Context-aware code generation: Retrieval augmentation and Vertex AI Codey APIs
Parashar Shah
Product Manager
Harkanwal Bedi
Enterprise AI/ML Customer Engineer
Retrieval augmented generation, or RAG, is a way to use external data or information to improve the accuracy of large language models (LLMs). Today, we'll explore how to use RAG to improve the output quality of Google Cloud AI models for code completion and generation on Vertex AI using its Codey APIs, a suite of code generation models that can help software developers complete coding tasks faster. There are three Codey APIs that help boost developer productivity:
- Code completion: Get instant code suggestions based on your current context, making coding a seamless and efficient experience. This API is designed to be integrated into IDEs, editors, and other applications to provide low-latency code autocompletion suggestions as you write code.
- Code generation: Generate code snippets for functions, classes, and more in seconds by describing the code you need in natural language. This API can be helpful when you need to write a lot of code quickly or when you're not sure how to start. It can be integrated into IDEs, editors, and other applications including CI/CD workflows.
- Code chat: Get help on your coding journey throughout the software development lifecycle, from debugging tricky issues to expanding your knowledge with insightful suggestions and answers. This multi-turn chat API can be integrated into IDEs, and editors as a chat assistant. It can also be used in batch workflows.
These models also integrate Responsible AI capabilities, such as source citation and toxicity checking, which automatically cite or block code based on Responsible AI guidelines set by Google.
The Codey APIs deliver far more than generic code generation, allowing you to tailor code output to your organization’s specific style and securely access private code repositories based on your organization’s guidelines. The ability to customize these models helps you generate code that complies with established coding standards and conventions while leveraging custom endpoints and proprietary codebases for code generation tasks.
To achieve this level of customization, you can tune models using specific datasets such as your company's codebase. Alternatively, you can also utilize RAG to incorporate external knowledge sources into the code generation process, which we will now discuss in detail below.
What is RAG?
Traditional large language models are limited by their internal knowledge base, which can lead to responses that are irrelevant or lack context. RAG addresses this issue by integrating an external retrieval system into LLMs, enabling them to access and utilize relevant information on the fly.
This technique allows LLMs to retrieve information from an authoritative external source, augment their input with relevant context, and generate more informed, accurate responses. Code generation models, for instance, can use RAG to fetch relevant information from existing code repositories and use it to create accurate code, documentation, or even fix code errors.
How does RAG work?
Implementing RAG requires a robust retrieval system capable of delivering relevant documents based on user queries.
Here’s a quick overview of how a RAG system works for code generation:
- The retrieval mechanism fetches relevant information from a data source. This information can be in the form of code, text, or other types of data.
- The generation mechanism — i.e., your code generation LLM — uses the retrieved information to generate its output.
- The generated code is now more relevant to the input query or question.
While you can employ various approaches, the most common RAG pattern involves generating embeddings for chunks of source information and indexing them in a vector database, such as Vertex AI Vector Search.
The diagram below shows a high-level RAG pattern for code generation with Codey APIs.
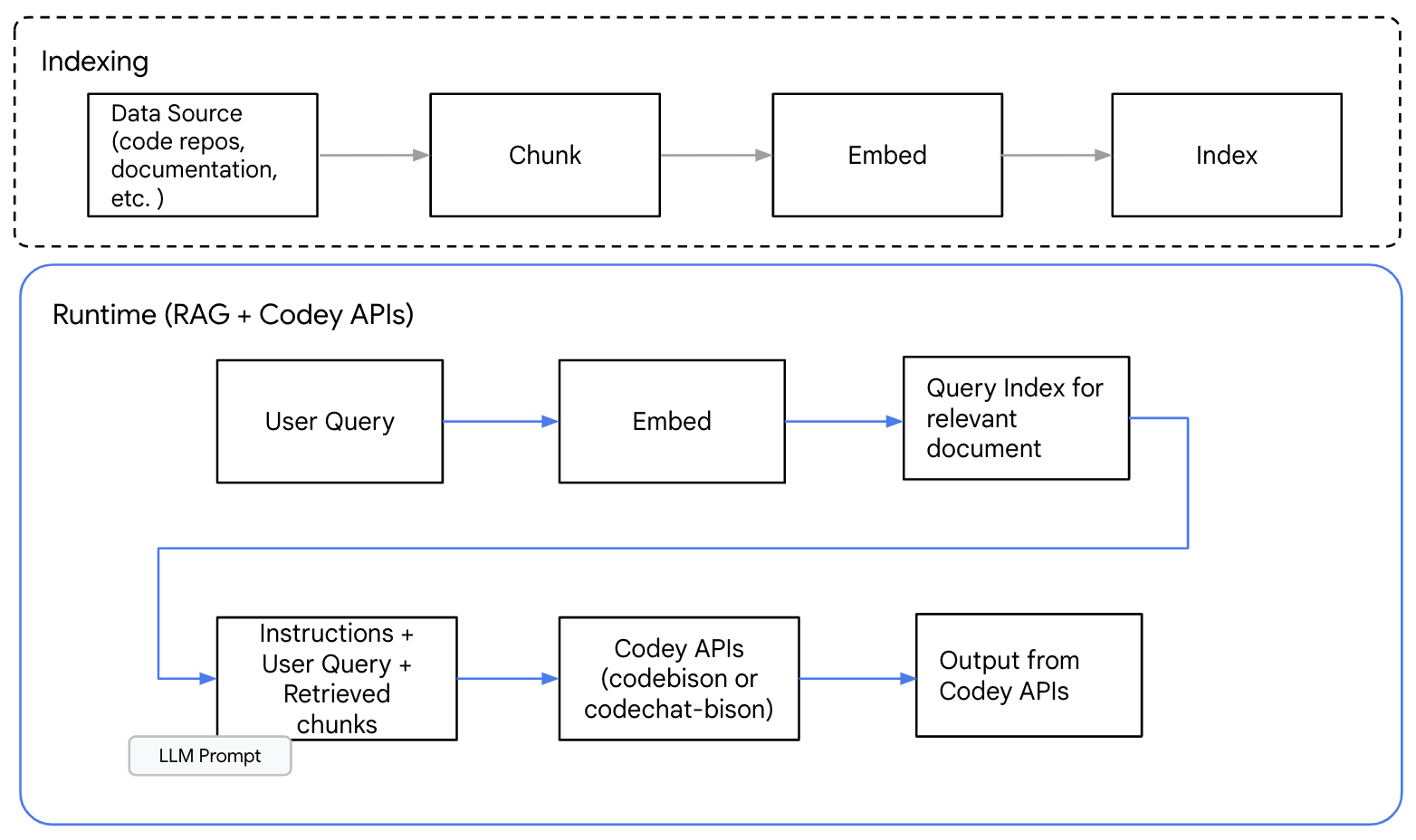
Figure1: High level information flow in RAG pattern for Code Generation
The first step is identifying source information. For code generation, this could be an API definition, code repositories, documentation, or similar. Next, you will need to determine the chunking scheme. Chunking information allows you to select and provide only the relevant content needed to address a query.
The best chunking approaches for RAG are those that preserve the contextual information required for text generation. For code, we recommend choosing chunking methods that respect natural code boundaries, such as function, class, or module borders. Techniques like random splits or mid-sentence/clauses could break the context and degrade your output.
After you create information chunks from the information source, you can generate embeddings and index them in a vector database. When a query is received, another embedding is generated for the query and used to help retrieve relevant information chunks.
From there, a prompt, the user question and relevant information chunks are sent to the Codey APIs to generate a response.
Using RAG with Codey APIs
Now that we understand what RAG is, let’s see how it works for code generation with the Codey models in Vertex AI.
For this demonstration, we utilized the sample code and Jupyter notebooks in Google Cloud's generative AI GitHub repository as the data source. We crawled the entire repository and listed any Jupyter notebooks. Subsequently, we analyzed these notebooks and extracted code elements, which were then chunked and indexed within a vector database. For detailed instructions on how to do this, you can follow the steps in the following notebook.
The example below shows a generated response to a prompt without using RAG to add external context.
Prompt: "Create python function that takes a prompt and predicts using langchain.llms interface for VertexAI text-bison model"
Output without RAG:
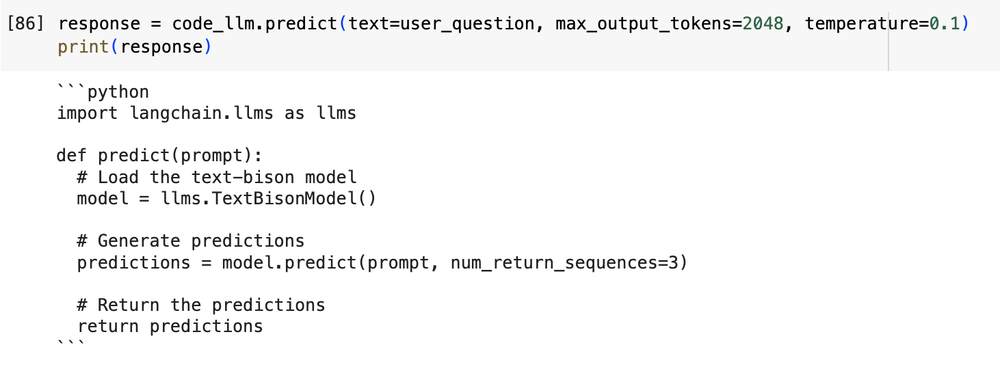
Figure 2: Output from the model without any external context
In the above example, the LLM does not have pre-existing knowledge of the Langchain library. While the response may look convincing and coherent, the model has actually hallucinated and generated code that does not correctly instantiate the text-bison model and make a call to the Predict function.
Next, let's try using RAG for the same prompt.
Output with RAG:
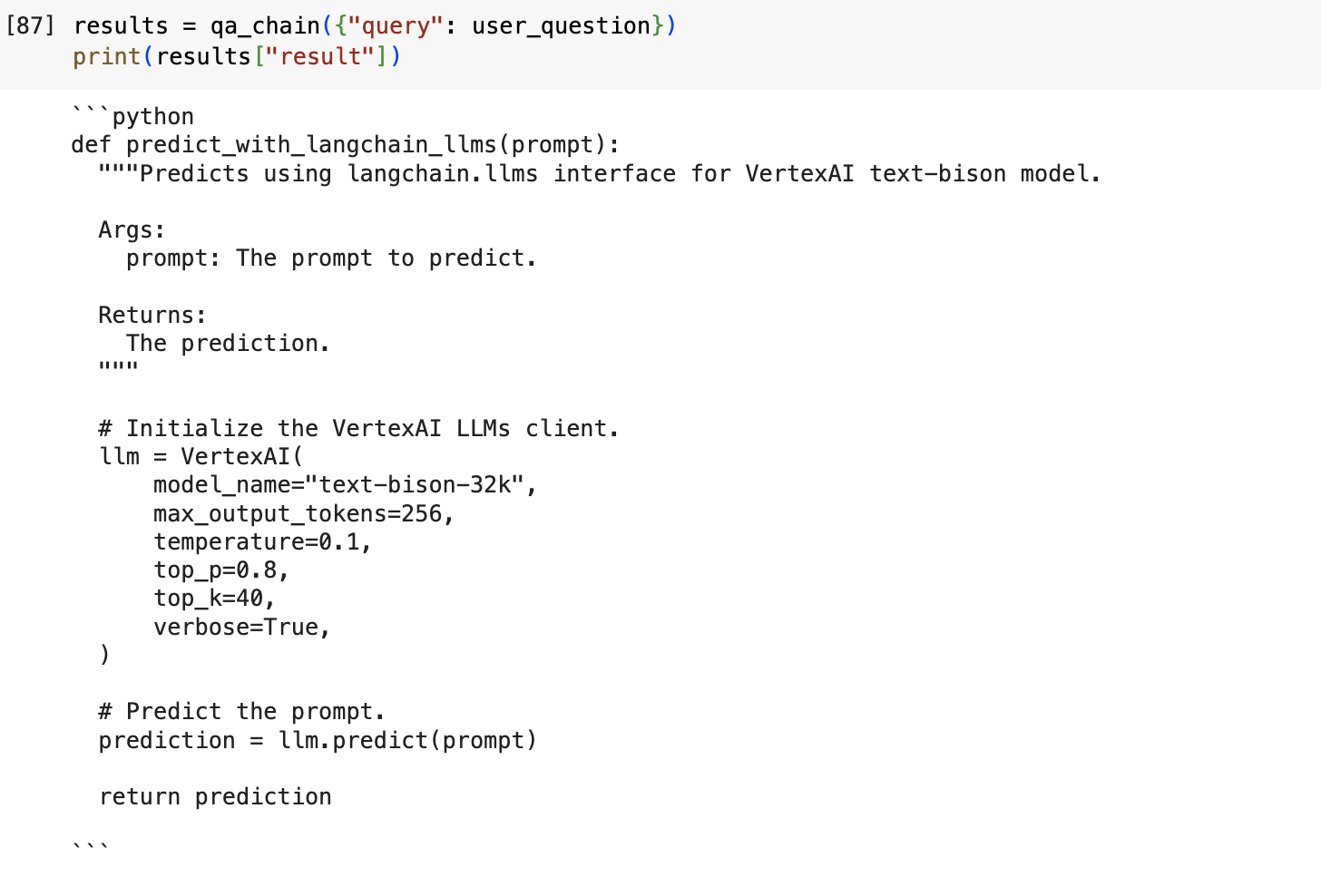
Figure 3: Output using Retrieval Augmented Generation
Using RAG, Codey was able to dynamically inject code from the Google Cloud Github repository and deliver code output that uses the correct syntax that will allow the Vertex AI text-bison model to call the Langchain API.
Common use cases and limitations of RAG
While RAG can be a helpful tool for improving the accuracy of LLM-generated code and text, it is important to note that RAG is not a perfect solution. There are still some cases where RAG can generate inaccurate or misleading results. This is because the knowledge base or other external source that RAG uses may not be accurate or up-to-date, or the LLM may not be able to correctly interpret the information from the knowledge base.
WIth that in mind, we recommend using RAG with Codey APIs when:
- A model should be able to generate code variations within a supported language. For example, using RAG to explore different coding styles or adapting code to specific variations of SQL.
- You need transparency and citations for the sources you used to generate code.
- Your model should be able to analyze and learn from your latest codebase, ensuring code freshness.
- You want an existing code model with a deep understanding of diverse coding patterns and nuances to achieve superior code completion and targeted function generation.
Is RAG an alternative to fine-tuning?
RAG and supervised tuning are two different techniques for improving the performance of code models. They are complementary approaches with unique strengths and weaknesses and can be used together.
For instance, you could first use supervised tuning to tune a Codey model (eg. code-bison) on a specific domain or task, and then use RAG to augment the model's knowledge with information from a large database. To learn more about fine-tuning your model, follow this guidance.
Limitations of using RAG
While RAG can be a helpful tool for improving the accuracy and informativeness of LLM-generated code and text, it is important to note that RAG is not a perfect solution.
There are still some cases where RAG can generate inaccurate or misleading results. This is because the knowledge base or other external source that RAG uses may not be accurate or up-to-date, or the LLM may not be able to correctly interpret the information from the knowledge base.
Getting started
To get started with Codey, you can sign up for a free trial of Vertex AI. Once you have a Vertex AI account, you can create a Codey instance and start using the code model APIs.
If you need a vector database, Vector Search has excellent performance, price, and industry-leading features. If you aren’t using code snippets and prefer an unstructured or structured (table) document RAG Search, Vertex AI Search makes this whole process easy.



