Introducing ML Productivity Goodput: a metric to measure AI system efficiency

Vaibhav Singh
Group Product Manager
Daniel Herrington
Product Manager
We live in one of the most exciting eras of computing. Large-scale generative models have expanded from the realms of research exploration to the fundamental ways we interact with technology, touching education, creativity, software design, and much more. The performance and capabilities of these foundation models continues to improve with the availability of ever-larger computation, typically measured in the number of floating-point operations required to train a model.
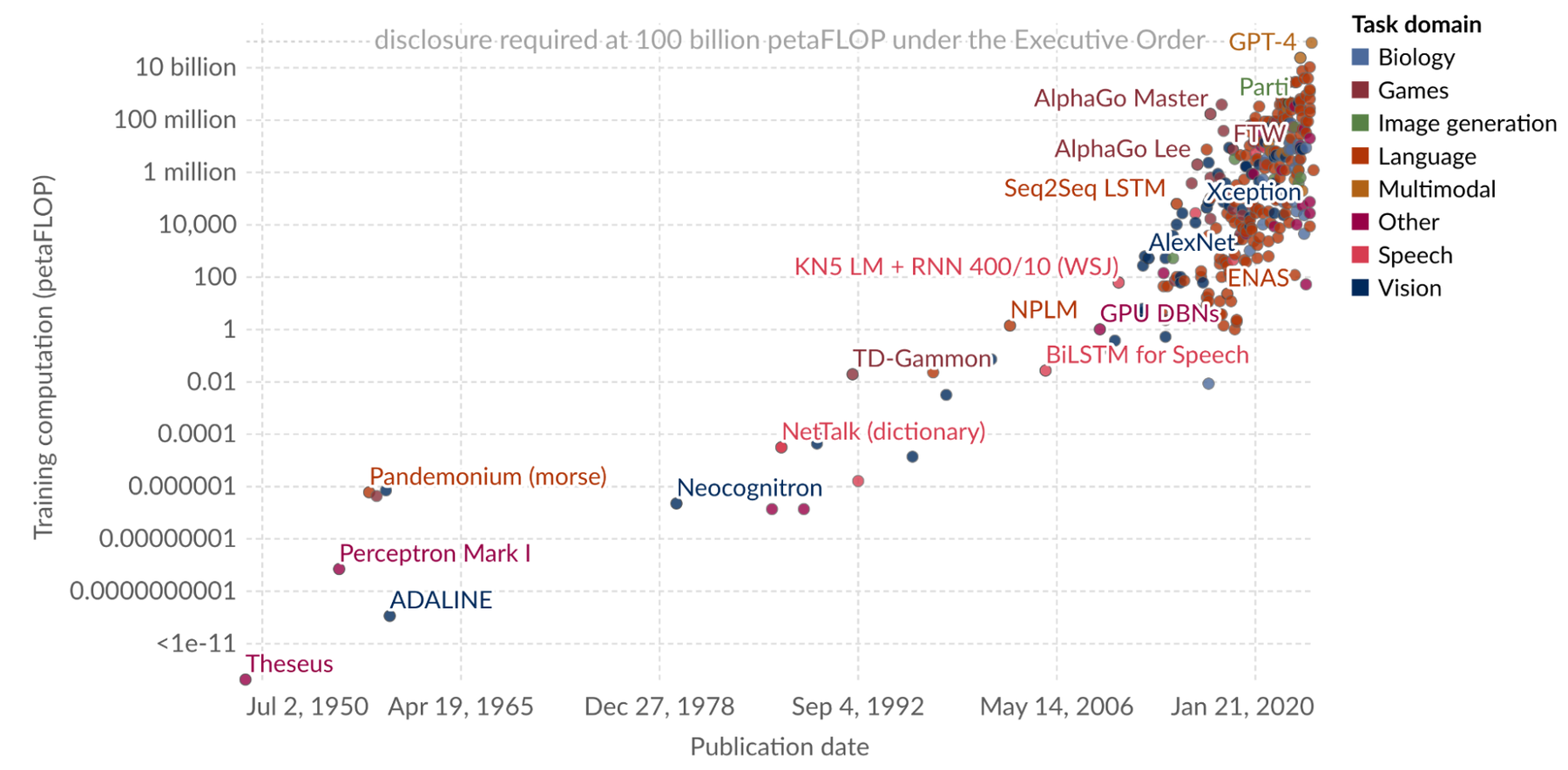
The exponential growth of computation scale for the notable models. Source: Our world in data
This rapid rise in compute scale is made feasible by larger and more efficient compute clusters. However, as the scale of a compute cluster (measured in the numbers of nodes or number of accelerators) increases, mean time between failures (MTBF) of the overall system reduces linearly, leading to a linear increase in the failure rate. Furthermore, the cost of infrastructure also increases linearly; therefore, the overall cost of failure rises quadratically with the scale of the compute cluster.
For large-scale training, the true efficiency of the overall ML system is core to its viability — if left unattended, it can make attaining a certain scale infeasible. But if engineered correctly, it can help you unlock new possibilities at a larger scale. In this blog post, we introduce a new metric, ML Productivity Goodput, to measure this efficiency. We also present an API that you can integrate into your projects to measure and monitor Goodput, and methods to maximize ML Productivity Goodput.
Introducing ML Productivity Goodput
ML Productivity Goodput is actually composed of three Goodput metrics: Scheduling Goodput, Runtime Goodput, and Program Goodput.
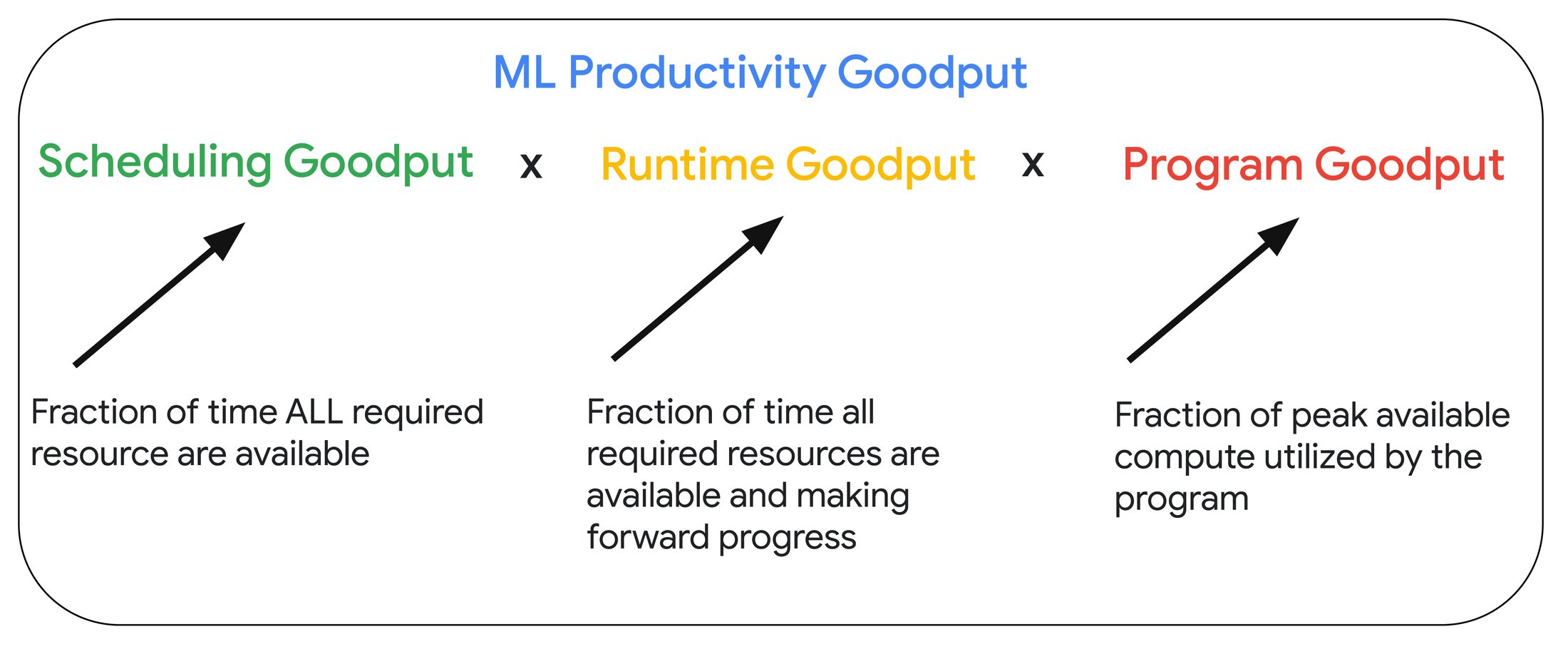
Scheduling Goodput measures the fraction of time that all the resources required to run the training job are available. In on-demand or preemptible consumption models, this factor is less than 100% because of potential stockouts. As such, we recommend you reserve your resources to optimize your Scheduling Goodput score.
Runtime Goodput measures the time spent to make forward progress as a fraction of time when all training resources are available. Maximizing runtime requires careful engineering considerations. In the next section we describe how you can measure and maximize runtime for your large-scale training jobs on Google Cloud.
Program Goodput measures the fraction of peak hardware performance that the training job can extract. Program Goodput is also referred to as Model Flop Utilization or effective model flop utilization, i.e., the model training throughput as a fraction of peak throughput of the system. Program Goodput depends on factors such as efficient compute communication overlaps and careful distribution strategies to scale efficiently to the desired number of accelerators.
Google’s AI Hypercomputer
AI Hypercomputer is a supercomputing architecture that incorporates a carefully selected set of functions built through systems-level codesign to boost ML productivity across AI training, tuning, and serving applications. The following diagram illustrates how different elements of ML Productivity Goodput are encoded into AI Hypercomputer:
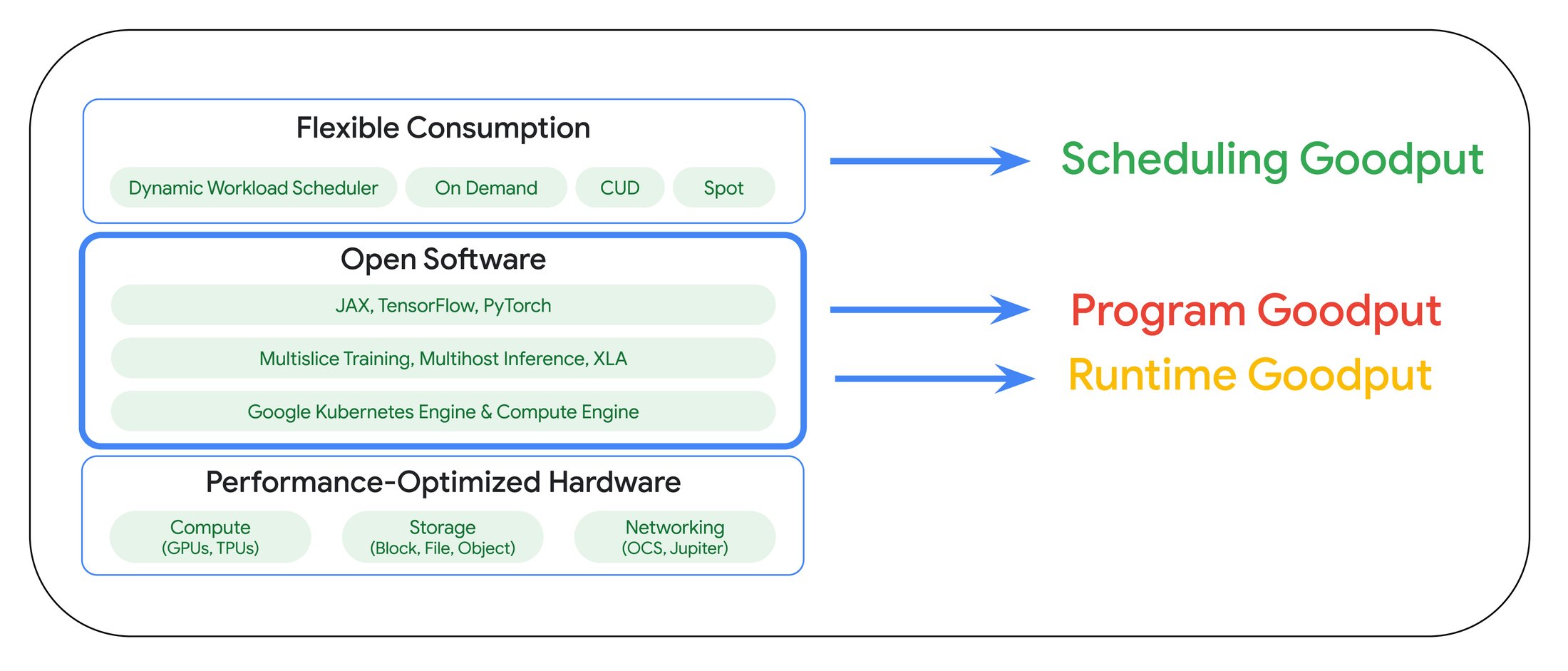
As indicated in the diagram above, AI Hypercomputer encodes specific capabilities aimed towards optimizing the Program and Runtime Goodput across the framework, runtime, and orchestration layers. For the remainder of this post we will focus on elements of AI Hypercomputer that can help you maximize it.
Understanding Runtime Goodput
The essence of Runtime Goodput is the number of useful training steps completed over a given window of time. Based on an assumed checkpointing interval, the time to reschedule the slice and the time to resume the training, we can estimate Runtime Goodput as follows:
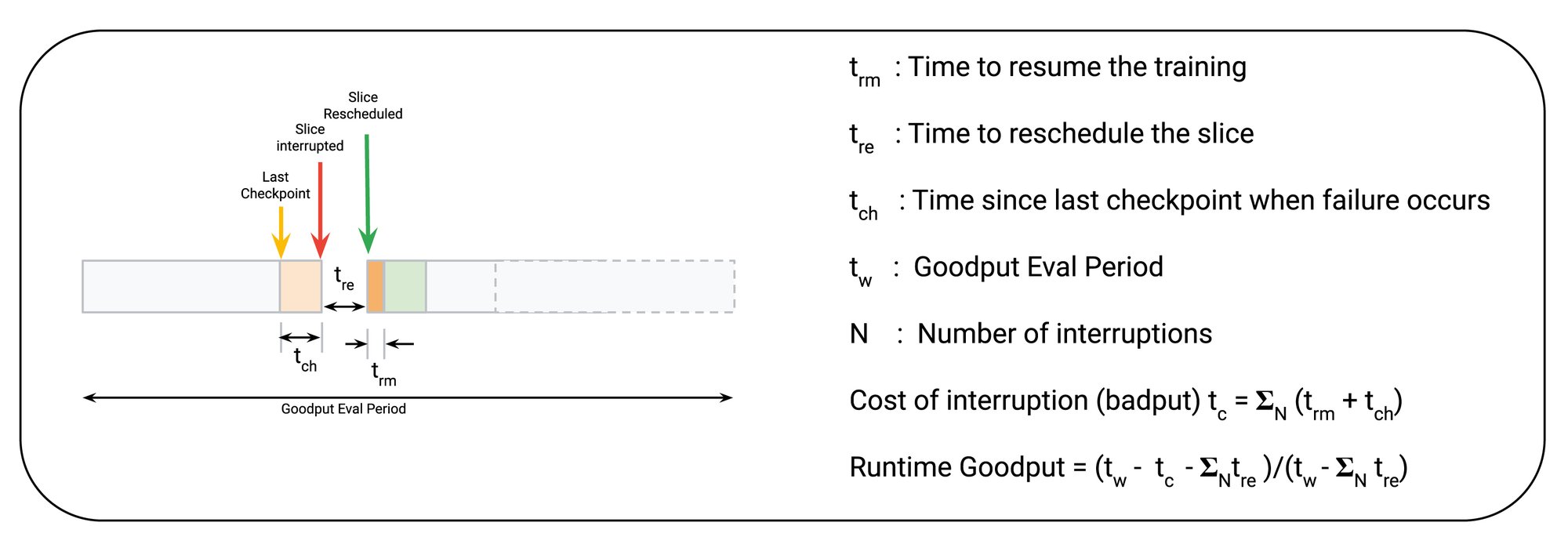
This analytical model also provides us with three precise factors that we need to minimize in order to maximize the Runtime Goodput: 1) time since the last checkpoint when the failure occurs (tch); 2) time to resume the training (trm). Time to reschedule (tre) the slice is also a key factor, however it’s accounted for under Scheduling Goodput.
Introducing Goodput Measurement API
The first step to improving something is to measure it. The Goodput Measurement API allows you to instrument (Scheduling Goodput * Runtime Goodput) measurement into your code using a Python package. The Goodput Measurement API provides methods to report your training step progress to Cloud Logging and then read the progress from Cloud Logging to measure and monitor Runtime Goodput.
Maximizing Scheduling Goodput
Scheduling goodput is contingent on the availability of ALL the required resources for the training execution. To maximize Goodput for short-term usage, we introduced DWS calendar mode that reserves compute resources for the training job. Furthermore, in order to minimize tre time to schedule resources when resuming from interruption, we recommend using “hot spares.” With the reserved resources and hot spares, we can maximize Scheduling Goodput.
Maximizing Runtime Goodput
AI Hypercomputer offers the following (recommended) methods to maximize the Runtime Goodput:
-
Enable auto-checkpointing
-
Use container pre-loading (available in Google Kubernetes Engine)
-
Use a persistent compilation cache
Auto-checkpointing
Auto-checkpointing lets you trigger checkpointing based on a SIGTERM signal that indicates the imminent interruption of the training job. Auto-checkpointing is useful in case of defragmentation-related preemption or maintenance events, helping to reduce loss since the last checkpoint.
An example implementation for auto-checkpointing is available in orbax as well as in Maxtext, a reference implementation for high-performance training and serving on Google Cloud.
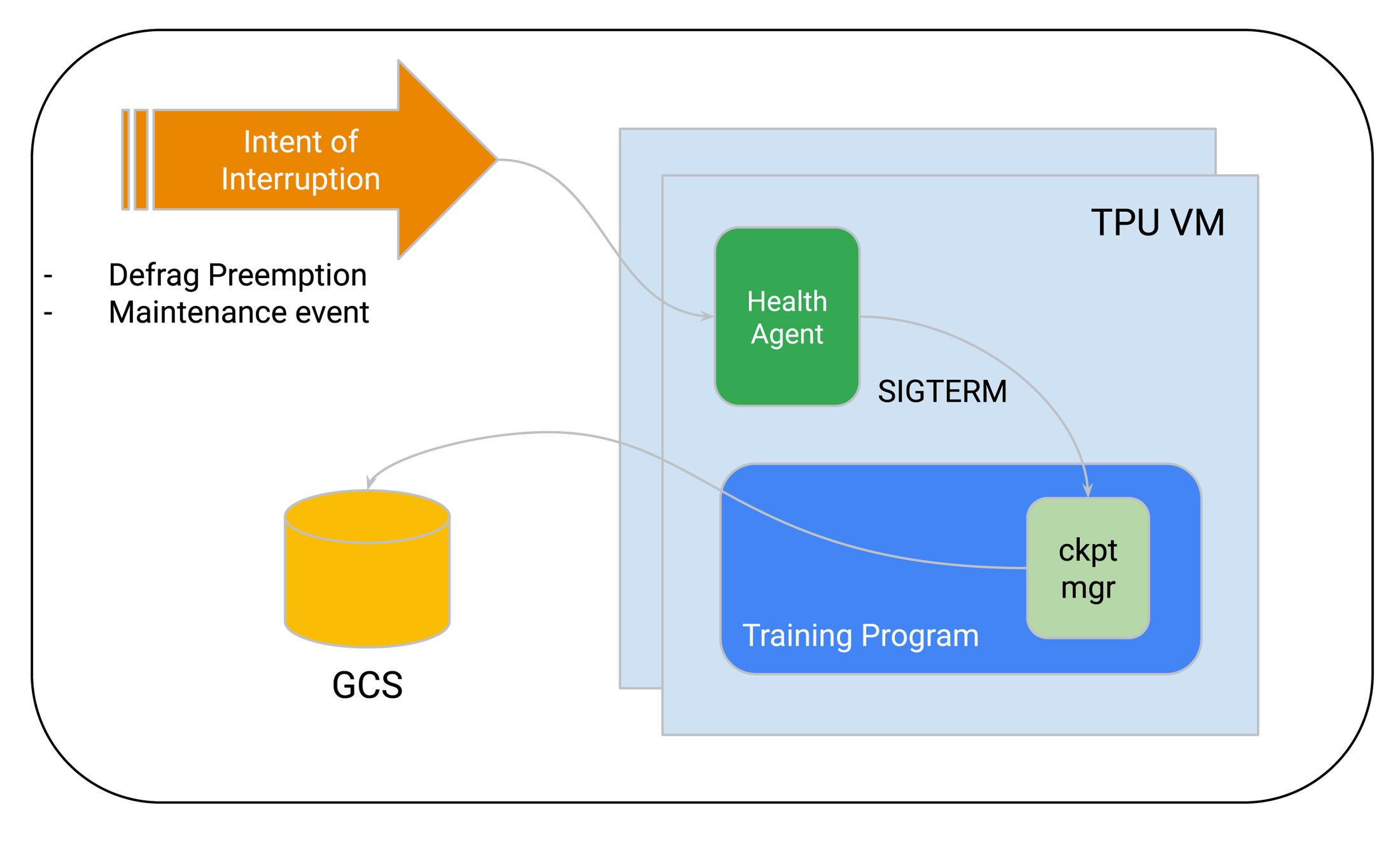
Auto-checkpointing is available for both GKE and non-GKE-based training orchestrators, and is available for training on both Cloud TPUs and GPUs.
Container pre-loading
To achieve a maximum Goodput score, it's important to rapidly resume training after a failure or any other interruption. To that end, we recommend Google Kubernetes Engine (GKE), which supports container and model preloading from a secondary boot disk. Currently available in preview, GKE's container and model preloading allows a workload, especially a large container image, to start up very quickly. This means training can recover from failure or other interruptions with minimal time loss. That’s important because when resuming a job, pulling a container image from object storage can be significant for large images. Pre-loading lets you specify a secondary boot disk that contains the required container image when creating the nodepool or even for auto-provisioning. The required container images are available as soon as GKE brings up the failed node, so you can resume training promptly.
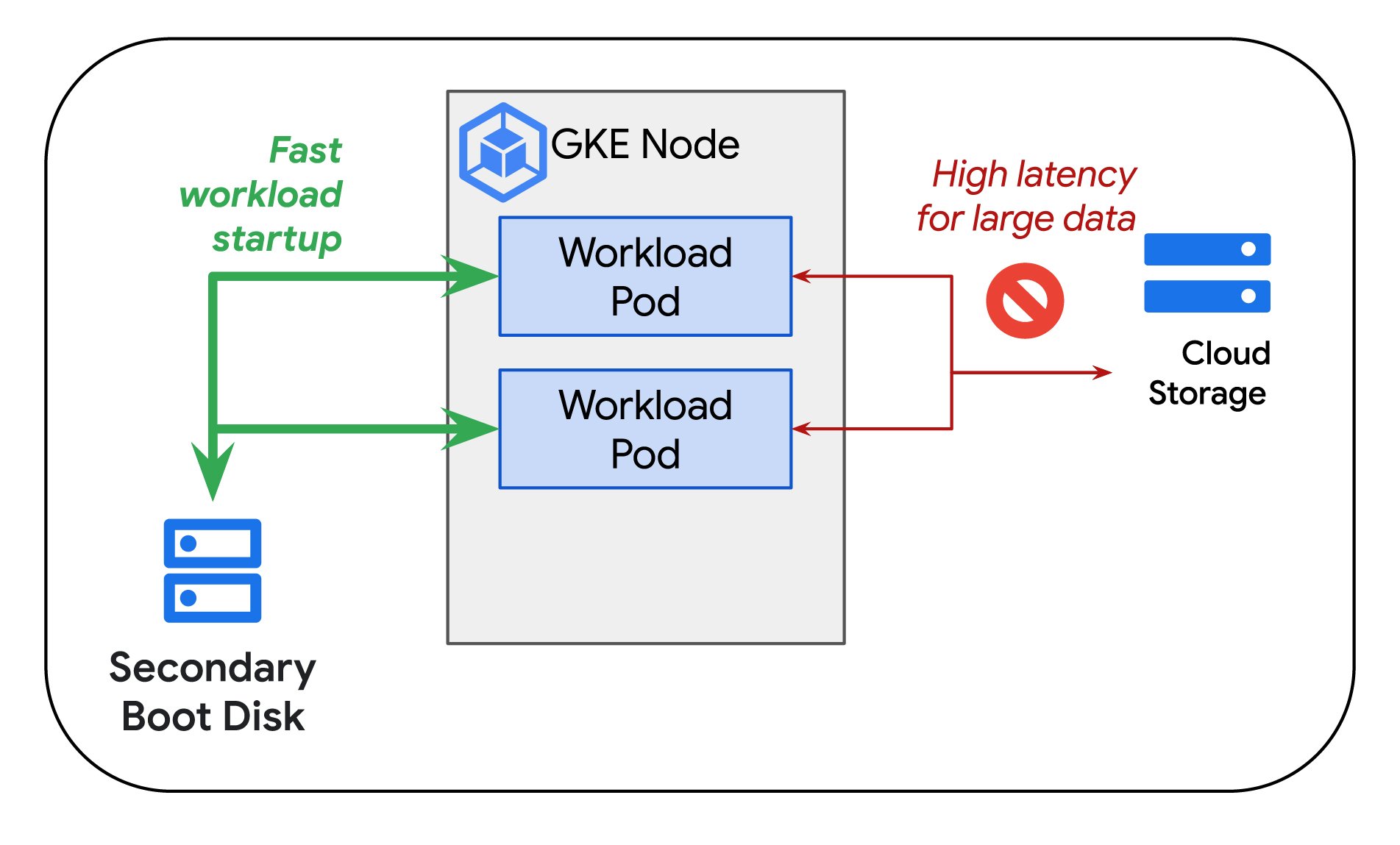
With container preloading, we measured the image pull operation for a 16GB container to be about 29X faster than the baseline (image pull from container registry).
Persistent compilation cache
Just-in-time compilation and system-aware optimizations are one of the key enablers for an XLA compiler-based computation stack. In most performant training loops, computation graphs are compiled once and executed many times with different input data. A compilation cache prevents recompilation if the graph shapes stay the same. In the event of a failure or interruption, this cache may be lost, thereby slowing down the training resumption process, adversely affecting the Runtime Goodput. A persistent compilation cache helps solve this problem by allowing users to save compilation cache to Cloud Storage such that the cache persists across restart events.
Furthermore, GKE, the recommended orchestration layer for AI Hypercomputer, has also made recent advancements to improve the job-scheduling throughput by 3X, helping reduce time to resume (trm).
Maximizing Program Goodput
Program Goodput or Model Flop Utilization depends on the efficient utilization of the underlying compute as the training program makes forward progress. Distribution strategy, efficient compute communication overlap, optimized memory access and designing efficient pipelines contribute to Program Goodput. XLA compiler is one of the core components of AI Hypercomputer designed to help you maximize the Program Goodput by out-of-the box optimizations and simple and performant scaling APIs such as GSPMD, which allows users to easily express a wide range of parallelisms to efficiently leverage scale. We recently introduced three key features to help Jax and PyTorch/XLA users maximize Program Goodput.
Custom Kernel with XLA
In compiler-driven computation optimization, often we need an “escape hatch,” which allows users to write more efficient implementations using fundamental primitives for complex computation blocks, pushing past the default performance. Jax/Pallas is the library built to support custom kernels for Cloud TPUs and GPUs. It supports both Jax and PyTorch/XLA. Some examples of custom kernels written using Pallas include Flash Attention or Block Sparse Kernels. The Flash attention kernel helps to improve Program Goodput or Model Flop Utilization for larger sequence lengths (more pronounced for sequence lengths 4K or above).
Host offload
For large-scale model training, accelerator memory is a limited resource and we often make trade-offs such as activation re-materialization to trade off compute cycles for accelerator memory resources. Host offload is another technique we recently introduced in the XLA compiler to leverage host DRAM to offload activations computed during the forward pass and reuse them during the backward pass for gradient computation; this saves activation recomputation cycles and therefore improves Program Goodput.
Int8 Mixed Precision Training using AQT
Accurated Quantized Training is another technique that maps a subset of matrix multiplications in the training step to int8 to boost training efficiency and therefore Program Goodput without compromising convergence.
The following benchmark shows aforementioned techniques used in conjunction to boost program goodput for a 128b dense LLM implementation using MaxText.
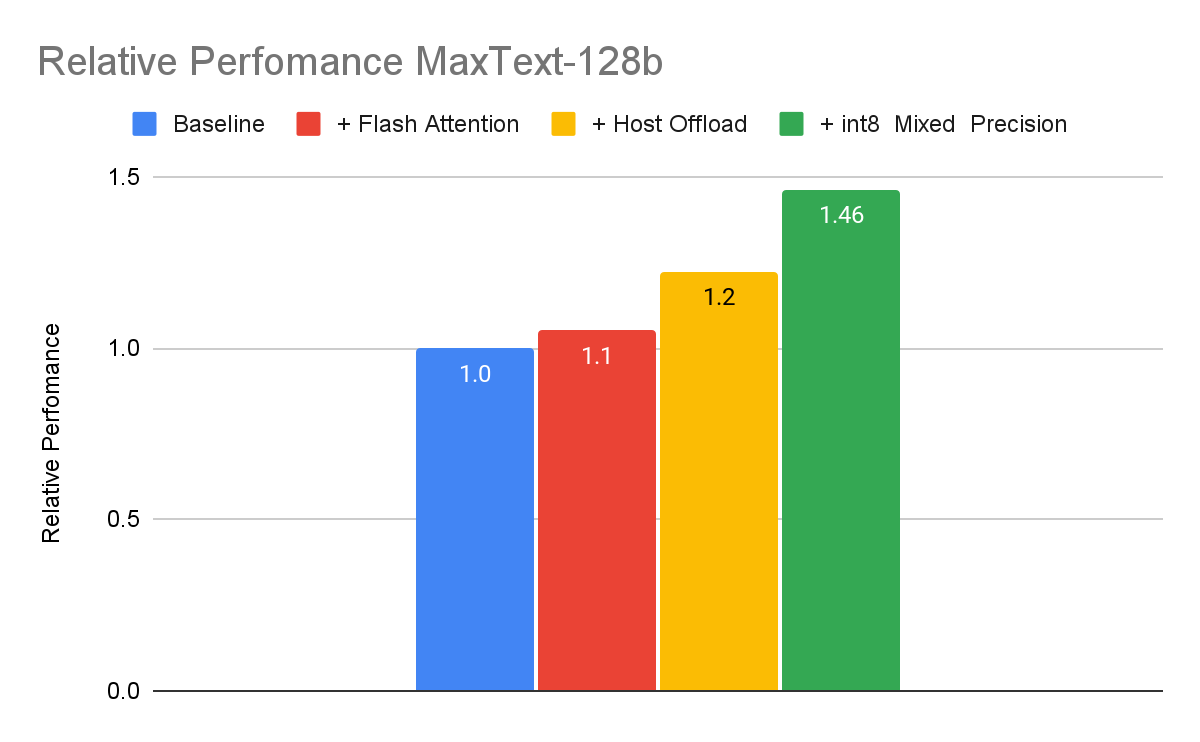
EMFU measured using MaxText 128b, context length 2048, trained with synthetic data, using Cloud TPU v5e-256. Measured as of April, 2024.
In this benchmark, the combination of these three techniques boosts the Program Goodput cumulatively up to 46%. Program Goodput improvement is often an iterative process. Actual improvements for a specific training job depend on training hyperparameters and the model architecture.
Conclusion
Large-scale training for generative models is an enabler of business value, but productivity for ML training becomes harder as it scales. In this post, we defined ML Productivity Goodput, a metric to measure overall ML productivity for large-scale training jobs. We introduced the Goodput measurement API, and we learned about the components of AI Hypercomputer that can help you maximize ML Productivity Goodput at scale. We look forward to helping you maximize your ML productivity at scale with AI Hypercomputer.



