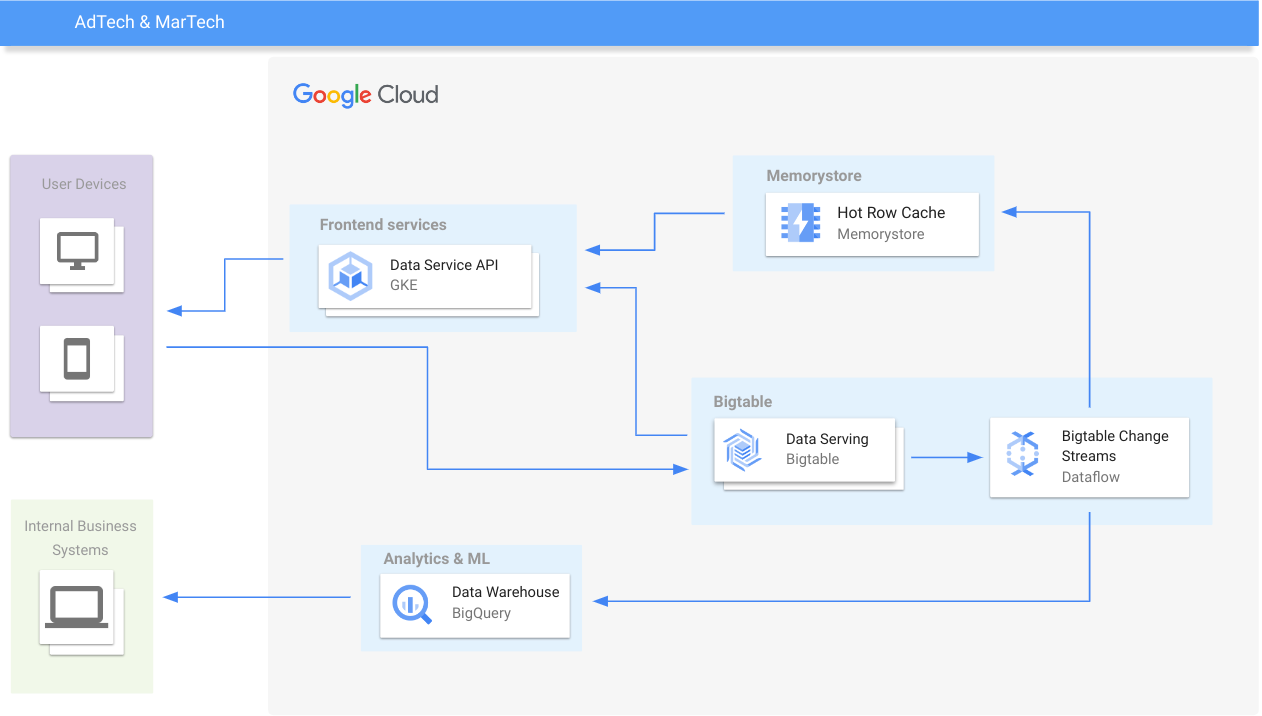
Lernressourcen
Personalisierte Erlebnisse in Echtzeit
Datenstruktur und operative Analysen
Datensilos konsolidieren und Legacy-Systeme horizontal skalieren
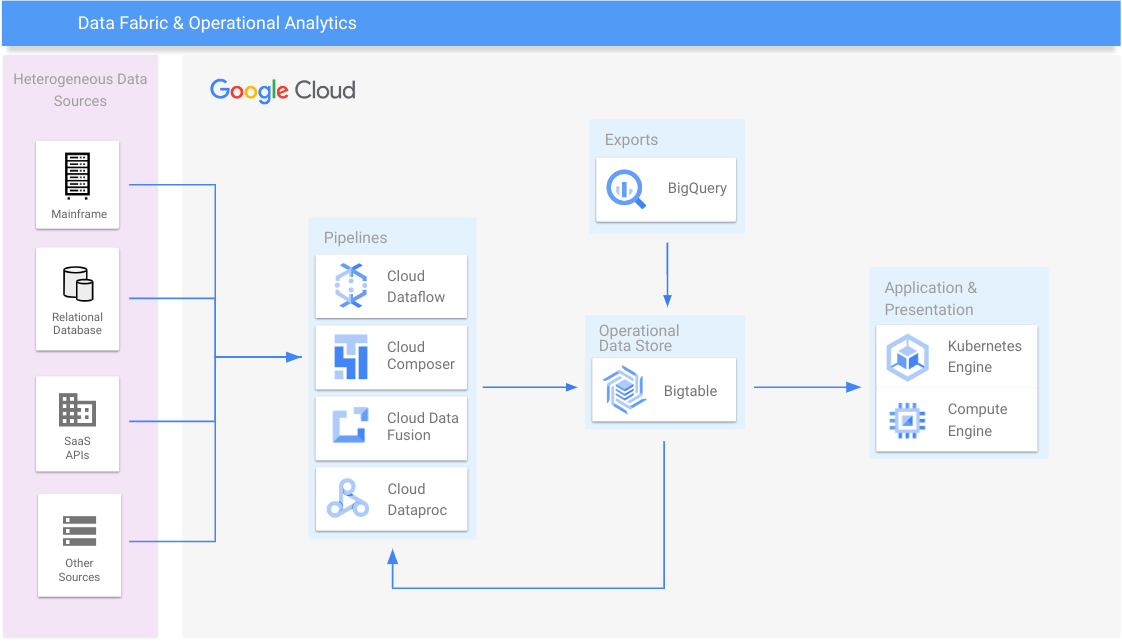
Lernressourcen
Datensilos konsolidieren und Legacy-Systeme horizontal skalieren
Internetsicherheit
Malware und Zahlungsbetrug erkennen, Spam und Betrug stoppen
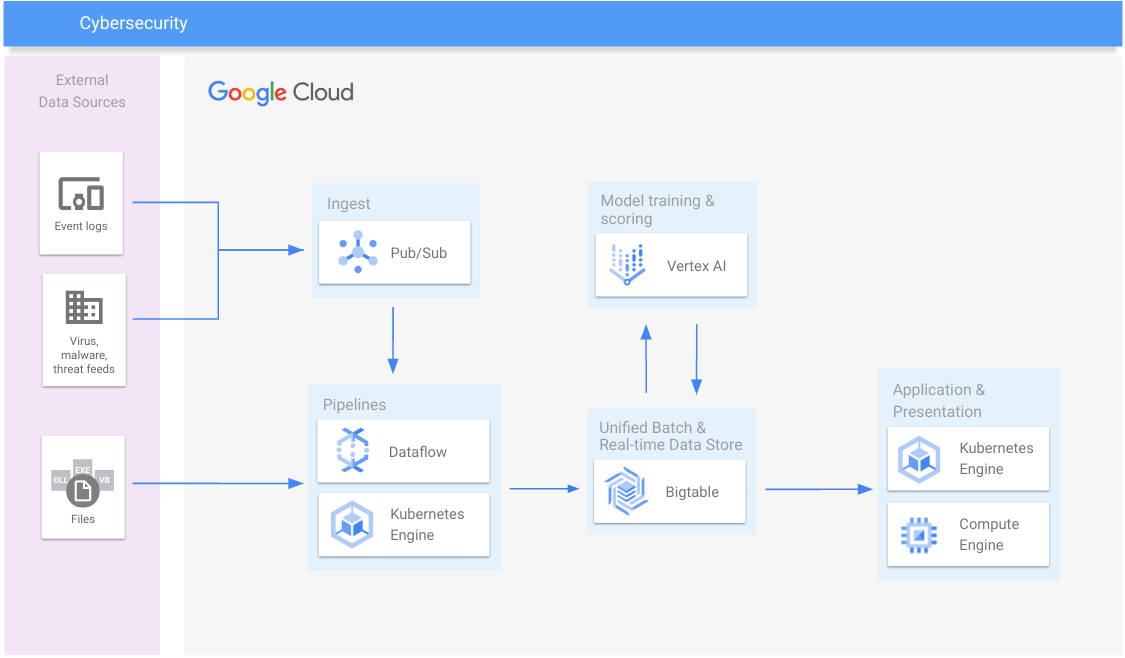
Lernressourcen
Malware und Zahlungsbetrug erkennen, Spam und Betrug stoppen
Medien
Medieninhalte und Analysen zum Nutzerverhalten bereitstellen
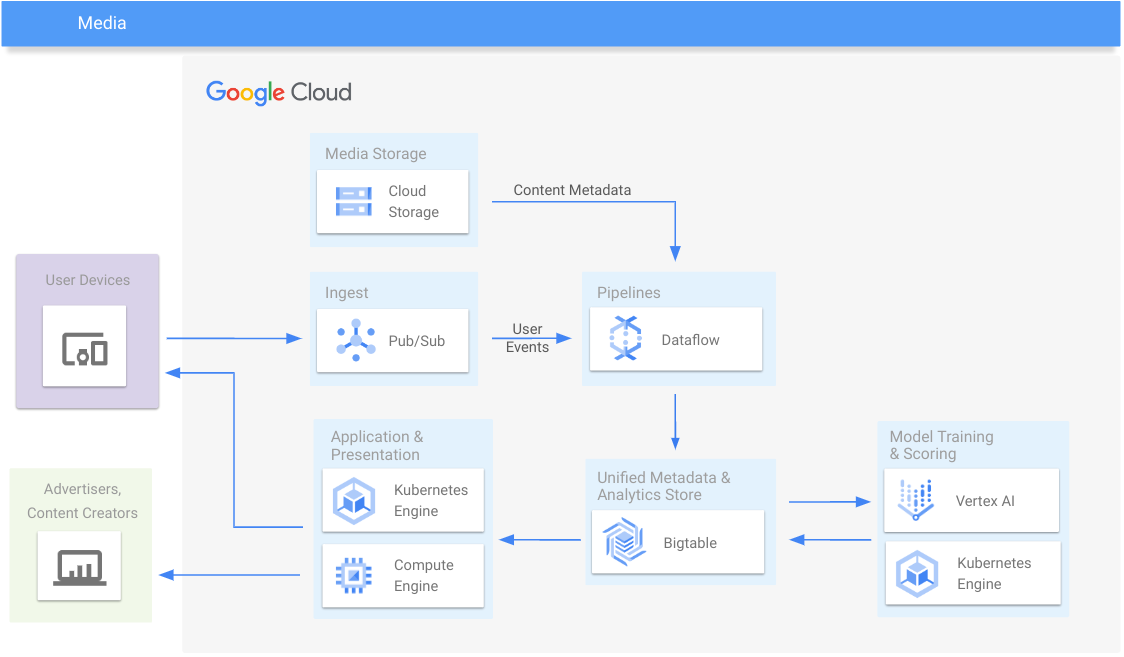
Lernressourcen
Medieninhalte und Analysen zum Nutzerverhalten bereitstellen
Zeitreihen und IoT
Zeitachsendaten in jeder Größenordnung verwalten
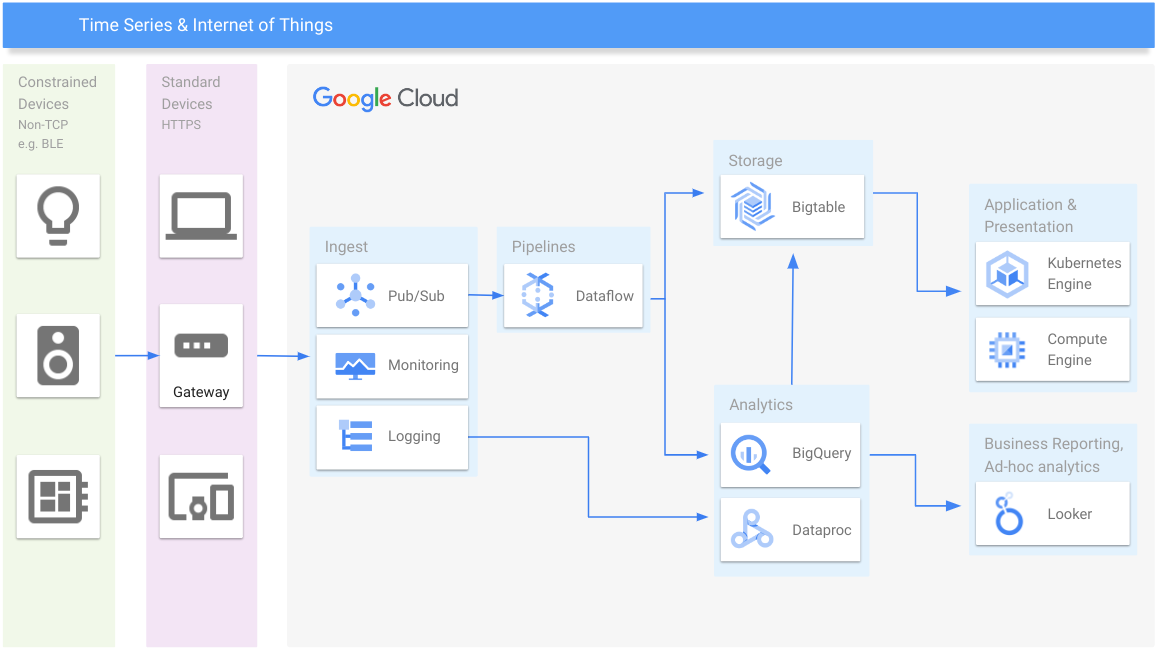
Lernressourcen
Zeitachsendaten in jeder Größenordnung verwalten
Infrastruktur für maschinelles Lernen
Trainieren und Bereitstellen des Modells skalieren
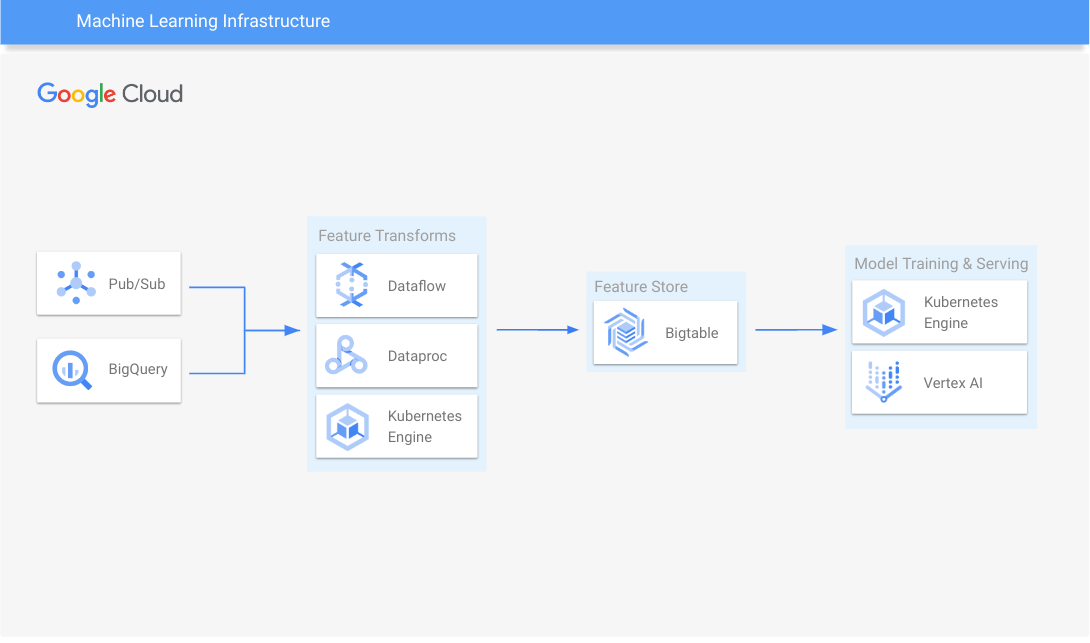
Bigtable mit beliebten Open-Source-Feature-Stores verwenden.
Lernressourcen
Trainieren und Bereitstellen des Modells skalieren
Bigtable mit beliebten Open-Source-Feature-Stores verwenden.
Preise
| Bigtable-Preise | Die Preise für Bigtable basieren auf der Rechenkapazität, dem Datenbankspeicher, dem Sicherungsspeicher und der Netzwerknutzung. Durch Rabatte für zugesicherte Nutzung wird der Preis weiter reduziert. | |
|---|---|---|
| Dienst | Beschreibung | Preis |
Rechenkapazität | Enterprise Edition Der Dienst bietet wichtige Funktionen für maschinelles Lernen, Zeitreihen, operative Analysen und skalierbare Anwendungen für Nutzer mit einer Latenz im niedrigen einstelligen Millisekundenbereich. Rechenkapazität wird als Knoten bereitgestellt. | Ab 0,65 $ pro Knoten und Stunde |
Enterprise Plus Edition Unterstützen Sie selbst die anspruchsvollsten Arbeitslasten mit höchster Konfigurierbarkeit, Leistung, Beobachtbarkeit und Governance. Beinhaltet alle Funktionen der Enterprise-Edition und kann eine Latenz von weniger als einer Millisekunde bieten. Rechenkapazität wird als Knoten bereitgestellt. | Ab 0,85 $ pro Knoten und Stunde | |
In-Memory-Stufe In-Memory-Lesedurchsatzkapazität für Lesevorgänge mit extrem niedriger Latenz und hoher Hotspot-Resistenz. Nur in der Enterprise Plus-Version verfügbar. Der Lesedurchsatz wird in Schritten von 40.000 (1 KB) Zeilen pro Sekunde bis zu 120.000 Zeilen pro Sekunde und Knoten bereitgestellt. | Ab 0,20 $ Kapazität von 40.000 Zeilen pro Sekunde | |
Data Boost | Isolierte On-Demand-Rechenressourcen für die Batchverarbeitung | Ab 0.000845 $ pro serverloser Verarbeitungseinheit und Stunde |
Datenspeicher | SSD Die Preise richten sich nach der physischen Größe der Tabellen. Jedes Replikat wird separat abgerechnet. Empfohlen für die Bereitstellung mit niedriger Latenz. | Ab 0,17 $ pro GB und Monat |
HDD Die Preise richten sich nach der physischen Größe der Tabellen. Jedes Replikat wird separat abgerechnet. Infrequent Access (IA) verwendet Festplatten und wird zum gleichen Tarif abgerechnet. | Ab 0,026 $ pro GB und Monat | |
Sicherungen | Standardsicherungen Die Preise richten sich nach der physischen Größe der Sicherungen. Bigtable-Sicherungen sind inkrementell. | Ab 0,026 $ pro GB und Monat |
Hot Backups Optimiert für eine deutlich kürzere Wiederherstellungszeit. Die Preise richten sich nach der physischen Größe der Sicherungen. | Ab 0,12 $ pro GB und Monat | |
Netzwerk | Eingehender Traffic | Kostenlos |
Ausgehender Traffic innerhalb der gleichen Region | Kostenlos | |
Ausgehender Traffic zwischen Regionen | Ab 0,10 $ pro GB | |
Replikation | Innerhalb derselben Region | Kostenlos |
Zwischen Regionen | Ab 0,01 $ pro GB | |
Weitere Informationen zu den Bigtable-Preisen und den Rabatten für zugesicherte Nutzung.
Bigtable-Preise
Die Preise für Bigtable basieren auf der Rechenkapazität, dem Datenbankspeicher, dem Sicherungsspeicher und der Netzwerknutzung. Durch Rabatte für zugesicherte Nutzung wird der Preis weiter reduziert.
Rechenkapazität
Enterprise Edition
Der Dienst bietet wichtige Funktionen für maschinelles Lernen, Zeitreihen, operative Analysen und skalierbare Anwendungen für Nutzer mit einer Latenz im niedrigen einstelligen Millisekundenbereich.
Rechenkapazität wird als Knoten bereitgestellt.
Starting at
0,65 $
pro Knoten und Stunde
Enterprise Plus Edition
Unterstützen Sie selbst die anspruchsvollsten Arbeitslasten mit höchster Konfigurierbarkeit, Leistung, Beobachtbarkeit und Governance. Beinhaltet alle Funktionen der Enterprise-Edition und kann eine Latenz von weniger als einer Millisekunde bieten.
Rechenkapazität wird als Knoten bereitgestellt.
Starting at
0,85 $
pro Knoten und Stunde
In-Memory-Stufe
In-Memory-Lesedurchsatzkapazität für Lesevorgänge mit extrem niedriger Latenz und hoher Hotspot-Resistenz. Nur in der Enterprise Plus-Version verfügbar.
Der Lesedurchsatz wird in Schritten von 40.000 (1 KB) Zeilen pro Sekunde bis zu 120.000 Zeilen pro Sekunde und Knoten bereitgestellt.
Starting at
0,20 $
Kapazität von 40.000 Zeilen pro Sekunde
Data Boost
Isolierte On-Demand-Rechenressourcen für die Batchverarbeitung
Starting at
0.000845 $
pro serverloser Verarbeitungseinheit und Stunde
Datenspeicher
SSD
Die Preise richten sich nach der physischen Größe der Tabellen. Jedes Replikat wird separat abgerechnet. Empfohlen für die Bereitstellung mit niedriger Latenz.
Starting at
0,17 $
pro GB und Monat
HDD
Die Preise richten sich nach der physischen Größe der Tabellen. Jedes Replikat wird separat abgerechnet. Infrequent Access (IA) verwendet Festplatten und wird zum gleichen Tarif abgerechnet.
Starting at
0,026 $
pro GB und Monat
Sicherungen
Standardsicherungen
Die Preise richten sich nach der physischen Größe der Sicherungen. Bigtable-Sicherungen sind inkrementell.
Starting at
0,026 $
pro GB und Monat
Hot Backups
Optimiert für eine deutlich kürzere Wiederherstellungszeit. Die Preise richten sich nach der physischen Größe der Sicherungen.
Starting at
0,12 $
pro GB und Monat
Netzwerk
Eingehender Traffic
Kostenlos
Ausgehender Traffic innerhalb der gleichen Region
Kostenlos
Ausgehender Traffic zwischen Regionen
Starting at
0,10 $
pro GB
Replikation
Innerhalb derselben Region
Kostenlos
Zwischen Regionen
Starting at
0,01 $
pro GB
Weitere Informationen zu den Bigtable-Preisen und den Rabatten für zugesicherte Nutzung.
Anwendungsszenario
Erfahren Sie, wie andere Unternehmen mit Spanner innovative Apps entwickelt haben, um eine hervorragende Nutzererfahrung zu bieten, die Kosten zu senken und den ROI zu steigern.
Erfahren Sie, wie Box seine NoSQL-Datenbanken mit Bigtable modernisiert hat
Box hat durch die nahtlose Migration die Skalierbarkeit und Verfügbarkeit verbessert und gleichzeitig die Verwaltungskosten gesenkt.
Weitere Informationen

Sabre liefert mit Bigtable Suchergebnisse für Reisen mit geringerer Latenz und niedrigeren Gesamtbetriebskosten

Wie Plaid seine Echtzeit-Analyseplattform auf BigQuery und Bigtable aufgebaut hat

Airship erreicht mit Bigtable kostengünstig über eine Million Schreibvorgänge und 700.000 Lesevorgänge pro Sekunde
Vorteile und Kunden
Bauen Sie Ihr Unternehmen aus mit innovativen Anwendungen, die sich unbegrenzt skalieren lassen, um alle Anforderungen zu erfüllen.
Sie erhalten ein hervorragendes Preis-Leistungs-Verhältnis und zahlen nur für was Sie nutzen.
Mit Open-Source-APIs und Migrationstools können Sie ganz einfach von anderen NoSQL-Datenbanken migrieren und Hybrid- oder Multi-Cloud-Bereitstellungen ausführen.















Partner und Integration
Profitieren Sie von Partnern, die sich mit Bigtable auskennen, um Sie bei jedem Schritt des Prozesses zu unterstützen – von Bewertungen und Anwendungsszenarien bis hin zu Migrationen und dem Erstellen neuer Anwendungen in Bigtable.

































Systemintegratoren
Möchten Sie mehr darüber erfahren, welche Partner‑ oder Drittanbieter-Einbindung am besten für Ihr Unternehmen geeignet ist? Dann sehen Sie sich unser Partnerverzeichnis an.
Weitere Informationen
FAQs
Welche Art von Datenbank ist Bigtable?
Bigtable ist ein NoSQL-Datenbankdienst, insbesondere ein Schlüssel/Wert-Speicher, der sehr breite Tabellen mit Zehntausenden von Spalten ermöglicht. Daher wird er auch als spaltenorientierte Datenbank oder verteilte mehrdimensionale Karte bezeichnet. Es ist eine NoSQL-Datenbank im Sinne von "Nicht nur SQL", aber nicht im Sinne von „Kein SQL“. Es unterstützt viele Funktionen, die über Key-Value-Lookups hinausgehen, einschließlich Aggregationen und globaler Sekundärindizes.
Bigtable ähnelt den beliebten Open-Source-Projekten, die es inspiriert hat, wie Apache HBase und Cassandra. Daher ist Bigtable das gängigste Ziel für Kunden mit großen Datenmengen, die eine leistungsstarke, kostengünstige, vollständig verwaltete NoSQL-Datenbanklösung bei Google Cloud suchen.
Unterstützt Bigtable SQL?
Neben den Schlüssel-Wert-APIs unterstützt Bigtable auch SQL-Abfragen auf drei verschiedene Arten:
- Für die Entwicklung latenzarmer Anwendungen bietet Bigtable eine SQL-Abfrage-API, die auf GoogleSQL mit Erweiterungen für das spaltenorientierte Datenmodell aufbaut und der Cassandra Query Language (CQL) ähnelt. Es unterstützt mehr als 200 Funktionen, darunter Aggregationen (GROUP BY), Fensterfunktionen, Funktionen für die Verarbeitung von Geodaten und JSON sowie die Vektorsuche (kNN). Bigtable unterstützt sowohl die Standard- als auch die verkettete Abfragesyntax.
- Für Data-Science-Anwendungsfälle oder andere Arten von Batchverarbeitung und ETL unterstützt Bigtable SparkSQL über den Spark-Client.
- Für Nutzer, die eine explorative Post-hoc-Analyse durchführen oder Daten aus mehreren Quellen für die Batch-Analyse zusammenführen möchten, sind Bigtable-Daten auch über BigQuery zugänglich. Sie müssen Ihre Bigtable-Tabellen lediglich in BigQuery registrieren und können sie dann wie jede andere BigQuery-Tabelle abfragen – ohne ETL oder Datenduplizierung.
Wie migriere ich Datenbanken zu Bigtable?
Bigtable bietet Apache Cassandra- und HBase-APIs sowie Migrationstools, die ein schnelleres und einfacheres Onboarding ermöglichen, da eine genaue Datenmigration mit geringerem Aufwand gewährleistet ist. Die HBase-Replikationsbibliothek und die Cassandra-Migrationstools von Bigtable ermöglichen Live-Migrationen ohne Ausfallzeiten. Bigtable bietet auch Dienstprogramme, die die Migration von DynamoDB und Aerospike vereinfachen.
Ist Bigtable serverlos?
Der Bigtable-Speicher wird ähnlich wie bei einem serverlosen Modell pro genutztem GB berechnet. Bigtable bietet außerdem eine lineare horizontale Skalierung und kann Rechenressourcen automatisch hoch- und herunterskalieren, um auf Nachfrageschwankungen zu reagieren. Daher ist keine langfristige Kapazitätsverpflichtung für Speicher oder Rechenleistung erforderlich. Die Preise für Rechenleistung mit niedriger Latenz basieren jedoch auf der Kapazität und werden pro Knoten abgerechnet, nicht pro Anfrage. Jeder Knoten kann bis zu 17.000 Anfragen pro Sekunde verarbeiten. Dadurch ist der Preis von Bigtable bei größeren Arbeitslasten günstiger, aber weniger ideal für kleine Anwendungen, die möglicherweise besser für Google Cloud-Datenbanken wie Firestore geeignet sind.
Für die Batch-Datenverarbeitung bietet Bigtable Data Boost, das in Serverless Processing Units (SPU) abgerechnet wird.
Ist Bigtable ein persistenter Cache?
Bigtable ist eine Datenbank mit cacheähnlicher Leistung, kein Cache mit Persistenz. Die Lösung bietet leistungsstarke In-Database-Verarbeitungsfunktionen, eine SQL-API, kontinuierliche materialisierte Ansichten und asynchrone Sekundärindizes. Die RDMA-Technologie ermöglicht einen direkten Zugriff auf den RAM für einen hohen Durchsatz und eine Leistung, die nicht durch die CPU-Kapazität des Datenbankservers begrenzt wird. Bigtable kann zwar als Ersatz für dauerhafte Caching-Lösungen wie MemoryDB verwendet werden, umgekehrt gilt das aber nicht immer, da Lösungen wie Redis als Cache und nicht als Datenbank konzipiert wurden.


















