Quando utilizzi query SQL per cercare i dati, Spanner utilizza automaticamente tutti gli indici secondari che possono contribuire a recuperare i dati in modo più efficiente. In alcuni casi, però, Spanner potrebbe scegliere un indice che rallenta le query. Di conseguenza, potresti notare che alcune query vengono eseguite più lentamente rispetto al passato.
Questa pagina spiega come rilevare le variazioni nella velocità di esecuzione delle query, ispezionare il piano di esecuzione delle query per queste query e, se necessario, specificare un indice diverso per le query future.
Rilevare le modifiche alla velocità di esecuzione delle query
È più probabile che si verifichi una variazione nella velocità di esecuzione delle query dopo aver apportato una di queste modifiche:
- Modifica significativa di una grande quantità di dati esistenti che hanno un indice secondario.
- Aggiunta, modifica o eliminazione di un indice secondario.
Puoi utilizzare diversi strumenti per identificare una query specifica che Spanner sta eseguendo più lentamente del solito:
- Query Insights e Statistiche sulle query.
Metriche specifiche per le applicazioni che acquisisci e analizzi con Cloud Monitoring. Ad esempio, puoi monitorare la metrica Conteggio query per determinare il numero di query in un'istanza nel tempo e scoprire quale versione dell'ottimizzatore delle query è stata utilizzata per eseguire una query.
Strumenti di monitoraggio lato client che misurano le prestazioni dell'applicazione.
Una nota sui nuovi database
Quando esegui query su database appena creati con dati appena inseriti o importati, Spanner potrebbe non selezionare gli indici più appropriati, perché l'optimizzatore delle query impiega fino a tre giorni per raccogliere automaticamente le statistiche dell'ottimizzatore. Per ottimizzare l'utilizzo dell'indice di un nuovo database Spanner prima di questo periodo, puoi creare manualmente un nuovo pacchetto di statistiche.
Rivedi lo schema
Dopo aver trovato la query che ha rallentato, esamina l'istruzione SQL per la query e identifica le tabelle utilizzate dall'istruzione e le colonne recuperate da queste tabelle.
Successivamente, trova gli indici secondari esistenti per queste tabelle. Determina se uno degli indici include le colonne su cui stai eseguendo la query, il che significa che Spanner potrebbe utilizzare uno degli indici per elaborare la query.
- Se sono presenti indici applicabili, il passaggio successivo consiste nel trovare l'indice utilizzato da Spanner per la query.
Se non sono presenti indici applicabili, utilizza il comando
gcloud spanner operations listper verificare se di recente hai eliminato un indice applicabile:gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"Se hai eliminato un indice applicabile, la modifica potrebbe aver influito sul rendimento delle query. Aggiungi di nuovo l'indice secondario alla tabella. Dopo che Spanner ha aggiunto l'indice, esegui di nuovo la query e controlla le relative prestazioni. Se le prestazioni non migliorano, il passaggio successivo consiste nel trovare l'indice utilizzato da Spanner per la query.
Se non hai eliminato un indice applicabile, la selezione dell'indice non ha comportato un calo del rendimento delle query. Cerca altre modifiche ai tuoi dati o ai pattern di utilizzo che potrebbero aver influito sul rendimento.
Trovare l'indice utilizzato per una query
Per scoprire quale indice viene utilizzato da Spanner per elaborare una query, visualizza il piano di esecuzione query nella Google Cloud console:
Vai alla pagina Istanze di Spanner nella Google Cloud console.
Fai clic sul nome dell'istanza su cui vuoi eseguire una query.
Nel riquadro a sinistra, fai clic sul database su cui vuoi eseguire una query, poi su Spanner Studio.
Inserisci la query da testare.
Nell'elenco a discesa Esegui query, seleziona Solo spiegazione. Spanner mostra il piano di query.
Cerca almeno uno dei seguenti operatori nel piano di query:
- Scansione tabella
- Scansione dell'indice
- Cross Apply o Distributed Cross Apply
Le sezioni seguenti spiegano il significato di ciascun operatore.
Operatore di scansione della tabella
L'operatore scansione tabella indica che Spanner non ha utilizzato un indice secondario:
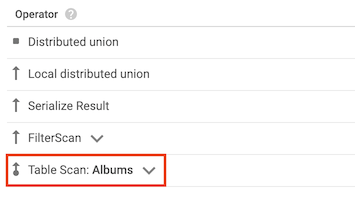
Ad esempio, supponiamo che la tabella Albums non abbia indici secondari e che tu esegua la seguente query:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
Poiché non sono disponibili indici da utilizzare, il piano di query include un operatore di scansione della tabella.
Operatore di scansione dell'indice
L'operatore scansione degli indici indica che Spanner ha utilizzato un indice secondario durante l'elaborazione della query:
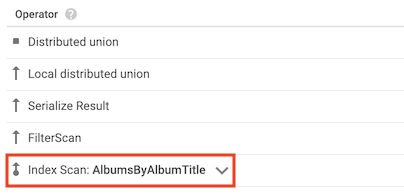
Ad esempio, supponiamo di aggiungere un indice alla tabella Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Quindi, esegui la seguente query:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
L'indice AlbumsByAlbumTitle contiene AlbumTitle, che è l'unica colonna selezionata dalla query. Di conseguenza, il piano di query include un operatore di scansione dell'indice.
Operatore di applicazione incrociata
In alcuni casi, Spanner utilizza un indice che contiene solo alcune delle colonne selezionate dalla query. Di conseguenza, Spanner deve unire l'indice con la tabella di base.
Quando si verifica questo tipo di join, il piano di query include un operatore join distribuito o join distribuito con i seguenti input:
- Un operatore di scansione dell'indice per l'indice di una tabella
- Un operatore di scansione della tabella per la tabella proprietaria dell'indice
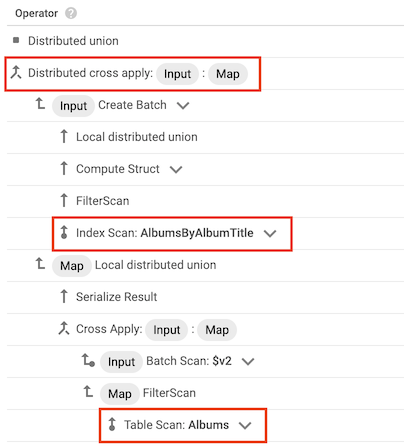
Ad esempio, supponiamo di aggiungere un indice alla tabella Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Quindi, esegui la seguente query:
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
L'indice AlbumsByAlbumTitle contiene AlbumTitle, ma la query seleziona tutte le colonne della tabella, non solo AlbumTitle. Di conseguenza, il piano di query include un operatore Outer Apply distribuito, con una scansione dell'indice di AlbumsByAlbumTitle e una scansione della tabella di Albums come input.
Scegli un altro indice
Dopo aver trovato l'indice utilizzato da Spanner per la query, prova a eseguire la query con un indice diverso o eseguendo la scansione della tabella di base anziché utilizzare un indice. Per specificare l'indice, aggiungi una direttiva FORCE_INDEX alla query.
Se trovi una versione più rapida della query, aggiorna l'applicazione in modo da utilizzarla.
Linee guida per la scelta di un indice
Segui queste linee guida per decidere quale indice testare per la query:
Se la query soddisfa uno di questi criteri, prova a utilizzare la tabella di base anziché un indice secondario:
- La query verifica l'uguaglianza con un prefisso della chiave primaria della tabella di base (ad esempio
SELECT * FROM Albums WHERE SingerId = 1). - Un numero elevato di righe soddisfa i predicati della query (ad esempio
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title"). - La query utilizza una tabella di base contenente solo poche centinaia di righe.
- La query verifica l'uguaglianza con un prefisso della chiave primaria della tabella di base (ad esempio
Se la query contiene un predicato molto selettivo (ad esempio
REGEXP_CONTAINS,STARTS_WITH,<,<=,>,>=o!=), prova a utilizzare un indice che includa le stesse colonne utilizzate nel predicato.
Testa la query aggiornata
Utilizza la Google Cloud console per testare la query aggiornata e scoprire quanto tempo occorre per elaborarla.
Se la query include parametri di query e un parametro di query è associato ad alcuni valori molto più spesso di altri, associa il parametro di query a uno di questi valori nei test. Ad esempio, se la query include un predicato come WHERE country = @countryId e quasi tutte le query associano @countryId al valore US, associa @countryId a US per i test di prestazioni. Questo approccio ti consente di eseguire l'ottimizzazione in base alle query che esegui più di frequente.
Per testare la query aggiornata nella Google Cloud console, segui questi passaggi:
Vai alla pagina Istanze di Spanner nella Google Cloud console.
Fai clic sul nome dell'istanza su cui vuoi eseguire una query.
Nel riquadro a sinistra, fai clic sul database su cui vuoi eseguire una query, poi su Spanner Studio.
Inserisci la query da testare, inclusa la direttiva
FORCE_INDEX, e fai clic su Esegui query.La Google Cloud console apre la scheda Tabella dei risultati, poi mostra i risultati della query, incluso il tempo impiegato dal servizio Spanner per elaborare la query.
Questa metrica non include altre fonti di latenza, ad esempio il tempo impiegato dalla Google Cloud console per interpretare e visualizzare i risultati della query.
Ottenere il profilo dettagliato di una query in formato JSON utilizzando l'API REST
Per impostazione predefinita, quando esegui una query vengono restituiti solo i risultati dell'istruzione.
Questo perché QueryMode è impostato su NORMAL.
Per includere statistiche dettagliate sull'esecuzione con i risultati della query, imposta QueryMode su PROFILE.
Creare una sessione
Prima di aggiornare la modalità di query, crea una sessione, che rappresenta un canale di comunicazione con il servizio di database Spanner.
- Fai clic su
projects.instances.databases.sessions.create. Fornisci gli ID project, instance e database nel seguente modulo:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]Fai clic su Execute (Esegui). La risposta mostra la sessione che hai creato in questo modulo:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]Lo utilizzerai per eseguire il profilo di query nel passaggio successivo. La sessione creata rimarrà attiva per un massimo di un'ora tra utilizzi consecutivi prima di essere eliminata dal database.
Profila la query
Attiva la modalità PROFILE per la query.
- Fai clic su
projects.instances.databases.sessions.executeSql. In session, inserisci l'ID sessione che hai creato nel passaggio precedente:
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]Per Request body (Corpo della richiesta), utilizza quanto segue:
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }Fai clic su Execute (Esegui). La risposta restituita includerà i risultati della query, il piano di query e le statistiche di esecuzione della query.