- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- La funzionalità Prova disponibile nella documentazione di riferimento dell'API Spanner. Gli esempi mostrati in questa pagina utilizzano la funzionalità Prova.
- Explorer API di Google, che contiene l'API Cloud Spanner e altre API di Google.
- Altri strumenti o framework che supportano le chiamate HTTP REST.
Gli esempi utilizzano
[PROJECT_ID]come ID progetto. Google Cloud Sostituisci Google Cloud con l'ID progetto[PROJECT_ID]. Non includere[e]nell'ID progetto.Gli esempi creano e utilizzano un ID istanza
test-instance. Sostituisci l'ID istanza se non utilizzitest-instance.Gli esempi creano e utilizzano un ID database
example-db. Sostituisci l'ID del tuo database se non utilizziexample-db.Gli esempi utilizzano
[SESSION]come parte del nome di una sessione. Sostituisci il valore che ricevi quando crei una sessione per[SESSION]. (Non includere[e]nel nome della sessione.)Gli esempi utilizzano un ID transazione pari a
[TRANSACTION_ID]. Sostituisci il valore che ricevi quando crei una transazione per[TRANSACTION_ID]. (Non includere[e]nell'ID transazione.)La funzionalità Prova supporta l'aggiunta interattiva di singoli campi di richiesta HTTP. La maggior parte degli esempi in questo argomento fornisce l'intera richiesta anziché descrivere come aggiungere in modo interattivo singoli campi alla richiesta.
- Fai clic su
projects.instanceConfigs.list. In genitore, inserisci:
projects/[PROJECT_ID]Fai clic su Esegui. Le configurazioni di istanza disponibili sono mostrate nella risposta. Ecco un esempio di risposta (il tuo progetto potrebbe avere configurazioni dell'istanza diverse):
{ "instanceConfigs": [ { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-south1", "displayName": "asia-south1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-east1", "displayName": "asia-east1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-asia-northeast1", "displayName": "asia-northeast1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-europe-west1", "displayName": "europe-west1" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-east4", "displayName": "us-east4" }, { "name": "projects/[PROJECT_ID]/instanceConfigs/regional-us-central1", "displayName": "us-central1" } ] }- Fai clic su
projects.instances.create. In genitore, inserisci:
projects/[PROJECT_ID]Fai clic su Aggiungi parametri del corpo della richiesta e seleziona
instance.Fai clic sulla bolla del suggerimento per istanza per visualizzare i campi possibili. Aggiungi valori per i seguenti campi:
nodeCount: inserisci1.config: inserisci il valorenamedi una delle configurazioni di istanza regionale restituite quando elenco delle configurazioni di istanza.displayName: inserisciTest Instance.
Fai clic sulla bolla del suggerimento che segue la parentesi chiusa per instance e seleziona instanceId.
Per
instanceId, inseriscitest-instance.
La pagina di creazione dell'istanza Prova dovrebbe ora avere il seguente aspetto: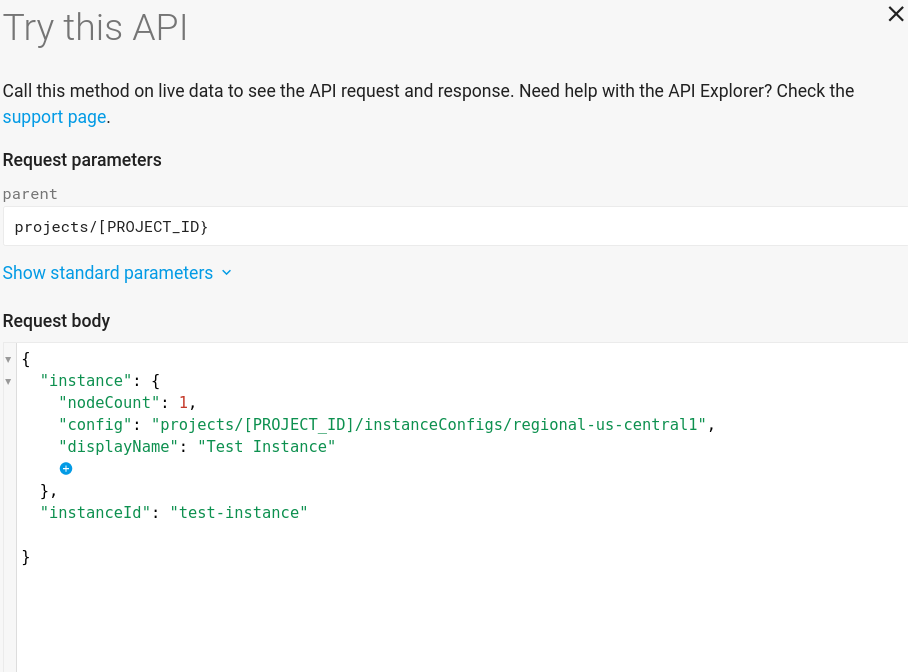
Fai clic su Esegui. La risposta restituisce un'operazione a lunga esecuzione che puoi interrogare per verificarne lo stato.
- Fai clic su
projects.instances.databases.create. In genitore, inserisci:
projects/[PROJECT_ID]/instances/test-instanceFai clic su Aggiungi parametri del corpo della richiesta e seleziona
createStatement.Per
createStatement, inserisci:CREATE DATABASE `example-db`Il nome del database,
example-db, contiene un trattino, quindi deve essere racchiuso tra apici inversi (`).Fai clic su Esegui. La risposta restituisce un'operazione a lunga esecuzione che puoi interrogare per verificarne lo stato.
- Fai clic su
projects.instances.databases.updateDdl. Per database, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbPer Corpo della richiesta, utilizza quanto segue:
{ "statements": [ "CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX) ) PRIMARY KEY (SingerId)", "CREATE TABLE Albums ( SingerId INT64 NOT NULL, AlbumId INT64 NOT NULL, AlbumTitle STRING(MAX)) PRIMARY KEY (SingerId, AlbumId), INTERLEAVE IN PARENT Singers ON DELETE CASCADE" ] }L'array
statementscontiene le istruzioni DDL che definiscono lo schema.Fai clic su Esegui. La risposta restituisce un'operazione a lunga esecuzione che puoi interrogare per verificarne lo stato.
- Fai clic su
projects.instances.databases.sessions.create. Per database, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbFai clic su Esegui.
La risposta mostra la sessione che hai creato, nel modulo
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Utilizzerai questa sessione quando leggi o scrivi nel database.
- Fai clic su
projects.instances.databases.sessions.commit. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "insertOrUpdate": { "table": "Singers", "columns": [ "SingerId", "FirstName", "LastName" ], "values": [ [ "1", "Marc", "Richards" ], [ "2", "Catalina", "Smith" ], [ "3", "Alice", "Trentor" ], [ "4", "Lea", "Martin" ], [ "5", "David", "Lomond" ] ] } }, { "insertOrUpdate": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "values": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ] } } ] }Fai clic su Esegui. La risposta mostra il timestamp del commit.
- Fai clic su
projects.instances.databases.sessions.executeSql. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums" }Fai clic su Esegui. La risposta mostra i risultati della query.
- Fai clic su
projects.instances.databases.sessions.read. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true } }Fai clic su Esegui. La risposta mostra i risultati della lettura.
- Fai clic su
projects.instances.databases.updateDdl. Per database, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbPer Corpo della richiesta, utilizza quanto segue:
{ "statements": [ "ALTER TABLE Albums ADD COLUMN MarketingBudget INT64" ] }L'array
statementscontiene le istruzioni DDL che definiscono lo schema.Fai clic su Esegui. Il completamento dell'operazione potrebbe richiedere alcuni minuti, anche dopo che la chiamata REST restituisce una risposta. La risposta restituisce un'operazione a lunga esecuzione che puoi interrogare per verificarne lo stato.
- Fai clic su
projects.instances.databases.sessions.commit. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "singleUseTransaction": { "readWrite": {} }, "mutations": [ { "update": { "table": "Albums", "columns": [ "SingerId", "AlbumId", "MarketingBudget" ], "values": [ [ "1", "1", "100000" ], [ "2", "2", "500000" ] ] } } ] }Fai clic su Esegui. La risposta mostra il timestamp del commit.
- Fai clic su
projects.instances.databases.sessions.executeSql. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "sql": "SELECT SingerId, AlbumId, MarketingBudget FROM Albums" }Fai clic su Esegui. Nella risposta dovresti vedere due righe che contengono i valori
MarketingBudgetaggiornati:"rows": [ [ "1", "1", "100000" ], [ "1", "2", null ], [ "2", "1", null ], [ "2", "2", "500000" ], [ "2", "3", null ] ]- Fai clic su
projects.instances.databases.updateDdl. Per database, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbPer Corpo della richiesta, utilizza quanto segue:
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle)" ] }Fai clic su Esegui. Il completamento dell'operazione potrebbe richiedere alcuni minuti, anche dopo che la chiamata REST restituisce una risposta. La risposta restituisce un'operazione a lunga esecuzione che puoi interrogare per verificarne lo stato.
- Fai clic su
projects.instances.databases.sessions.executeSql. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "sql": "SELECT AlbumId, AlbumTitle, MarketingBudget FROM Albums WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo'" }Fai clic su Esegui. Nella risposta dovresti vedere le seguenti righe:
"rows": [ [ "2", "Go, Go, Go", null ], [ "2", "Forever Hold Your Peace", "500000" ] ]- Fai clic su
projects.instances.databases.sessions.read. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle" }Fai clic su Esegui. Nella risposta dovresti vedere le seguenti righe:
"rows": [ [ "2", "Forever Hold Your Peace" ], [ "2", "Go, Go, Go" ], [ "1", "Green" ], [ "3", "Terrified" ], [ "1", "Total Junk" ] ]- Fai clic su
projects.instances.databases.updateDdl. Per database, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbPer Corpo della richiesta, utilizza quanto segue:
{ "statements": [ "CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget)" ] }Fai clic su Esegui. Il completamento dell'operazione potrebbe richiedere alcuni minuti, anche dopo che la chiamata REST restituisce una risposta. La risposta restituisce un'operazione a lunga esecuzione che puoi interrogare per verificarne lo stato.
- Fai clic su
projects.instances.databases.sessions.read. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "table": "Albums", "columns": [ "AlbumId", "AlbumTitle", "MarketingBudget" ], "keySet": { "all": true }, "index": "AlbumsByAlbumTitle2" }Fai clic su Esegui. Nella risposta dovresti vedere le seguenti righe:
"rows": [ [ "2", "Forever Hold Your Peace", "500000" ], [ "2", "Go, Go, Go", null ], [ "1", "Green", null ], [ "3", "Terrified", null ], [ "1", "Total Junk", "100000" ] ]- Fai clic su
projects.instances.databases.sessions.beginTransaction. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Per Request Body, utilizza quanto segue:
{ "options": { "readOnly": {} } }Fai clic su Esegui.
La risposta mostra l'ID della transazione che hai creato.
- Fai clic su
projects.instances.databases.sessions.executeSql. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "sql": "SELECT SingerId, AlbumId, AlbumTitle FROM Albums", "transaction": { "id": "[TRANSACTION_ID]" } }Fai clic su Esegui. Nella risposta dovresti visualizzare righe simili alle seguenti:
"rows": [ [ "2", "2", "Forever Hold Your Peace" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "3", "Terrified" ], [ "1", "1", "Total Junk" ] ]- Fai clic su
projects.instances.databases.sessions.read. Per session, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-db/sessions/[SESSION]Ricevi questo valore quando crei una sessione.
Per Corpo della richiesta, utilizza quanto segue:
{ "table": "Albums", "columns": [ "SingerId", "AlbumId", "AlbumTitle" ], "keySet": { "all": true }, "transaction": { "id": "[TRANSACTION_ID]" } }Fai clic su Esegui. Nella risposta dovresti visualizzare righe simili alle seguenti:
"rows": [ [ "1", "1", "Total Junk" ], [ "1", "2", "Go, Go, Go" ], [ "2", "1", "Green" ], [ "2", "2", "Forever Hold Your Peace" ], [ "2", "3", "Terrified" ] ]- Fai clic su
projects.instances.databases.dropDatabase. Come nome, inserisci:
projects/[PROJECT_ID]/instances/test-instance/databases/example-dbFai clic su Esegui.
- Fai clic su
projects.instances.delete. Come nome, inserisci:
projects/[PROJECT_ID]/instances/test-instanceFai clic su Esegui.
Modi per effettuare chiamate REST
Puoi effettuare chiamate REST Spanner utilizzando:
Convenzioni utilizzate in questa pagina
Istanze
Quando utilizzi Spanner per la prima volta, devi creare un'istanza, ovvero un'allocazione di risorse utilizzate dai database Spanner. Quando crei un'istanza, scegli dove archiviare i dati e quanta capacità di calcolo deve avere l'istanza.
Elencare le configurazioni delle istanze
Quando crei un'istanza, specifichi una configurazione dell'istanza, che definisce il posizionamento geografico e la replica dei tuoi database in quell'istanza. Puoi scegliere una configurazione regionale, che archivia i dati in una regione, o una configurazione multiregionale, che distribuisce i dati in più regioni. Scopri di più in Istanze.
Utilizza projects.instanceConfigs.list per determinare quali configurazioni sono disponibili per il tuo progetto Google Cloud .
Utilizzi il valore name per una delle configurazioni dell'istanza quando crei
l'istanza.
Crea un'istanza
Puoi elencare le tue istanze utilizzando
projects.instances.list.
Crea un database
Crea un database denominato example-db.
Puoi elencare i tuoi database utilizzando
projects.instances.databases.list.
Crea uno schema
Utilizza il Data Definition Language (DDL) di Spanner per creare, modificare o eliminare tabelle e per creare o eliminare indici.
Lo schema definisce due tabelle, Singers e Albums, per un'applicazione
musicale di base. Queste tabelle vengono utilizzate in tutta la pagina. Dai un'occhiata allo schema di esempio se non l'hai
ancora fatto.
Puoi recuperare lo schema utilizzando
projects.instances.databases.getDdl.
Creare una sessione
Prima di poter aggiungere, aggiornare, eliminare o interrogare i dati, devi creare una sessione, che rappresenta un canale di comunicazione con il servizio di database Spanner. (Non utilizzi direttamente una sessione se utilizzi una libreria client Spanner, perché la libreria client gestisce le sessioni per tuo conto.)
Le sessioni sono pensate per durare a lungo. Il servizio di database Spanner può eliminare una sessione quando è inattiva per più di un'ora. I tentativi di
utilizzare una sessione eliminata restituiscono NOT_FOUND. Se si verifica questo errore, crea
e utilizza una nuova sessione. Puoi verificare se una sessione è ancora attiva utilizzando
projects.instances.databases.sessions.get.
Per informazioni correlate, vedi Mantenere attiva una sessione inattiva.
Il passaggio successivo consiste nello scrivere i dati nel database.
Scrivi dati
Scrivi i dati utilizzando il tipo
Mutation. Un Mutation è un contenitore per le operazioni di mutazione. Una Mutation
rappresenta una sequenza di inserimenti, aggiornamenti, eliminazioni e altre azioni che possono
essere applicate in modo atomico a righe e tabelle diverse in un database
Spanner.
In questo esempio è stato utilizzato insertOrUpdate. Altre operazioni
per Mutations sono insert, update, replace e delete.
Per informazioni su come codificare i tipi di dati, vedi TypeCode.
Eseguire query sui dati utilizzando SQL
Lettura dei dati utilizzando l'API di lettura
Aggiorna lo schema del database
Supponiamo che tu debba aggiungere una nuova colonna denominata MarketingBudget alla tabella Albums, che richiede un aggiornamento dello schema del database. Spanner
supporta gli aggiornamenti dello schema di un database mentre il database continua a gestire
il traffico. Gli aggiornamenti dello schema non richiedono di mettere offline il database e non bloccano intere tabelle o colonne. Puoi continuare a scrivere dati nel database durante l'aggiornamento dello schema.
Aggiungere una colonna
Scrivi i dati nella nuova colonna
Il seguente codice scrive i dati nella nuova colonna. Imposta MarketingBudget su
100000 per la riga con chiave Albums(1, 1) e su 500000 per la riga con chiave
Albums(2, 2).
Puoi anche eseguire una query SQL o una chiamata di lettura per recuperare i valori che hai appena scritto.
Ecco come eseguire la query:
Utilizzare un indice secondario
Supponiamo di voler recuperare tutte le righe di Albums che hanno valori AlbumTitle
in un determinato intervallo. Potresti leggere tutti i valori della colonna AlbumTitle utilizzando
un'istruzione SQL o una chiamata di lettura, quindi scartare le righe che non soddisfano i
criteri, ma questa scansione completa della tabella è costosa, soprattutto per le tabelle
con molte righe. Puoi invece velocizzare il recupero delle righe quando
cerchi per colonne non chiave primaria creando un
indice secondario nella tabella.
L'aggiunta di un indice secondario a una tabella esistente richiede un aggiornamento dello schema. Come altri aggiornamenti dello schema, Spanner supporta l'aggiunta di un indice mentre il database continua a gestire il traffico. Spanner esegue automaticamente il backfill dell'indice con i dati esistenti. Il completamento dei backfill potrebbe richiedere alcuni minuti, ma non è necessario mettere offline il database o evitare di scrivere in determinate tabelle o colonne durante questo processo. Per maggiori dettagli, vedi riempimento dell'indice.
Dopo aver aggiunto un indice secondario, Spanner lo utilizza automaticamente per le query SQL che probabilmente vengono eseguite più velocemente con l'indice. Se utilizzi l'interfaccia di lettura, devi specificare l'indice che vuoi utilizzare.
Aggiungere un indice secondario
Puoi aggiungere un indice utilizzando updateDdl.
Query che utilizza l'indice
Lettura utilizzando l'indice
Aggiungere un indice con la clausola STORING
Potresti aver notato che l'esempio di lettura riportato sopra non includeva la lettura della colonna
MarketingBudget. Questo perché l'interfaccia di lettura di Spanner non supporta la possibilità di unire un indice a una tabella di dati per cercare valori non archiviati nell'indice.
Crea una definizione alternativa di AlbumsByAlbumTitle che memorizzi una copia di
MarketingBudget nell'indice.
Puoi aggiungere un indice STORING utilizzando updateDdl.
Ora puoi eseguire una lettura che recupera tutte le colonne AlbumId, AlbumTitle e
MarketingBudget dall'indice AlbumsByAlbumTitle2:
Recuperare i dati utilizzando le transazioni di sola lettura
Supponiamo che tu voglia eseguire più di una lettura con lo stesso timestamp. Le transazioni di sola lettura osservano un prefisso coerente della cronologia dei commit delle transazioni, in modo che la tua applicazione riceva sempre dati coerenti.
Creare una transazione di sola lettura
Ora puoi utilizzare la transazione di sola lettura per recuperare i dati a un timestamp coerente, anche se i dati sono cambiati da quando hai creato la transazione di sola lettura.
Eseguire una query utilizzando la transazione di sola lettura
Lettura con la transazione di sola lettura
Spanner supporta anche le transazioni di lettura/scrittura, che eseguono un insieme di letture e scritture in modo atomico in un unico punto logico nel tempo. Per ulteriori informazioni, vedi Transazioni di lettura/scrittura. La funzionalità Prova non è adatta per dimostrare una transazione di lettura/scrittura.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi aggiuntivi per le risorse utilizzate in questo tutorial, elimina il database e l'istanza che hai creato.