How L’Oréal's tech accelerator built its end-to-end MLOps platform

Moutia Khatiri
Tech Accelerators CTO, L’Oréal
Dr. Wafae Bakkali
Staff Generative AI Specialist, Blackbelt, Google
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try nowTechnology has transformed our lives and social interactions at an unprecedented speed and scale, creating new opportunities. To adapt to this reality, L'Oréal has established itself as a leader in Beauty Tech, promoting personalized, inclusive, and responsible beauty accessible to all, under the banner "Beauty for Each, powered by Beauty Tech."
This convergence of Beauty Tech is evident in augmented beauty products, smart devices, enhanced marketing, online and offline services, and digital platforms, all powered by information and communication technologies, data, and artificial intelligence. L'Oréal is committed to developing innovative solutions that elevate the beauty experience and contribute to a future where beauty is accessible, sustainable, and caters to the diverse needs and aspirations of individuals worldwide.
L'Oréal, the world’s largest cosmetics company, has for years leveraged AI to enhance digital solutions for its employees and provide personalized experiences for customers. In this blog, we will describe how L'Oréal’s Tech Accelerator built a scalable and end-to-end MLOps platform using Google Cloud. This platform accelerates the deployment of AI models, enabling the team to rapidly innovate.
Our MLOps vision and requirements
To accelerate AI initiatives and optimize product development, L'Oréal Tech Accelerator sought to build a reusable, secure, and user-friendly Machine Learning Operations (MLOps) platform on Google Cloud. This platform aims to:
-
Streamline workflows and enhance collaboration, reducing friction between teams and accelerating time to market.
-
Ensure security and best practices that promote consistent, well-documented processes to minimize errors.
-
Enable rapid adoption through an intuitive platform that requires minimal training.
This approach fosters a more cohesive and efficient development environment, ultimately leading to higher quality products and greater agility in responding to evolving business needs.
Overview of L'Oréal’s MLOps platform
To understand the Tech Accelerator’s MLOps platform, let's break down its key components. Here's a simplified view of the process:
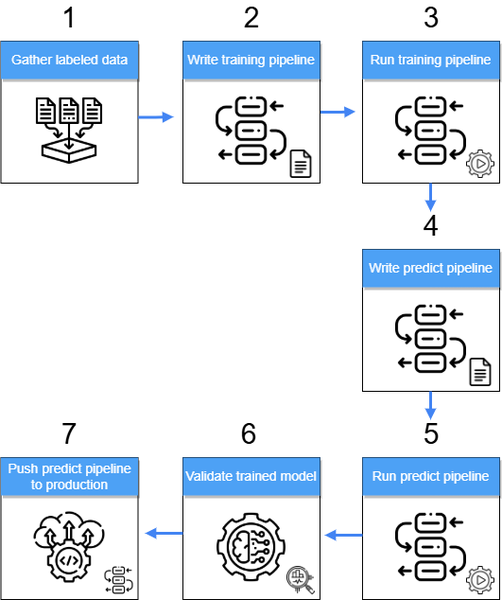
- Labeled data preparation: Labeled data is gathered from various sources, including BigQuery, Google Cloud Storage, on-premise systems, and data lakes. It’s then processed and stored in a centralized location (such as BigQuery or Google Cloud Storage) to prepare it for training ML models
- Training pipeline development: The team uses the Kubeflow SDK to define the flow and logic for the training pipeline. This pipeline automates the process of training the ML model.
- Run training pipeline: The training pipeline is executed, generating a trained model artifact. This artifact is stored as a pickle file embedded in a Python library for easy access and deployment.
- Prediction pipeline development: Using the Kubeflow SDK again, the team creates a prediction pipeline that utilizes the trained model to generate inferences on new data.
- Run predict pipeline: The prediction pipeline is executed, generating inferences that are stored in BigQuery, Google Cloud Storage, or a data lake.
- Validate trained model: The inference results from the prediction pipeline are used to evaluate the performance of the trained model. This involves calculating key accuracy metrics like F1-score and precision.
- Push prediction pipeline to production: Up to this point, all pipeline components have been developed, tested, and validated manually by data scientists or ML engineers, and a new model version (or versions) has been created. The next step is to push the new version of the prediction pipeline, incorporating the new model version, to production. This deployment leverages development best practices, such as CI/CD pipelines.
The MLOps platform leverages DevOps principles to ensure a robust and efficient development lifecycle. This involves separating the ML development process into four distinct environments (i.e. Google Cloud projects):
-
DataOps: This environment provides a centralized repository for storing and managing all data assets, including labelled training data, model artifacts, and pipeline components. This ensures data consistency and accessibility throughout the ML workflow. Additionally, in this environment, the training pipeline is run to create the new version of the models.
-
Development: A dedicated space for testing new versions of prediction pipelines orchestrating multiple models. This environment allows for evaluating computation speeds, data coherence, end-to-end integration, and other performance aspects.
-
Staging: This environment mirrors the production setup, enabling rigorous testing and validation of the business expectations and requirements. By using staging data that closely resembles real-world data, potential business issues of prediction pipelines can be identified and addressed early on.
-
Production: The live environment where validated prediction pipelines and new versions of the models are deployed to generate real-time/batch predictions for L'Oréal's Tech Accelerator applications and services, delivering value to end-users.
This structured approach, with its clear separation of environments, promotes efficient collaboration, minimizes risks, and ensures a smooth transition from development to production, ultimately enabling L'Oréal's Tech Accelerator to deliver high-quality AI-powered beauty experiences. Note that, to further optimize efficiency and reduce costs, the training pipeline is executed only once within the DataOps environment. The resulting trained model is then deployed across the other environments. This eliminates the need to retrain the model in each environment, resulting in a significant cost reduction (up to 3x).
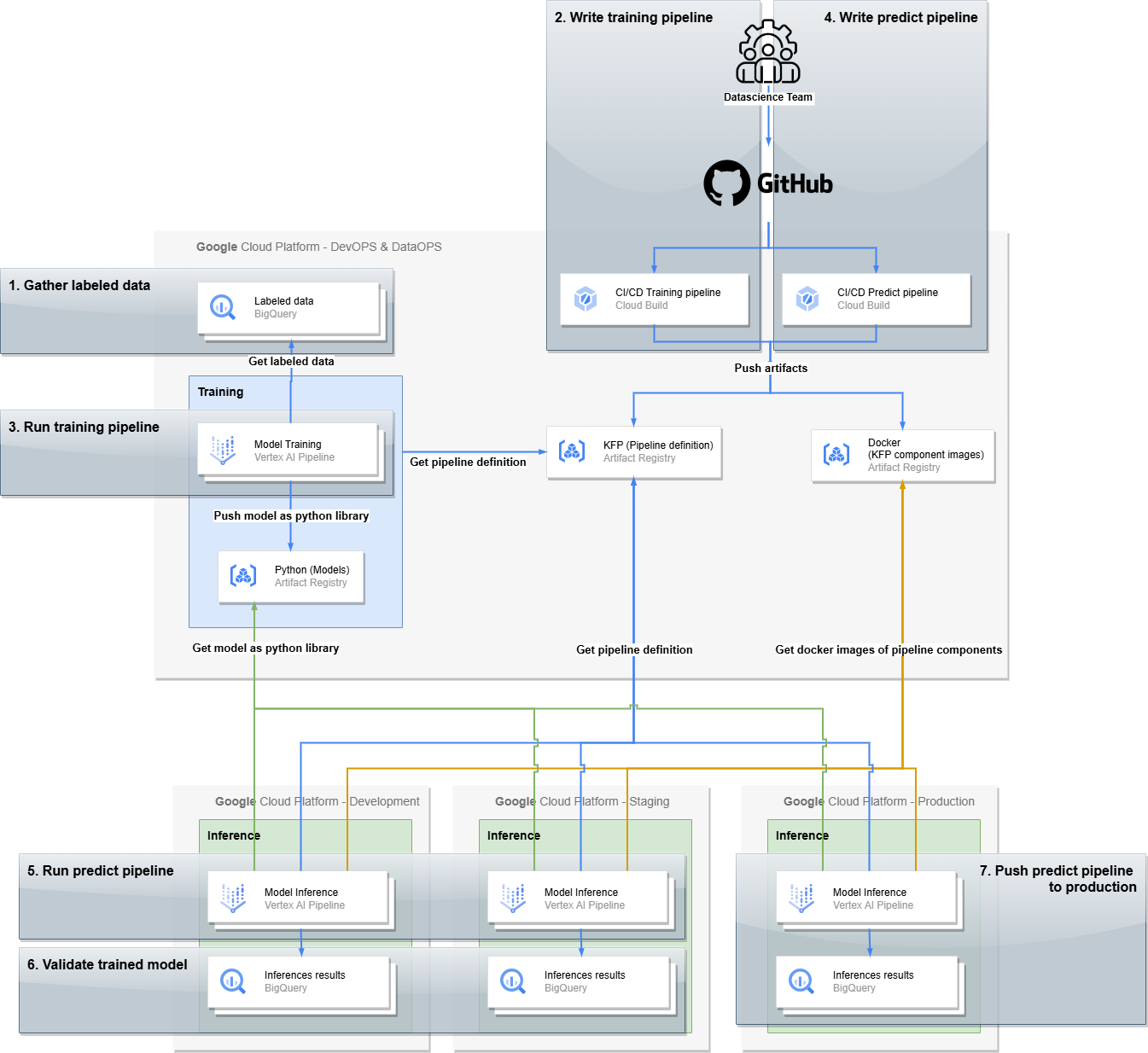
The figure above illustrates the relationship among the multiple environments and the required infrastructure. Notable points:
-
Model training pipelines output Python packages that embed the trained models.
-
The CI/CD pipeline outputs Kubeflow Pipelines (KFP) pipeline definitions and Docker images related to their components.
-
There are two distinct operational blocks: "Training" for creating new models and "Inference" for generating predictions.
Diving Deeper: Key Components of the MLOps Platform
At the core of the platform's operation is KFP. To understand its role, let's define what Vertex pipelines are:
“A pipeline is a definition of a workflow that composes one or more components together to form a computational directed acyclic graph (DAG). At runtime, each component execution corresponds to a single container execution, which may create ML artifacts. Pipelines may also feature control flow.”
— Kubeflow Documentation
In this section, we'll focus on how L'Oréal Tech Accelerator builds and manages the two main operational building blocks: "Training" and "Inference."
Training pipeline
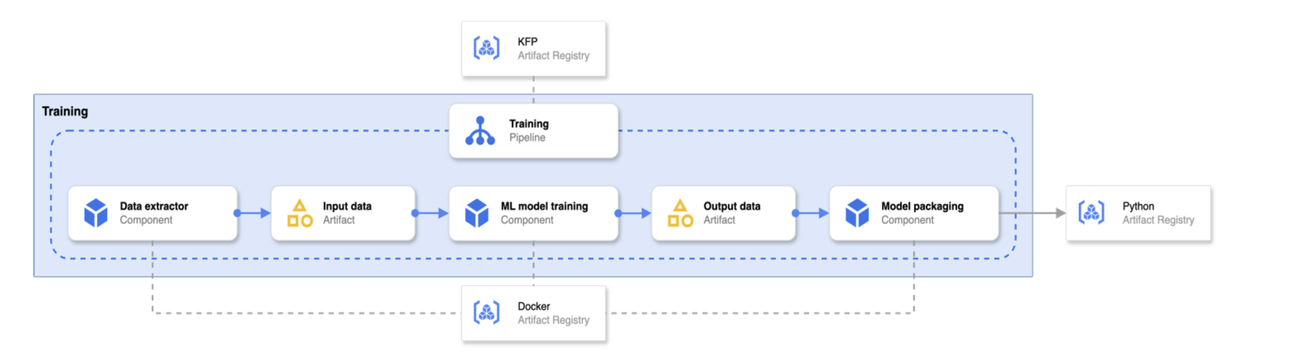
The training pipeline architecture is designed for efficiency and reproducibility. Here's how it works:
-
Pipeline Definition and Components: The pipeline's definition is fetched from a KFP artifact registry, while the container images that execute individual pipeline steps are retrieved from a Docker artifact registry. These artifacts are created and managed by a CI/CD pipeline, ensuring version control and consistency (as described in the “MLOps platform overview” section).
-
Model Training and Packaging: Once a new training pipeline run completes, the newly trained model is packaged into a Python library for easy deployment and integration.
-
Model Registry: This packaged model is then pushed to a Python artifact registry, creating a centralized repository of trained models. This allows for easy versioning, sharing, and deployment of models across different environments.
Inference pipeline
The inference pipeline follows a similar architecture to the training pipeline, ensuring consistency and efficiency in model deployment. Here's how it works:
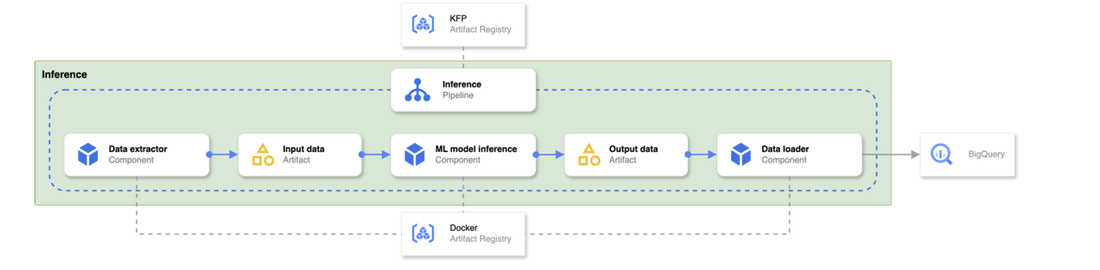
-
Pipeline Definition and Components: The inference pipeline's definition, defined using KFP, is retrieved from an artifact registry. Similarly, the Docker images containing the necessary components for the pipeline are fetched from another artifact registry.
-
CI/CD Integration: These pipeline definitions and Docker images are created and deployed by the CI/CD pipeline, ensuring that the inference pipeline is always up-to-date and uses the latest validated components.
The modularity and dependency challenge
Traditional ML pipelines often rely on a single, shared codebase for their definition. This can lead to challenges when multiple teams need to collaborate and contribute to the pipeline's development. Having all these teams work on the same codebase can create friction and slow down the development process due to:
-
Merge conflicts: When multiple teams edit the same files simultaneously.
-
Integration challenges: Ensuring the different components developed by separate teams work together seamlessly.
-
Version control complexities: Managing different versions and updates of the pipeline.
-
Deployment bottlenecks: Coordinating deployments when different teams need to make changes.
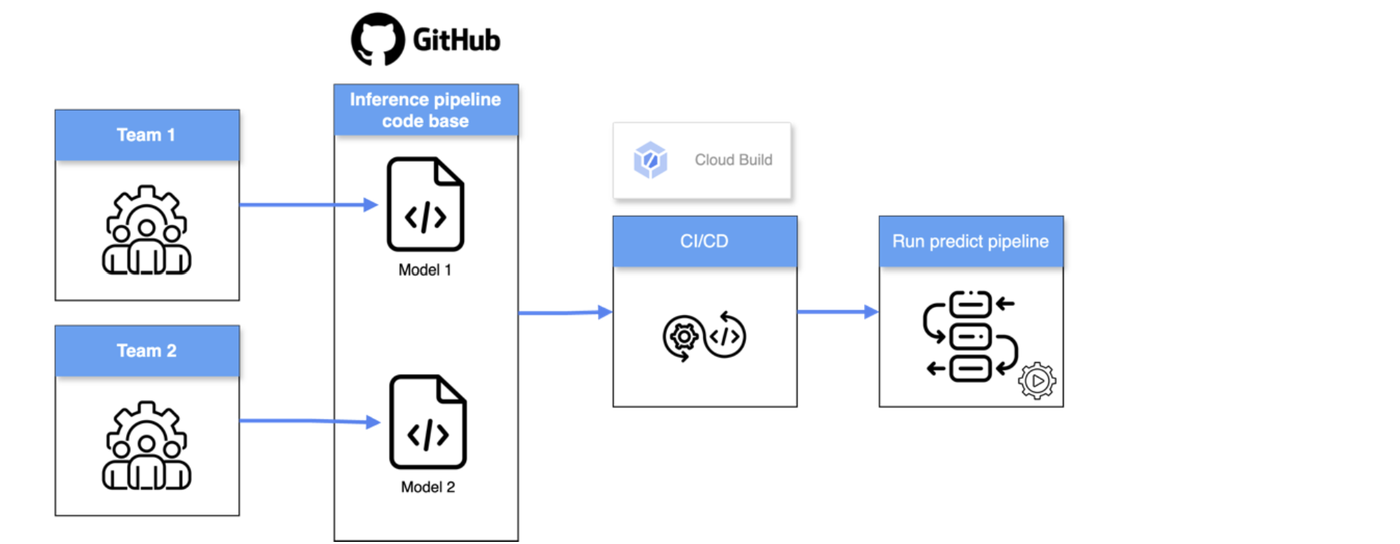
For example (see figure above), if two teams are working on separate models (Model 1 and Model 2) within the same codebase, and one model's pipeline fails, it can prevent the other model's inference pipeline from running. This creates a single point of failure that can disrupt the entire system.
To address this, a more modular and independent approach to pipeline development is needed, where individual teams can work on their components without affecting others.
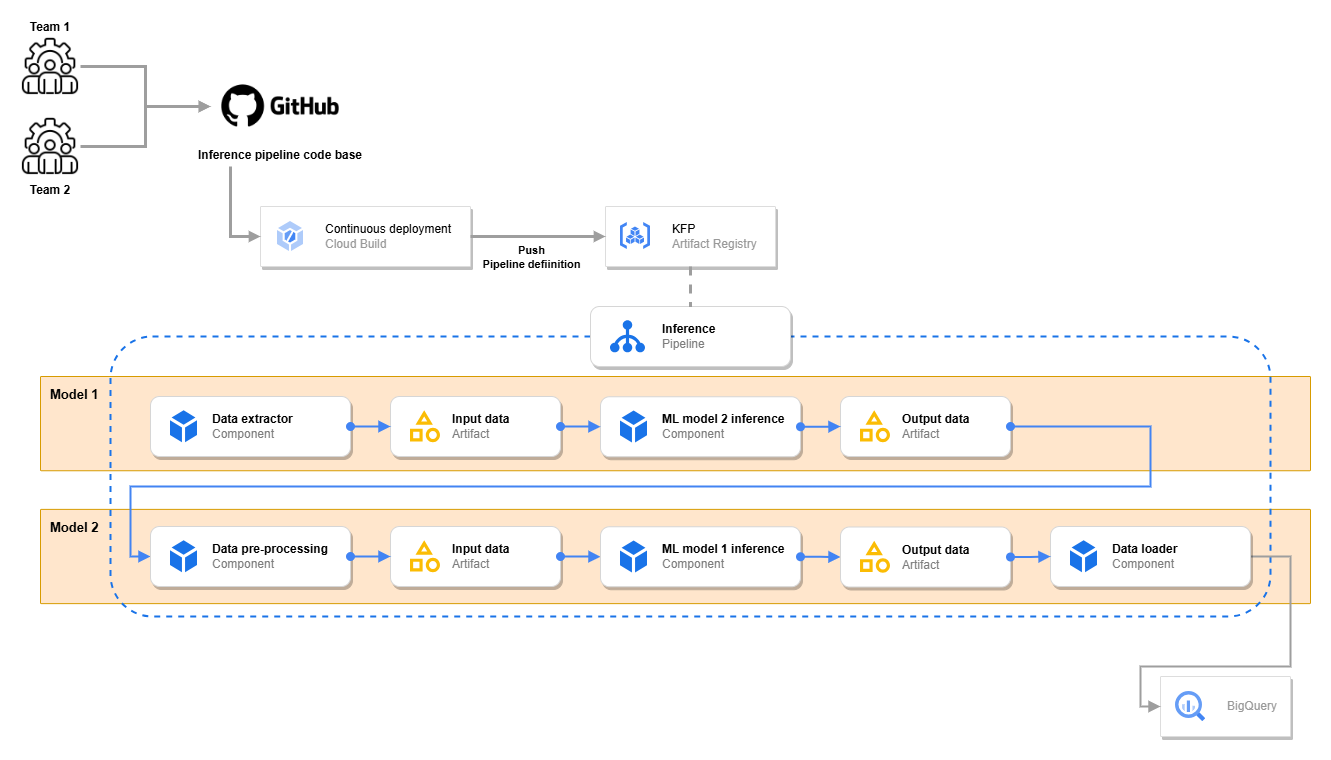
The figure above illustrates the ML pipeline definition and infrastructure for the example and issue explained previously
How we solved it
L’Oréal Tech Accelerator solution uses KFP artifact registry to enable a modular approach to pipeline development. This allows the creation of independent sub-pipelines, each with its own codebase and CI/CD pipeline. This separation offers significant benefits:
-
Independent Development: Teams can work autonomously on their sub-pipelines without interfering with each other’s progress or deployments. This reduces friction and accelerates development cycles.
-
Isolated Testing and Versioning: Each sub-pipeline can be tested and versioned independently, ensuring that changes in one component don’t inadvertently affect others.
-
Increased Agility: This modularity enables teams to quickly adapt and update their sub-pipelines without impacting the overall system.
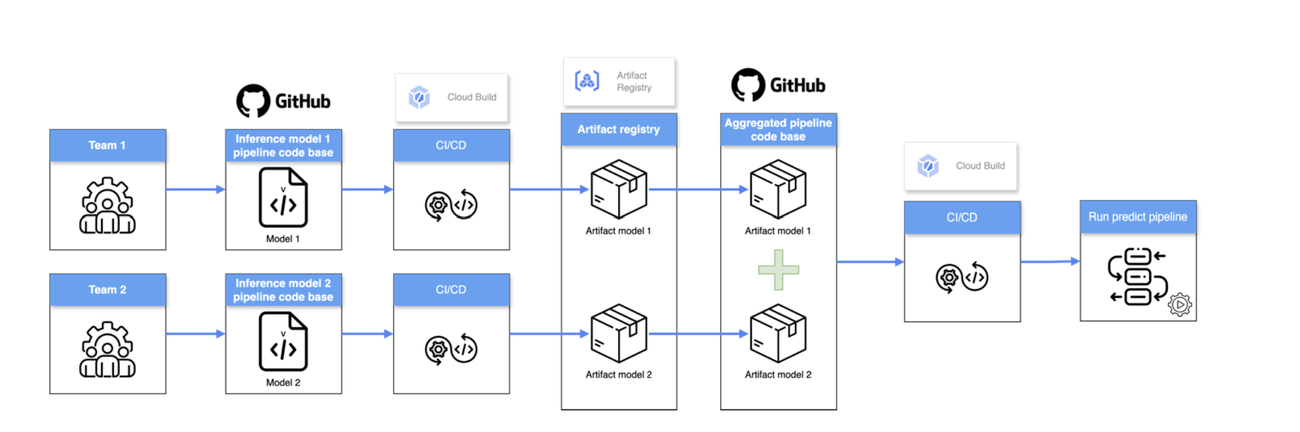
Furthermore, L'Oréal's Tech Accelerator introduces an additional codebase that acts as an orchestrator. This orchestrator assembles the individual sub-pipelines into a cohesive workflow, using the output artifacts of each sub-pipeline as building blocks. This approach combines the benefits of independent development with the power of a unified pipeline.
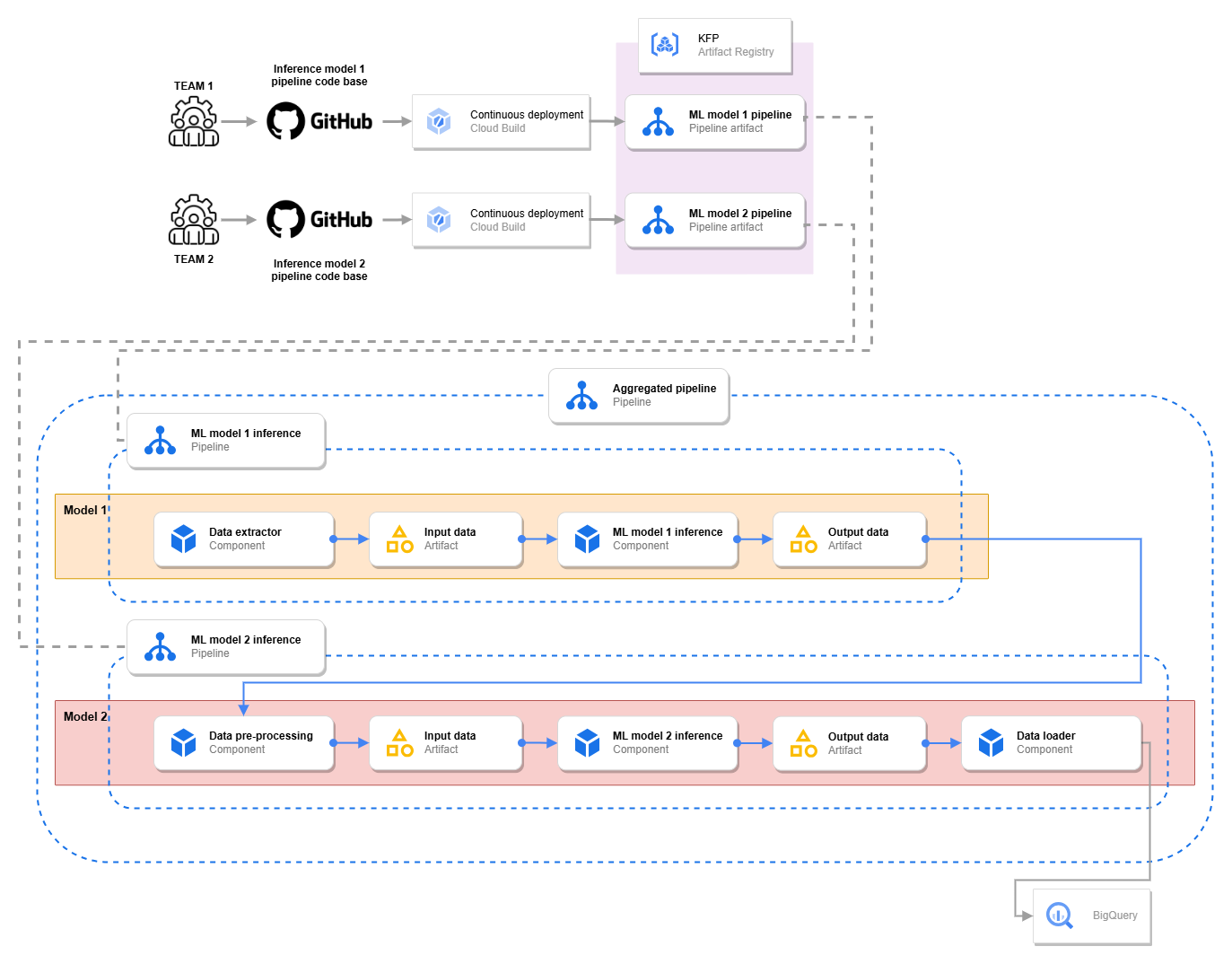
The figure above illustrates the ML pipeline definition and infrastructure of the solution
Example: Code snippet of an aggregated pipeline
The following code snippet demonstrates the simplicity of using an aggregation module to combine multiple prediction pipelines and models from different teams. This orchestration layer allows for seamless integration of individual components into a unified workflow.
Conclusion & Next steps
L'Oréal's modular MLOps platform, built on Google Cloud, has significantly boosted efficiency and agility in the AI development process. By empowering teams to work independently on their respective ML models, L'Oréal's Tech Accelerator has accelerated development, improved collaboration, and enhanced the quality and reliability of its systems.
While the current platform offers significant advantages, the team continues to optimize it.
One focus area is addressing the challenges of large model artifacts, which can increase Docker image sizes and slow down pipelines. L'Oréal's Tech Accelerator is exploring solutions like on-demand model downloading and API-driven inference to mitigate this and remain at the forefront of Beauty Tech innovation.
The authors would like to thank and acknowledge the following contributors to this blog: Kerebel Paul-Sirawit, DevOps & Cloud Lead, L’Oréal, Dr. Sokratis Kartakis, Generative AI Blackbelt, Google, Christophe Dubos, Principal Architect, Google.
Opening image credits: Ben Hassett / Myrtille Revemont / Helena Rubinstein pour L’Oréal



