Google Cloud Managed Service para Prometheus cobra por la cantidad de muestras transferidas a Cloud Monitoring y por las solicitudes de lectura a la API de Monitoring. El número de muestras transferidas es el factor principal del costo.
En este documento, se describe cómo puedes controlar los costos asociados con la transferencia de métricas y cómo identificar las fuentes de las transferencias de alto volumen.
Si deseas obtener más información sobre los precios de Managed Service para Prometheus, consulta las secciones de Cloud Monitoring en la página Precios de Google Cloud Observability.
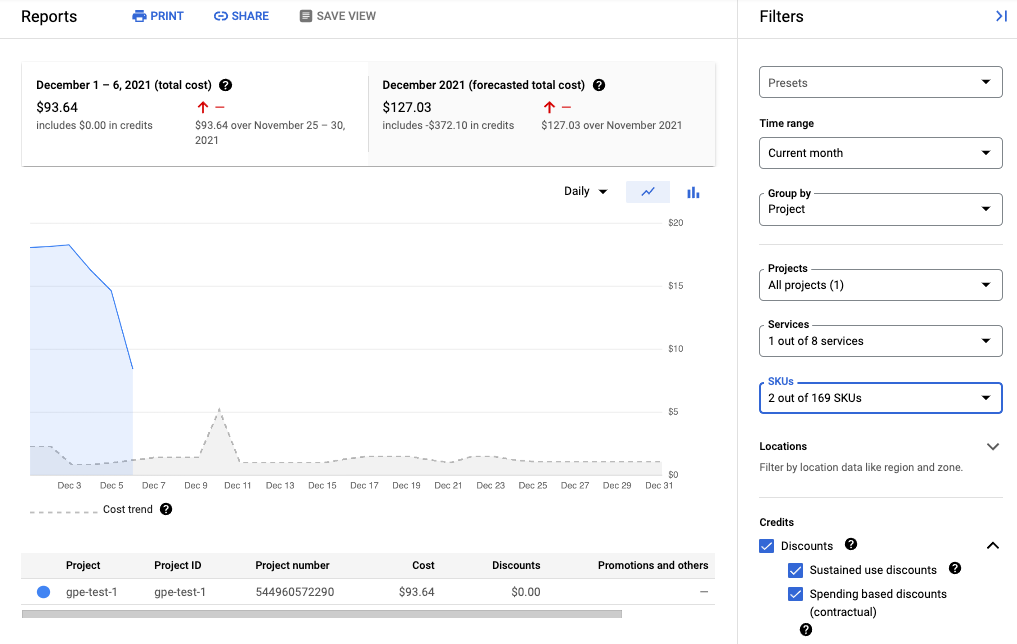
Visualiza tu factura
Para ver tu Google Cloud factura, haz lo siguiente:
En la consola de Google Cloud , ve a la página Facturación.
Si tienes más de una cuenta de facturación, selecciona Go to linked billing account (Ir a la cuenta de facturación vinculada) a fin de administrar la facturación del proyecto actual. Si deseas encontrar otra cuenta de facturación, selecciona Administrar cuentas de facturación y elige la cuenta para la cual quieres obtener informes de uso.
En la sección Administración de costos del menú de navegación de Facturación, selecciona Informes.
En el menú Servicios, selecciona la opción Cloud Monitoring.
En el menú SKU, selecciona las siguientes opciones:
- Muestras transferidas de Prometheus
- Solicitudes a la API de Monitoring
En la siguiente captura de pantalla, se muestra el informe de facturación de Managed Service para Prometheus de un proyecto:
Reduce los costos
A fin de reducir los costos asociados con el uso de Managed Service para Prometheus, puedes hacer lo siguiente:
- Filtra los datos de métricas que generas para reducir la cantidad de series temporales que envías al servicio administrado.
- Cambia el intervalo de scraping para reducir la cantidad de muestras que recopilas.
- Limita la cantidad de muestras de métricas con alta cardinalidad que puedan estar mal configuradas.
Reduce la cantidad de series temporales
La documentación de Prometheus de código abierto rara vez recomienda filtrar el volumen de métricas, lo que es razonable cuando los costos están delimitados por los costos de máquina. Sin embargo, cuando se paga a un proveedor de servicios administrados por unidad, el envío de datos ilimitados puede generar facturas innecesariamente altas.
Los exportadores incluidos en el proyecto kube-prometheus
(en particular, el servicio kube-state-metrics)
pueden emitir muchos datos de métricas.
Por ejemplo, el servicio kube-state-metrics emite cientos de métricas, muchas de las cuales pueden no tener ningún valor para ti como consumidor. Un clúster nuevo de tres nodos que usa el proyecto kube-prometheus envía alrededor de 900 muestras por segundo al servicio administrado para Prometheus.
Filtrar estas métricas innecesarias puede ser suficiente para que tu factura se reduzca a un nivel aceptable.
Para reducir la cantidad de métricas, puedes hacer lo siguiente:
- Modifica tu configuración de scraping para recopilar menos objetivos.
- Filtra las métricas recopiladas como se describe a continuación:
- Filtra las métricas exportadas cuando uses la recopilación administrada.
- Filtra las métricas exportadas cuando uses la recopilación de implementación automática.
Si usas el servicio kube-state-metrics, puedes agregar una regla de reetiquetado de Prometheus con una acción keep. Para la recopilación administrada, esta regla va en tu definición de PodMonitoring o ClusterPodMonitoring. Para la recopilación implementada de forma automática, esta regla va en tu configuración de recopilación de Prometheus o tu definición de ServiceMonitor (para prometheus-operator).
Por ejemplo, si usas el siguiente filtro en un clúster de tres nodos nuevo, se reduce el volumen de muestras en aproximadamente 125 muestras por segundo:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
El filtro anterior usa una expresión regular para especificar qué métricas se deben conservar según el nombre de la métrica. Por ejemplo, se conservan las métricas cuyo nombre empieza con kube_daemonset_.
También puedes especificar una acción de drop, que filtre las métricas que coinciden con la expresión regular.
A veces, es posible que un exportador completo no te parezca importante. Por ejemplo, el paquete kube-prometheus instala las siguientes supervisiones de servicio de forma predeterminada, muchas de las cuales son innecesarias en un entorno administrado:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Para reducir la cantidad de métricas que exportas, puedes borrar, inhabilitar o detener el scraping de los monitores de servicios que no necesitas. Por ejemplo, inhabilitar el monitor de servicios kube-apiserver en un clúster de tres nodos nuevo reduce el volumen de muestras en aproximadamente 200 muestras por segundo.
Reduce la cantidad de muestras recopiladas
Managed Service para Prometheus cobra por muestra. Puedes reducir la cantidad de muestras transferidas si aumentas la duración del período de scraping. Por ejemplo:
- Cambiar un período de scraping de 10 segundos a 30 segundos puede reducir tu volumen de muestras en un 66%, sin perder mucha información.
- Cambiar un período de muestreo de 10 segundos a 60 segundos puede reducir el volumen de muestras en un 83%.
Para obtener información sobre cómo se cuentan las muestras y cómo el período de muestreo afecta la cantidad de muestras, consulta Datos de métricas cobrados por muestras transferidas.
Por lo general, puedes establecer el intervalo de scraping por trabajo o por objetivo.
Para la recopilación administrada, configura el intervalo de scraping en el recurso PodMonitoring mediante el campo interval.
Para la recopilación autoimplementada, debes establecer el intervalo de muestreo en tu configuración de scraping, por lo general, mediante la configuración de un campo interval o scrape_interval.
Configura la agregación local (solo la colección implementada automáticamente)
Si configuras el servicio mediante la colección implementada automáticamente, por ejemplo, con kube-prometheus, prometheus-operator o mediante la implementación manual de la imagen, puedes reducir las muestras que se envían a un servicio administrado para Prometheus mediante la agregación de métricas de cardinalidad alta de manera local. Puedes usar reglas de grabación para agregar etiquetas como instance y usar la marca --export.match o la variable de entorno EXTRA_ARGS para enviar solo datos agregados a Monarch.
Por ejemplo, supón que tienes tres métricas: high_cardinality_metric_1, high_cardinality_metric_2 y low_cardinality_metric. Deseas reducir las muestras enviadas para high_cardinality_metric_1 y eliminar todas las muestras enviadas para high_cardinality_metric_2, mientras mantienes todos los datos sin procesar almacenados de manera local (tal vez para fines de alerta). Tu configuración debería verse similar a esta:
- Implementa la imagen del servicio administrado para Prometheus.
- Establece tu configuración de scraping para recopilar todos los datos sin procesar en el servidor local (con la menor cantidad de filtros que desees).
Configurar tus reglas de grabación para ejecutar agregaciones locales en
high_cardinality_metric_1yhigh_cardinality_metric_2, tal vez mediante la agregación de la etiquetainstanceo cualquier cantidad de etiquetas de métricas, según lo que proporcione la mejor reducción en la cantidad de series temporales innecesarias. Puedes ejecutar una regla similar a la siguiente, que descarta la etiquetainstancey suma las series temporales resultantes en las etiquetas restantes:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Consulta los operadores de agregación en la documentación de Prometheus para obtener más opciones de agregación.
Implementa la imagen de servicio administrado para Prometheus con la siguiente marca de filtro, que evita que los datos sin procesar de las métricas enumeradas se envíen a Monarch:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'Esta marca
export.matchde ejemplo usa selectores separados por comas con el operador!=para filtrar los datos sin procesar no deseados. Si agregas reglas de grabación adicionales para agregar otras métricas de alta cardinalidad, también debes agregar un selector__name__nuevo al filtro a fin de que se descarten los datos sin procesar. Si usas una sola marca que contiene varios selectores con el operador!=para filtrar los datos no deseados, solo necesitas modificar el filtro cuando crees una agregación nueva en lugar de hacerlo cuando modifiques o agregues una configuración de scraping.Ciertos métodos de implementación, como el operador de Prometheus, pueden requerir que omitas las comillas simples alrededor de los corchetes.
Este flujo de trabajo puede generar sobrecarga operativa durante la creación y la administración de reglas de grabación y marcas export.match, pero es probable que puedas reducir mucho volumen si te enfocas solo en las métricas con cardinalidad excepcionalmente alta. Para obtener información sobre cómo identificar qué métricas podrían beneficiarse más de la agregación local realizada previamente, consulta Identifica métricas de gran volumen.
No implementes la federación cuando uses el servicio administrado para Prometheus. Este flujo de trabajo hace que el uso de servidores de federación sea obsoleto, ya que un único servidor de Prometheus implementado de forma automática puede realizar cualquier agregación a nivel de clúster que necesites. La federación puede causar efectos inesperados, como métricas de tipo “desconocido” y volumen de transferencia duplicado.
Limita las muestras de las métricas de cardinalidad alta (solo la colección implementada automáticamente)
Puedes crear métricas de cardinalidad extremadamente alta si agregas etiquetas que tengan una gran cantidad de valores potenciales, como un ID de usuario o una dirección IP. Estas métricas pueden generar una gran cantidad de muestras. El uso de etiquetas con una gran cantidad de valores suele ser una configuración incorrecta. Puedes protegerte contra las métricas de cardinalidad alta en los colectores implementados de forma automática si configuras un valor sample_limit en tu configuración de recopilación.
Si usas este límite, te recomendamos que lo establezcas en un valor muy alto, de modo que solo detecte métricas que estén evidentemente configuradas de forma incorrecta. Cualquier muestra que supere el límite se descarta, y puede ser muy difícil diagnosticar los problemas causados por exceder el límite.
Usar un límite de muestra no es una buena forma de administrar la transferencia de muestras, pero el límite puede protegerte contra una configuración incorrecta accidental. Para obtener más información, consulta Usa sample_limit para evitar la sobrecarga.
Identifica y atribuye costos
Puedes usar Cloud Monitoring para identificar las métricas de Prometheus que escriben la mayor cantidad de muestras. Estas métricas son las que más contribuyen a los costos. Después de identificar las métricas más costosas, puedes modificar tu configuración de recopilación para filtrarlas de forma adecuada.
En la página Administración de métricas de Cloud Monitoring, se proporciona información que puede ayudarte a controlar el importe que inviertes en las métricas facturables sin afectar la observabilidad. En la página Administración de métricas, se proporciona la siguiente información:
- Volúmenes de transferencia para la facturación basada en bytes y de muestra, en todos los dominios de métricas y en cada métrica individual
- Datos sobre etiquetas y cardinalidad de métricas
- Cantidad de lecturas para cada métrica
- Uso de métricas en políticas de alertas y paneles personalizados
- Tasa de errores de escritura de métricas
También puedes usar la página Administración de métricas para excluir las métricas innecesarias, de modo que te ahorrarás el costo de su transferencia.
Para ver la página Administración de métricas, haz lo siguiente:
-
En la consola de Google Cloud , ve a la página Administración de métricas:
Ir a Administración de métricas
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Monitoring.
- En la barra de herramientas, selecciona tu período. De forma predeterminada, la página Administración de métricas muestra información sobre las métricas recopiladas en el día anterior.
Para obtener más información sobre la página Administración de métricas, consulta Visualiza y administra el uso de métricas.
En las siguientes secciones, se describen formas de analizar la cantidad de muestras que envías a Managed Service para Prometheus y atribuir el gran volumen a métricas específicas, espacios de nombres de Kubernetes y regiones de Google Cloud .
Identifica métricas de gran volumen
Para identificar las métricas de Prometheus con los volúmenes de transferencia más grandes, haz lo siguiente:
-
En la consola de Google Cloud , ve a la página Administración de métricas:
Ir a Administración de métricas
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Monitoring.
- En el cuadro de evaluación Muestras facturables transferidas, haz clic en Ver gráficos.
- Ubica el gráfico Transferencia de volúmenes de espacio de nombres y haz clic en more_vert Más opciones de gráfico.
- Selecciona la opción de gráfico Ver en el Explorador de métricas.
- En el panel Compilador del Explorador de métricas, modifica los campos
de la siguiente manera:
- En la Métrica verifica que estén seleccionados los recursos y la métrica siguientes:
Metric Ingestion AttributionySamples written by attribution id. - En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionmetric_type
- En el campo Filtro, usa
attribution_dimension = namespace. Debes hacer esto después de agregar por la etiquetaattribution_dimension.
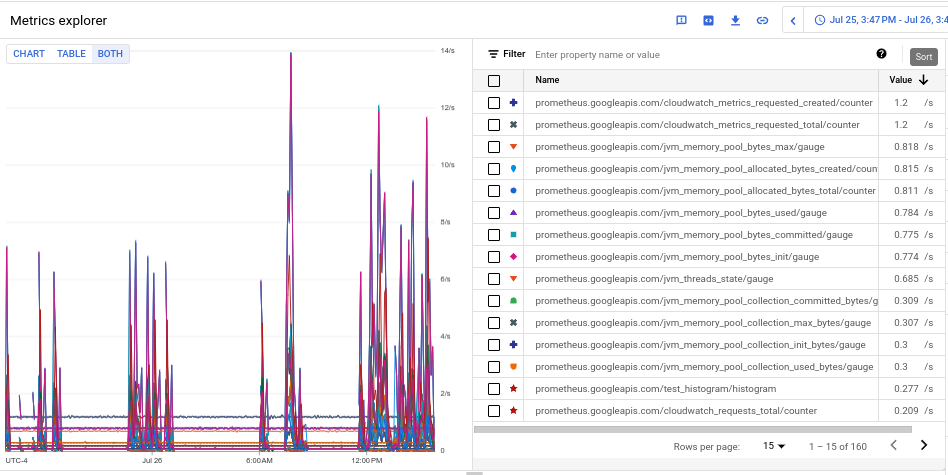
En el gráfico resultante, se muestran los volúmenes de transferencia para cada tipo de métrica.
- En la Métrica verifica que estén seleccionados los recursos y la métrica siguientes:
- Para ver el volumen de transferencia de cada una de las métricas, selecciona Ambos en el botón de activación Gráfico de tabla de ambos. En la tabla, se muestra el volumen transferido para cada métrica de la columna Valor.
- Haz clic en el encabezado de la columna Valor dos veces para ordenar las métricas por volumen de transferencia descendente.
El gráfico resultante, que muestra tus métricas principales por volumen clasificadas por media, se parece a la siguiente captura de pantalla:
Identifica espacios de nombres de gran volumen
Para atribuir el volumen de transferencia a espacios de nombres específicos de Kubernetes, haz lo siguiente:
-
En la consola de Google Cloud , ve a la página Administración de métricas:
Ir a Administración de métricas
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Monitoring.
- En el cuadro de evaluación Muestras facturables transferidas, haz clic en Ver gráficos.
- Ubica el gráfico Transferencia de volúmenes de espacio de nombres y haz clic en more_vert Más opciones de gráfico.
- Selecciona la opción de gráfico Ver en el Explorador de métricas.
- En el panel Compilador del Explorador de métricas, modifica los campos
de la siguiente manera:
- En la Métrica verifica que estén seleccionados los recursos y la métrica siguientes:
Metric Ingestion AttributionySamples written by attribution id. - Configura el resto de los parámetros de consulta según corresponda:
- Para correlacionar el volumen de transferencia general con los espacios de nombres, haz lo siguiente:
- En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionattribution_id
- En el campo Filtro, usa
attribution_dimension = namespace.
- En el campo Agregación, selecciona
- Para correlacionar el volumen de transferencia de métricas individuales con los espacios de nombres, haz lo siguiente:
- En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionattribution_idmetric_type
- En el campo Filtro, usa
attribution_dimension = namespace.
- En el campo Agregación, selecciona
- Para identificar los espacios de nombres responsables de una métrica específica de gran volumen, haz lo siguiente:
- Identifica el tipo de métrica de la métrica de gran volumen mediante uno de los otros ejemplos para identificar los tipos de métricas de gran volumen. El tipo de métrica es la string en la vista de
tabla que comienza con
prometheus.googleapis.com/. Para obtener más información, consulta Identifica métricas de gran volumen. - Agrega un filtro para el tipo de métrica en el campo Filtros para restringir los datos del gráfico al tipo de métrica identificado. Por ejemplo:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - En el campo Agregación, selecciona
sum. - En el campo por, selecciona las siguientes etiquetas:
attribution_dimensionattribution_id
- En el campo Filtro, usa
attribution_dimension = namespace.
- Identifica el tipo de métrica de la métrica de gran volumen mediante uno de los otros ejemplos para identificar los tipos de métricas de gran volumen. El tipo de métrica es la string en la vista de
tabla que comienza con
- Para ver la transferencia por región Google Cloud , agrega la etiqueta
locational campo por. - Para ver la transferencia por proyecto de Google Cloud , agrega la etiqueta
resource_containeral campo por.
- Para correlacionar el volumen de transferencia general con los espacios de nombres, haz lo siguiente:
- En la Métrica verifica que estén seleccionados los recursos y la métrica siguientes: