查詢計畫視覺化工具可讓您快速瞭解 Spanner 為評估查詢而選擇的查詢計畫結構,本指南說明如何使用查詢計畫,瞭解查詢的執行情況。
事前準備
如要熟悉本指南中提及的 Google Cloud 控制台使用者介面,請參閱下列內容:
在 Google Cloud 控制台中執行查詢
- 前往 Google Cloud 控制台的 Spanner「Instances」(執行個體) 頁面。
-
選取包含要查詢資料庫的執行個體名稱。
Google Cloud 主控台會顯示執行個體的「總覽」頁面。
-
選取要查詢的資料庫名稱。
Google Cloud 控制台會顯示資料庫的「總覽」頁面。
-
在側邊選單中,按一下「Spanner Studio」。
Google Cloud 控制台會顯示資料庫的「Spanner Studio」頁面。
- 在編輯器窗格中輸入 SQL 查詢。
-
按一下「Run」(執行)。
Spanner 會執行查詢。
- 按一下「說明」分頁標籤,即可查看查詢計畫的視覺化呈現方式。
查詢編輯器導覽
Spanner Studio 頁面提供查詢分頁,可供您輸入或貼上 SQL 查詢和 DML 陳述式,針對資料庫執行這些陳述式,並查看結果和查詢執行計畫。下方的螢幕截圖標示了 Spanner Studio 頁面的主要元件。
- 分頁列會顯示已開啟的查詢分頁。如要建立新分頁,請按一下「新分頁」。
分頁列也會提供查詢範本清單,您可以貼上查詢,深入瞭解資料庫查詢、交易、讀取作業等,詳情請參閱「內省工具總覽」。
- 編輯器指令列提供下列選項:
- 執行指令會執行編輯窗格中輸入的陳述式,並在「結果」分頁中產生查詢結果,在「說明」分頁中產生查詢執行計畫。使用下拉式選單變更預設行為,只產生結果或說明。
在編輯器中醒目顯示內容時,「執行」指令會變更為「執行所選項目」,讓您只執行所選內容。
- 「清除查詢」指令會刪除編輯器中的所有文字,並清除「結果」和「說明」子分頁。
- 「格式化查詢」指令會格式化編輯器中的陳述式,方便您閱讀。
- 「快速鍵」指令會顯示您可以在編輯器中使用的鍵盤快速鍵組合。
- 點選「SQL 查詢說明」連結後,瀏覽器分頁會開啟 SQL 查詢語法說明文件。
在編輯器中更新查詢時,系統會自動驗證查詢。如果陳述式有效,編輯器指令列會顯示確認勾號和「有效」訊息。如有任何問題,系統會顯示錯誤訊息和詳細資料。
- 執行指令會執行編輯窗格中輸入的陳述式,並在「結果」分頁中產生查詢結果,在「說明」分頁中產生查詢執行計畫。使用下拉式選單變更預設行為,只產生結果或說明。
- 您可以在編輯器中輸入 SQL 查詢和 DML 陳述式。
系統會自動為多行陳述式加上行號,並以顏色區分。
如果在編輯器中輸入多個陳述式,除了最後一個陳述式外,每個陳述式後方都必須使用終止分號。
- 查詢分頁的底部窗格提供三個子分頁:
- 「結構定義」子分頁會顯示資料庫中的資料表及其結構定義。在編輯器中撰寫陳述式時,可快速參考這份文件。
- 在編輯器中執行陳述式時,「結果」子分頁會顯示結果。如果是查詢,系統會顯示結果表格;如果是
INSERT和 >UPDATE等 DML 陳述式,系統會顯示受影響的資料列數。 - 「說明」子分頁會顯示您在編輯器中執行陳述式時建立的查詢計畫視覺化圖表。
- 「結果」和「說明」子分頁都提供陳述式選取器,可供您選擇要查看哪個陳述式的結果或查詢計畫。
查看取樣的查詢計畫
- 前往 Google Cloud 控制台的 Spanner「Instances」(執行個體) 頁面。
-
按一下要調查查詢的執行個體名稱。
Google Cloud 主控台會顯示執行個體的「總覽」頁面。
-
在「Navigation」(導覽) 選單的「Observability」(可觀測性) 標題下方,按一下「Query insights」(查詢洞察)。
Google Cloud 控制台會顯示執行個體的「查詢洞察」頁面。
-
在「資料庫」下拉式選單中,選取要調查的查詢所在的資料庫。
Google Cloud 控制台會顯示資料庫的查詢負載資訊。TopN 查詢和標記表格會顯示依 CPU 使用率排序的熱門查詢和要求標記清單。
-
找出 CPU 使用率高的查詢,然後點選該查詢的「FPRINT」值,即可查看取樣查詢計畫。
「查詢詳細資料」頁面會顯示查詢的「查詢計畫範例」圖表。你最多可以縮小至目前時間的前七天。 注意:如果查詢使用從 PartitionQuery API 取得的 partitionTokens,以及分區 DML 查詢,則不支援查詢計畫。
-
按一下圖表中的任一點,即可查看較舊的查詢計畫,並以視覺化的方式瞭解查詢執行期間採取的步驟。您也可以點選任一運算子,查看運算子的詳細資訊。
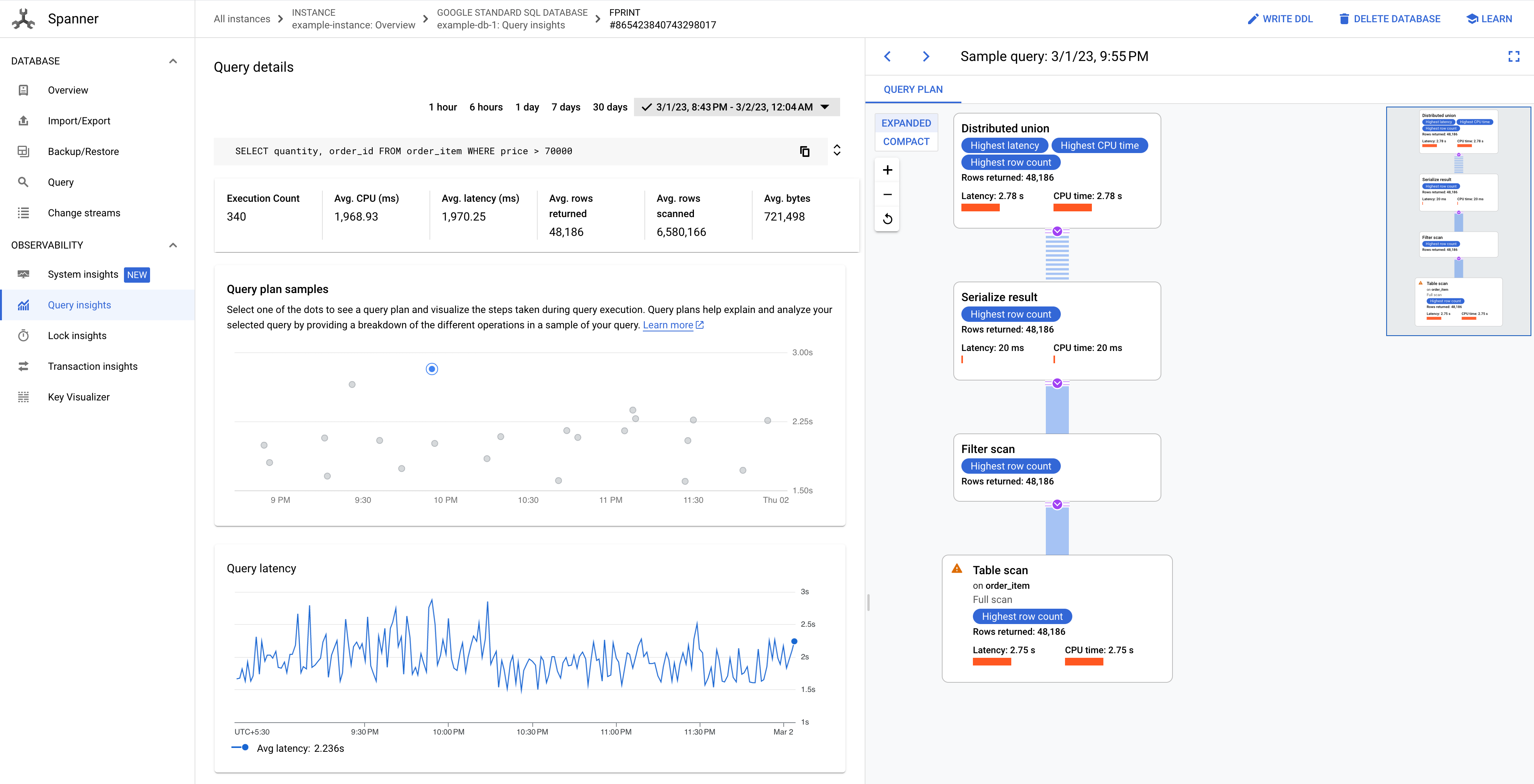
圖 8. 查詢計畫範例圖表。
在某些情況下,您可能想查看查詢計畫樣本,並比較查詢在不同時間的成效。對於耗用較多 CPU 的查詢,Spanner 會在 Google Cloud 控制台的「查詢洞察」頁面上,保留取樣的查詢計畫 30 天。如要查看取樣的查詢計畫,請按照下列步驟操作:
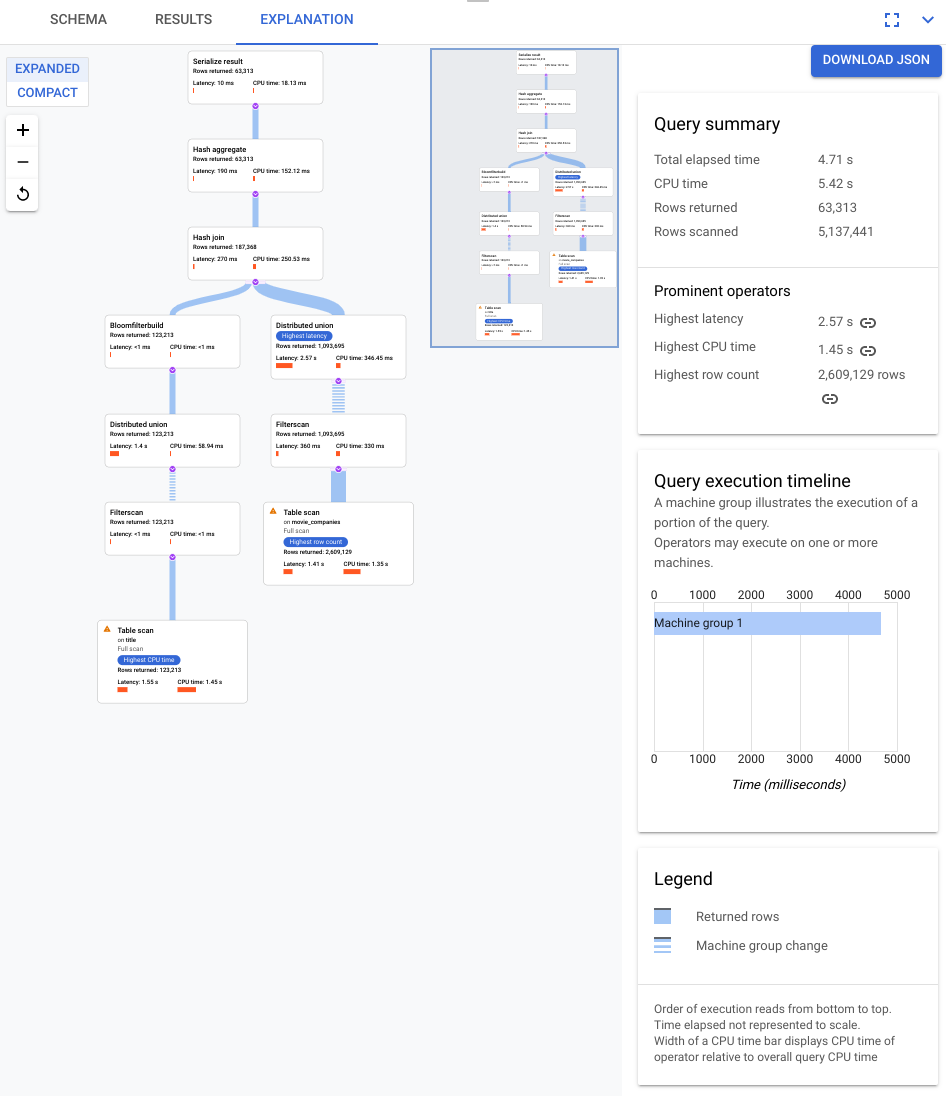
查詢計畫視覺化工具導覽
下方的螢幕截圖標示了視覺化工具的主要元件,並提供詳細說明。在查詢分頁中執行查詢後,選取查詢編輯器下方的「EXPLANATION」分頁,即可開啟查詢執行計畫視覺化工具。
下圖的資料流程是從底部到頂部,也就是所有表格和索引都在圖表底部,最終輸出則在頂部。
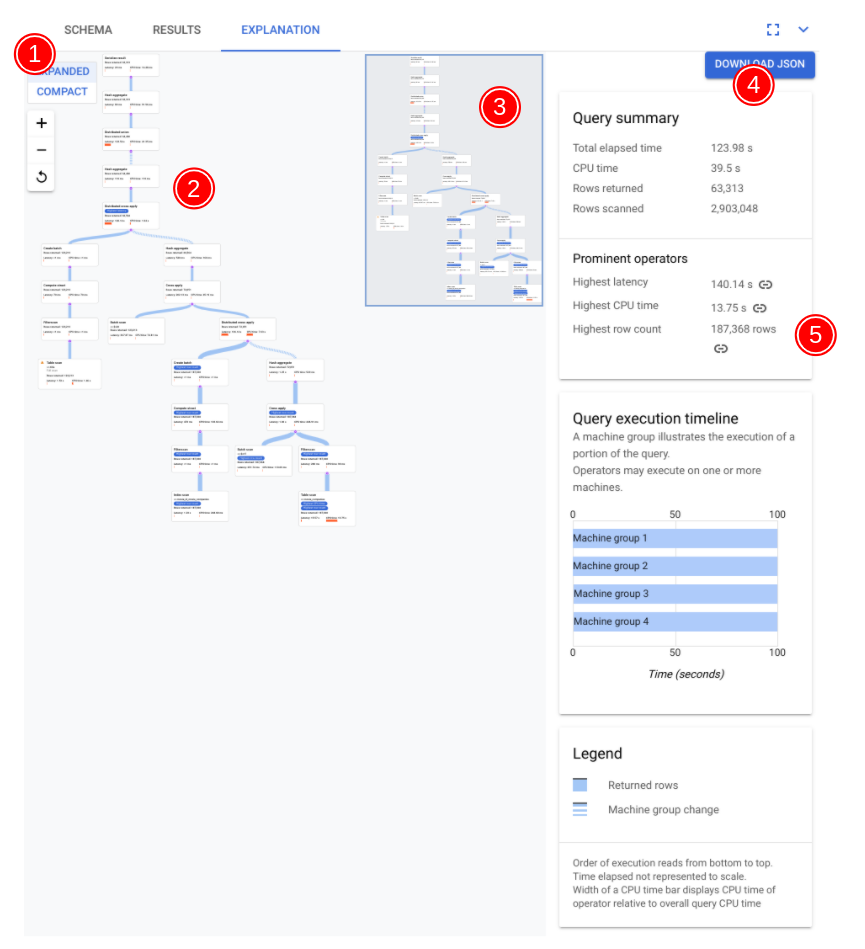
- 視您執行的查詢而定,計畫的視覺化呈現內容可能會很大。如要隱藏及顯示詳細資料,請切換「展開/精簡」檢視畫面選取器。你可以使用縮放控制項,自訂一次要查看多少計畫內容。
- 說明 Spanner 如何執行查詢的代數會繪製為非循環圖,其中每個節點都對應至一個疊代器,該疊代器會從輸入內容取用資料列,並將資料列產生至其父項。圖 9 顯示範例計畫。按一下圖表,即可查看方案詳細資料的展開檢視畫面。
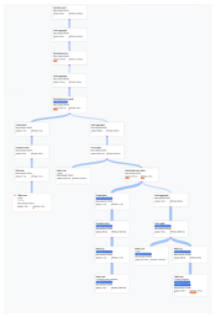
圖 9. 視覺化計畫範例 (按一下可放大)。 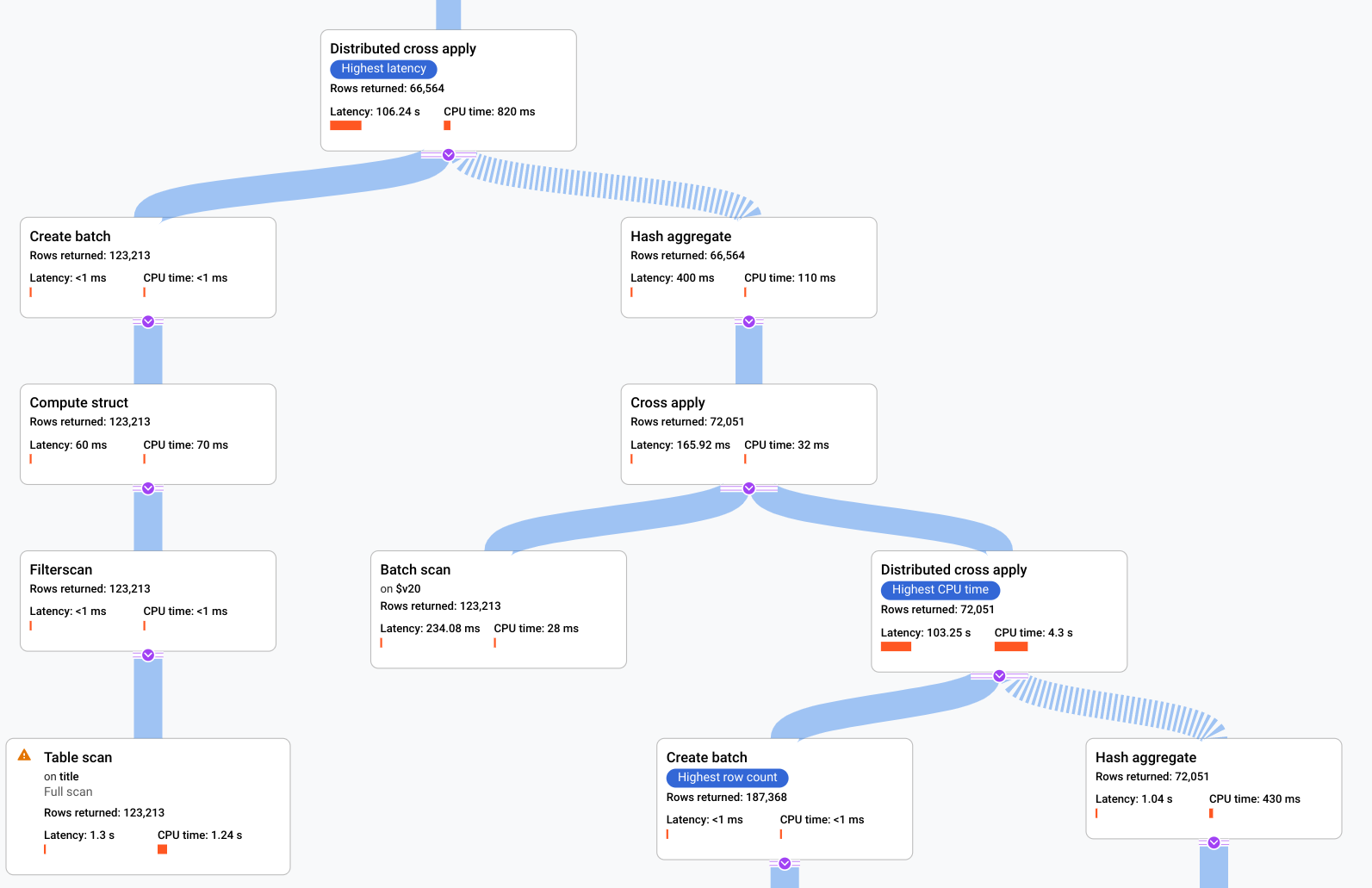
圖表中的每個節點 (或資訊卡) 都代表一個疊代器,並包含下列資訊:
- 疊代器名稱。疊代器會從輸入取用資料列,並產生資料列。
- 執行階段統計資料,包括傳回的資料列數、延遲時間和 CPU 用量。
- 我們提供下列視覺提示,協助您找出查詢執行計畫中的潛在問題。
- 節點中的紅色長條是視覺指標,代表這個疊代器的延遲或 CPU 作業時間,相較於查詢總計所占的百分比。
- 連接各節點的線條粗細代表列數。線條越粗,傳遞至下一個節點的資料列數量就越多。實際列數會顯示在每張資訊卡中,以及您將指標懸停在連接器上時。
- 如果節點執行完整資料表掃描,就會顯示警告三角形。資訊面板中的詳細資料包括建議,例如新增索引,或盡可能以其他方式修訂查詢或結構定義,以避免完整掃描。
- 選取方案中的資訊卡,即可在右側的資訊面板中查看詳細資料 (5)。
- 執行計畫小導覽圖會顯示完整計畫的縮小檢視畫面,有助於判斷執行計畫的整體形狀,以及快速導覽至計畫的不同部分。直接在迷你地圖上拖曳,或點選要聚焦的位置,即可前往視覺化計畫的其他部分。
選取「下載 JSON」,下載執行計畫的 JSON 版本,這有助於排解問題。 您也可以在與 Spanner 團隊聯絡以尋求支援時,分享這項資訊。 儲存 JSON 不會儲存查詢結果。
如要下載並儲存執行計畫的 JSON 版本,以便日後查看:
- 在 Spanner Studio 中執行查詢。
- 選取「說明」分頁標籤。
- 按一下「下載 JSON」,即可下載執行計畫的 JSON 版本。
- 儲存並複製 JSON 檔案的內容。
- 開啟新的查詢編輯器分頁。
- 在編輯器分頁中輸入:
PROTO: CONTENT_OF_JSON
- 按一下「執行」。
- 選取查詢編輯器下方的「說明」分頁標籤,即可查看下載的執行計畫。
- 資訊面板會顯示查詢計畫圖中,所選節點的詳細脈絡資訊。這些資訊會依下列類別分類。
- 「迭代器資訊」會提供您在圖表中選取的迭代器資訊卡詳細資料,以及執行階段統計資料。
- 「查詢摘要」會提供詳細資料,包括傳回的資料列數和執行查詢所花的時間。顯著運算子是指延遲時間較長、相較於其他運算子耗用大量 CPU,以及傳回大量資料列的運算子。
- 查詢執行時間軸是以時間為準的圖表,顯示每個機器群組執行部分查詢的時間長度。機器群組不一定會在查詢的整個執行時間內運作。此外,機器群組可能在查詢執行期間多次執行,但這裡的時間軸只會顯示第一次執行的開始時間和最後一次執行的結束時間。
調整效能不佳的查詢
假設貴公司經營線上電影資料庫,其中包含電影資訊,例如演員、製作公司、電影詳細資料等。這項服務在 Spanner 上執行,但最近發生一些效能問題。
您是這項服務的主要開發人員,因此需要調查這些效能問題,因為這些問題導致服務評分不佳。開啟 Google Cloud 控制台,前往資料庫執行個體,然後開啟查詢編輯器。在編輯器中輸入並執行以下查詢。
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
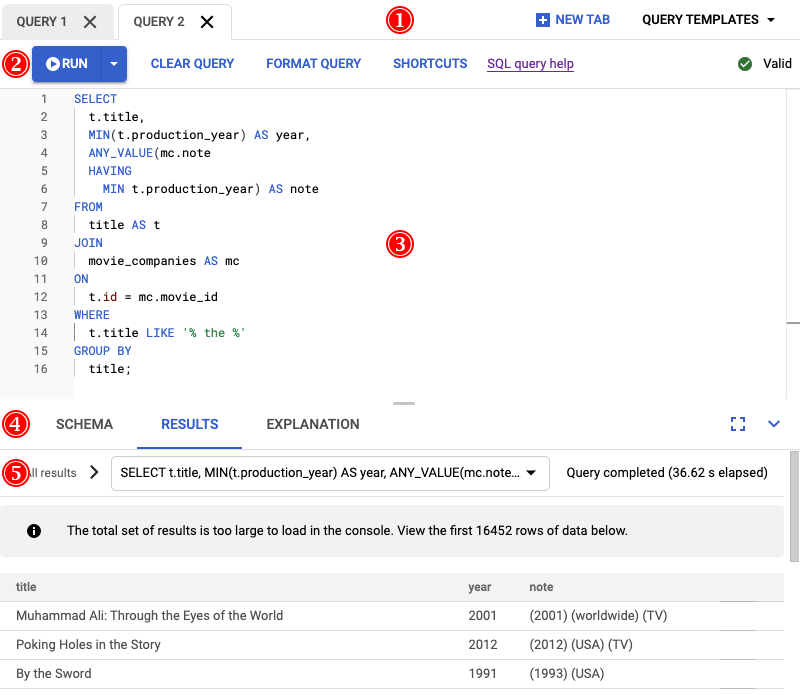
執行這項查詢的結果如下列螢幕截圖所示。我們在編輯器中選取「FORMAT QUERY」(格式化查詢),畫面右上角也有附註,說明查詢有效。
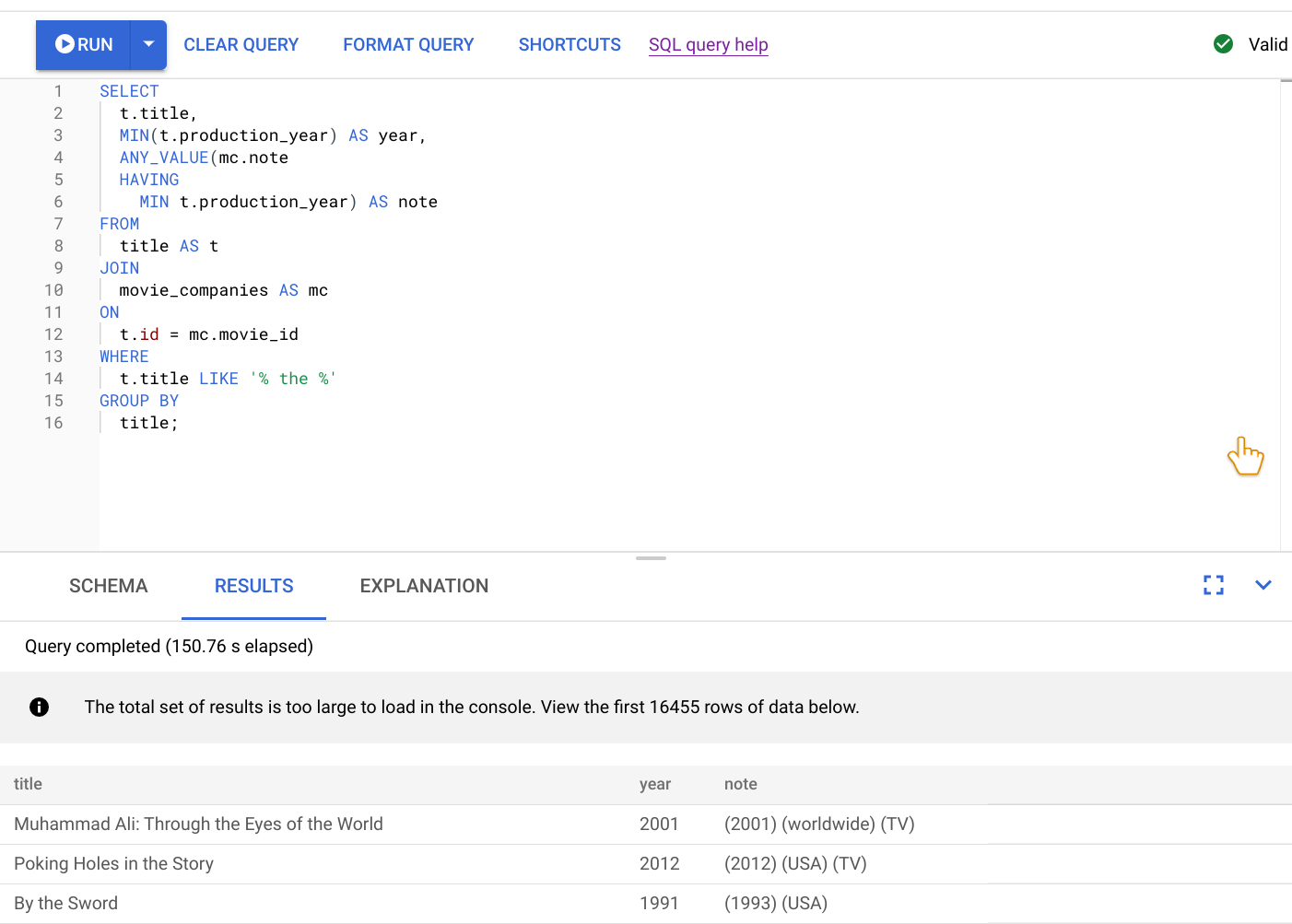
查詢編輯器下方的「結果」分頁會顯示查詢完成時間,大約是兩分鐘多一點。您決定進一步查看查詢,瞭解查詢是否有效率。
使用查詢計畫視覺化工具分析執行速度緩慢的查詢
此時我們知道上一個步驟中的查詢需要兩分鐘以上,但不知道查詢是否盡可能有效率,因此不確定這個時間長度是否符合預期。
選取查詢編輯器下方的「EXPLANATION」(說明) 分頁,即可查看 Spanner 建立的執行計畫,瞭解執行查詢及傳回結果的過程。
下圖顯示的計畫相對較大,但即使在這個縮放層級,您也可以觀察到下列事項。
根據右側資訊面板中的「查詢摘要」,我們得知系統掃描了近 300 萬個資料列,但最終只傳回不到 64, 000 個資料列。
從「查詢執行時間軸」面板中,我們也可以看到查詢涉及 4 個機器群組。機器群組負責執行部分查詢。運算子可以在一或多部機器中運作。在時間軸中選取機器群組,即可在視覺化計畫中醒目顯示該群組執行的查詢部分。
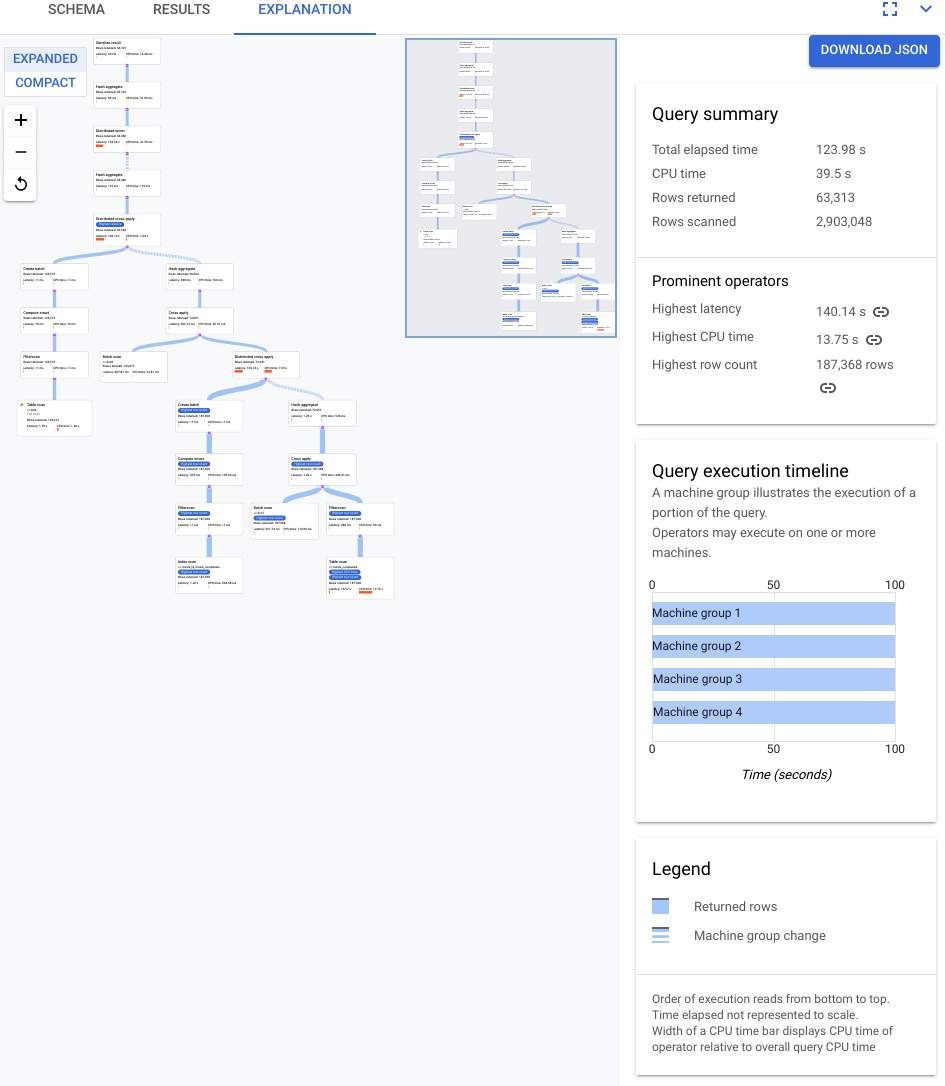
基於上述因素,您認為將 Spanner 預設選擇的聯結從套用聯結變更為雜湊聯結,或許能提升效能。
改善查詢
如要提升查詢效能,請使用聯結提示將聯結方法變更為雜湊聯結。這項聯結實作項目會執行以集合為基礎的處理程序。
更新後的查詢如下:
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
下圖說明更新後的查詢。如螢幕截圖所示,查詢在 5 秒內完成,相較於這項變更前的 120 秒執行時間,大幅提升了效能。
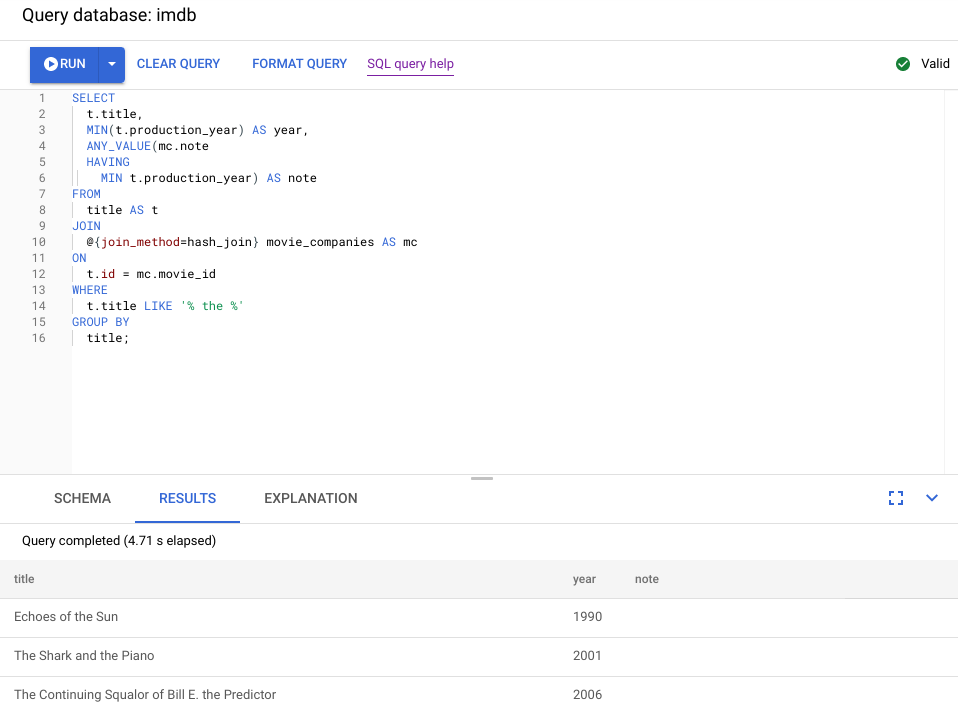
請查看下圖所示的新視覺化計畫,瞭解這項改善措施的影響。
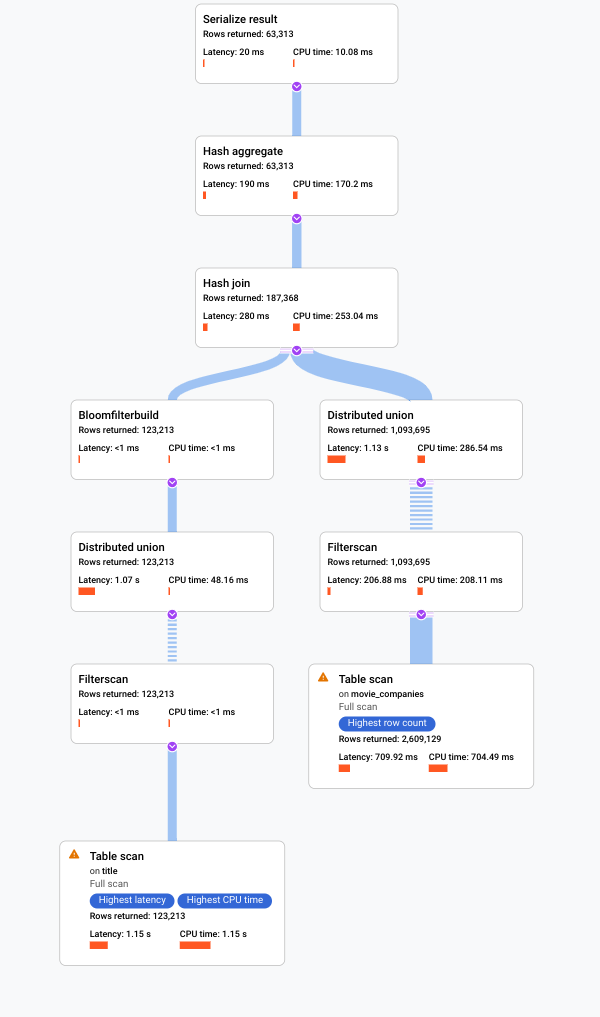
您會立即發現幾項差異:
這項查詢執行作業只涉及一個機器群組。
匯總數量大幅減少。
結論
在這個情境中,我們執行了緩慢的查詢,並查看其視覺化計畫,找出效率不彰之處。以下是變更前後的查詢和方案摘要。每個分頁都會顯示執行的查詢,以及完整查詢執行計畫的精簡檢視畫面。
使用前
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
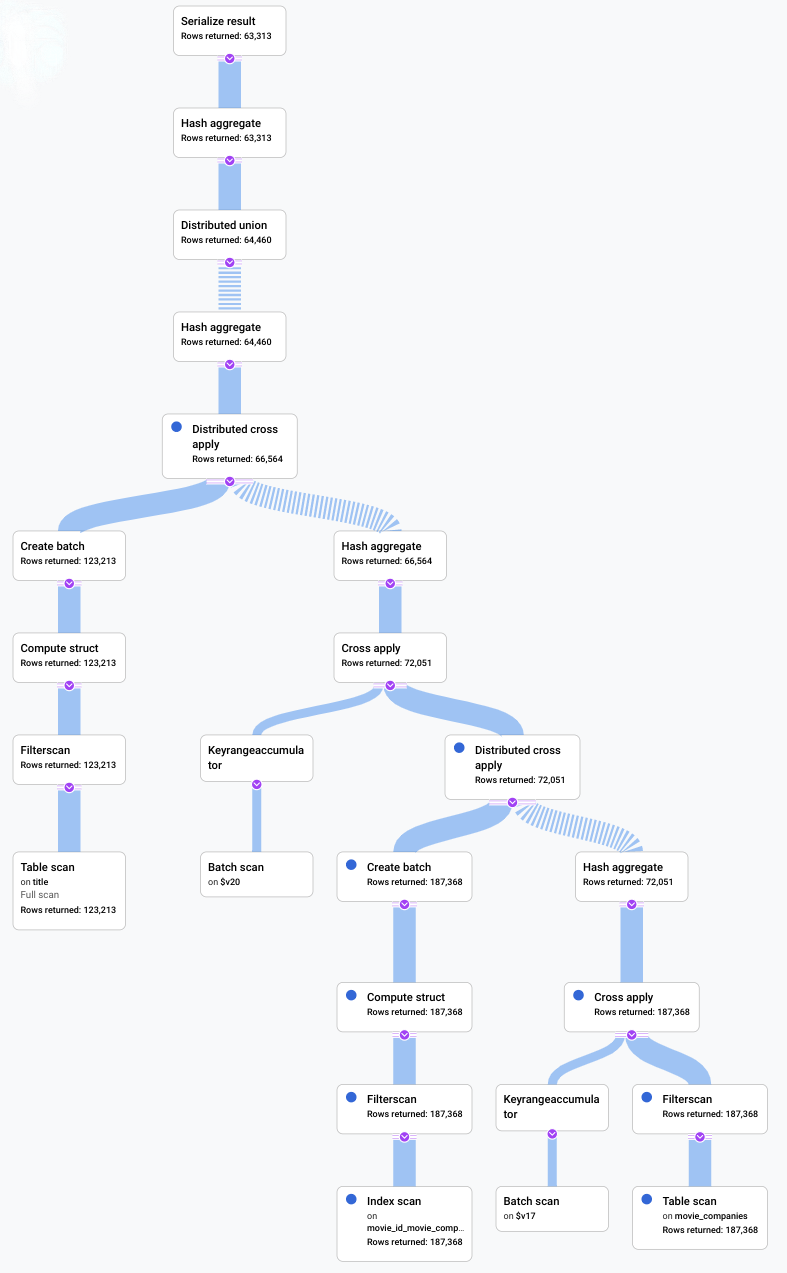
完成後
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
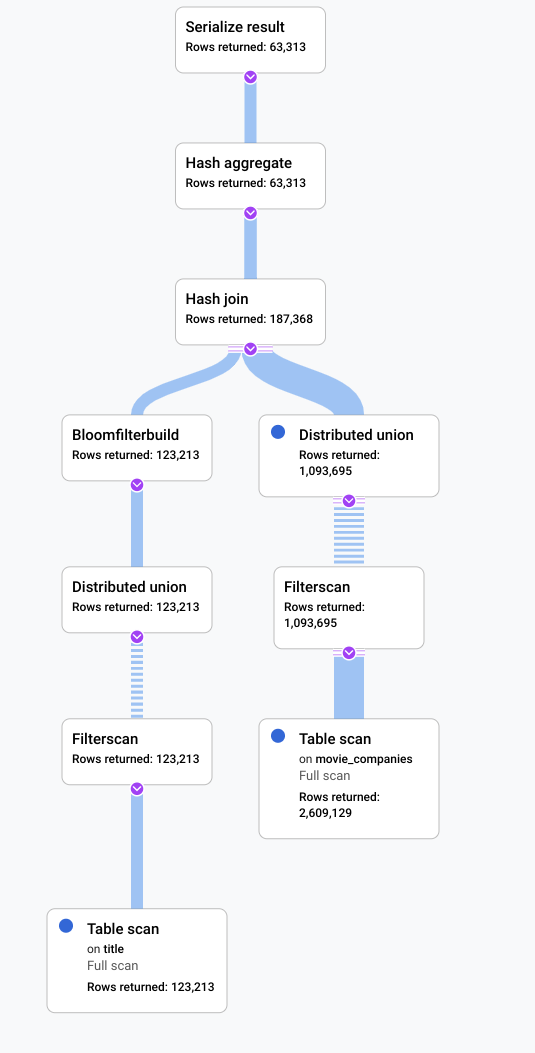
在此情境中,有大量資料列來自 title 資料表,且符合 LIKE
'% the %' 篩選條件,這項指標顯示可能需要改善。如果另一個表格的資料列數量龐大,搜尋作業的成本可能很高。將聯結實作方式改為雜湊聯結後,效能大幅提升。