Meet AI’s multitool: Vector embeddings
Dale Markowitz
Applied AI Engineer
Embeddings are one of the most versatile techniques in machine learning, and a critical tool every ML engineer should have in their toolbelt. It’s a shame, then, that so few of us understand what they are and what they’re good for!
The problem, perhaps, is that embeddings sound slightly abstract and esoteric:
In machine learning, an embedding is a way of representing data as points in n-dimensional space so that similar data points cluster together.
Sound boring and unimpressive? Don’t be fooled! Because once you understand this ML multitool, you’ll be able to build everything from search engines to recommendation systems to chatbots, and a whole lot more. Plus, you don’t have to be a data scientist with ML expertise to use them, nor do you need a huge labeled dataset.
Have I convinced you how neat these bad boys are? ?
Good. Let’s dive in. In this post, we’ll explore:
What embeddings are
What they’re used for
Where and how to find open-source embedding models
How to use them
What can you build with embeddings?
Before we talk about what embeddings are, let’s take quick stock of what you can build with them. Vector embeddings power:
Recommendation systems (i.e. Netflix-style if-you-like-these-movies-you’ll-like-this-one-too)
All kinds of search
Text search (like Google Search)
Image search (like Google Reverse Image Search)
Chatbots and question-answering systems
Data preprocessing (preparing data to be fed into a machine learning model)
One-shot/zero-shot learning (i.e. machine learning models that learn from almost no training data)
Fraud detection/outlier detection
Typo detection and all manners of “fuzzy matching”
Detecting when ML models go stale (drift)
So much more!
Even if you’re not trying to do something on this list, the applications of embeddings are so broad that you should probably keep reading, just in case.
What are embeddings?
Embeddings are a way of representing data–almost any kind of data, like text, images, videos, users, music, whatever–as points in space where the locations of those points in space are semantically meaningful.
The best way to intuitively understand what this means is by example, so let’s take a look at one of the most famous embeddings, Word2Vec.
Word2Vec (short for word to vector) was a technique invented by Google in 2013 for embedding words. It takes as input a word and spits out an n-dimensional coordinate (or “vector”) so that when you plot these word vectors in space, synonyms cluster. Here’s a visual:
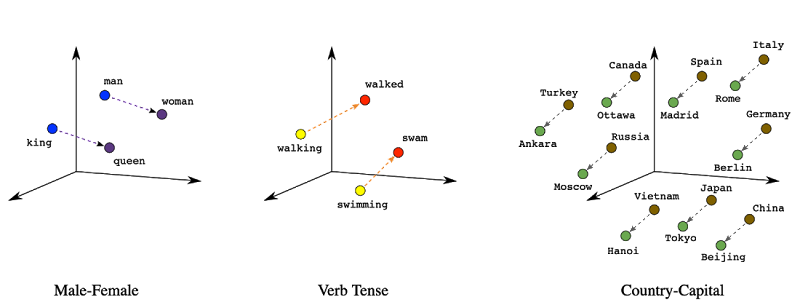
With Word2Vec, similar words cluster together in space–so the vector/point representing “king” and “queen” and “prince” will all cluster nearby. Same thing with synonyms (“walked,” “strolled,” “jogged”).
For other data types, it’s the same thing. A song embedding would plot similar-sounding songs nearby. An image embedding would plot similar-looking images nearby. A customer-embedding would plot customers with similar buying habits nearby.
You can probably already see how this is useful: embeddings allow us to find similar data points. I could build a function, for example, that takes as input a word (i.e. “king”) and finds me its ten closest synonyms. This is called a nearest neighbor search. Not terribly interesting to do with single words, but imagine instead if we embedded whole movie plots. Then we could build a function that, given the synopsis of one movie, gives us ten similar movies. Or, given one news article, recommends semantically similar articles.
Additionally, embeddings allow us to compute numerical similarity scores between embedded data points, i.e. “How similar is this news article to that one?” One way to do this is to compute the distance between two embedded points in space and say that the closer they are, the more similar they are. This measure is also known as Euclidean distance. (You could also use dot product, cosine distance, and other trigonometric measures.)
Similarity scores are useful for applications like duplicate detection and facial recognition. To implement facial recognition, for example, you might embed pictures of people’s faces, then determine that if two pictures have a high enough similarity score, they’re of the same person. Or, if you were to embed all the pictures on your cell phone camera and found photos that were very nearby in embedding space, you could conclude those points were likely near-duplicate photos.
Similarity scores can also be used for typo correction. In Word2Vec, common misspellings–”hello,” “helo,” “helllo,” “hEeeeelO”--tend to have high similarity scores because they’re all used in the same contexts.
The graphs (way) above also illustrate an additional and very neat property of Word2Vec, which is that different axes capture grammatical meaning, like gender, verb tense, and so on. This means that by adding and subtracting word vectors, we can solve analogies, like “man is to woman as king is to ____.” It’s quite a neat feature of word vectors, though this trait doesn’t always translate in a useful way to embeddings of more complex data types, like images and longer chunks of text. (More on that in a second.)
What kinds of things can be embedded?
So many kinds of things!
Text
Individual words, as in the case of Word2Vec, but also entire sentences and chunks of text. One of open source’s most popular embedding models is called the Universal Sentence Encoder (USE). The name is a bit misleading, because USE can be used to encode not only sentences but also entire text chunks. Here’s a visual from the TensorFlow website. The heat map shows how similar different sentences are according to their distance in embedding space.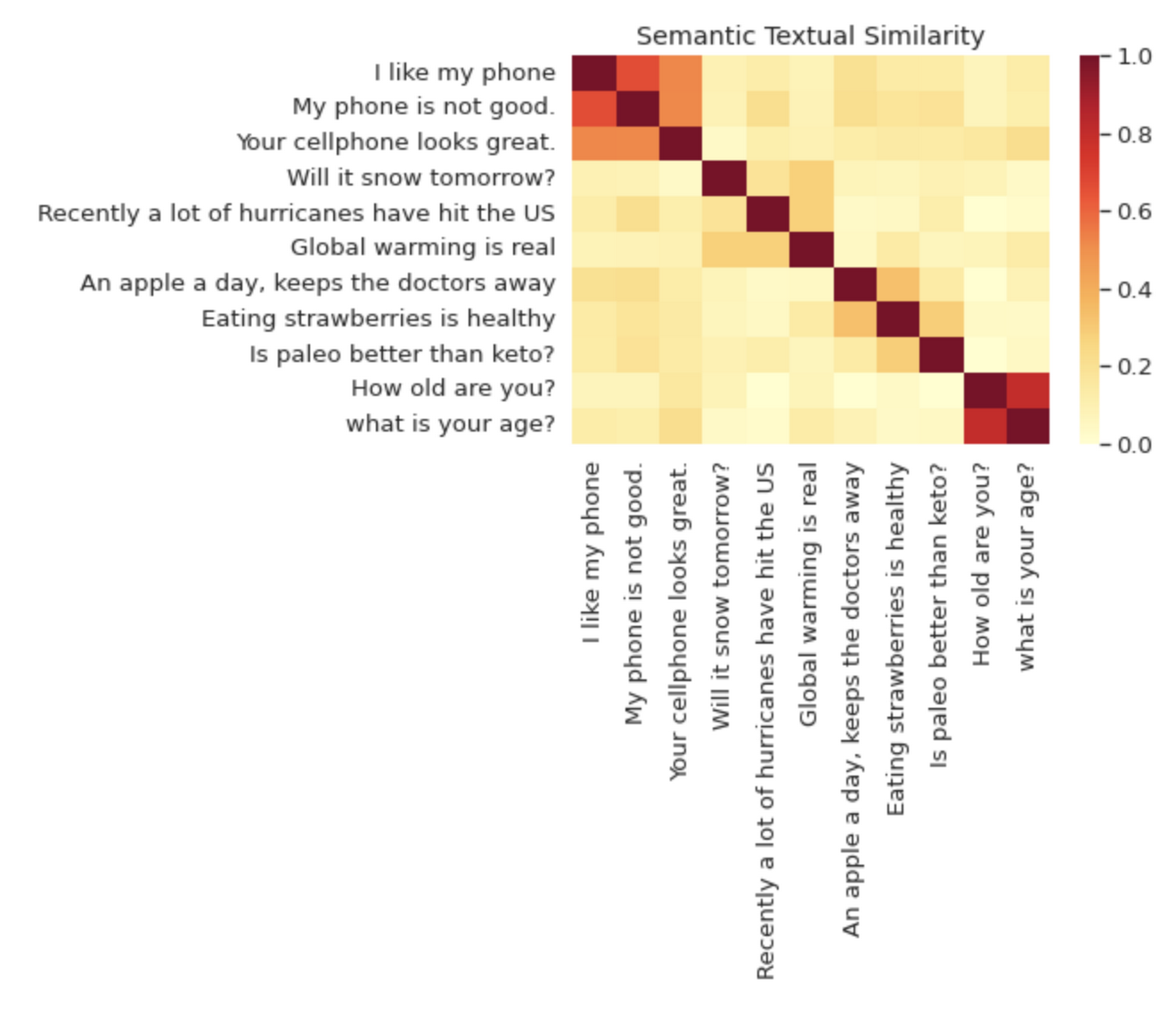
My News Article Database |
Boosters 90% Effective in Averting Hospitalization, C.D.C. Data Show |
Now suppose I search this database with the text query “food.” The most relevant result in the database is the article about the burrito, even though the word “food” doesn’t appear in the article headline. If we searched by the USE embeddings of the headlines rather than by the raw text itself, we’d be able to capture that–because USE captures semantic similarity of text rather than overlap of specific words.
It’s worth noting here that since we can associate many data types with text–captions for images, transcripts for movies–we can also adapt this technique to use text search for multimedia. As an example, check out this searchable video archive.
Images
Images can also be embedded, which enables us to do reverse-image search, i.e. “search by image.” One example is vision product search, which also happens to be a Google Cloud product by the same name.
Imagine, for example, that you’re a clothing store and you want to build out a search feature. You might want to support text queries like “leather goth studded mini skirt.” Using something like a USE embedding, you might be able to match that text user query with a product description. But wouldn’t it be neat if you could let users search by image instead of just text? So that shoppers could upload, say, a trending top from Instagram and see it matched against similar products in your inventory? (That’s exactly what this tutorial shows you how to build.)
One of my favorite products that uses image search is Google Lens. It matches camera photos with visually similar products. Here, it tries to match online products that look similar to my pair of sneakers:

As with sentence embeddings, there are lots of free-to-use image embedding models available. This TensorFlow Hub page provides a bunch, under the label “feature vector.” These embeddings were extracted from large deep learning models that were initially trained to do image classification on large datasets. To see a demo of image search powered by MobileNet embeddings, check out this demo that lets you upload a photo and searches all of Wikimedia to find similar images.
Unfortunately, unlike sentence embeddings, open-source image embeddings often need to be tuned for a particular task to be high-quality. For example, if you wanted to build a similarity search for clothing, you’d likely want a clothing dataset to train your embeddings on. (More on how to train embeddings in a bit.)
Products and Shoppers
Embeddings are especially useful in the retail space when it comes to making product recommendations. How does Spotify know which songs to recommend listeners based on their listening histories? How does Netflix decide which movies to suggest? How does Amazon know what products to recommend shoppers based on purchase histories?
Nowadays, the cutting-edge way to build recommendation systems is with embeddings. Using purchase/listening/watching history data, retailers train models that embed users and items.
What does that mean?
Imagine, for example, that I’m a frequent shopper at an imaginary, high-tech book-selling site called BookShop. Using purchase history data, BookShop trained two embedding models:
The first, its user embedding model, maps me, a book-buyer, to user space based on my purchase history. I.e. because I buy a lot of O’Reilly tech guides, pop science books, and fantasy books, this model maps me close to other nerds in user space.
Meanwhile, BookSpace also maintains an item embedding model that maps books to item space. In item space, we'd expect books of similar genres and topics to cluster together. So, we'd find the vector representing Philip K. Dick's Do Androids Dream of Electric Sheep nearby to the vector representing William Gibson's Neuromancer, since these books are topically/stylistically similar.
How are embeddings created?
To recap, so far we’ve talked about:
What types of apps embeddings power
What embeddings are (a mapping of data to points in space)
Some of the data types that can actually be embedded
What we haven’t yet covered is where embeddings come from, or, more specifically: how to build a machine learning model that takes in data and spits out semantically meaningful embeddings based on your use case.
Here, as in most of machine learning, we have two options: the pre-trained model route and the DIY, train-your-own model route.
Pre-Trained Models
If you’d like to embed text–i.e. to do text search or similarity search on text–you’re in luck. There are tons and tons of pre-trained text embeddings free and easily available for your using. One of the most popular models is the Universal Sentence Encoder model I mentioned above, which you can download here from the TensorFlow Hub model repository. Using this model in code is pretty straightforward. This sample is snatched directly from the TensorFlow website:
Personally, I think it’s absolutely mind-blowing that you can accomplish something as sophisticated as sentence embeddings in so few lines of Python code.
To actually get use out of these text embeddings, we'll need to implement nearest neighbor search and calculate similarity. For that, let me point you to this blog post I wrote recently on this very topic--building text/semantically intelligent apps using sentence embeddings.
Open-source image embeddings are easy to come by too. Here’s where you can find them on TensorFlow Hub. Again, to be useful for domain-specific tasks, it’s often useful to fine-tune these types of embeddings on domain-specific data (i.e. pictures of clothing items, dog breeds, etc.)
Finally, I'd be remiss not to mention one of the most hype-inducing embedding models released as of late: OpenAI's CLIP model. CLIP can take an image or text as input and map both data types to the same embedding space. This allows you to build software that can do things like: figure out which caption (text) is most fitting for an image.
Training Your Own Embeddings
Beyond generic text and image embeddings, we often need to train embedding models ourselves on our own data. Nowadays, one of the most popular ways to do this is with what’s called a Two-Tower Model. From the Google Cloud website:
The Two-Tower model trains embeddings by using labeled data. The Two-Tower model pairs similar types of objects, such as user profiles, search queries, web documents, answer passages, or images, in the same vector space, so that related items are close to each other. The Two-Tower model consists of two encoder towers: the query tower and the candidate tower. These towers embed independent items into a shared embedding space, which lets Matching Engine retrieve similarly matched items.
I’m not going to go into detail about how to train a two-tower model in this post. For that, I’ll direct you to this guide on Training Your Own Two-Tower Model on Google Cloud, or this page on Tensorflow Recommenders, which shows you how to train your own TensorFlow Two-Tower/recommendation models.Special thanks to Kaz Sato for his early feedback!




