Google Cloud Managed Service for Prometheus 会对提取到 Cloud Monitoring 的样本数量和发送到 Monitoring API 的读取请求收费。注入的样本数量是造成费用的主要因素。
本文档介绍了如何控制与指标注入相关的成本以及如何识别大量注入的来源。
如需详细了解 Managed Service for Prometheus 的价格,请参阅 Google Cloud Observability 价格页面中的“Cloud Monitoring”部分。
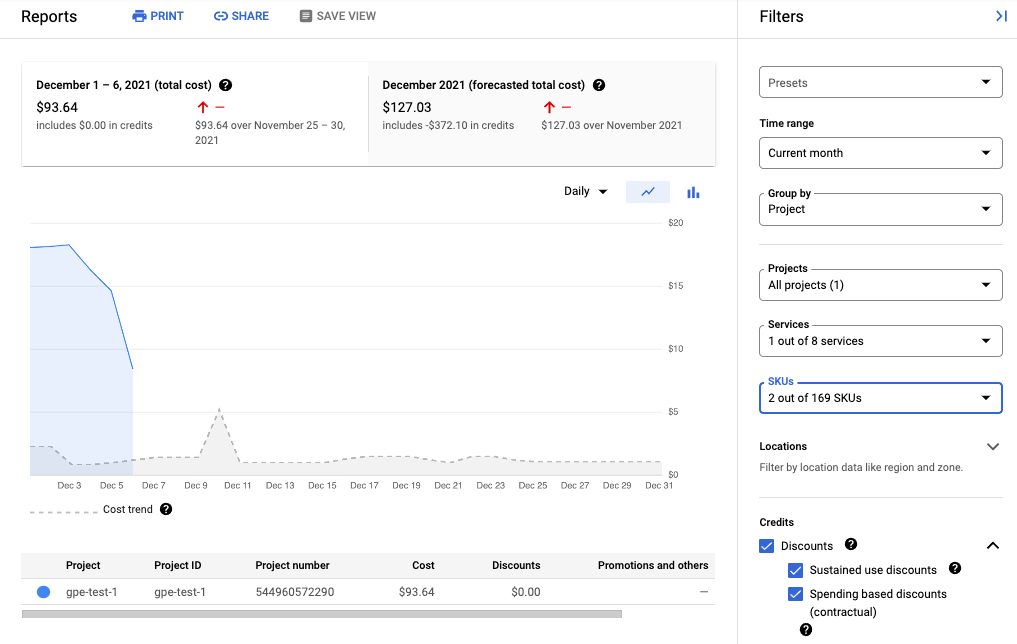
查看您的账单
如需查看您的 Google Cloud 账单,请执行以下操作:
在 Google Cloud 控制台中,前往结算页面。
如果您有多个结算账号,请选择转至关联的结算账号以查看当前项目的结算账号。如需查找不同的结算账号,请选择管理结算账号,然后选择想要获取其用量报告的账号。
在“结算”导航菜单的费用管理部分中,选择报告。
从服务菜单中,选择 Cloud Monitoring 选项。
从 SKU 菜单中选择以下选项:
- 注入的 Prometheus 样本数
- Monitoring API 请求
以下屏幕截图显示了来自一个项目的 Managed Service for Prometheus 的结算报告:
降低费用
如需降低与使用 Managed Service for Prometheus 相关的费用,您可以执行以下操作:
- 通过过滤生成的指标数据,减少发送到托管式服务的时序的数量。
- 通过更改抓取间隔来减少收集的样本数量。
- 限制来自可能错误配置的高基数指标的样本数量。
减少时序的数量
开源 Prometheus 文档很少建议过滤指标量,当费用受机器费用限制时,这是合理的。但是,在按单元支付代管式服务提供商的费用时,发送无限制的数据可能会导致不必要的高昂账单。
kube-prometheus 项目(尤其是 kube-state-metrics 服务)中包含的导出程序可能会发出大量指标数据。例如,kube-state-metrics 服务会发出数百个指标,其中许多指标可能对您而言没有价值。使用 kube-prometheus 项目的全新三节点集群每秒向 Managed Service for Prometheus 发送大约 900 个样本。过滤这些不相关的指标本身可能足以让您将费用降低到可接受的水平。
要减少指标数量,您可以执行以下操作:
如果您使用 kube-state-metrics 服务,则可以添加包含 keep 操作的 Prometheus 重新添加标签规则。对于代管式收集,此规则位于 PodMonitoring 或 ClusterPodMonitoring 定义中。对于自部署收集,此规则位于 Prometheus 抓取配置或 ServiceMonitor 定义中(针对 prometheus-operator)。
例如,在新的三节点集群上使用以下过滤条件可每秒减少约 125 个样本:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
上一个过滤条件使用正则表达式根据指标名称指定要保留的指标。例如,名称以 kube_daemonset_ 开头的指标将被保留。您还可以指定 drop 操作,以过滤掉与正则表达式匹配的指标。
有时,您可能会发现整个导出器并不重要。例如,kube-prometheus 软件包默认安装以下服务监控服务,其中许多在代管式环境中都是不必要的:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
要减少导出的指标数量,您可以删除、禁用或停止抓取不需要的服务监视器。例如,在新的三节点集群上停用 kube-apiserver 服务监控器可将样本量每秒减少大约 200 个样本。
减少收集的样本数量
Managed Service for Prometheus 按样本收费。您可以通过增加采样周期的长度来减少注入的样本数量。例如:
- 将 10 秒采样周期更改为 30 秒采样周期可将采样量减少 66%,而不会丢失大量信息。
- 将 10 秒采样周期更改为 60 秒采样周期可将采样量减少 83%。
如需了解样本的计算方式以及采样周期对样本数量的影响,请参阅按注入的样本数计费的指标数据。
通常可以按作业或按目标设置注入间隔。
对于代管式收集,您可以使用 interval 字段在 PodMonitoring 资源中设置抓取间隔。对于自部署集合,通常通过设置 interval 或 scrape_interval 字段在抓取配置中设置采样间隔。
配置局部聚合(仅限自行部署的收集)
如果您要使用自行部署的收集(例如通过 kube-prometheus、prometheus-operator 或手动部署映像)来配置服务,则可以通过在本地汇总高基数指标来减少发送到 Managed Service for Prometheus 的样本。您可以使用记录规则来聚合 instance 等标签,并使用 --export.match 标志或 EXTRA_ARGS 环境变量来仅将数据发送到 Monarch。
例如,假设您有三个指标:high_cardinality_metric_1、high_cardinality_metric_2 和 low_cardinality_metric。 您希望减少针对 high_cardinality_metric_1 发送的样本,并消除针对 high_cardinality_metric_2 发送的所有样本,同时保留所有存储在本地的原始数据(可能用于提醒目的)。您的设置可能如下所示:
- 部署 Managed Service for Prometheus 映像。
- 配置爬取配置,以将所有原始数据爬取到本地服务器(根据需要使用较少的过滤条件)。
将您的记录规则配置为对
high_cardinality_metric_1和high_cardinality_metric_2运行局部聚合,方法是聚合instance标签或任意数量的指标标签,具体取决于哪种方式可将不需要的时序的数量减至最少。您可以运行类似如下的规则,它丢弃instance标签,并针对其余标签生成的时序进行求和:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
如需了解更多聚合选项,请参阅 Prometheus 文档中的聚合运算符。
使用以下过滤条件标志部署 Managed Service for Prometheus 映像,以防止将所列指标中的原始数据发送到 Monarch:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'此示例
export.match标志使用英文逗号分隔的选择器与!=运算符来过滤掉不需要的原始数据。如果您添加其他记录规则以聚合其他高基数指标,则还必须向过滤条件添加新的__name__选择器以舍弃原始数据。通过将包含多个选择器的单个标志与!=运算符搭配使用来过滤掉不需要的数据,您只需在创建新聚合时而不是需修改或添加时爬取配置时修改过滤条件。某些部署方法(例如 prometheus-operator)可能要求您省略括起英文括号的英文单引号。
此工作流可能会在创建和管理记录规则和 export.match 标志时产生一些操作开销,但您可能可以通过只关注基数非常高的指标来大大减少数据量。如需了解如何确定哪些指标可能会从本地预聚合中获益最多,请参阅确定大量指标。
在使用 Managed Service for Prometheus 时,请勿实现联合功能。此工作流会使正在使用的联合服务器过时,因为单个自行部署的 Prometheus 服务器便可以执行您可能需要的任何集群级层聚合。联合可能会产生一些意外的影响,例如“未知”类型的指标和加倍的注入量。
限制高基数指标的样本(仅限自行部署的收集)
您可以通过添加具有极大量潜在值的标签(例如用户 ID 或 IP 地址)来创建高基数指标。此类指标可能会生成大量样本。使用具有大量值的标签通常是一种错误配置。通过在抓取配置中设置 sample_limit 值,您可以防止自部署收集器中的高基数指标。
如果您使用此限制,我们建议您将其设置为非常高的值,以便仅捕获明显配置错误的指标。任何超出限制的样本都会被丢弃,并且超出诊断的限制可能会导致很难诊断。
使用样本限制不能很好地管理样本注入,但该限制可以防止意外配置错误。如需了解详情,请参阅使用 sample_limit 以避免过载。
确定和归因费用
您可以使用 Cloud Monitoring 来标识写入最多样本的 Prometheus 指标。这些指标对费用的影响最大。在确定费用最高的指标后,您可以修改抓取配置以适当过滤这些指标。
Cloud Monitoring 指标管理页面提供的信息可帮助您控制在收费指标上支出的金额,而不会影响可观测性。指标管理页面报告以下信息:
- 针对指标网域中基于字节和基于样本的结算以及各个指标的注入量。
- 有关标签和指标基数的数据。
- 每个指标的读取次数。
- 指标在提醒政策和自定义信息中心内的使用。
- 指标写入错误率。
您还可以使用指标管理来排除不需要的指标,从而免除注入这些指标的费用。
如需查看指标管理页面,请执行以下操作:
-
在 Google Cloud 控制台中,前往 指标管理页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在工具栏中,选择时间窗口。默认情况下,指标管理页面会显示有关前一天收集的指标的信息。
如需详细了解指标管理页面,请参阅查看和管理指标使用情况。
以下部分介绍了分析发送到 Managed Service for Prometheus 的样本数量以及将大量指标归因于特定指标、Kubernetes 命名空间和 Google Cloud 区域的方法。
标识大量指标
如需标识注入量最大的 Prometheus 指标,请执行以下操作:
-
在 Google Cloud 控制台中,前往 指标管理页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在注入的计费样本数统计信息摘要图表上,点击查看图表。
- 找到命名空间卷注入图表,然后点击 more_vert 更多图表选项。
- 选择在 Metrics Explorer 中查看图表选项。
- 在 Metrics Explorer 的构建器窗格中,按如下方式修改字段:
- 在指标字段中,验证是否已选择以下资源和指标:
Metric Ingestion Attribution和Samples written by attribution id。 - 在聚合字段中,选择
sum。 - 在依据字段中,选择以下标签:
attribution_dimensionmetric_type
- 在过滤条件字段中,使用
attribution_dimension = namespace。您必须在按attribution_dimension标签聚合后执行此操作。
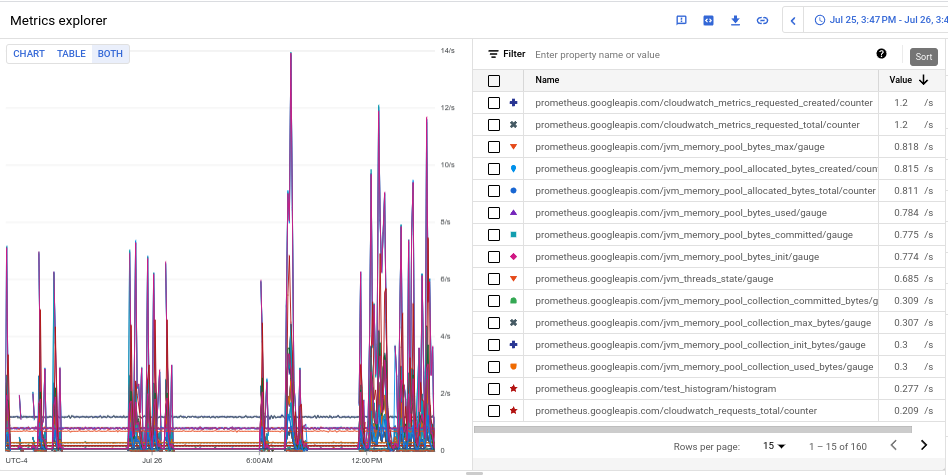
生成的图表显示每种指标类型的注入量。
- 在指标字段中,验证是否已选择以下资源和指标:
- 如需查看每个指标的注入量,请在标有图表/表/两者的切换开关中,选择两者。该表的值列中显示了每个指标的注入量。
- 点击值列标题两次,以按注入量降序对指标排序。
生成的图表显示按平均值排序的注入量最多的指标,如以下屏幕截图所示:
标识大量命名空间
如需将注入量归因于特定的 Kubernetes 命名空间,请执行以下操作:
-
在 Google Cloud 控制台中,前往 指标管理页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
- 在注入的计费样本数统计信息摘要图表上,点击查看图表。
- 找到命名空间卷注入图表,然后点击 more_vert 更多图表选项。
- 选择在 Metrics Explorer 中查看图表选项。
- 在 Metrics Explorer 的构建器窗格中,按如下方式修改字段:
- 在指标字段中,验证是否已选择以下资源和指标:
Metric Ingestion Attribution和Samples written by attribution id。 - 根据需要配置其余查询参数:
- 如需将总体注入量与命名空间相关联,请执行以下操作:
- 在聚合字段中,选择
sum。 - 在依据字段中,选择以下标签:
attribution_dimensionattribution_id
- 在过滤条件字段中,使用
attribution_dimension = namespace。
- 在聚合字段中,选择
- 如需将各个指标的注入量与命名空间相关联,请执行以下操作:
- 在聚合字段中,选择
sum。 - 在依据字段中,选择以下标签:
attribution_dimensionattribution_idmetric_type
- 在过滤条件字段中,使用
attribution_dimension = namespace。
- 在聚合字段中,选择
- 如需确定负责特定大量指标的命名空间,请执行以下操作:
- 使用其他示例之一确定大量指标类型,以确定大量指标的指标类型。指标类型是表视图中以
prometheus.googleapis.com/开头的字符串。如需了解详情,请参阅确定大量指标。 - 如需将图表数据限制为已确定的指标类型,请在过滤条件字段中为该指标类型添加过滤条件。例如:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge。 - 在聚合字段中,选择
sum。 - 在依据字段中,选择以下标签:
attribution_dimensionattribution_id
- 在过滤条件字段中,使用
attribution_dimension = namespace。
- 使用其他示例之一确定大量指标类型,以确定大量指标的指标类型。指标类型是表视图中以
- 如需按 Google Cloud 区域查看注入的数据,请将
location标签添加到依据字段。 - 如需按 Google Cloud 项目查看注入的数据,请将
resource_container标签添加到依据字段。
- 如需将总体注入量与命名空间相关联,请执行以下操作:
- 在指标字段中,验证是否已选择以下资源和指标: