Powering cost-efficient AI inference at scale with Cloud TPU v5e on GKE
David Porter
Senior Software Engineer
Vivian Wu
Software Engineer
Google Cloud TPU v5e is a purpose-built AI accelerator that brings the cost-efficiency and performance required for large-scale model training and inference. With Cloud TPUs on Google Kubernetes Engine (GKE), the leading Kubernetes service in the industry, customers can orchestrate AI workloads efficiently and cost effectively with best-in-class training and inference capabilities. GKE has long been a leader in supporting GPUs for AI workloads and we are excited to expand our support to include TPU v5e for large-scale inference capabilities.
MLPerf™ 3.1 results
As we announced in September, Google Cloud submitted results for the MLPerf™ Inference 3.1 benchmark and achieved 2.7x higher performance per dollar compared to TPU v4.
Our MLPerf™ Inference 3.1 submission results demonstrated running the 6-billion parameter GPT-J LLM benchmark using Saxml, a high-performance inference system, and XLA, Google’s AI compiler. Some of the key optimizations used include:
- XLA optimizations and fusions of Transformer operators
- Post-training weight quantization with INT8 precision
- High-performance sharding across the 2x2 TPU node pool topology using GSPMD
- Bucketized execution of batches of prefix computation and decoding in Saxml
- Dynamic batching in Saxml
We achieved the same performance when running Cloud TPU v5e on GKE clusters, demonstrating that Cloud TPUs on GKE allow you to gain the scalability, orchestration, and operational benefits of GKE while maintaining the price-performance of TPU.
Maximizing cost-efficiency with GKE and TPUs
When building a production-ready, highly-scalable, and fault-tolerant managed application, GKE brings additional value by reducing your total cost of ownership (TCO) for inference on TPUs:
- Manage and deploy your AI workloads with a Kubernetes standard platform.
- Minimize cost with autoscaling to ensure that resources automatically adjust to workload needs. GKE can automatically scale up and down TPU node pools based on traffic using the autoscaling, increasing cost efficiency and improved automation for inference.
- Provision the necessary compute resources needed for your workloads: TPU node pools can be automatically provisioned based on TPU workload requirements with GKE’s node auto provisioning capabilities.
- Ensure high availability of your applications with built in health monitoring for TPU VM node pools on GKE. If TPU nodes become unavailable, GKE will perform node auto repair to avoid disruptions.
- Minimize disruption from updates and hardware failures with GKE’s proactive handling of maintenance events and gracefully terminating workloads.
- Gain full visibility into your TPU applications with GKE's mature and reliable metrics and logging capabilities
GKE TPU Inference Reference Architecture
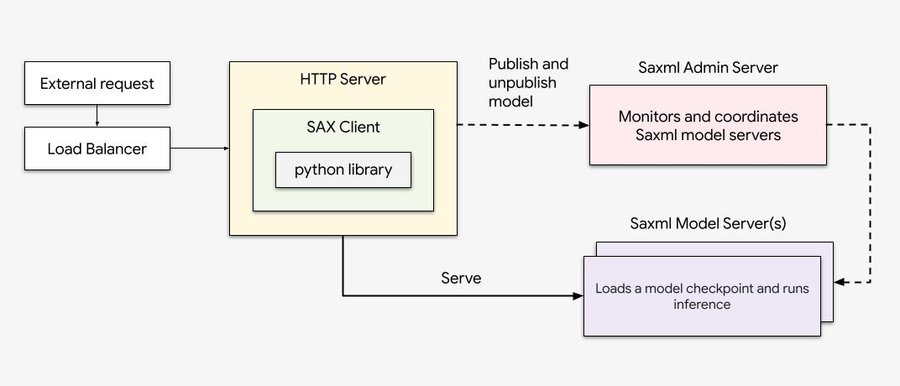
To take advantage of all of the above benefits, we created a proof of concept to demonstrate TPU inference using the GPT-J 6B LLM model with a single-host Saxml model server.
Below: Saxml Workflow
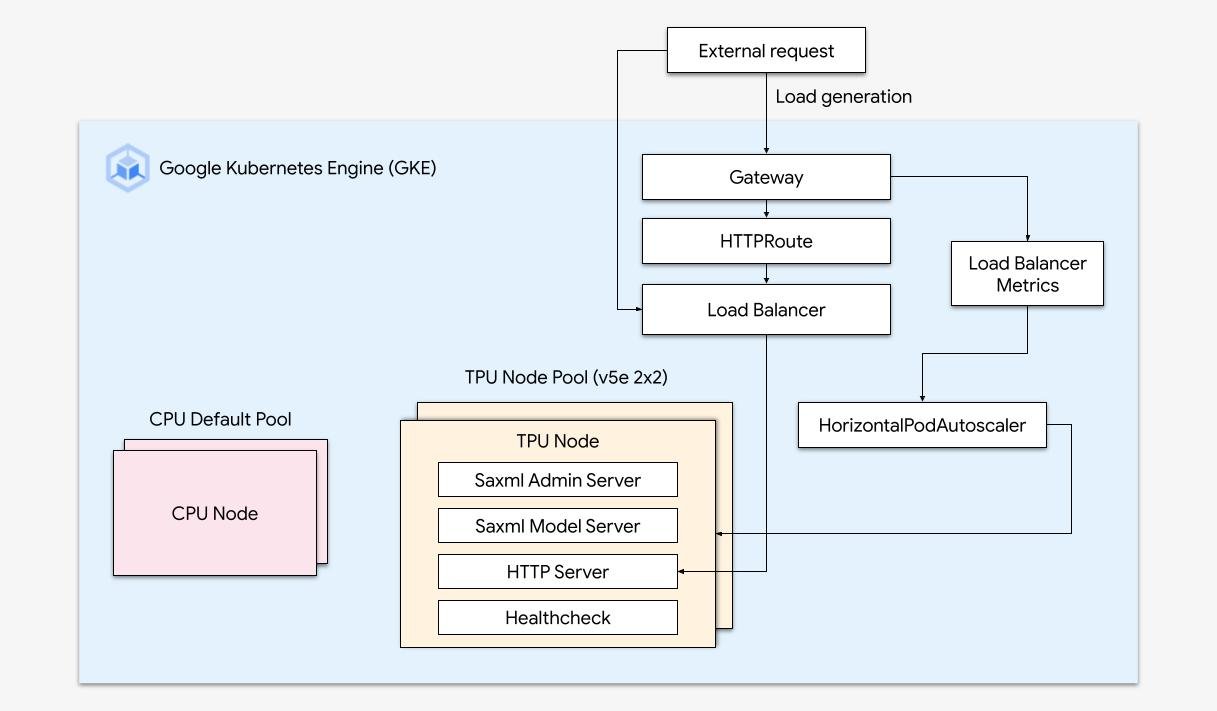
We created a GKE cluster with the following architecture:
- We created a GKE cluster with a TPU v5e (2x2) node pool
- We enabled the Gateway API which provides the ability to expose different HTTP endpoints and provide health checks.
- We developed a simple HTTP server as frontend to Saxml. This server proxied requests from end users to Saxml.
- We developed a Kubernetes deployment that served two containers, the Saxml deployment as well the HTTP server. This ensured that the HTTP server ran as a sidecar and scaled proportionally with Saxml.
- We configured the necessary Gateway API configuration including HTTP route, healthcheck, and a backing k8s load balancer based service for the Deployment.
- Lastly, we added a HorizontalPodAutoscaler which can dynamically scale the number of replicas of the Deployment based on traffic to the load balancer.
This reference architecture demonstrates how to achieve optimal price-performance for large-scale AI inference when operationalizing TPU v5e through the use of GKE. Refer to the below demo to see the cluster in action!
Demo

Refer to our Github for more examples and details around the reference architecture described!
Try it out and if you have any questions about Saxml on GKE, you can leave us a comment. We look forward to your feedback!
Learn more about AI/ML Workloads on GKE.

