Vision AI
從圖片、文件和影片擷取深入分析資訊
透過 API 使用先進的視覺模型,自動執行視覺類工作、簡化分析程序,並取得可做為行動依據的洞察資料。您也能在代管環境中進行無程式碼模型訓練,輕鬆建構自訂應用程式,同時兼顧成本效益。
新客戶最多可獲得價值 $300 美元的免費抵免額,開始試用 Vision AI 和其他 Google Cloud 產品。
您也能嘗試部署 Google 推薦的文件摘要製作與 AI/機器學習圖片處理解決方案。
總覽
什麼是電腦視覺?
電腦視覺是人工智慧 (AI) 的一個領域,可讓電腦和系統解讀及分析視覺化資料,並從數位圖片、影片和其他視覺化輸入內容中取得有意義的資訊。常見的應用實例包括:偵測物件、處理視覺化內容 (圖片、文件和影片)、理解與分析資料、搜尋產品,分類和搜尋圖片,以及審核內容等。
先進的多模態生成式 AI
Google Cloud 的 Vertex AI 提供 Gemini,這一系列先進的多模態模型能夠理解絕大多數輸入內容、結合不同類型的資訊,並生成幾乎任何輸出內容。
聚焦視覺的生成式 AI
有了 Vertex AI 的 Imagen,開發人員就能透過 API,使用 Google 最先進的圖片生成式 AI 功能。這項產品的部分主要功能包括:使用文字提示詞生成圖像、使用文字提示詞編輯圖像、提供圖片的文字說明,以及微調主題模型。
立即可用的 Vision AI
Cloud Vision API 是現成可用的 API (REST 和 RPC),採用 Google 預先訓練的電腦視覺機器學習模型,可讓開發人員輕鬆將常見的視覺偵測功能整合至應用程式,包括為圖片加上標籤、偵測臉部和地標、光學字元辨識 (OCR),以及煽情露骨內容偵測。
套用至圖片的每項功能都是一個計費單位,而您每個月都可免費使用 1,000 個單位的 Cloud Vision API 功能。歡迎參閱定價詳細資料。
文件理解生成式 AI
Document AI 是文件解讀平台,結合電腦視覺和其他技術 (例如自然語言處理技術等),可從掃描的文件中擷取文字與資料,再將非結構化資料轉換為結構化資訊與業務洞察。
這個平台提供多種經過最佳化調整的預先訓練處理器,適合用於不同類型的文件。您也能透過 Document AI Workbench,輕鬆建構專屬處理器,藉此分類、分割和擷取文件中的結構化資料。

立即可用的 Vision AI 影片處理功能
Video Intelligence API 以電腦視覺技術為核心,讓您能輕鬆處理、分析及理解影片內容。
這個 API 的預先訓練機器學習模型會自動識別串流影片中的大量物件、地點和動作,而且品質相當卓越。如果將 Video Intelligence API 用於一般用途,例如審核及推薦內容、封存媒體和放送內容相關廣告,就能享有高效率的體驗。您也可使用 Vertex AI Vision 訓練自訂機器學習模型,滿足獨特的需求。

目視檢測 AI
目視檢測 AI 會自動處理製造業和其他工業環境的目視檢測工作。這個系統採用先進的電腦視覺和深度學習技術,可分析圖片和影片、識別異常狀況、偵測並找出瑕疵,以及檢查組裝產品是否缺少零件或有不良零件。
您不必具備技術專業知識,只要提供少量加上標籤的圖片,就能訓練自訂模型,在生產線中有效地執行推論,並持續運用來自廠區的最新資料更新模型。

統合式 Vision AI 平台
Vertex AI Vision 是全代管的應用程式開發環境,可讓開發人員輕鬆建構、部署及管理電腦視覺應用程式,進而處理多種形式的資料,例如文字、圖片、影片和表格型資料。這個環境能夠將建構時間從數天縮短為幾分鐘,且費用是目前產品/服務的十分之一。
您可以建構並部署自訂模型,然後透過 CI/CD 管道執行管理和擴充工作。另外,Vertex AI Vision 也與多項熱門開放原始碼工具整合,例如 TensorFlow 和 PyTorch 等。

資料隱私權和安全性
Google Cloud 提供領先業界的功能,讓客戶能控管自己的資料,清楚掌握資料的存取時間和方式。
Google Cloud 客戶的資料為客戶所有。我們採用最嚴謹的安全措施,確保客戶資料的安全,並提供相關工具和功能協助您自行控管資料。客戶資料並非屬 Google 所有,您才是資料的擁有者。我們只會根據您的協議內容處理您的資料。
詳情請前往隱私權資源中心。
比較電腦視覺產品
| 服務 | 支援的裝置 | 主要功能與特色 |
|---|---|---|
輕鬆快速地整合基本視覺功能。 | 預先建構的功能,例如為圖片加上標籤、偵測臉部和地標、光學字元辨識、安全搜尋等。 按用量計費,符合成本效益。 | |
從掃描的文件和圖片中擷取深入分析資訊,將文件工作流程自動化。 | 融入 OCR (採用生成式 AI)、自然語言處理、機器學習技術,可協助理解文件、擷取文字、識別實體及分類文件。 | |
影片內容分析、內容審核及推薦、媒體封存檔和內容相關廣告。 | 物件偵測與追蹤、情境理解、動作辨識、臉部偵測和分析、文字偵測與辨識。 | |
將製造業與工業環境的目視檢測工作自動化 | 偵測異常狀況、偵測並找出瑕疵,以及檢查組件。 | |
依特定需求建構及部署自訂模型。 | 使用資料準備工具、訓練及部署模型,以及全面控管解決方案。需具備專業知識。 | |
取得自動產生的圖片說明。 圖片分類及搜尋。 內容審核及推薦。 | 圖像生成、圖像編輯、圖像說明生成和多模態嵌入。 請參閱這份完整清單,瞭解各項功能及其推出階段。 |
這些產品已針對不同用途經過最佳化調整,讓您能藉助預先訓練的模型快速取得成果,並輕鬆視需要進行微調。
這些產品已針對不同用途經過最佳化調整,讓您能藉助預先訓練的模型快速取得成果,並輕鬆視需要進行微調。

示範
瞭解如何將電腦視覺用於你的檔案
偵測原始檔案中的文字並自動製作摘要
透過生成式 AI 產生大型文件的摘要
如右側架構圖所示,將新 PDF 文件加入 Cloud Storage bucket 時,會觸發這項解決方案部署的管道。這個管道會從文件擷取文字並據以建立摘要,然後將摘要儲存在資料庫中,方便您查看及搜尋。
您可使用兩種方式叫用應用程式:透過Jupyter 筆記本上傳檔案,或直接前往 Google Cloud 控制台的 Cloud Storage 叫用。

預估部署時間:11 分鐘 (設定需 1 分鐘,部署需 10 分鐘)。
操作說明
透過生成式 AI 產生大型文件的摘要
如右側架構圖所示,將新 PDF 文件加入 Cloud Storage bucket 時,會觸發這項解決方案部署的管道。這個管道會從文件擷取文字並據以建立摘要,然後將摘要儲存在資料庫中,方便您查看及搜尋。
您可使用兩種方式叫用應用程式:透過Jupyter 筆記本上傳檔案,或直接前往 Google Cloud 控制台的 Cloud Storage 叫用。
預估部署時間:11 分鐘 (設定需 1 分鐘,部署需 10 分鐘)。
建構影像處理管道
在無伺服器架構上進行可擴充的圖片處理作業
如右側圖表所示,這項解決方案使用預先訓練的機器學習模型,分析使用者提供的圖片,並生成圖片註解文字。部署這項解決方案,即可建立圖片處理服務,來協助處理不安全或有害的使用者自製內容、將書面文件的文字數位化,以及偵測並分類圖片物件等。
您可以查看安全性設定及其他設定,瞭解如何配合不同的需求,調整影像處理服務。

預估部署時間:12 分鐘 (設定需 2 分鐘,部署需 10 分鐘)。
操作說明
在無伺服器架構上進行可擴充的圖片處理作業
如右側圖表所示,這項解決方案使用預先訓練的機器學習模型,分析使用者提供的圖片,並生成圖片註解文字。部署這項解決方案,即可建立圖片處理服務,來協助處理不安全或有害的使用者自製內容、將書面文件的文字數位化,以及偵測並分類圖片物件等。
您可以查看安全性設定及其他設定,瞭解如何配合不同的需求,調整影像處理服務。
預估部署時間:12 分鐘 (設定需 2 分鐘,部署需 10 分鐘)。
使用生成式 AI 自動產生圖片說明
操作說明
串流處理影片
使用 Vertex AI Vision 從串流影片中取得洞察資訊
使用應用程式分析影片資料前,先透過 Vertex AI Vision 中的串流服務建立持續資料流管道。接著,Google 預先訓練的模型或您的自訂模型會分析擷取的資料。經串流處理的分析輸出內容會儲存在 Vertex AI Vision 倉儲中,您可在其中使用進階 AI 技術輔助搜尋功能,查詢非結構化媒體內容。
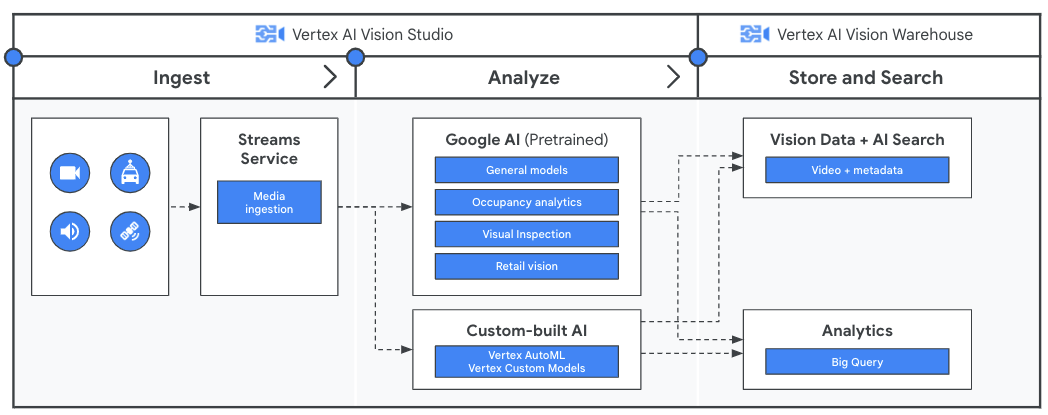
操作說明
使用 Vertex AI Vision 從串流影片中取得洞察資訊
使用應用程式分析影片資料前,先透過 Vertex AI Vision 中的串流服務建立持續資料流管道。接著,Google 預先訓練的模型或您的自訂模型會分析擷取的資料。經串流處理的分析輸出內容會儲存在 Vertex AI Vision 倉儲中,您可在其中使用進階 AI 技術輔助搜尋功能,查詢非結構化媒體內容。
運用生成式 AI 從文件中擷取文字和洞察資訊
運用 Document AI 從存在細微差異的文件中取得洞察資訊
Document AI Custom Extractor 採用基礎模型,能以更快、更準確的方式從文件中擷取出文字和資料 (無論是一般或特定領域的內容)。只要利用 5 到 10 份文件輕鬆微調,即可提高成效。
如要訓練自己的模型,請使用基礎模型為資料集自動加上標籤,藉此縮短導入實際工作環境的時間。
您也可以選擇使用預先訓練的專用處理器。如要查看完整的處理器清單,請按這裡。
操作說明
運用 Document AI 從存在細微差異的文件中取得洞察資訊
Document AI Custom Extractor 採用基礎模型,能以更快、更準確的方式從文件中擷取出文字和資料 (無論是一般或特定領域的內容)。只要利用 5 到 10 份文件輕鬆微調,即可提高成效。
如要訓練自己的模型,請使用基礎模型為資料集自動加上標籤,藉此縮短導入實際工作環境的時間。
您也可以選擇使用預先訓練的專用處理器。如要查看完整的處理器清單,請按這裡。
執行高精確度的目視檢測工作
透過目視檢測 AI 將品質檢查作業自動化
目視檢測 AI 的每個環節都經過最佳化,讓您輕鬆完成設定,並快速從投資中獲得報酬。與一般用途的機器學習平台相比,加上標籤的圖片數量需求最高少 300 倍,就能開始訓練高效能檢查模型,而準確率高出 10 倍。您不需要具備技術專業知識就能訓練模型,並在地端部署環境執行。最棒的是,模型可運用來自廠區的資料流,持續更新,在您發現新用途時提供準確度更高的結果。
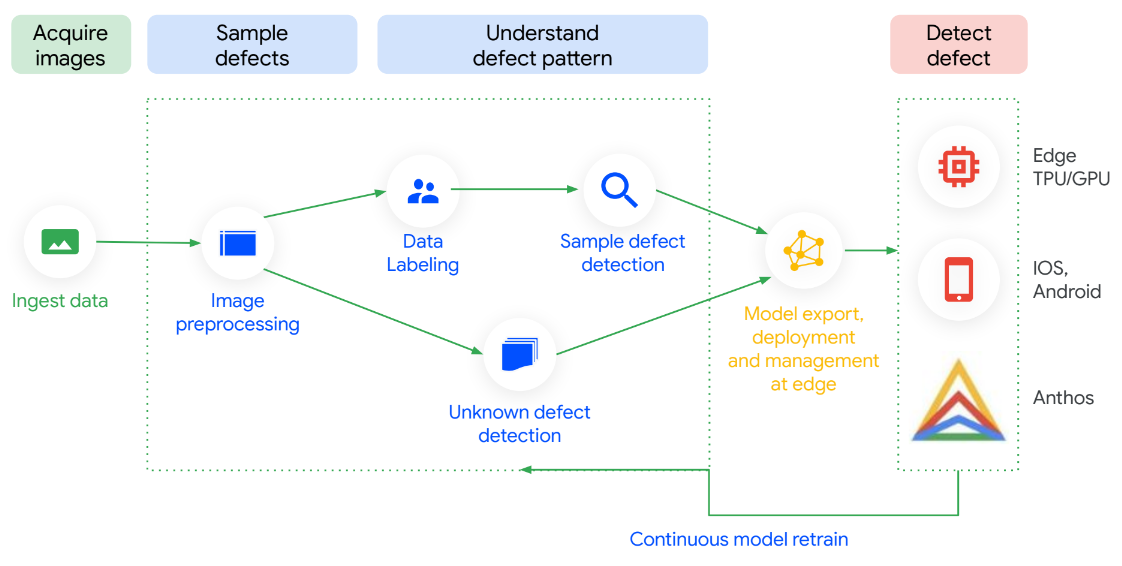
操作說明
透過目視檢測 AI 將品質檢查作業自動化
目視檢測 AI 的每個環節都經過最佳化,讓您輕鬆完成設定,並快速從投資中獲得報酬。與一般用途的機器學習平台相比,加上標籤的圖片數量需求最高少 300 倍,就能開始訓練高效能檢查模型,而準確率高出 10 倍。您不需要具備技術專業知識就能訓練模型,並在地端部署環境執行。最棒的是,模型可運用來自廠區的資料流,持續更新,在您發現新用途時提供準確度更高的結果。
定價
| Vision AI 計價方式 | 每項視覺產品/服務都有一組專屬功能或處理器,計價方式不盡相同。如要進一步瞭解價格,請參閱詳細定價頁面。 | ||
|---|---|---|---|
| 免費方案 | 產品/服務 | 優惠價格 | 詳細資料 |
Vision API | 前 1,000 個單位 每月免費用量 | 超過 5,000,001 個單位 每月 | |
Document AI | 不適用 價格因處理器而異。 | 超過 5,000,001 頁 Enterprise Document OCR Processor 的每月用量 | |
Video Intelligence API | 前 1,000 分鐘 每月免費用量 | 超過 100,000 分鐘 每月 | |
Vertex AI Vision | 不適用 價格因功能而異。 |
| |
Imagen:多模態嵌入 |
|
| $0.0001 美元 每個圖片輸入內容的費用 |
Imagen - 圖像說明生成 |
|
| $0.0015 美元 每張圖片的費用 |
Gemini Pro Vision | |||
Vision AI 計價方式
每項視覺產品/服務都有一組專屬功能或處理器,計價方式不盡相同。如要進一步瞭解價格,請參閱詳細定價頁面。
Imagen:多模態嵌入
$0.0001 美元
每個圖片輸入內容的費用
Imagen - 圖像說明生成
$0.0015 美元
每張圖片的費用











