In un database Spanner, Spanner crea automaticamente un indice per la chiave primaria di ogni tabella. Ad esempio, non devi fare nulla
per indicizzare la chiave primaria di Singers, perché viene indicizzata automaticamente.
Puoi anche creare indici secondari per altre colonne. Aggiungere un indice secondario a una colonna rende più efficiente la ricerca dei dati nella colonna. Ad esempio, se devi cercare rapidamente un album in base al titolo, devi creare un indice secondario su AlbumTitle, in modo che Spanner non debba scansionare l'intera tabella.
Se la ricerca nell'esempio precedente viene eseguita all'interno di una transazione di lettura/scrittura,
la ricerca più efficiente evita anche di bloccare l'intera tabella,
il che consente inserimenti e aggiornamenti simultanei alla tabella per le righe al di fuori dell'AlbumTitleintervallo di ricerca.
Oltre ai vantaggi che apportano alle ricerche, gli indici secondari possono anche aiutare Spanner a eseguire le scansioni in modo più efficiente, consentendo le scansioni degli indici anziché le scansioni complete delle tabelle.
Spanner archivia i seguenti dati in ogni indice secondario:
- Tutte le colonne chiave della tabella di base
- Tutte le colonne incluse nell'indice
- Tutte le colonne specificate nella clausola facoltativa
STORING(database con dialetto GoogleSQL) oINCLUDE(database con dialetto PostgreSQL) della definizione dell'indice.
Nel tempo, Spanner analizza le tabelle per garantire che gli indici secondari vengano utilizzati per le query appropriate.
Aggiungere un indice secondario
Il momento più efficiente per aggiungere un indice secondario è quando crei la tabella. Per creare una tabella e i relativi indici contemporaneamente, invia le istruzioni DDL per la nuova tabella e i nuovi indici in un'unica richiesta a Spanner.
In Spanner, puoi anche aggiungere un nuovo indice secondario a una tabella esistente mentre il database continua a gestire il traffico. Come qualsiasi altra modifica dello schema in Spanner, l'aggiunta di un indice a un database esistente non richiede di mettere offline il database e non blocca intere colonne o tabelle.
Ogni volta che viene aggiunto un nuovo indice a una tabella esistente, Spanner esegue automaticamente il backfill, ovvero compila l'indice in modo da riflettere una visualizzazione aggiornata dei dati indicizzati. Spanner gestisce questo processo di backfill per te e viene eseguito in background utilizzando le risorse dei nodi a bassa priorità. La velocità di riempimento degli indici si adatta alle risorse dei nodi in evoluzione durante la creazione dell'indice e il riempimento non influisce in modo significativo sulle prestazioni del database.
La creazione dell'indice può richiedere da diversi minuti a molte ore. Poiché la creazione dell'indice è un aggiornamento dello schema, è vincolata dagli stessi vincoli di rendimento di qualsiasi altro aggiornamento dello schema. Il tempo necessario per creare un indice secondario dipende da diversi fattori:
- Le dimensioni del set di dati
- La capacità di calcolo dell'istanza
- Il carico sull'istanza
Per visualizzare l'avanzamento di un processo di backfill dell'indice, consulta la sezione sull'avanzamento.
Tieni presente che l'utilizzo della colonna timestamp del commit come prima parte dell'indice secondario può creare hotspot e ridurre le prestazioni di scrittura.
Utilizza l'istruzione CREATE INDEX per definire un indice secondario
nello schema. Ecco alcuni esempi:
Per indicizzare tutti i Singers nel database in base al nome e al cognome:
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Per creare un indice di tutti i Songs nel database in base al valore di SongName:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
Per indicizzare solo i brani di un determinato cantante, utilizza la clausola
INTERLEAVE IN per intercalare l'indice nella
tabella Singers:
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
Per indicizzare solo i brani di un determinato album:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
Per indicizzare in ordine decrescente di SongName:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
Tieni presente che l'annotazione precedente DESC si applica solo a SongName. Per indicizzare in base all'ordine decrescente di altre chiavi di indice, annotale anche con DESC:
SingerId DESC, AlbumId DESC.
Tieni presente inoltre che PRIMARY_KEY è una parola riservata e non può essere utilizzata come nome
di un indice. È il nome assegnato allo pseudo-indice
che viene creato quando viene creata una tabella con la specifica PRIMARY KEY
Per ulteriori dettagli e best practice per la scelta di indici senza interleaving e con interleaving, consulta Opzioni di indice e Utilizzare un indice con interleaving su una colonna il cui valore aumenta o diminuisce monotonicamente.
Indici e interleaving
Gli indici Spanner possono essere intercalati con altre tabelle per collocare le righe dell'indice con quelle di un'altra tabella. Analogamente all'interfoliazione delle tabelle Spanner, le colonne di chiave primaria del padre dell'indice devono essere un prefisso delle colonne indicizzate, corrispondenti per tipo e ordine di ordinamento. A differenza delle tabelle interleaved, non è necessario che i nomi delle colonne corrispondano. Ogni riga di un indice interleaved viene archiviata fisicamente insieme alla riga principale associata.
Ad esempio, considera lo schema seguente:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
Per indicizzare tutti i Singers nel database in base al nome e al cognome, devi
creare un indice. Ecco come definire l'indice SingersByFirstLastName:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Se vuoi creare un indice di Songs su (SingerId, AlbumId, SongName),
puoi procedere nel seguente modo:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
In alternativa, puoi creare un indice intercalato con un antenato di Songs,
come il seguente:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
Inoltre, potresti creare un indice di Songs su
(PublisherId, SingerId, AlbumId, SongName) che si alterna a una tabella
che non è un elemento principale di Songs, come Publishers. Tieni presente che la chiave primaria
per la tabella Publishers (id) non è un prefisso delle colonne indicizzate nell'esempio seguente. Ciò è ancora consentito perché Publishers.Id e
Songs.PublisherId condividono lo stesso tipo, lo stesso ordinamento e la stessa possibilità di valori nulli.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
Controllare l'avanzamento del backfill dell'indice
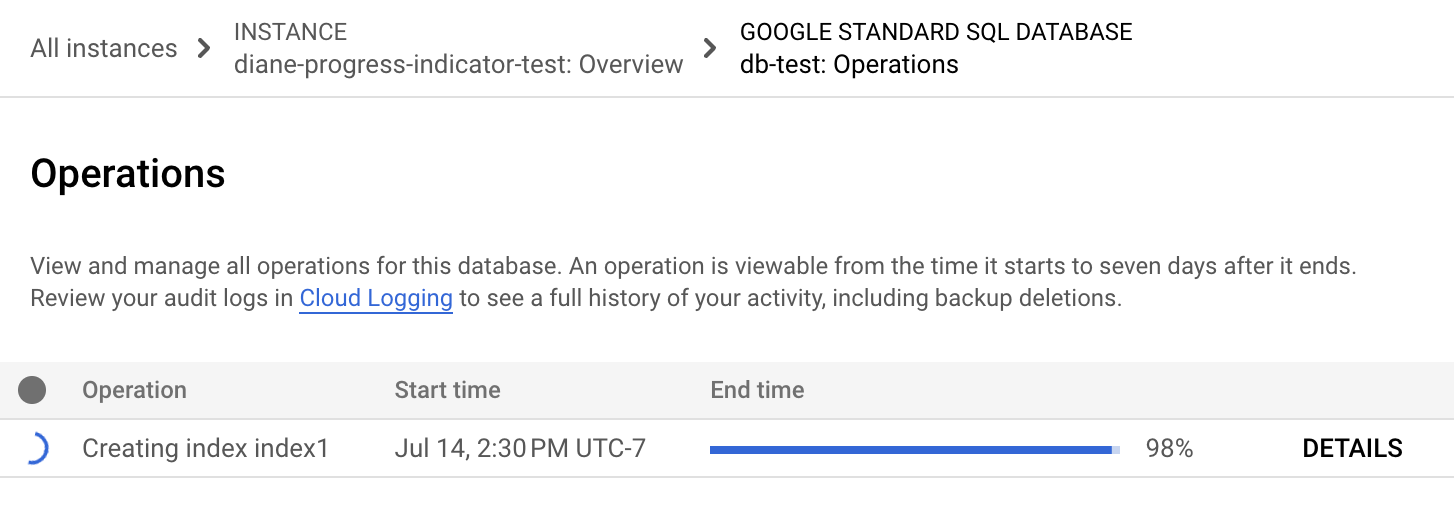
Console
Nel menu di navigazione di Spanner, fai clic sulla scheda Operazioni. La pagina Operazioni mostra un elenco delle operazioni in esecuzione.
Trova l'operazione di backfill nell'elenco. Se è ancora in esecuzione, l'indicatore di avanzamento nella colonna Ora di fine mostra la percentuale dell'operazione completata, come mostrato nell'immagine seguente:
gcloud
Utilizza gcloud spanner operations describe
per controllare lo stato di avanzamento di un'operazione.
Recupera l'ID operazione:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Sostituisci quanto segue:
- INSTANCE-NAME con il nome dell'istanza Spanner.
- DATABASE-NAME con il nome del database.
Note sull'utilizzo:
Per limitare l'elenco, specifica il flag
--filter. Ad esempio:--filter="metadata.name:example-db"elenca solo le operazioni su un database specifico.--filter="error:*"elenca solo le operazioni di backup non riuscite.
Per informazioni sulla sintassi dei filtri, consulta gcloud topic filters. Per informazioni sul filtro delle operazioni di backup, consulta il campo
filterin ListBackupOperationsRequest.Il flag
--typenon è sensibile alle maiuscole.
L'output è simile al seguente:
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadataCorsa
gcloud spanner operations describe:gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
Sostituisci quanto segue:
- INSTANCE-NAME: il nome dell'istanza Spanner.
- DATABASE-NAME: il nome del database Spanner.
- PROJECT-NAME: il nome del progetto.
- OPERATION-ID: l'ID operazione dell'operazione che vuoi controllare.
La sezione
progressnell'output mostra la percentuale di completamento dell'operazione. L'output è simile al seguente:done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
Recupera l'ID operazione:
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Sostituisci quanto segue:
- INSTANCE-NAME con il nome dell'istanza Spanner.
- DATABASE-NAME con il nome del database.
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- PROJECT-ID: l'ID progetto
- INSTANCE-ID: l'ID istanza
- DATABASE-ID: l'ID database.
- OPERATION-ID: l'ID operazione.
Metodo HTTP e URL:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Per gcloud e REST, puoi trovare l'avanzamento di ogni istruzione di backfill dell'indice
nella sezione progress. Per ogni istruzione nell'array di istruzioni,
esiste un campo corrispondente nell'array di avanzamento. L'ordine di questa matrice di avanzamento
corrisponde all'ordine della matrice delle istruzioni. Una volta disponibili, i campi
startTime, progressPercent e endTime vengono compilati di conseguenza.
Tieni presente che l'output non mostra un tempo stimato per il completamento
dell'avanzamento del riempimento.
Se l'operazione richiede troppo tempo, puoi annullarla. Per saperne di più, consulta la sezione Annullare la creazione dell'indice.
Scenari durante la visualizzazione dell'avanzamento del backfill dell'indice
Esistono diversi scenari che puoi incontrare quando tenti di controllare lo stato di avanzamento di un backfill dell'indice. Le istruzioni di creazione dell'indice che richiedono un riempimento dell'indice fanno parte delle operazioni di aggiornamento dello schema e possono esserci diverse istruzioni che fanno parte di un'operazione di aggiornamento dello schema.
Il primo scenario è il più semplice, ovvero quando l'istruzione di creazione dell'indice
è la prima istruzione nell'operazione di aggiornamento dello schema. Poiché l'istruzione di creazione dell'indice è la prima, viene elaborata ed eseguita per prima a causa dell'ordine di esecuzione.
Immediatamente, il campo startTime dell'istruzione di creazione dell'indice verrà
compilato con l'ora di inizio dell'operazione di aggiornamento dello schema. Successivamente, il campo progressPercent dell'istruzione di creazione dell'indice viene compilato quando l'avanzamento del backfill dell'indice è superiore allo 0%. Infine, il campo endTime viene compilato una volta
che l'estratto conto è stato registrato.
Il secondo scenario si verifica quando l'istruzione di creazione dell'indice non è la prima
istruzione nell'operazione di aggiornamento dello schema. Nessun campo correlato all'istruzione di creazione dell'indice verrà compilato finché le istruzioni precedenti non saranno state eseguite a causa dell'ordine di esecuzione.
Analogamente allo scenario precedente, una volta confermati gli estratti conto precedenti, viene compilato prima il campo startTime dell'istruzione di creazione dell'indice, seguito dal campo progressPercent. Infine, il campo endTime viene compilato al termine del commit dell'istruzione.
Annulla creazione indice
Puoi utilizzare Google Cloud CLI per annullare la creazione dell'indice. Per recuperare un elenco di
operazioni di aggiornamento dello schema per un database Spanner, utilizza il
comando gcloud spanner operations list e includi
l'opzione --filter:
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
Trova l'OPERATION_ID per l'operazione che vuoi annullare, poi utilizza il comando
gcloud spanner operations cancel per annullarla:
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
Visualizza gli indici esistenti
Per visualizzare le informazioni sugli indici esistenti in un database, puoi utilizzare la consoleGoogle Cloud o Google Cloud CLI:
Console
Vai alla pagina Istanze di Spanner nella console Google Cloud .
Fai clic sul nome dell'istanza che vuoi visualizzare.
Nel riquadro a sinistra, fai clic sul database che vuoi visualizzare, poi fai clic sulla tabella che vuoi visualizzare.
Fai clic sulla scheda Indici. La console Google Cloud mostra un elenco di indici.
(Facoltativo) Per visualizzare i dettagli di un indice, ad esempio le colonne che include, fai clic sul nome dell'indice.
gcloud
Utilizza il comando gcloud spanner databases ddl describe:
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
La gcloud CLI stampa le istruzioni Data Definition Language (DDL)
per creare le tabelle e gli indici del database. Le istruzioni CREATE
INDEX descrivono gli indici esistenti. Ad esempio:
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
Query con un indice specifico
Le sezioni seguenti spiegano come specificare un indice in un'istruzione SQL e
con l'interfaccia di lettura per Spanner. Gli esempi in queste sezioni
presuppongono che tu abbia aggiunto una colonna MarketingBudget alla tabella Albums e
che tu abbia creato un indice denominato AlbumsByAlbumTitle:
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Specificare un indice in un'istruzione SQL
Quando utilizzi SQL per eseguire query su una tabella Spanner, Spanner utilizza automaticamente
gli indici che potrebbero rendere la query più efficiente. Di conseguenza,
non è necessario specificare un indice per le query SQL. Tuttavia,
per le query fondamentali per il tuo carico di lavoro, Google ti consiglia di utilizzare
direttive FORCE_INDEX nelle istruzioni SQL per un rendimento più coerente.
In alcuni casi, Spanner potrebbe scegliere un indice che causa un aumento della latenza delle query. Se hai seguito i passaggi per la risoluzione dei problemi relativi alle regressioni delle prestazioni e hai verificato che è opportuno provare un indice diverso per la query, puoi specificare l'indice come parte della query.
Per specificare un indice in un'istruzione SQL, utilizza il suggerimento FORCE_INDEX per fornire un'istruzione index. Le direttive di indicizzazione utilizzano la seguente sintassi:
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Puoi anche utilizzare una direttiva di indice per indicare a Spanner di analizzare la tabella di base anziché utilizzare un indice:
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
Puoi utilizzare una direttiva index per indicare a Spanner di eseguire la scansione di un indice in una tabella con schemi denominati:
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
L'esempio seguente mostra una query SQL che specifica un indice:
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
Una direttiva di indice potrebbe forzare il processore di query di Spanner a leggere
colonne aggiuntive richieste dalla query, ma non archiviate nell'indice.
Il processore di query recupera queste colonne unendo l'indice e la tabella di base. Per evitare questo join aggiuntivo, utilizza una
clausola STORING (database con dialetto GoogleSQL) o INCLUDE (database con dialetto PostgreSQL) per
memorizzare le colonne aggiuntive nell'indice.
Nell'esempio precedente, la colonna MarketingBudget non è
memorizzata nell'indice, ma la query SQL la seleziona. Di conseguenza,
Spanner deve cercare la colonna MarketingBudget nella tabella di base,
quindi unirla ai dati dell'indice per restituire i risultati della query.
Spanner genera un errore se la direttiva dell'indice presenta uno dei seguenti problemi:
- L'indice non esiste.
- L'indice si trova in una tabella di base diversa.
- Nella query manca un'espressione di filtro
NULLobbligatoria per un indiceNULL_FILTERED.
Gli esempi seguenti mostrano come scrivere ed eseguire query che recuperano i valori di AlbumId, AlbumTitle e MarketingBudget utilizzando l'indice AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Specificare un indice nell'interfaccia di lettura
Quando utilizzi l'interfaccia di lettura per Spanner e vuoi che Spanner utilizzi un indice, devi specificare l'indice. L'interfaccia di lettura non seleziona automaticamente l'indice.
Inoltre, l'indice deve contenere tutti i dati visualizzati nei risultati della query, escluse le colonne che fanno parte della chiave primaria. Questa limitazione esiste perché l'interfaccia di lettura non supporta i join tra l'indice e la tabella di base. Se devi includere altre colonne nei risultati della query, hai a disposizione alcune opzioni:
- Utilizza una clausola
STORINGoINCLUDEper memorizzare le colonne aggiuntive nell'indice. - Esegui la query senza includere le colonne aggiuntive, quindi utilizza le chiavi primarie per inviare un'altra query che legge le colonne aggiuntive.
Spanner restituisce i valori dell'indice in ordine crescente in base alla chiave dell'indice. Per recuperare i valori in ordine decrescente:
Annota la chiave di indice con
DESC. Ad esempio:CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);L'annotazione
DESCsi applica a una singola chiave di indice. Se l'indice include più di una chiave e vuoi che i risultati della query vengano visualizzati in ordine decrescente in base a tutte le chiavi, includi un'annotazioneDESCper ogni chiave.Se la lettura specifica un intervallo di chiavi, assicurati che anche questo sia in ordine decrescente. In altre parole, il valore della chiave iniziale deve essere maggiore del valore della chiave finale.
Il seguente esempio mostra come recuperare i valori di AlbumId e
AlbumTitle utilizzando l'indice AlbumsByAlbumTitle:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Creare un indice per le scansioni solo indice
Se vuoi, puoi utilizzare la clausola STORING (per i database con dialetto GoogleSQL) o la clausola INCLUDE (per i database con dialetto PostgreSQL) per archiviare una copia di una colonna nell'indice. Questo tipo di indice offre vantaggi per le query e le chiamate di lettura che lo utilizzano, a costo di utilizzare spazio di archiviazione aggiuntivo:
- Le query SQL che utilizzano l'indice e selezionano le colonne memorizzate nella clausola
STORINGoINCLUDEnon richiedono un join aggiuntivo alla tabella di base. - Le chiamate
read()che utilizzano l'indice possono leggere le colonne memorizzate dalla clausolaSTORING/INCLUDE.
Ad esempio, supponiamo di aver creato una versione alternativa di AlbumsByAlbumTitle
che memorizza una copia della colonna MarketingBudget nell'indice (nota la
clausola STORING o INCLUDE in grassetto):
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
Con il vecchio indice AlbumsByAlbumTitle, Spanner deve unire l'indice
alla tabella di base, quindi recuperare la colonna dalla tabella di base. Con il nuovo indice AlbumsByAlbumTitle2, Spanner legge la colonna direttamente dall'indice, il che è più efficiente.
Se utilizzi l'interfaccia di lettura anziché SQL, il nuovo indice AlbumsByAlbumTitle2
ti consente anche di leggere direttamente la colonna MarketingBudget:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Modificare un indice
Puoi utilizzare l'istruzione ALTER INDEX per aggiungere colonne aggiuntive
a un indice esistente o eliminare colonne. Questo
può aggiornare l'elenco delle colonne definito dalla clausola STORING
(database con dialetto GoogleSQL) o dalla clausola INCLUDE (database con dialetto PostgreSQL) quando crei l'indice. Non puoi utilizzare questa istruzione per aggiungere colonne alla chiave di indice o rimuoverle. Ad esempio, invece di creare un nuovo indice AlbumsByAlbumTitle2, puoi utilizzare ALTER INDEX per aggiungere una colonna a AlbumsByAlbumTitle, come mostrato nell'esempio seguente:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
Quando aggiungi una nuova colonna a un indice esistente, Spanner
utilizza un processo di riempimento in background. Mentre il riempimento è in corso,
la colonna nell'indice non è leggibile, quindi potresti non ottenere l'aumento delle prestazioni
previsto. Puoi utilizzare il comando gcloud spanner operations
per elencare l'operazione a lunga esecuzione e visualizzarne lo stato.
Per ulteriori informazioni, vedi describe operation.
Puoi anche utilizzare Annulla operazione per annullare un'operazione in esecuzione.
Al termine del backfill, Spanner aggiunge la colonna all'indice. Man mano che l'indice aumenta di dimensioni, le query che lo utilizzano potrebbero rallentare.
L'esempio seguente mostra come eliminare una colonna da un indice:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
Indice di valori NULL
Per impostazione predefinita, Spanner indicizza i valori NULL. Ad esempio, ricorda la
definizione dell'indice SingersByFirstLastName nella tabella Singers:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Tutte le righe di Singers vengono indicizzate anche se FirstName o LastName, o
entrambi, sono NULL.

Quando i valori NULL vengono indicizzati, puoi eseguire query SQL e letture efficienti
sui dati che includono valori NULL. Ad esempio, utilizza questa istruzione di query SQL
per trovare tutti i Singers con un NULL FirstName:
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
Ordinamento per i valori NULL
Spanner ordina NULL come valore più piccolo per qualsiasi tipo. Per una
colonna in ordine crescente (ASC), i valori NULL vengono ordinati per primi. Per una colonna in ordine
decrescente (DESC), i valori NULL vengono ordinati per ultimi.
Disabilita l'indicizzazione dei valori NULL
GoogleSQL
Per disattivare l'indicizzazione dei valori null, aggiungi la parola chiave NULL_FILTERED alla definizione dell'indice. Gli indici NULL_FILTERED sono particolarmente utili per indicizzare colonne sparse, in cui la maggior parte delle righe contiene un valore NULL. In questi casi, l'indice
NULL_FILTERED può essere notevolmente più piccolo e più efficiente da gestire
rispetto a un indice normale che include valori NULL.
Ecco una definizione alternativa di SingersByFirstLastName che non
indicizza i valori NULL:
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
La parola chiave NULL_FILTERED si applica a tutte le colonne delle chiavi di indice. Non puoi specificare
il filtro NULL in base alle colonne.
PostgreSQL
Per filtrare le righe con valori null in una o più colonne indicizzate, utilizza il predicato
WHERE COLUMN IS NOT NULL.
Gli indici filtrati per valori null sono particolarmente utili per indicizzare colonne sparse, in cui la maggior parte delle righe contiene un valore NULL. In questi casi, l'indice filtrato per valori null può essere notevolmente più piccolo e più efficiente da gestire rispetto a un indice normale che include valori NULL.
Ecco una definizione alternativa di SingersByFirstLastName che non
indicizza i valori NULL:
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
Il filtro dei valori NULL impedisce a Spanner di utilizzarli per alcune
query. Ad esempio, Spanner non utilizza l'indice per questa query,
perché l'indice omette tutte le righe Singers per le quali LastName è NULL; di conseguenza, l'utilizzo dell'indice impedirebbe alla query di restituire le righe corrette:
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Per consentire a Spanner di utilizzare l'indice, devi riscrivere la query in modo che escluda le righe escluse anche dall'indice:
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
Campi proto dell'indice
Utilizza le colonne generate per indicizzare
i campi nei buffer di protocollo archiviati nelle colonne PROTO, a condizione che i campi
indicizzati utilizzino i tipi di dati primitivi o ENUM.
Se definisci un indice su un campo del messaggio del protocollo, non puoi modificare o rimuovere questo campo dallo schema proto. Per ulteriori informazioni, vedi Aggiornamenti agli schemi che contengono un indice sui campi proto.
Di seguito è riportato un esempio della tabella Singers con una colonna del messaggio proto SingerInfo. Per definire un indice nel campo nationality di PROTO,
devi creare una colonna generata archiviata:
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
Ha la seguente definizione del tipo di proto googlesql.example.SingerInfo:
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
Poi definisci un indice sul campo nationality del proto:
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
La seguente query SQL legge i dati utilizzando l'indice precedente:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
Note:
- Utilizza una direttiva di indice per accedere agli indici nei campi delle colonne del buffer del protocollo.
- Non puoi creare un indice sui campi del buffer del protocollo ripetuti.
Aggiornamenti agli schemi che contengono un indice sui campi proto
Se definisci un indice su un campo del messaggio del protocollo, non puoi modificare o rimuovere questo campo dallo schema proto. Questo perché dopo aver definito l'indice, il controllo del tipo viene eseguito ogni volta che lo schema viene aggiornato. Spanner acquisisce le informazioni sul tipo per tutti i campi nel percorso utilizzati nella definizione dell'indice.
Indici univoci
Gli indici possono essere dichiarati UNIQUE. Gli indici UNIQUE aggiungono un vincolo ai dati indicizzati che vieta le voci duplicate per una determinata chiave di indice.
Questo vincolo viene applicato da Spanner al momento del commit della transazione.
Nello specifico, qualsiasi transazione che causerebbe l'esistenza di più voci di indice per la stessa chiave non verrà eseguita.
Se una tabella contiene dati non UNIQUE, il tentativo di creare un indice UNIQUE non andrà a buon fine.
Una nota sugli indici UNIQUE NULL_FILTERED
Un indice UNIQUE NULL_FILTERED non impone l'unicità della chiave di indice quando almeno una delle parti della chiave dell'indice è NULL.
Ad esempio, supponiamo di aver creato la seguente tabella e il seguente indice:
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
Le due righe seguenti in ExampleTable hanno gli stessi valori per le chiavi dell'indice secondario Key1, Key2 e Col1:
1, NULL, 1, 1
1, NULL, 2, 1
Poiché Key2 è NULL e l'indice è filtrato per valori nulli, le righe non saranno
presenti nell'indice ExampleIndex. Poiché non vengono inseriti nell'indice, quest'ultimo non li rifiuterà per violazione dell'unicità su (Key1, Key2,
Col1).
Se vuoi che l'indice imponga l'unicità dei valori della tupla (Key1,
Key2, Col1), devi annotare Key2 con NOT NULL nella definizione della tabella
o creare l'indice senza filtrare i valori null.
Eliminare un indice
Utilizza l'istruzione DROP INDEX per eliminare un indice secondario dallo schema.
Per eliminare l'indice denominato SingersByFirstLastName:
DROP INDEX SingersByFirstLastName;
Indice per una scansione più rapida
Quando Spanner deve eseguire una scansione della tabella (anziché una ricerca indicizzata) per recuperare i valori da una o più colonne, puoi ricevere risultati più rapidi se esiste un indice per queste colonne e nell'ordine specificato dalla query. Se esegui spesso query che richiedono scansioni, valuta la possibilità di creare indici secondari per rendere queste scansioni più efficienti.
In particolare, se hai bisogno che Spanner esegua spesso la scansione della chiave primaria o di un altro indice di una tabella in ordine inverso, puoi aumentare la sua efficienza tramite un indice secondario che rende esplicito l'ordine scelto.
Ad esempio, la seguente query restituisce sempre un risultato rapido, anche se
Spanner deve analizzare Songs per trovare il valore più basso di
SongId:
SELECT SongId FROM Songs LIMIT 1;
SongId è la chiave primaria della tabella, memorizzata (come tutte le chiavi primarie)
in ordine crescente. Spanner può scansionare l'indice della chiave e trovare
rapidamente il primo risultato.
Tuttavia, senza l'aiuto di un indice secondario, la seguente query non
restituirebbe risultati altrettanto rapidamente, soprattutto se Songs contiene molti dati:
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
Anche se SongId è la chiave primaria della tabella, Spanner non ha modo di recuperare il valore più alto della colonna senza ricorrere a una scansione completa della tabella.
L'aggiunta del seguente indice consentirebbe a questa query di restituire risultati più rapidamente:
CREATE INDEX SongIdDesc On Songs(SongId DESC);
Con questo indice, Spanner lo utilizzerebbe per restituire un risultato per la seconda query molto più rapidamente.
Passaggi successivi
- Scopri le best practice SQL per Spanner.
- Comprendi i piani di esecuzione delle query per Spanner.
- Scopri come risolvere i problemi di regressione delle prestazioni nelle query SQL.