RAG in production faster with Ray, LangChain and HuggingFace
Julie Amundson
Senior Staff Software Engineer
Jason Soo Hoo
Software Engineering Manager
We’re excited to announce the release of a quickstart solution and reference architecture for retrieval augmented generation (RAG) applications, designed to accelerate your journey to production. In this post, you’ll learn how to quickly deploy a complete RAG application on Google Kubernetes Engine (GKE), and Cloud SQL for PostgreSQL and pgvector, using Ray, LangChain, and Hugging Face.
What is RAG?
RAG can improve the outputs of foundation modes, such as large language models (LLMs), for a specific application. Rather than relying purely on knowledge developed during training, AI apps equipped for RAG can retrieve the information most relevant to a user’s prompt from an external knowledge base, then add that information to the prompt before sending it to the generative model. The knowledge base can come in various forms, such as a vector database, traditional search index, or relational database — and by accessing it, customer service chabots can look up help center articles, digital shopping assistants can tap into product catalogs and customer reviews, and AI-powered travel agents can deliver up-to-date flight and hotel information.
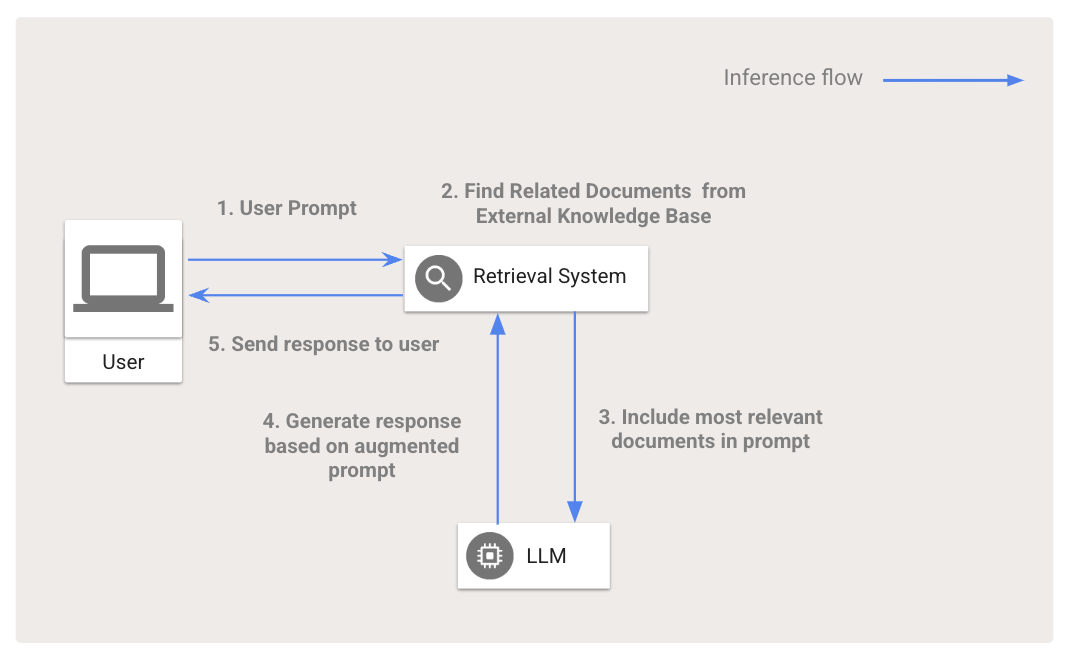
LLMs rely on their training data, which can quickly fall out of date and may not include data relevant to the application’s domain. Re-training or fine-tuning an LLM to provide fresh, domain-specific data can be an expensive and complex process. RAG not only gives the LLM access to such data without training or-fine tuning. but can also guide an LLM toward factual responses, thereby reducing hallucinations and enabling applications to provide human-verifiable source material.
For more background on how RAG works, see our blog on context-aware code generation.
AI Infrastructure for RAG
Prior to the rise of Generative AI, a typical application architecture might involve a database, a set of microservices, and a frontend. Even the most basic RAG applications introduce new requirements for serving LLMs, processing, and retrieving unstructured data. To meet these requirements, customers need infrastructure that is optimized specifically for AI workloads.
Many customers choose to access AI infrastructure like TPUs and GPUs via a fully managed platform, such as Vertex AI. Others, however, prefer to manage their own infrastructure on top of GKE while leveraging open-source frameworks and open models. This blog post is for the latter group.
Building an AI platform from scratch involves a number of key decisions, such as which frameworks to use for model serving, which machine shapes to use for inference, how to protect sensitive data, how to meet cost and performance requirements, and how to scale as traffic grows. Each decision involves many tradeoffs against a vast and fast-changing landscape of generative AI tools.
This is why we have developed a quickstart solution and reference architecture for RAG applications built on top of GKE, Cloud SQL, and open-source frameworks Ray, LangChain and Hugging Face. Our solution is designed to help you get started quickly and accelerate your journey to production with RAG best practices built-in from the start.
Benefits of RAG on GKE and Cloud SQL
GKE and Cloud SQL accelerate your journey to production in a variety of ways:
-
Load Data Fast - Use Ray Data to seamlessly access data in parallel from your Ray cluster via GKE’s GCSFuse driver. Efficiently load your embeddings into Cloud SQL for PostgreSQL and pgvector to perform low latency vector search at scale.
-
Fast deploy - Quickly deploy Ray, JupyterHub, and Hugging Face Text Generation Inference (TGI) to your GKE cluster
-
Security made simple - Get move-in ready Kubernetes security with GKE. Filter out sensitive or toxic content using Sensitive Data Protection (SDP). Leverage Google-standard authentication with Identity-Aware Proxy so users can seamlessly connect to your LLM frontend and Jupyter notebooks.
-
Cost efficiency & reduced management overhead - GKE reduces cluster maintenance and makes it easy to take advantage of cost-saving measures like spot nodes via YAML configuration.
-
Scalability - GKE automatically provisions nodes as traffic grows, eliminating the need for manual configuration to scale up.
Deploying RAG on GKE and Cloud SQL
Our end-to-end RAG application and reference architecture provide the following:
-
Google Cloud project - configures your project with the needed prerequisites to run the RAG application, including a GKE Cluster and Cloud SQL for PostgreSQL and pgvector instance
-
AI frameworks - deploys Ray, JupyterHub, and Hugging Face TGI to GKE
-
RAG Embedding Pipeline - generates embeddings and populates the Cloud SQL for PostgreSQL and pgvector instance
-
Example RAG Chatbot Application - deploys a web-based RAG chatbot to GKE
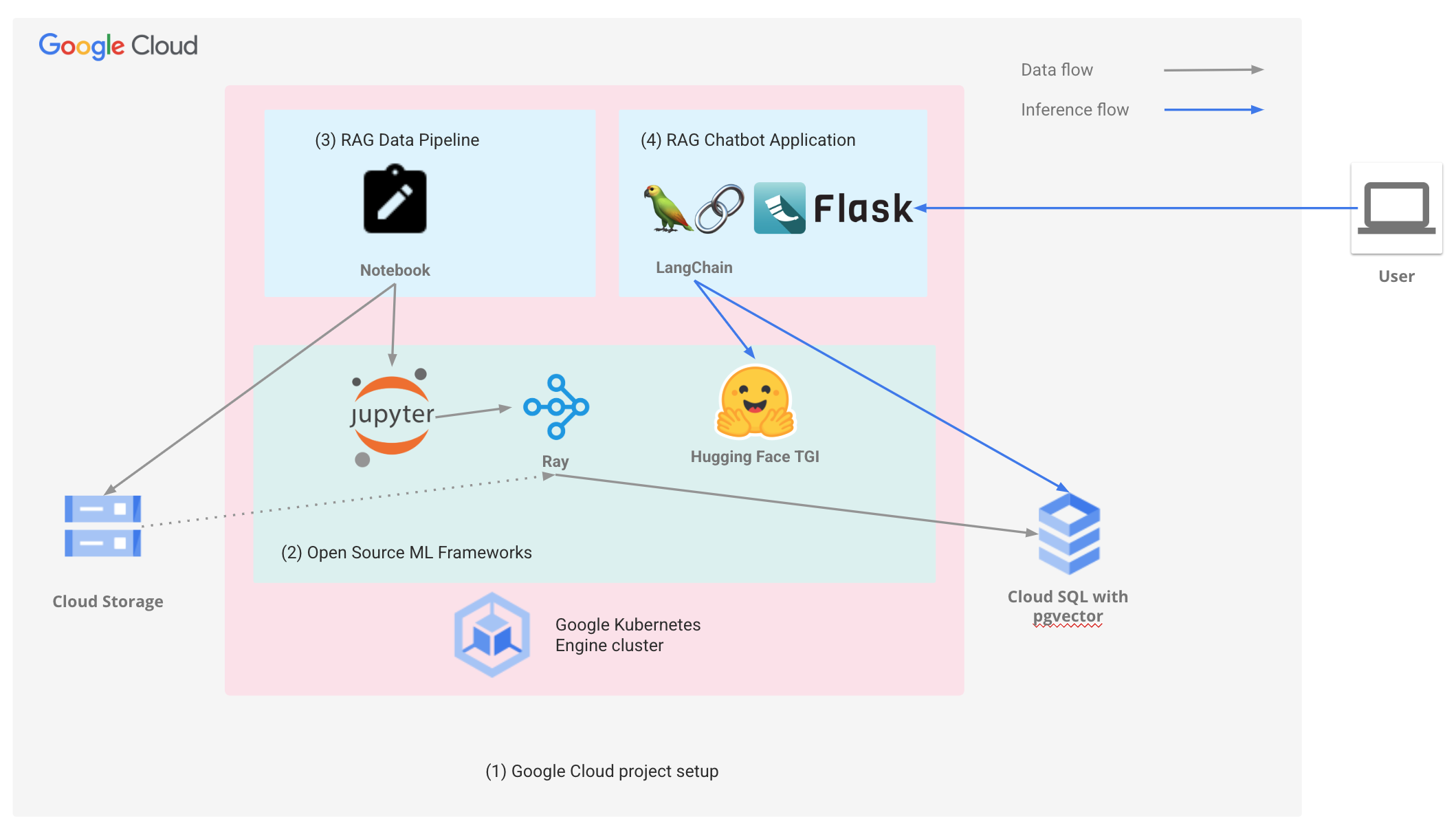
The example chatbot application provides a web interface where users can interact with an open source LLM. It leverages data loaded by the RAG data pipeline into Cloud SQL for PostgreSQL with pgvector, providing more comprehensive and informative responses to user queries.
Our end-to-end RAG solution serves as a starting point for further development, demonstrating the potential of this technology for a wide range of applications. By combining the power of RAG with the scalability and flexibility of GKE and Cloud SQL as well as security features of Google Cloud, developers can build powerful and versatile applications that can handle complex tasks and provide valuable insights.
We plan to evolve this solution over time, including the ability to add custom data sets, replace models, and update the dataset and vector database with new documents.
For more information, please check our README and github instructions, and reference RAG architecture. You can also view our Google Cloud Next 2024 session discussing RAG.



