In dieser Anleitung wird erläutert, wie Sie mit einem geplanten Autoscaling in Google Kubernetes Engine (GKE) die Kosten senken können. Bei dieser Art von Autoscaling werden Cluster nach einem Zeitplan entsprechend der Tageszeit oder dem Wochentag skaliert. Ein geplanter Autoscaler ist nützlich, wenn Ihr Traffic einen vorhersehbaren An- und Abstieg aufweist, z. B. wenn Sie ein regionaler Einzelhändler sind oder wenn Ihre Software für Mitarbeiter bestimmt ist, deren Arbeitszeit auf einen bestimmten Teil des Tages beschränkt ist.
Diese Anleitung richtet sich an Entwickler und Operatoren, die Cluster vor dem Eintreffen von Spitzen zuverlässig hoch- und danach wieder herunterskalieren möchten, um nachts, am Wochenende oder zu jeder anderen Zeit, wenn weniger Nutzer online sind, Geld zu sparen. Es wird davon ausgegangen, dass Sie mit Docker, Kubernetes, Kubernetes-CronJobs, GKE und Linux vertraut sind.
Einführung
Bei vielen Anwendungen treten ungleichmäßige Trafficmuster auf. Beispielsweise interagieren Mitarbeiter in einer Organisation nur während des Tages mit einer Anwendung. Daher werden die Rechenzentrumsserver für diese Anwendung nachts geschlossen.
Neben anderen Vorteilen können Sie mit Google Cloud Geld sparen. Ordnen Sie dazu die Infrastruktur entsprechend der Trafficlast dynamisch zu. In einigen Fällen kann eine einfache Konfiguration mit automatischer Skalierung die Zuordnungsherausforderung für ungleichmäßigen Traffic bewältigen. Wenn das dein Fall ist, bleiben Sie dabei. In anderen Fällen erfordern schnelle Änderungen der Trafficmuster jedoch fein abgestimmte Autoscale-Konfigurationen, um eine Systeminstabilität während des Hochskalierens und eine Überdimensionierung des Clusters zu vermeiden.
Diese Anleitung konzentriert sich auf Szenarien, in denen starke Änderungen in den Trafficmustern gut auszumachen sind, und Sie den Autoscaler dahingehend einstellen möchten, dass in Ihrer Infrastruktur Spitzen auftreten werden. In diesem Dokument wird gezeigt, wie GKE-Cluster morgens nach oben und nachts nach unten skaliert werden. Sie können jedoch einen ähnlichen Ansatz verwenden, um die Kapazität für bekannte Ereignisse zu erhöhen und zu verringern, z. B. bei Spitzenereignissen, Werbekampagnen oder Wochenendtraffic.
Cluster herunterskalieren, wenn Sie Rabatte für zugesicherte Nutzung haben
In dieser Anleitung wird erläutert, wie Sie die Kosten senken können, wenn Sie Ihre GKE-Cluster außerhalb der Spitzenzeiten auf ein Minimum herunterskalieren. Wenn Sie jedoch einen Rabatt für zugesicherte Nutzung erworben haben, ist es wichtig zu verstehen, wie diese Rabatte in Verbindung mit Autoscaling eingesetzt werden.
Verträge über zugesicherte Nutzung bieten Ihnen stark reduzierte Preise, wenn Sie sich dazu verpflichten, für eine bestimmte Menge an Ressourcen (vCPUs, Speicher und andere) zu zahlen. Um jedoch die Menge der festzuschreibenden Ressourcen zu bestimmen, müssen Sie im Voraus wissen, wie viele Ressourcen Ihre Arbeitslasten im Laufe der Zeit verbrauchen. Das folgende Diagramm zeigt Ihnen, welche Ressourcen Sie bei der Planung berücksichtigen sollten und welche Kosten Sie vermeiden können.

Wie das Diagramm zeigt, ist die Zuweisung von Ressourcen im Rahmen eines zugesagten Nutzungsvertrags flach. Die vom Vertrag abgedeckten Ressourcen müssen die meiste Zeit genutzt werden, damit sich die eingegangene Verpflichtung auch lohnt. Daher sollten Sie keine Ressourcen, die während Spitzen verwendet werden, in die Berechnung Ihrer festgeschriebenen Ressourcen einbeziehen. Für Ressourcen mit Lastspitzen empfehlen wir die Verwendung von GKE-Autoscaler-Optionen. Zu diesen Optionen gehören das geplante Autoscaling, das in diesem Artikel erläutert wird, oder andere verwaltete Optionen, die in Best Practices zum Ausführen kostenoptimierter Kubernetes-Anwendungen in GKE erläutert werden.
Wenn Sie bereits einen Vertrag über zugesicherte Nutzung für eine bestimmte Menge an Ressourcen haben, reduzieren Sie Ihre Kosten nicht, wenn Sie Ihren Cluster unter dieses Minimum herunterskalieren. In solchen Szenarien empfehlen wir, dass Sie versuchen, einige Jobs so zu planen, dass sie die Lücken in Zeiten mit geringem Computerbedarf schließen.
Architektur
Das folgende Diagramm zeigt die Architektur für die Infrastruktur und das geplante Autoscaling, das Sie in dieser Anleitung bereitstellen. Das geplante Autoscaling besteht aus einer Reihe von Komponenten, die gemeinsam die Skalierung auf der Grundlage eines Zeitplans verwalten.

In dieser Architektur exportiert eine Reihe von CronJobs von Kubernetes bekannte Informationen über Trafficmuster in einen benutzerdefinierten Cloud Monitoring-Messwert. Diese Daten werden dann von einem Horizontalen Pod-Autoscaling (HPA) als Eingabe gelesen, wann das HPA Ihre Arbeitslast skalieren soll. Zusammen mit anderen Lademesswerten wie der CPU-Zielauslastung entscheidet das HPA, wie die Replikate für eine bestimmte Bereitstellung skaliert werden.
Ziele
- Einen GKE-Cluster installieren
- Beispielanwendung bereitstellen, die ein Kubernetes-HPA verwendet
- Richten Sie die Komponenten für das geplante Autoscaling ein und aktualisieren Sie Ihr HPA, um einen geplanten benutzerdefinierten Messwert zu lesen.
- Richten Sie eine Benachrichtigung ein, die ausgelöst wird, wenn Ihr geplantes Autoscaling nicht ordnungsgemäß funktioniert.
- Last für die Anwendung generieren
- Untersuchen Sie, wie das HPA auf normale Anstiege des Traffics und auf die von Ihnen konfigurierten, benutzerdefinierten Messwerte reagiert.
Der Code für diese Anleitung ist in einem GitHub-Repository.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the GKE, Artifact Registry and the Cloud Monitoring APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Umgebung vorbereiten
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Konfigurieren Sie in Cloud Shell Ihre Google Cloud Projekt-ID, Ihre E-Mail-Adresse sowie Ihre Computerzone und -region:
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-fErsetzen Sie Folgendes:
YOUR_PROJECT_ID: Der Google Cloud -Projektname für das Projekt, das Sie verwenden.YOUR_EMAIL_ADDRESS: E-Mail-Adresse, an die Benachrichtigungen gesendet werden, wenn das geplante Autoscaling nicht ordnungsgemäß funktioniert.
Sie können für diese Anleitung eine andere Region und Zone auswählen.
Klonen Sie das GitHub-Repository
kubernetes-engine-samples:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscalerDer Code in diesem Beispiel ist in folgende Ordner strukturiert:
- Root: Enthält den Code, der von den CronJobs zum Exportieren benutzerdefinierter Messwerte in Cloud Monitoring verwendet wird.
k8s/: Enthält ein Deployment-Beispiel mit einem Kubernetes HPA.k8s/scheduled-autoscaler/: Enthält die CronJobs, die einen benutzerdefinierten Messwert exportieren, und eine aktualisierte Version des HPA, die aus einem benutzerdefinierten Messwert gelesen werden kann.k8s/load-generator/: Enthält ein Kubernetes-Deployment mit einer Anwendung, die die stündliche Nutzung simuliert. Ein Deployment ist ein Kubernetes-API-Objekt, mit dem Sie mehrere Replikate von Pods ausführen können, die auf die Knoten in einem Cluster verteilt sind.monitoring/: Enthält die Cloud Monitoring-Komponenten, die Sie in dieser Anleitung konfigurieren.
Erstellen Sie in Cloud Shell einen GKE-Cluster zum Ausführen des geplanten Autoscalings:
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilizationDie Ausgabe sieht etwa so aus:
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNINGDies ist keine Produktionskonfiguration, aber eine Konfiguration, die für diese Anleitung geeignet ist. Bei dieser Einrichtung konfigurieren Sie den Cluster Autoscaler mit mindestens einem Knoten und maximal zehn Knoten. Sie aktivieren außerdem das Profil
optimize-utilization, um das Herunterskalieren zu beschleunigen.Stellen Sie die Beispielanwendung ohne das geplante Autoscaling bereit:
kubectl apply -f ./k8sÖffnen Sie die Datei
k8s/hpa-example.yaml.Die folgende Auflistung zeigt den Inhalt der Datei.
Beachten Sie, dass die Mindestanzahl an Replikaten (
minReplicas) auf 10 festgelegt ist. Diese Konfiguration legt auch fest, dass der Cluster anhand der CPU-Auslastung (Einstellungname: cpuundtype: Utilization) skaliert.Warten Sie, bis die Anwendung verfügbar ist:
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IPWenn die Anwendung verfügbar ist, sieht die Ausgabe so aus:
OK!Prüfen Sie die Einstellungen:
kubectl get hpa php-apacheDie Ausgabe sieht etwa so aus:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hIn der Spalte
REPLICASwird10angezeigt. Dies entspricht dem Wert des FeldsminReplicasin der Dateihpa-example.yaml.Prüfen Sie, ob die Anzahl der Knoten auf 4 erhöht wurde:
kubectl get nodesDie Ausgabe sieht etwa so aus:
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504Wenn Sie den Cluster erstellt haben, legen Sie mit dem Flag
min-nodes=1eine Mindestkonfiguration fest. Die Anwendung, die Sie zu Beginn dieses Verfahrens bereitgestellt haben, erfordert jedoch mehr Infrastruktur, daminReplicasin der Dateihpa-example.yamlauf 10 gesetzt ist.Die häufige Verwendung von
minReplicasauf einen Wert wie 10 ist eine gängige Strategie von Unternehmen wie Einzelhändlern, die in den ersten Stunden des Werktags einen plötzlichen Anstieg der Zugriffszahlen erwarten. Wenn Sie jedoch hohe Werte für HPA-minReplicasfestlegen, könnte das Ihre Kosten erhöhen, da der Cluster nicht verkleinert werden kann. Auch nicht nachts, wenn der Anwendungstraffic niedrig ist.Installieren Sie in Cloud Shell den Benutzerdefinierte Messwerte – Cloud Monitoring-Adapter in Ihrem GKE-Cluster:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metricsMit diesem Adapter wird das Pod-Autoscaling basierend auf benutzerdefinierten Cloud Monitoring-Messwerten aktiviert.
Erstellen Sie in Artifact Registry ein Repository und gewähren Sie Leseberechtigungen:
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.readerErstellen Sie den Exportcode des benutzerdefinierten Messwerts und übertragen Sie ihn per Push:
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporterStellen Sie die CronJobs bereit, die benutzerdefinierte Messwerte exportieren und die aktualisierte Version des HPA bereitstellen, die aus diesen benutzerdefinierten Messwerten liest:
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscalerÖffnen und prüfen Sie die Datei
k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml.Die folgende Auflistung zeigt den Inhalt der Datei.
Diese Konfiguration gibt an, dass die CronJobs die vorgeschlagenen Pod-Replikate basierend auf der Tageszeit zu einem benutzerdefinierten Messwert namens
custom.googleapis.com/scheduled_autoscaler_exampleexportieren. Um den Monitoring-Abschnitt in dieser Anleitung zu vereinfachen, wird in der Konfiguration des Zeitplanfelds eine stündliche Hoch- und Herunterskalierung definiert. Für die Produktion können Sie diesen Zeitplan an Ihre geschäftlichen Anforderungen anpassen.Öffnen und prüfen Sie die Datei
k8s/scheduled-autoscaler/hpa-example.yaml.Die folgende Auflistung zeigt den Inhalt der Datei.
Diese Konfiguration gibt an, dass das HPA-Objekt das zuvor bereitgestellte HPA ersetzen soll. Beachten Sie, dass die Konfiguration den Wert in
minReplicasauf 1 reduziert. Dies bedeutet, dass die Arbeitslast bis auf das Minimum skaliert werden kann. Die Konfiguration fügt auch einen externen Messwert (type: External) hinzu. Außerdem wird das Autoscaling jetzt durch zwei Faktoren ausgelöst.In diesem Szenario mit mehreren Messwerten berechnet das HPA für jeden Messwert eine vorgeschlagene Replikatanzahl und wählt anschließend den Messwert aus, der den höchsten Wert zurückgibt. Wichtig: Das geplante Autoscaling kann erkennen, dass die Pod-Anzahl zu einem bestimmten Zeitpunkt 1 betragen sollte. Wenn die tatsächliche CPU-Auslastung für einen Pod jedoch höher als erwartet ist, erstellt das HPA mehr Replikate.
Prüfen Sie die Anzahl der Knoten und HPA-Replikate noch einmal. Führen Sie dazu alle folgenden Befehle noch einmal aus:
kubectl get nodes kubectl get hpa php-apacheWelche Ausgabe angezeigt wird, hängt davon ab, was das geplante Autoscaling in letzter Zeit getan hat. Insbesondere sind die Werte von
minReplicasundnodesan verschiedenen Punkten im Skalierungszyklus unterschiedlich.Beispielsweise beträgt bei ungefähr Minute 51 bis 60 in jeder Stunde (für einen Zeitraum mit Trafficspitzen) der HPA-Wert für
minReplicas10 und der Wert vonnodes4.Im Gegensatz dazu beträgt der HPA-Wert
minReplicasfür die Minuten 1 bis 50 (für einen Zeitraum mit geringerem Traffic) 1 und der Wertnodesentweder 1 oder 2, je nachdem, wie viele Pods zugewiesen und entfernt wurden. Bei den niedrigeren Werten (Minuten 1 bis 50) kann es bis zu 10 Minuten dauern, bis der Cluster vollständig herunterskaliert ist.Erstellen Sie in Cloud Shell einen Benachrichtigungskanal:
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}Die Ausgabe sieht etwa so aus:
Created notification channel NOTIFICATION_CHANNEL_ID.Dieser Befehl erstellt einen Benachrichtigungskanal vom Typ
email, um die Anleitungsschritte zu vereinfachen. In Produktionsumgebungen sollten Sie eine weniger asynchrone Strategie verwenden. Legen Sie dazu den Benachrichtigungskanal aufsmsoderpagerdutyfest.Legen Sie eine Variable mit dem Wert fest, der im Platzhalter
NOTIFICATION_CHANNEL_IDangezeigt wurde:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_IDStellen Sie die Benachrichtigungsrichtlinie bereit:
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDDie Datei
alert-policy.yamlenthält die Spezifikation zum Senden einer Benachrichtigung, wenn der Messwert nach fünf Minuten nicht vorhanden ist.Rufen Sie die Cloud Monitoring-Seite Benachrichtigungen auf, um die Benachrichtigungsrichtlinie anzusehen.
Klicken Sie auf Geplante Autoscaling-Richtlinie und prüfen Sie die Details der Benachrichtigungsrichtlinie.
Stellen Sie in Cloud Shell den Ladegenerator bereit:
kubectl apply -f ./k8s/load-generatorIn der folgenden Liste wird das Vorhersageskript
load-generatoraufgeführt:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;Dieses Skript wird in Ihrem Cluster ausgeführt, bis Sie die Bereitstellung
load-generatorlöschen. Sie sendet alle paar Millisekunden Anfragen an den Dienstphp-apache. Der Befehlsleepsimuliert die Lastverteilungsänderungen während des Tages. Mithilfe eines Skripts, das Traffic auf diese Weise generiert, können Sie nachvollziehen, was passiert, wenn Sie die CPU-Auslastung und die benutzerdefinierten Messwerte in Ihrer HPA-Konfiguration kombinieren.Erstellen Sie in Cloud Shell ein neues Dashboard:
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yamlRufen Sie die Cloud Monitoring-Seite Dashboards auf:
Klicken Sie auf Geplantes Autoscaling-Dashboard.
Im Dashboard werden drei Grafiken angezeigt. Sie müssen mindestens zwei Stunden (idealerweise 24 Stunden oder länger) warten, um die Dynamik von Hoch- und Herunterskalierungen zu sehen und um zu sehen, wie sich unterschiedliche Lastverteilungen während des Tages auf die automatische Skalierung auswirken.
Um Ihnen eine Vorstellung davon zu geben, was die Grafiken zeigen, können Sie die folgenden Grafiken studieren, die eine Ganztagsansicht darstellen:
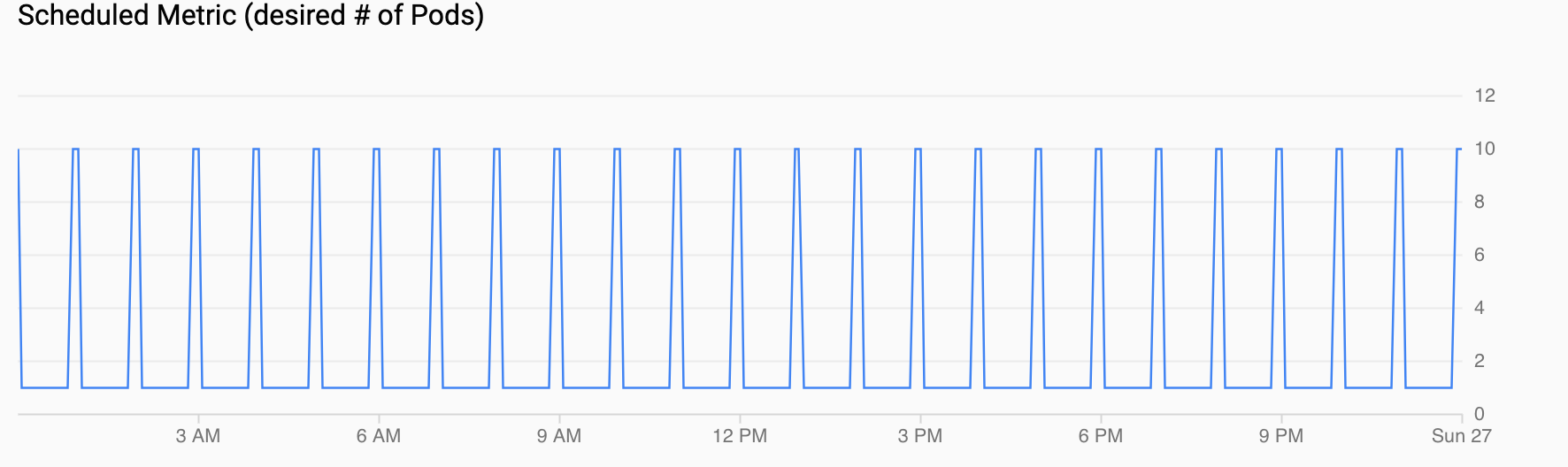
Geplanter Messwert (gewünschte Anzahl von Pods) zeigt eine Zeitachse des benutzerdefinierten Messwerts an, der über CronJobs, die Sie unter Geplantes Autoscaling einrichten konfiguriert haben, in Cloud Monitoring exportiert wird.
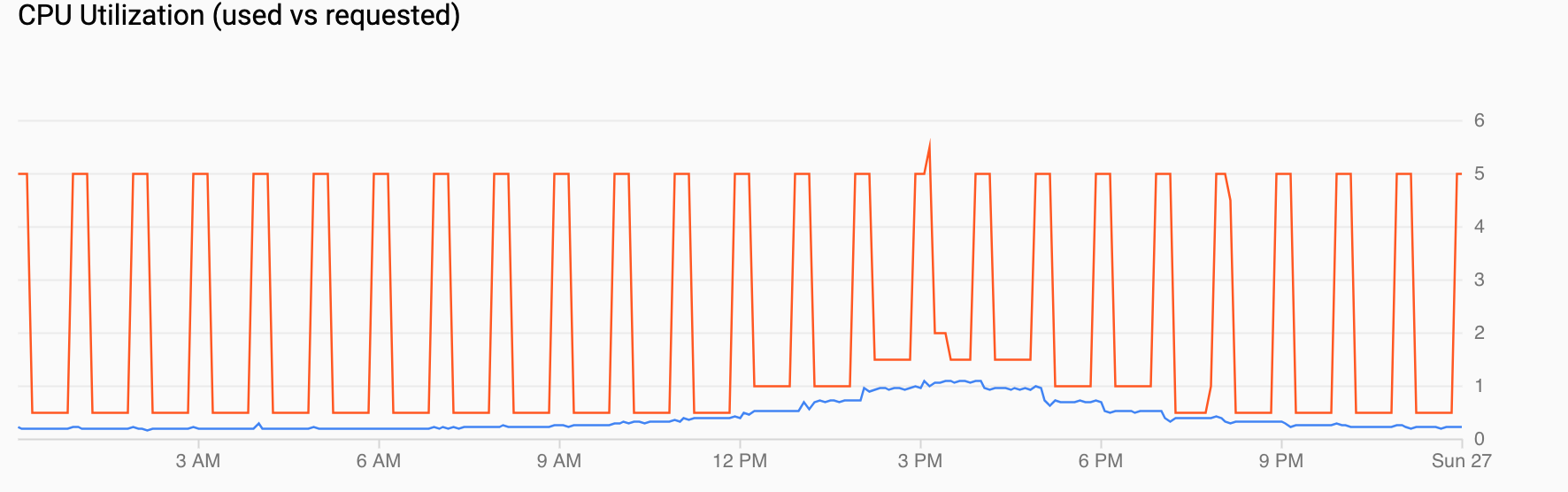
CPU-Auslastung (angefragt oder verwendet) zeigt eine Zeitachse der angeforderten CPU (rot) und der tatsächlichen CPU-Auslastung (blau). Wenn die Last niedrig ist, berücksichtigt das HPA die Auslastungsentscheidung durch das geplante Autoscaling. Wenn der Traffic jedoch ansteigt, erhöht das HPA die Anzahl der Pods nach Bedarf, wie Sie für die Datenpunkte zwischen 12:00 und 18:00 Uhr erkennen können.
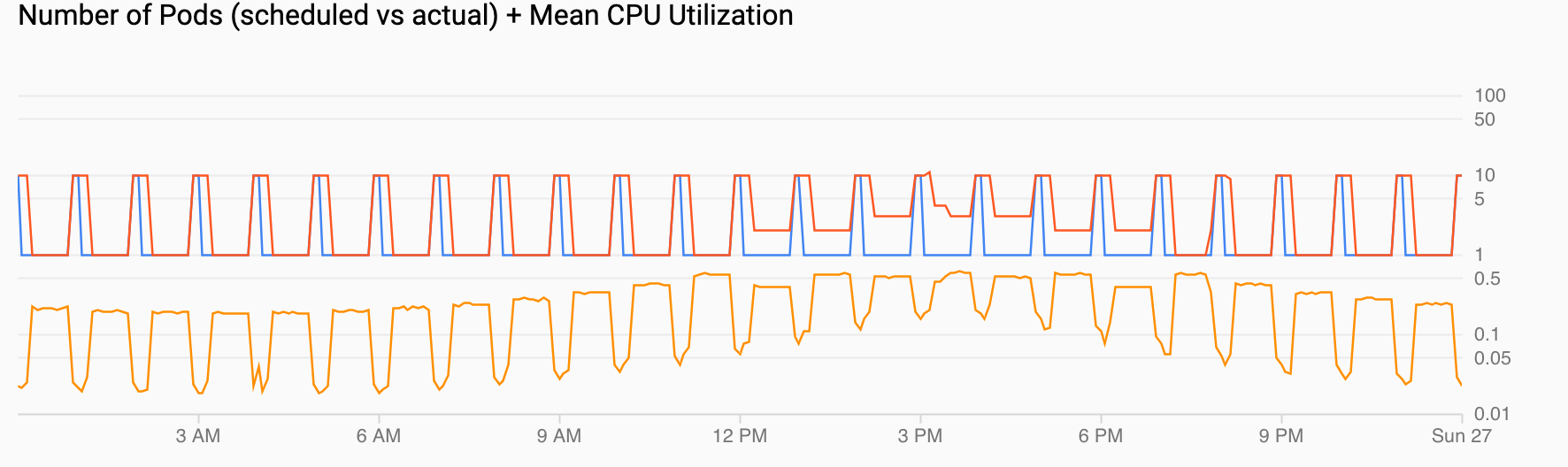
Anzahl der Pods (geplant oder tatsächlich) + durchschnittliche CPU-Auslastung zeigt eine Ansicht ähnlich wie die der vorherigen. Die Anzahl der Pods (rot) erhöht sich wie geplant (blau) stündlich auf 10. Die Anzahl der Pods steigt und sinkt natürlich im Laufe der Zeit als Reaktion auf die Belastung (12 und 18 Uhr). Die durchschnittliche CPU-Auslastung (orange) bleibt unter dem von Ihnen festgelegten Ziel (60 %).
GKE-Cluster erstellen
Beispielanwendung bereitstellen
Geplantes Autoscaling einrichten
Benachrichtigungen konfigurieren, wenn der geplante Autoscaler nicht ordnungsgemäß funktioniert
In einer Produktionsumgebung möchten Sie normalerweise wissen, wenn CronJobs den benutzerdefinierten Messwert nicht ausfüllt. Zu diesem Zweck können Sie eine Benachrichtigung erstellen, die ausgelöst wird, wenn ein custom.googleapis.com/scheduled_autoscaler_example-Stream fünf Minuten lang nicht vorhanden ist.
Last für die Beispielanwendung generieren
Skalierung als Reaktion auf Traffic oder geplante Messwerte visualisieren
In diesem Abschnitt sehen Sie Visualisierungen, die die Auswirkungen einer Hoch- und Herunterskalierung zeigen.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Nächste Schritte
- Weitere Informationen zur GKE-Kostenoptimierung finden Sie unter Best Practices zum Ausführen kostenoptimierter Kubernetes-Anwendungen in GKE.
- Designempfehlungen und Best Practices zur Optimierung der Kosten vonGoogle Cloud -Arbeitslasten finden Sie im Google Cloud Well-Architected Framework: Kostenoptimierung.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center