
Engineered for next-generation AI
Tensor Processing Units (TPUs) are custom accelerators co-designed with open software to power the entire AI lifecycle—from frontier training and large-scale inference to the multi-step reasoning data demands of Agentic AI.
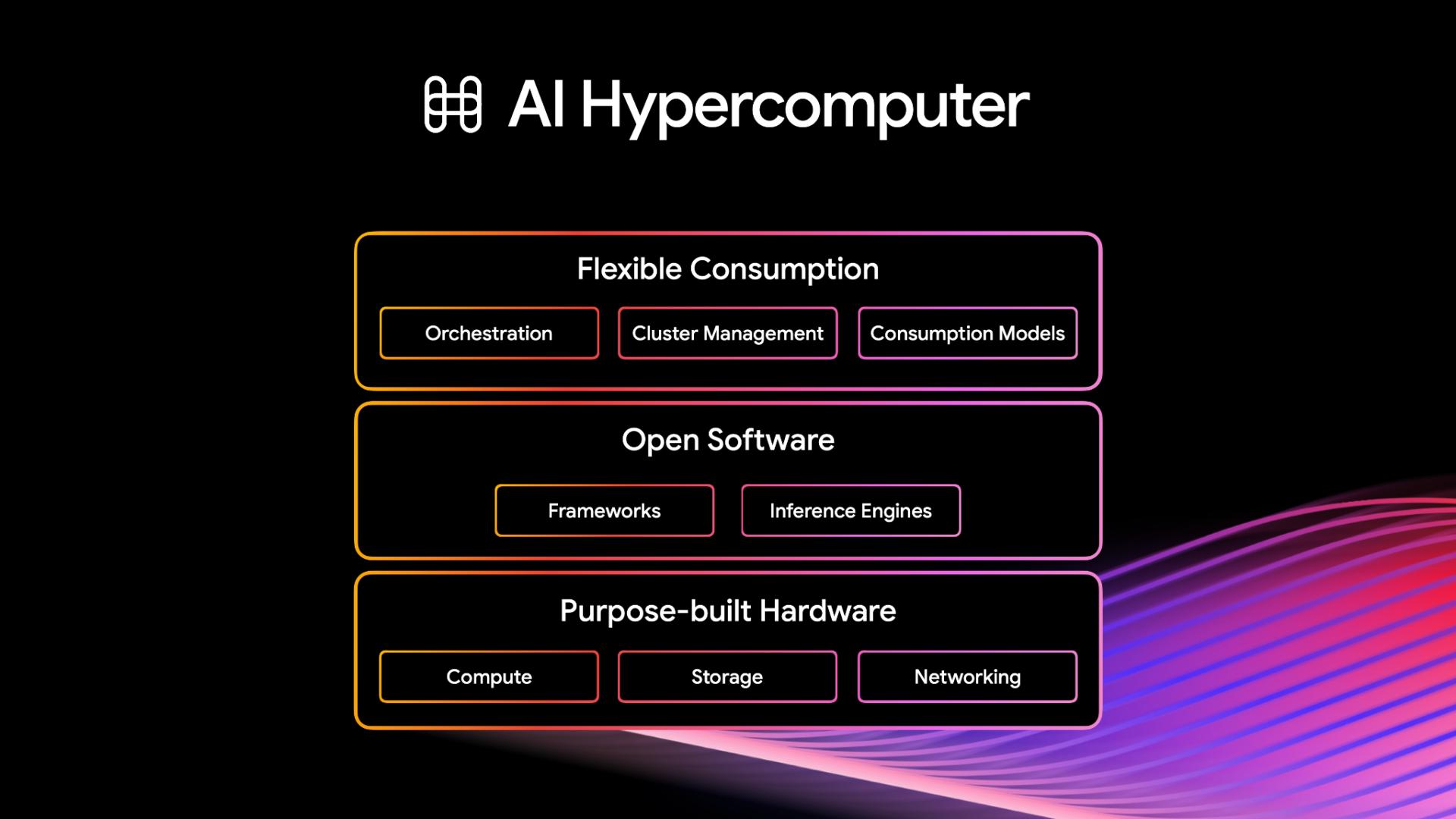
Powered by AI Hypercomputer
TPUs are powered by Google Cloud's AI Hypercomputer, a groundbreaking architecture that brings together purpose-built hardware, open software, and flexible consumption models.
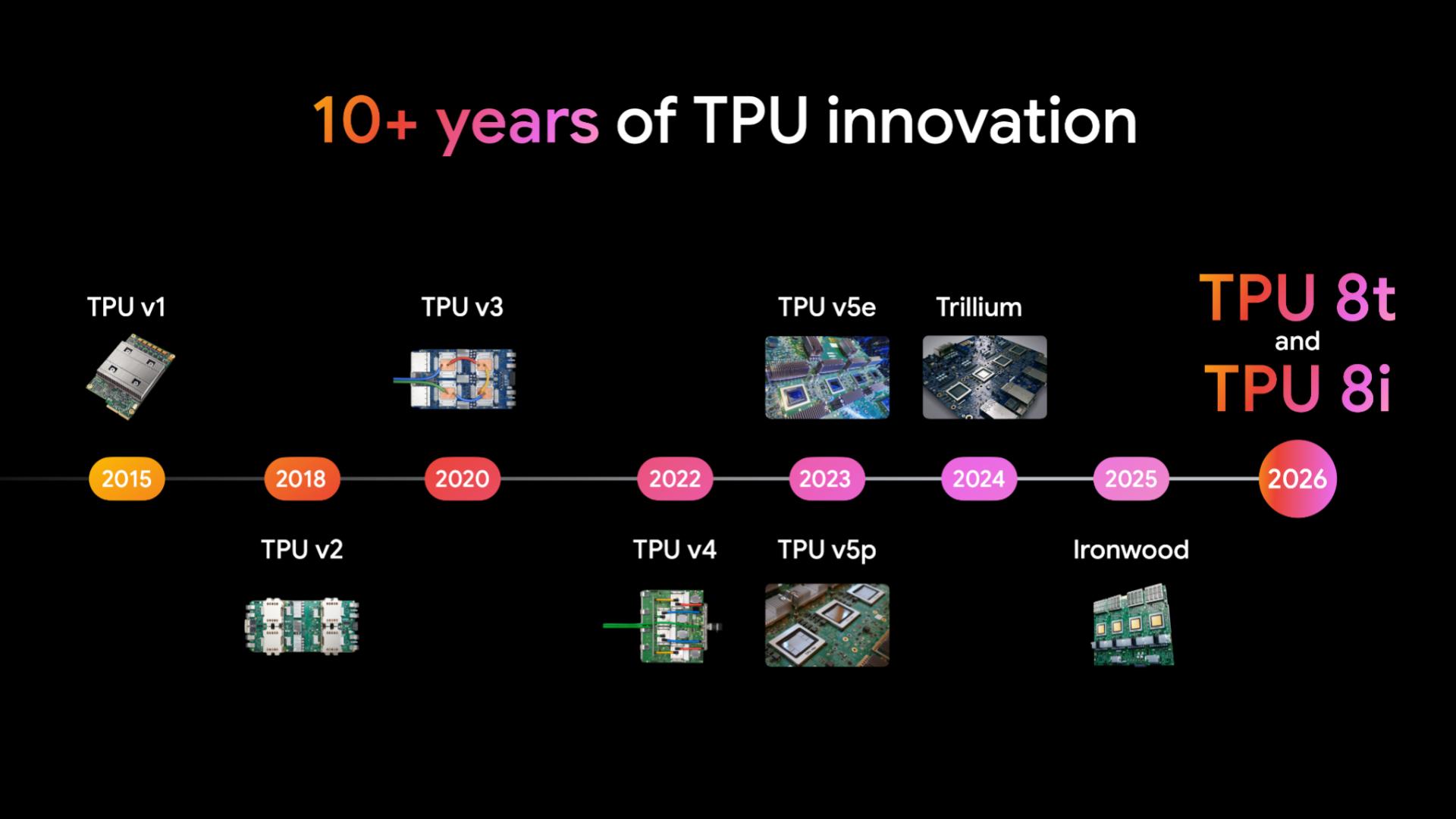
A decade of Tensor Processing Units (TPUs)
TPUs are purpose-built for advanced AI workloads—from large language models and code generation to intelligent agents. They are the engine behind Gemini and Google’s flagship billion-user products, including Search, Photos, and Maps.
Engineered for next-generation AI
Tensor Processing Units (TPUs) are custom accelerators co-designed with open software to power the entire AI lifecycle—from frontier training and large-scale inference to the multi-step reasoning data demands of Agentic AI.
Powered by AI Hypercomputer
TPUs are powered by Google Cloud's AI Hypercomputer, a groundbreaking architecture that brings together purpose-built hardware, open software, and flexible consumption models.
A decade of Tensor Processing Units (TPUs)
TPUs are purpose-built for advanced AI workloads—from large language models and code generation to intelligent agents. They are the engine behind Gemini and Google’s flagship billion-user products, including Search, Photos, and Maps.
Benefits
Open, flexible, and reliable operations

Build on an open ecosystem using familiar libraries and tools. TPUs provide native, high-performance support for PyTorch and JAX, and support the vLLM engine for fast inference. Manage and scale these deployments reliably across global clusters with Google Kubernetes Engine (GKE).
Performance without compromise

Turn months of training into weeks for frontier models. With up to 1 million TPU chips in a single cluster, TPUs maximize goodput, ensuring nearly every compute cycle goes toward active learning.
Benefits
Open, flexible, and reliable operations
Build on an open ecosystem using familiar libraries and tools. TPUs provide native, high-performance support for PyTorch and JAX, and support the vLLM engine for fast inference. Manage and scale these deployments reliably across global clusters with Google Kubernetes Engine (GKE).
Performance without compromise
Turn months of training into weeks for frontier models. With up to 1 million TPU chips in a single cluster, TPUs maximize goodput, ensuring nearly every compute cycle goes toward active learning.




TPU 8t
TPU 8t is built for large-scale pre-training and embedding-heavy workloads at a scale of 9,600 chips in a single superpod, delivering the high-density compute required for frontier models with nearly 3x the compute performance per pod over the previous generation.
Coming soon.
TPU 8i
TPU 8i is optimized for post-training and inference. It provides an 80% performance-per-dollar improvement over previous generations for low-latency inference for large MoE models.
Coming soon.
Ironwood - 7th generation
7th-generation energy-efficient TPU engineered for large-scale training, reasoning, and inference. Features 9,216 liquid-cooled chips per pod, provides 42.5 ExaFlops and 4X better performance per chip over Trillium.
Generally available.
Trillium - 6th generation
Sixth-generation TPU featuring improved energy efficiency and peak compute performance for training and inference. Operates with 67% more energy efficiency and provides 4.7x higher peak compute performance per chip compared to previous generation TPU v5e.
Generally available.
TPU 8t
TPU 8t is built for large-scale pre-training and embedding-heavy workloads at a scale of 9,600 chips in a single superpod, delivering the high-density compute required for frontier models with nearly 3x the compute performance per pod over the previous generation.
Coming soon.
TPU 8i
TPU 8i is optimized for post-training and inference. It provides an 80% performance-per-dollar improvement over previous generations for low-latency inference for large MoE models.
Coming soon.
Ironwood - 7th generation
7th-generation energy-efficient TPU engineered for large-scale training, reasoning, and inference. Features 9,216 liquid-cooled chips per pod, provides 42.5 ExaFlops and 4X better performance per chip over Trillium.
Generally available.
Trillium - 6th generation
Sixth-generation TPU featuring improved energy efficiency and peak compute performance for training and inference. Operates with 67% more energy efficiency and provides 4.7x higher peak compute performance per chip compared to previous generation TPU v5e.
Generally available.






TPU software stack
TPU software stack is engineered to bridge the gap between high-level machine learning code and custom silicon to optimize raw hardware efficiency.
JAX
Compile complex mathematical operations at near-native hardware speed on TPUs. This open-source library for numerical computation and automatic differentiation scales effortlessly across massive distributed TPU clusters using an explicit device mesh.
TorchTPU & PyTorch
Run PyTorch workloads directly on TPUs using standard syntax. Built with Meta, this native, "eager-first" stack enables the migration of existing codebases with minimal changes to unlock major cost-performance benefits—without requiring engineering teams to learn a new framework.
OpenXLA
Reduce compilation bottlenecks to extract high performance from TPU hardware. This open-source machine learning compiler automatically fuses operations, optimizes memory usage, and eliminates framework overhead for linear algebra computations across TPU backends.
MaxText
Slash training timelines for massive foundation models. This JAX-based reference implementation provides a highly scalable, out-of-the-box blueprint to achieve peak hardware utilization during LLM pre-training on TPUs.
Tunix
Streamline LLM post-training and alignment on TPU infrastructure. This lightweight, open-source JAX library delivers scalable workflows for Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to efficiently turn raw models into production-ready agents.
vLLM
Maximize serving concurrency and drive down operational costs for real-time TPU inference. This high-throughput open-source engine leverages memory management techniques like PagedAttention to eliminate waste and deliver highly efficient LLM serving on TPU architecture.
TPU software stack
TPU software stack is engineered to bridge the gap between high-level machine learning code and custom silicon to optimize raw hardware efficiency.
JAX
Compile complex mathematical operations at near-native hardware speed on TPUs. This open-source library for numerical computation and automatic differentiation scales effortlessly across massive distributed TPU clusters using an explicit device mesh.
TorchTPU & PyTorch
Run PyTorch workloads directly on TPUs using standard syntax. Built with Meta, this native, "eager-first" stack enables the migration of existing codebases with minimal changes to unlock major cost-performance benefits—without requiring engineering teams to learn a new framework.
OpenXLA
Reduce compilation bottlenecks to extract high performance from TPU hardware. This open-source machine learning compiler automatically fuses operations, optimizes memory usage, and eliminates framework overhead for linear algebra computations across TPU backends.
MaxText
Slash training timelines for massive foundation models. This JAX-based reference implementation provides a highly scalable, out-of-the-box blueprint to achieve peak hardware utilization during LLM pre-training on TPUs.
Tunix
Streamline LLM post-training and alignment on TPU infrastructure. This lightweight, open-source JAX library delivers scalable workflows for Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to efficiently turn raw models into production-ready agents.
vLLM
Maximize serving concurrency and drive down operational costs for real-time TPU inference. This high-throughput open-source engine leverages memory management techniques like PagedAttention to eliminate waste and deliver highly efficient LLM serving on TPU architecture.
TPUs are powering the innovators





Additional resources
- Run large-scale AI pre-training workloadsReduce pre-training timelines for massive foundation models. The TPU 8t provides high-performance compute power within a single pod and scales using the Virgo network. Paired with rapid storage access and Axion-powered NUMA isolation, the architecture achieves high Goodput—ensuring compute cycles are spent on active model building rather than idling during data transfer or hardware resets.A developer’s guide to training with Ironwood TPUs
- Efficient post-training and reinforcement learningBuild base models into intelligent agents through intensive post-training workflows. The 8th generation of TPU system rapidly processes continuous reinforcement learning trials, rewarding the best reasoning paths without the cycle delays common to previous generations. This allows you to efficiently fine-tune world models, enabling agents to refine their reasoning in simulated environments before executing in the real world.MaxText post-training
- Low-latency AI inference workloads at scaleBreak the inference memory wall. The TPU 8i expands on-chip SRAM and high-bandwidth memory, hosting high-capacity KV caches entirely on-silicon. By using the SparseCore-Collectives Acceleration Engine (SC-CAE) to offload global communication tasks, this architecture significantly reduces on-chip latency, freeing the main compute cores for pure, low-latency token generation.Accelerate AI Inference with Google Cloud
- Virgo Network, Google’s scale-out AI data center fabricVirgo Network is a scale-out fabric designed for the extreme requirements of modern AI workloads. Built on high-radix switches that reduce network layers by allowing more ports per switch, it employs a flat, two-layer non-blocking topology.Read the announcement article
- Cluster-level reliability for trillion-parameter models on TPUsFor over a decade, Google has operated Tensor Processing Unit (TPU) clusters at scale, achieving reliability that meets the architectural requirements of modern AI workloads. In this blog, we’re presenting our cluster-level reliability framework for Google Cloud TPUs that focuses on collective performance at the superpod level, and one we use internally within Google to build the world’s most advanced AI models.Read the article
- Designing sustainable AI with TPUsTake a deep dive into TPU efficiency and lifecycle emissions. Our significant improvements in hardware carbon-efficiency complement rapid advancements in AI model and algorithm design.Read the article
- Introduction to Cloud TPUReview the Cloud TPU documentation to get an introduction into Tensor Processing Units (TPUs).Review the documentation
- TPU architectureThe following documentation describes key components of the TPU cloud architecture.Review the documentation
- TPU RecipesTPU recipes Instructions to reproduce a specific workload on Google Cloud TPUs.View the guide
Technical Use Cases
- Run large-scale AI pre-training workloadsReduce pre-training timelines for massive foundation models. The TPU 8t provides high-performance compute power within a single pod and scales using the Virgo network. Paired with rapid storage access and Axion-powered NUMA isolation, the architecture achieves high Goodput—ensuring compute cycles are spent on active model building rather than idling during data transfer or hardware resets.A developer’s guide to training with Ironwood TPUs
- Efficient post-training and reinforcement learningBuild base models into intelligent agents through intensive post-training workflows. The 8th generation of TPU system rapidly processes continuous reinforcement learning trials, rewarding the best reasoning paths without the cycle delays common to previous generations. This allows you to efficiently fine-tune world models, enabling agents to refine their reasoning in simulated environments before executing in the real world.MaxText post-training
- Low-latency AI inference workloads at scaleBreak the inference memory wall. The TPU 8i expands on-chip SRAM and high-bandwidth memory, hosting high-capacity KV caches entirely on-silicon. By using the SparseCore-Collectives Acceleration Engine (SC-CAE) to offload global communication tasks, this architecture significantly reduces on-chip latency, freeing the main compute cores for pure, low-latency token generation.Accelerate AI Inference with Google Cloud
Articles
- Virgo Network, Google’s scale-out AI data center fabricVirgo Network is a scale-out fabric designed for the extreme requirements of modern AI workloads. Built on high-radix switches that reduce network layers by allowing more ports per switch, it employs a flat, two-layer non-blocking topology.Read the announcement article
- Cluster-level reliability for trillion-parameter models on TPUsFor over a decade, Google has operated Tensor Processing Unit (TPU) clusters at scale, achieving reliability that meets the architectural requirements of modern AI workloads. In this blog, we’re presenting our cluster-level reliability framework for Google Cloud TPUs that focuses on collective performance at the superpod level, and one we use internally within Google to build the world’s most advanced AI models.Read the article
- Designing sustainable AI with TPUsTake a deep dive into TPU efficiency and lifecycle emissions. Our significant improvements in hardware carbon-efficiency complement rapid advancements in AI model and algorithm design.Read the article
Documentation
- Introduction to Cloud TPUReview the Cloud TPU documentation to get an introduction into Tensor Processing Units (TPUs).Review the documentation
- TPU architectureThe following documentation describes key components of the TPU cloud architecture.Review the documentation
- TPU RecipesTPU recipes Instructions to reproduce a specific workload on Google Cloud TPUs.View the guide

Frequently Asked Questions
What is a Tensor Processing Unit (TPU)?
TPUs are custom-designed application-specific integrated circuits (ASICs) developed by Google. They are purpose-built from the ground up to accelerate machine learning and artificial intelligence workloads. TPUs are optimized specifically for the heavy matrix multiplication and tensor operations that act as the fundamental building blocks of neural networks, powering everything from large language models to complex reasoning agents.
How does the TPU architecture work?
At the heart of a TPU is a specialized Matrix Multiplier Unit (MXU) that processes massive amounts of matrix operations simultaneously. TPUs utilize a "systolic array" architecture that reads data once and flows it continuously through thousands of arithmetic logic units (ALUs), accumulating results without needing to constantly read and write to memory. They also support reduced precision arithmetic (like 16-bit or 8-bit floating-point), allowing for millions of computations per second without sacrificing the accuracy required for AI models.
Which machine learning frameworks do Cloud TPUs support?
Cloud TPUs offer native, high-performance support for leading machine learning frameworks, primarily TensorFlow, PyTorch, and JAX. Code written in these frameworks is compiled by the Accelerated Linear Algebra (XLA) compiler, which automatically optimizes the computational graph to run efficiently on the underlying TPU hardware.
What types of workloads are best suited for TPUs?
TPUs excel at deep learning tasks that require massive parallel matrix operations. They are highly recommended for:
- Models dominated by matrix computations
- Training runs that take weeks or months to converge
- Large foundation models and large language models (LLMs)
- Workloads with ultra-large embeddings, such as advanced recommendation engines
- Continuous reinforcement learning and high-volume, low-latency inference
What are TPU pods and slices?
A TPU Pod is a massive physical cluster of TPU chips connected together over a specialized, high-speed network (such as Google's Optical Circuit Switching or Virgo network). A single superpod can contain thousands of interconnected chips. A "slice" is a smaller, dedicated subset of a pod that you can rent. This networking architecture allows developers to scale their AI workloads across massive amounts of compute with little to no code changes, effectively operating the entire slice as a single unified machine.
What is ML "Goodput" in the context of TPU training?
Goodput refers to the actual, productive time your infrastructure spends actively training your model, rather than idling. Training massive foundation models involves complex orchestration across thousands of chips, meaning compute cycles can easily be wasted on data transfer delays, hardware resets, or checkpointing. Cloud TPUs are engineered to maximize Goodput through high-bandwidth interconnects and optimized memory caching, ensuring that paid compute cycles contribute directly to model advancement.
How is orchestration handled at scale for TPUs?
Users can support reliability, comprehensive monitoring, and management using Google Kubernetes Engine (GKE) and Cluster Director. By leveraging GKE for TPU, customers operate in a cloud-native ecosystem featuring Inference Gateway for load balancing and the ability to scale deployments up to 130,000 GKE nodes.


















