Questa pagina descrive come utilizzare il recupero point-in-time (PITR) per conservare e recuperare i dati in Spanner per i database con dialetto GoogleSQL e PostgreSQL.
Per scoprire di più, consulta Recupero point-in-time.
Prerequisiti
Questa guida utilizza il database e lo schema definiti nella guida rapida di Spanner. Puoi seguire la guida rapida per creare il database e lo schema oppure modificare i comandi per utilizzarli con il tuo database.
Imposta il periodo di conservazione
Per impostare il periodo di conservazione del database:
Console
Vai alla pagina Istanze Spanner nella consoleGoogle Cloud .
Fai clic sull'istanza contenente il database per aprire la pagina Panoramica.
Fai clic sul database per aprire la relativa pagina Panoramica.
Seleziona la scheda Backup/Ripristino.

Fai clic sull'icona a forma di matita nel campo Periodo di conservazione delle versioni.
Inserisci una quantità e un'unità di tempo per il periodo di conservazione, quindi fai clic su Aggiorna.
gcloud
Aggiorna lo schema del database con l'istruzione ALTER DATABASE. Ad esempio:
gcloud spanner databases ddl update example-db \
--instance=test-instance \
--ddl='ALTER DATABASE `example-db` \
SET OPTIONS (version_retention_period="7d");'Per visualizzare il periodo di conservazione, recupera il DDL del database:
gcloud spanner databases ddl describe example-db \
--instance=test-instanceEcco l'output:
ALTER DATABASE example-db SET OPTIONS (
version_retention_period = '7d'
);
...
Librerie client
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Note sull'utilizzo:
- Il periodo di conservazione deve essere compreso tra 1 ora e 7 giorni e può essere specificato
in giorni, ore, minuti o secondi. Ad esempio, i valori
1d,24h,1440me86400ssono equivalenti. - Se hai abilitato la registrazione per l'API Spanner nel tuo progetto, l'evento viene registrato come UpdateDatabaseDdl ed è visibile in Logs Explorer.
- Per ripristinare il periodo di conservazione predefinito di 1 ora, puoi impostare l'opzione di database
version_retention_periodsuNULLper i database GoogleSQL o suDEFAULTper i database PostgreSQL. - Quando estendi il periodo di conservazione, il sistema non esegue il backfill delle versioni precedenti dei dati. Ad esempio, se estendi il periodo di conservazione da un'ora a 24 ore, devi attendere 23 ore affinché il sistema accumuli i dati precedenti prima di poter recuperare i dati di 24 ore prima.
Ottenere il periodo di conservazione e l'ora della prima versione
La risorsa Database include due campi:
version_retention_period: il periodo in cui Spanner conserva tutte le versioni dei dati per il database.earliest_version_time: il timestamp più recente in cui è possibile leggere le versioni precedenti dei dati dal database. Questo valore viene aggiornato continuamente da Spanner e diventa obsoleto nel momento in cui viene eseguita una query. Se utilizzi questo valore per recuperare i dati, assicurati di tenere conto del tempo che intercorre tra il momento in cui viene eseguita la query sul valore e il momento in cui avvii il recupero.
Console
Vai alla pagina Istanze Spanner nella console Google Cloud .
Fai clic sull'istanza contenente il database per aprire la pagina Panoramica.
Fai clic sul database per aprire la relativa pagina Panoramica.
Seleziona la scheda Backup/Ripristino per aprire la pagina Backup/Ripristino e visualizzare il periodo di conservazione.
Fai clic su Crea per aprire la pagina Crea un backup e visualizzare l'ora della versione meno recente.
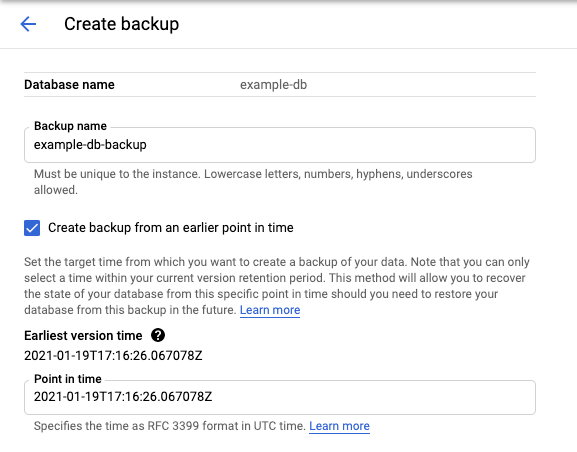
gcloud
Puoi ottenere questi campi chiamando describe databases o list databases. Ad esempio:
gcloud spanner databases describe example-db \
--instance=test-instanceEcco l'output:
createTime: '2020-09-07T16:56:08.285140Z'
earliestVersionTime: '2020-10-07T16:56:08.285140Z'
name: projects/my-project/instances/test-instance/databases/example-db
state: READY
versionRetentionPeriod: 3d
Recuperare una parte del database
Esegui una lettura obsoleta e specifica il timestamp di recupero necessario. Assicurati che il timestamp che specifichi sia più recente di
earliest_version_time.del database.gcloud
Utilizza execute-sql Ad esempio:
gcloud spanner databases execute-sql example-db \ --instance=test-instance --read-timestamp=2020-09-11T10:19:36.010459-07:00\ --sql='SELECT * FROM SINGERS'Librerie client
Consulta Eseguire una lettura obsoleta.
Memorizza i risultati della query. Questo è necessario perché non puoi riscrivere i risultati della query nel database nella stessa transazione. Per piccole quantità di dati, puoi stampare sulla console o archiviare in memoria. Per quantità di dati maggiori, potrebbe essere necessario scrivere in un file locale.
Scrivi i dati recuperati nella tabella che deve essere recuperata. Ad esempio:
gcloud
gcloud spanner rows update --instance=test-instance --database=example-db --table=Singers \ --data=SingerId=1,FirstName='Marc'Per saperne di più, consulta la sezione Aggiornare i dati utilizzando gcloud.
Librerie client
Per saperne di più, consulta Aggiornamento dei dati mediante DML o Aggiornamento dei dati mediante mutazioni.
Se vuoi eseguire un'analisi sui dati recuperati prima di riscriverli, puoi creare manualmente una tabella temporanea nello stesso database, scrivere prima i dati recuperati in questa tabella temporanea, eseguire l'analisi e poi leggere i dati che vuoi recuperare da questa tabella temporanea e scriverli nella tabella da recuperare.
Recuperare un intero database
Puoi recuperare l'intero database utilizzando Backup e ripristino o Importa ed esporta e specificando un timestamp di recupero.
Backup e ripristino
Crea un backup e imposta
version_timesul timestamp di ripristino necessario.Console
Vai alla pagina Dettagli database nella console Cloud.
Nella scheda Backup/Ripristino, fai clic su Crea.
Seleziona la casella Crea backup da un point-in-time precedente.
gcloud
gcloud spanner backups create example-db-backup-1 \ --instance=test-instance \ --database=example-db \ --retention-period=1y \ --version-time=2021-01-22T01:10:35Z --asyncPer saperne di più, consulta Creare un backup utilizzando gcloud.
Librerie client
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Esegui il ripristino dal backup in un nuovo database. Tieni presente che Spanner mantiene l'impostazione del periodo di conservazione dal backup al database ripristinato.
Console
Vai alla pagina Dettagli istanza nella console Cloud.
Nella scheda Backup/Ripristino, seleziona un backup e fai clic su Ripristina.
gcloud
gcloud spanner databases restore --async \ --destination-instance=destination-instance --destination-database=example-db-restored \ --source-instance=test-instance --source-backup=example-db-backup-1Per ulteriori informazioni, vedi Ripristinare un database da un backup.
Librerie client
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Importazione ed esportazione
- Esporta il database specificando il parametro
snapshotTimecon il timestamp di recupero necessario.Console
Vai alla pagina Dettagli istanza nella console Cloud.
Nella scheda Importa/Esporta, fai clic su Esporta.
Seleziona la casella Esporta database da un point-in-time precedente.
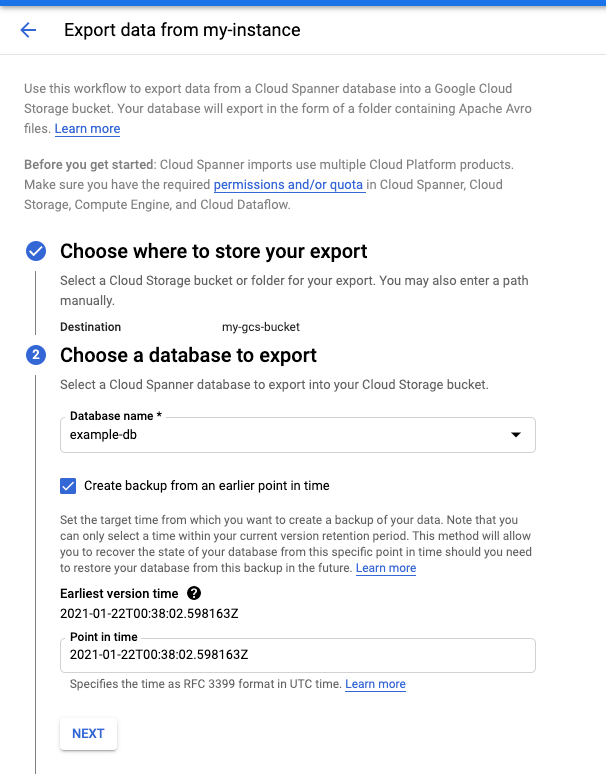
Per istruzioni dettagliate, vedi Esportare un database.
gcloud
Utilizza il modello Dataflow Spanner to Avro per esportare il database.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/export/templates/Cloud_Spanner_to_GCS_Avro' --region=DATAFLOW_REGION \ --parameters='instanceId=test-instance,databaseId=example-db,outputDir=YOUR_GCS_DIRECTORY,snapshotTime=2020-09-01T23:59:40.125245Z'Note sull'utilizzo:
- Puoi monitorare l'avanzamento dei job di importazione ed esportazione nella console Dataflow.
- Spanner garantisce che i dati esportati siano coerenti esternamente e dal punto di vista transazionale al timestamp specificato.
- Specifica il timestamp nel formato RFC 3339. Ad esempio, 2020-09-01T23:59:30.234233Z.
- Assicurati che il timestamp specificato sia più recente di
earliest_version_timedel database. Se i dati non esistono più al timestamp specificato, viene visualizzato un errore.
Importa in un nuovo database.
Console
Vai alla pagina Dettagli istanza nella console Cloud.
Nella scheda Importa/Esporta, fai clic su Importa.
Per istruzioni dettagliate, vedi Importazione di file Avro Spanner.
gcloud
Utilizza il modello Dataflow Avro di Cloud Storage in Spanner per importare i file Avro.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/import/templates/GCS_Avro_to_Cloud_Spanner' \ --region=DATAFLOW_REGION \ --staging-location=YOUR_GCS_STAGING_LOCATION \ --parameters='instanceId=test-instance,databaseId=example-db,inputDir=YOUR_GCS_DIRECTORY'
Stimare l'aumento dello spazio di archiviazione
Prima di aumentare il periodo di conservazione delle versioni di un database, puoi stimare l'aumento previsto dell'utilizzo dello spazio di archiviazione del database sommando i byte delle transazioni per il periodo di tempo necessario. Ad esempio, la seguente query calcola il numero di GiB scritti negli ultimi 7 giorni (168 ore) leggendo dalle tabelle delle statistiche sulle transazioni.
GoogleSQL
SELECT
SUM(bytes_per_hour) / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168);
PostgreSQL
SELECT
bph / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
SUM(bytes_per_hour) as bph
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168)
sub1) sub2;
Tieni presente che la query fornisce una stima approssimativa e può essere imprecisa per alcuni motivi:
- La query non tiene conto del timestamp che deve essere memorizzato per ogni versione dei dati precedenti. Se il database è costituito da molti tipi di dati di piccole dimensioni, la query potrebbe sottostimare l'aumento dello spazio di archiviazione.
- La query include tutte le operazioni di scrittura, ma solo le operazioni di aggiornamento creano versioni precedenti dei dati. Se il tuo carico di lavoro include molte operazioni di inserimento, la query potrebbe sovrastimare l'aumento dello spazio di archiviazione.