概要
このページでは、クエリ実行プランのコンセプト、および Spanner でそれを使用して分散環境でクエリを実行する方法について説明します。Google Cloud コンソールを使用して特定のクエリの実行プランを取得する方法については、Spanner によるクエリの実行方法を理解するをご覧ください。また、サンプリングされた過去のクエリプランを表示し、特定のクエリのパフォーマンスの推移を比較することもできます。詳細については、サンプリングされたクエリプランをご覧ください。
Spanner は、宣言型 SQL ステートメントを使用して、データベースのクエリを実行します。SQL ステートメントは、結果を取得する方法を指定することなく、ユーザーが必要とするものを定義します。クエリ実行プランは、結果を取得する方法についての一連の手順です。特定の SQL ステートメントについて、結果を取得する方法が複数存在する場合があります。Spanner のクエリ オプティマイザーは、さまざまな実行プランを評価し、最も効率的であると判断するものを選択します。その後、Spanner はその実行プランを使用して結果を取得します。
概念的には、実行プランは関係演算子のツリーです。各演算子は、入力から行を読み取り、出力行を生成します。実行のルートにある演算子の結果が、SQL クエリの結果として返されます。
例として次のようなクエリを考えます。
SELECT s.SongName FROM Songs AS s;
クエリ実行プランの結果は次のように表現できます。
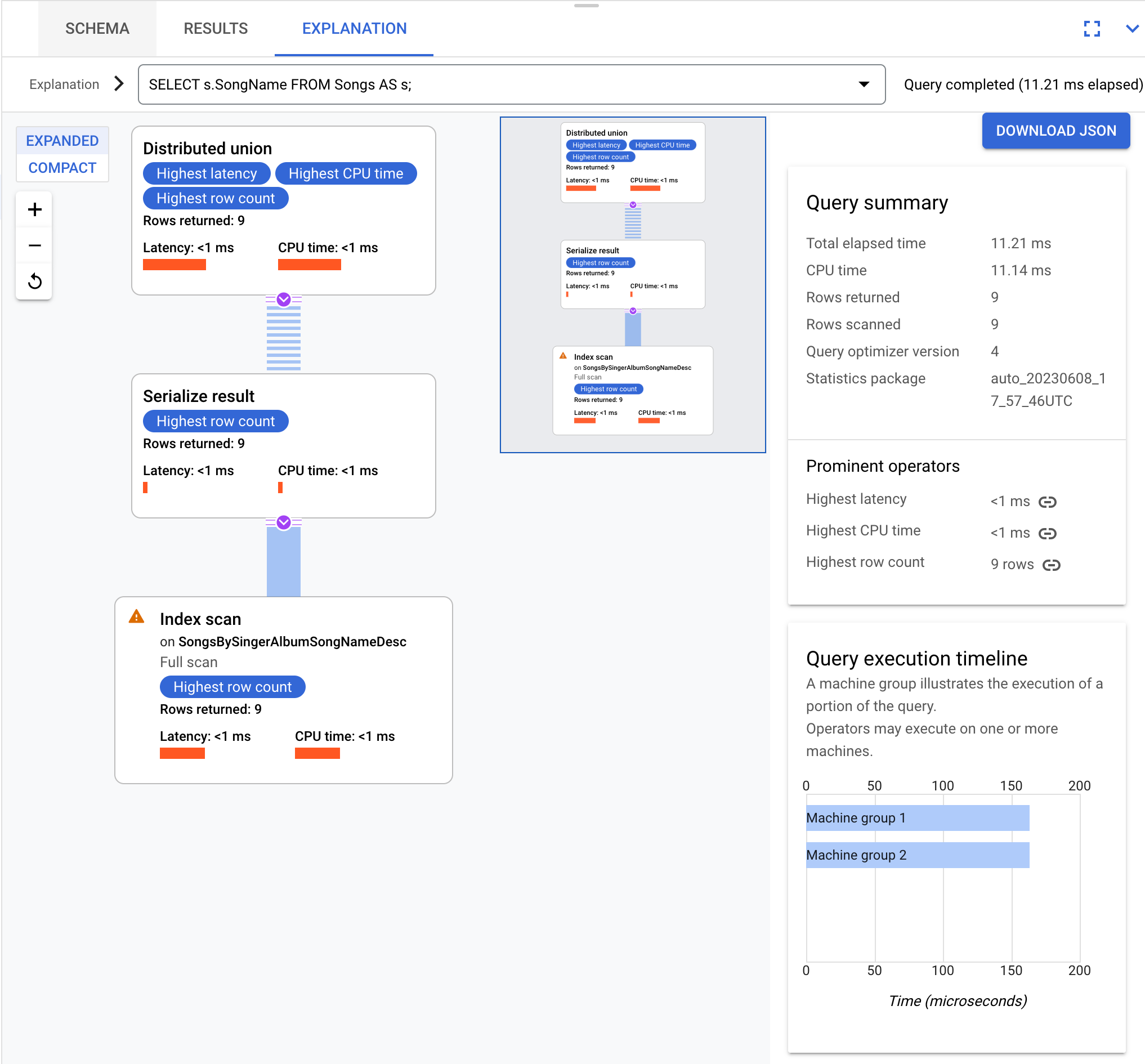
このページのクエリと実行プランは、次のデータベース スキーマに基づいています。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY(SingerId);
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64
) PRIMARY KEY(SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
SongName STRING(MAX),
Duration INT64,
SongGenre STRING(25)
) PRIMARY KEY(SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC), INTERLEAVE IN Albums;
CREATE INDEX SongsBySongName ON Songs(SongName);
CREATE TABLE Concerts (
VenueId INT64 NOT NULL,
SingerId INT64 NOT NULL,
ConcertDate DATE NOT NULL,
BeginTime TIMESTAMP,
EndTime TIMESTAMP,
TicketPrices ARRAY<INT64>
) PRIMARY KEY(VenueId, SingerId, ConcertDate);
次のデータ操作言語(DML)ステートメントを使用して、これらのテーブルにデータを追加できます。
INSERT INTO Singers (SingerId, FirstName, LastName, BirthDate)
VALUES (1, "Marc", "Richards", "1970-09-03"),
(2, "Catalina", "Smith", "1990-08-17"),
(3, "Alice", "Trentor", "1991-10-02"),
(4, "Lea", "Martin", "1991-11-09"),
(5, "David", "Lomond", "1977-01-29");
INSERT INTO Albums (SingerId, AlbumId, AlbumTitle)
VALUES (1, 1, "Total Junk"),
(1, 2, "Go, Go, Go"),
(2, 1, "Green"),
(2, 2, "Forever Hold Your Peace"),
(2, 3, "Terrified"),
(3, 1, "Nothing To Do With Me"),
(4, 1, "Play");
INSERT INTO Songs (SingerId, AlbumId, TrackId, SongName, Duration, SongGenre)
VALUES (2, 1, 1, "Let's Get Back Together", 182, "COUNTRY"),
(2, 1, 2, "Starting Again", 156, "ROCK"),
(2, 1, 3, "I Knew You Were Magic", 294, "BLUES"),
(2, 1, 4, "42", 185, "CLASSICAL"),
(2, 1, 5, "Blue", 238, "BLUES"),
(2, 1, 6, "Nothing Is The Same", 303, "BLUES"),
(2, 1, 7, "The Second Time", 255, "ROCK"),
(2, 3, 1, "Fight Story", 194, "ROCK"),
(3, 1, 1, "Not About The Guitar", 278, "BLUES");
Spanner はデータを複数のスプリットに分割するので、効率的な実行プランを取得するのは簡単ではありません。スプリットは相互に独立して移動でき、異なるサーバーに割り当てることができます。サーバーは異なる物理的なロケーションに存在することもあります。分散データに対して実行プランを評価するため、Spanner は以下に基づく実行を使用します。
- データを含むサーバーでのサブプランのローカルな実行
- 積極的な分散プルーニングによる複数のリモート実行のオーケストレーションと集約
Spanner は、このモデルを実現するためにプリミティブ演算子 distributed union とその派生形である distributed cross apply と distributed outer apply を使用します。
サンプリングされたクエリプラン
Spanner のサンプリングされたクエリプランを使用すると、過去のクエリプランのサンプルを表示し、クエリのパフォーマンスの推移を比較できます。すべてのクエリでサンプリングされたクエリプランが利用できるとは限りません。CPU の消費量が多いクエリのみサンプリングされる場合があります。Spanner クエリプランのサンプルのデータの保持期間は 30 日間です。クエリプランのサンプルは、 Google Cloud コンソールの [Query Insights] ページで確認できます。手順については、サンプリングされたクエリプランを表示するをご覧ください。
サンプリングされたクエリプランの構造は、通常のクエリ実行プランと同じです。視覚的なプランを理解し、クエリのデバッグに使用する方法については、クエリプラン ビジュアライザの概要をご覧ください。
サンプリングされたクエリプランの一般的なユースケース:
サンプリングされたクエリプランの一般的なユースケースには、次のようなものがあります。
- スキーマの変更(インデックスの追加や削除など)によるクエリプランの変更を観測する。
- オプティマイザーのバージョンの更新によるクエリプランの変更を観測する。
- 新しいオプティマイザーの統計情報によるクエリプランの変更を観測する。この統計情報は 3 日ごとに自動的に収集されるか、
ANALYZEコマンドを使用して手動で実行されます。
時間の経過とともにクエリのパフォーマンスに大きな変化がある場合や、クエリのパフォーマンスを向上させたい場合は、SQL のベスト プラクティスを参照して、Spanner での効率的な実行計画の策定に役立つ最適化されたクエリ ステートメントを構築してください。
クエリのライフサイクル
Spanner の SQL クエリは、最初に実行プランにコンパイルされた後、実行のために最初のルートサーバーに送信されます。ルートサーバーは、クエリ対象のデータに到達するためのホップ数が最小になるように選択されます。ルートサーバーでは次の処理が行われます。
- サブプランのリモート実行を開始します(必要な場合)
- リモート実行からの結果を待機します
- 結果の集計など、残っているローカル実行ステップを処理します
- クエリの結果を返します
サブプランを受け取ったリモート サーバーは、そのサブプランに対する「ルート」サーバーとなり、最上位のルートサーバーと同じモデルに従います。結果はリモート実行のツリーです。概念的には、クエリの実行は上位から下位に向かって行われ、クエリ結果は下位から上位に向かって返されます。次の図は、このパターンを示しています。

次の例ではこのパターンをさらに詳細に説明します。
集計クエリ
集計クエリは GROUP BY クエリを実装します。
たとえば、次のクエリについて考えます。
SELECT s.SingerId, COUNT(*) AS SongCount
FROM Songs AS s
WHERE s.SingerId < 100
GROUP BY s.SingerId;
結果は次のようになります。
+----------+-----------+
| SingerId | SongCount |
+----------+-----------+
| 3 | 1 |
| 2 | 8 |
+----------+-----------+
概念的には、実行プランは次のようになります。
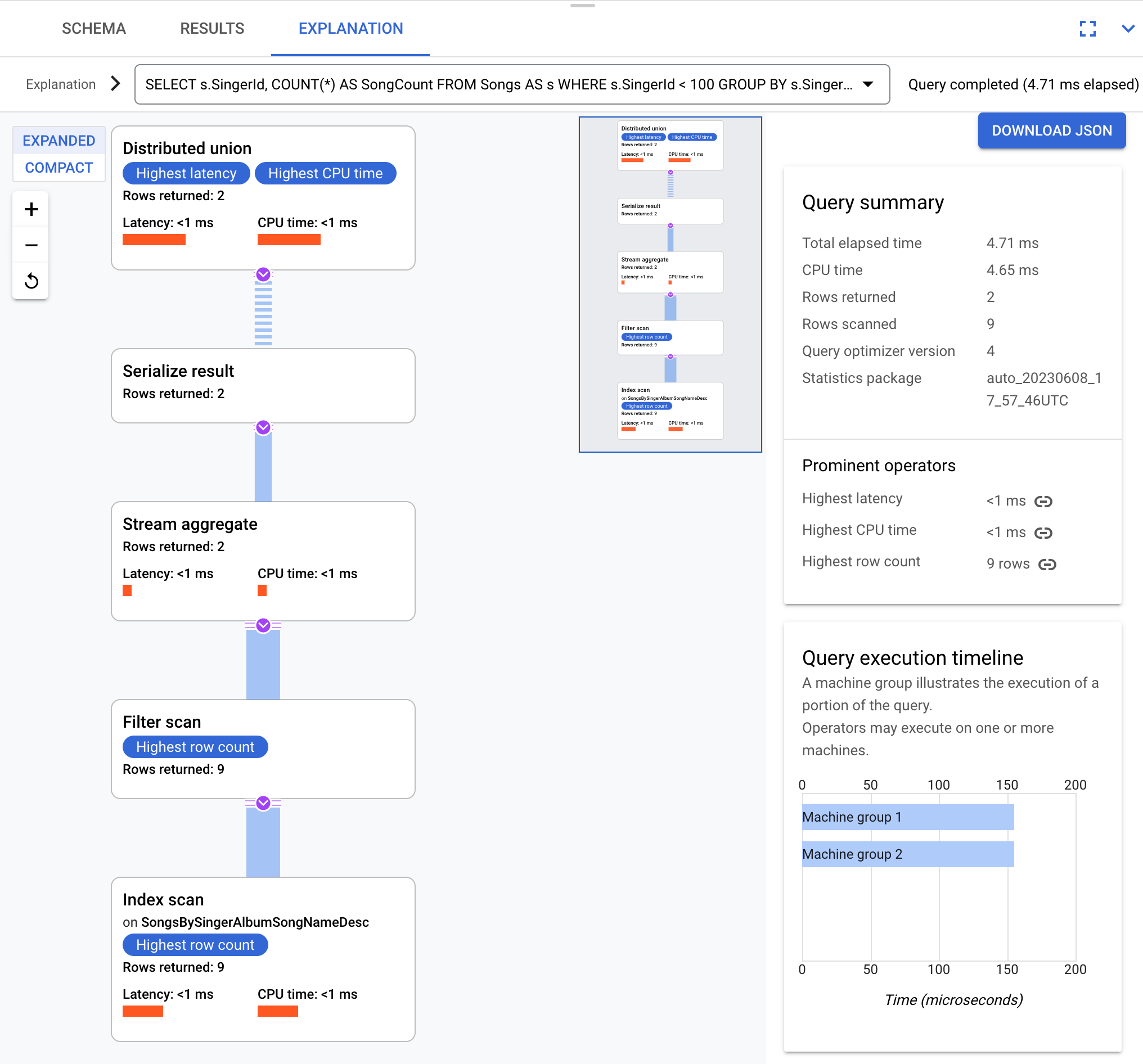
Spanner は、実行プランをルートサーバーに送信します。ルートサーバーは、クエリの実行を調整し、サブプランのリモート分散を実行します。
この実行プランは分散ユニオンで開始します。この分散ユニオンは、スプリットが SingerId < 100 を満たすリモート サーバーにサブプランを分散させます。個々のスプリットのスキャンが完了すると、ストリーム集計演算子は行を集計して、各 SingerId のカウントを取得します。結果のシリアル化演算子は、結果をシリアル化します。最後に、分散ユニオンは、すべての結果を結合してクエリ結果を返します。
集計の詳細については、集計演算子をご覧ください。
併置結合クエリ
インターリーブされたテーブルは、同じ場所に配置された関連のあるテーブルの行とともに物理的に格納されます。併置結合は、インターリーブされたテーブル間の結合です。併置結合は、インデックスを必要とする結合またはバック結合よりパフォーマンスが向上します。
たとえば、次のクエリについて考えます。
SELECT al.AlbumTitle, so.SongName
FROM Albums AS al, Songs AS so
WHERE al.SingerId = so.SingerId AND al.AlbumId = so.AlbumId;
(このクエリでは、Songs は Albums 内でインターリーブされているものとします。)
結果は次のようになります。
+-----------------------+--------------------------+
| AlbumTitle | SongName |
+-----------------------+--------------------------+
| Nothing To Do With Me | Not About The Guitar |
| Green | The Second Time |
| Green | Starting Again |
| Green | Nothing Is The Same |
| Green | Let's Get Back Together |
| Green | I Knew You Were Magic |
| Green | Blue |
| Green | 42 |
| Terrified | Fight Story |
+-----------------------+--------------------------+
実行プランは次のとおりです。
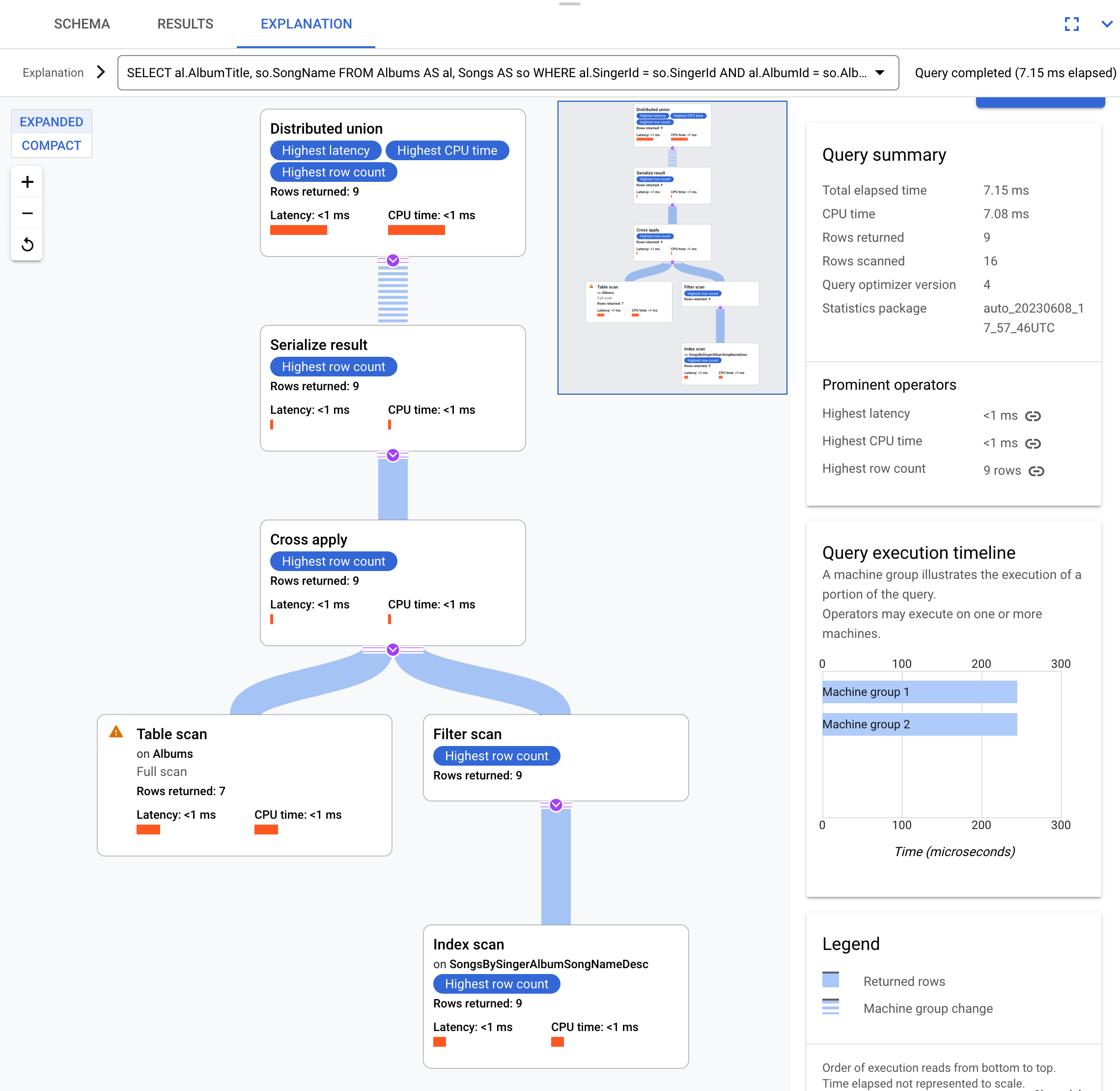
この実行プランは分散ユニオンで開始します。この分散ユニオンは、テーブル Albums のスプリットを含むリモート サーバーにサブプランを分散させます。Songs は Albums のインターリーブされたテーブルなので、各リモート サーバーは、異なるサーバーへの結合を必要とせずに、各リモート サーバー上でサブプラン全体を実行できます。
サブプランにはクロス適用が含まれます。各クロス適用は、テーブル Albums でテーブル スキャン を実行し、SingerId、AlbumId、AlbumTitle を取得します。その後、クロス適用は、テーブル スキャンからの出力を、インデックス SongsBySingerAlbumSongNameDesc でのインデックス スキャンからの出力にマップします。これは、テーブル スキャン出力からの SingerId と一致するインデックスに SingerId のフィルタを適用したものです。各クロス適用は結果を結果のシリアル化演算子に送信します。この演算子は AlbumTitle と SongName のデータをシリアル化し、結果をローカル分散ユニオンに返します。分散ユニオンはローカル分散ユニオンからの結果を集計し、それをクエリ結果として返します。
インデックスとバック結合クエリ
上の例では 2 つのテーブルに対する結合を使用し、1 つのテーブルは他のテーブルにインターリーブされていました。2 つのテーブルまたは 1 つのテーブルと 1 つのインデックスがインターリーブされていない場合、実行プランは複雑になり効率が低下します。
次のコマンドで作成されるインデックスについて考えます。
CREATE INDEX SongsBySongName ON Songs(SongName)
このインデックスを次のクエリで使用します。
SELECT s.SongName, s.Duration
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
結果は次のようになります。
+----------+----------+
| SongName | Duration |
+----------+----------+
| Blue | 238 |
+----------+----------+
実行プランは次のとおりです。
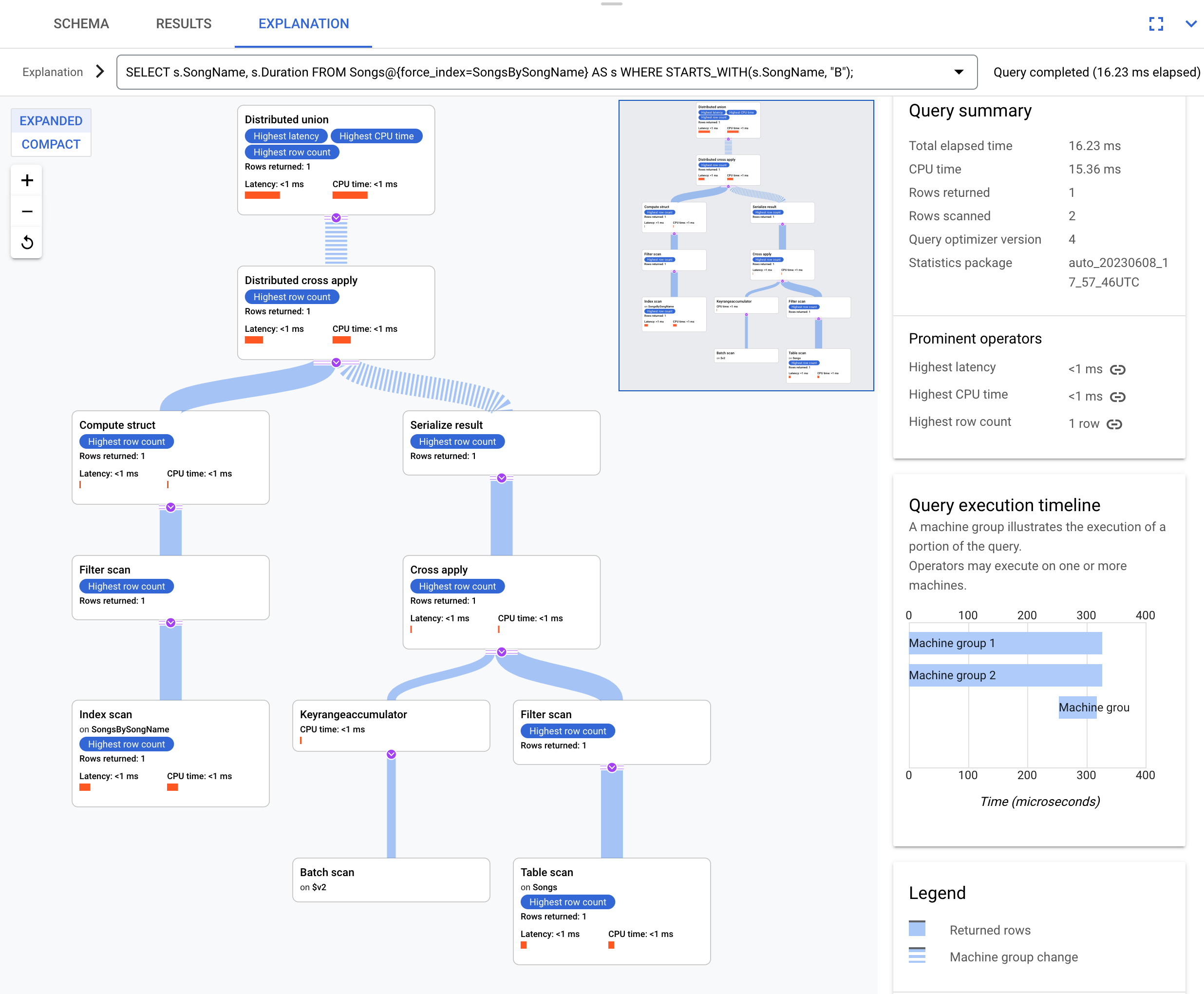
インデックス SongsBySongName には列 Duration が含まれないため、結果の実行プランは複雑です。Duration の値を取得するには、インデックスが作成された結果を Spanner がテーブル Songs にバック結合する必要があります。これは結合ですが、Songs テーブルとグローバル インデックス SongsBySongName はインターリーブされていないので、併置結合ではありません。データが併置されていない場合、Spanner は実行速度を上げるために最適化を行うので、生成される実行プランは併置結合の例より複雑です。
最上位の演算子は分散クロス適用です。この演算子の入力側は、インデックス SongsBySongName からの行のバッチであり、これは述語 STARTS_WITH(s.SongName, "B") を満たします。その後、分散クロス適用は、これらのバッチを、スプリットに Duration データが含まれるリモート サーバーにマップします。リモート サーバーは、テーブル スキャンを使用して Duration 列を取得します。テーブル スキャンは、Condition:($Songs_key_TrackId' =
$batched_Songs_key_TrackId) フィルタを使用します。このフィルタは、Songs テーブルからの TrackId を、インデックス SongsBySongName からバッチ化された行の TrackId に結合します。
結果は、最終的なクエリ応答に集計されます。一方、分散クロス適用の入力側には、述語 STARTS_WITH を満たすインデックスからの行を評価するための分散ユニオン / ローカル分散ユニオンのペアが含まれます。
次のような少し異なるクエリについて考えます。このクエリでは s.Duration 列を選択しません。
SELECT s.SongName
FROM Songs@{force_index=SongsBySongName} AS s
WHERE STARTS_WITH(s.SongName, "B");
次の実行プランで示すように、このクエリはインデックスを完全に利用できます。
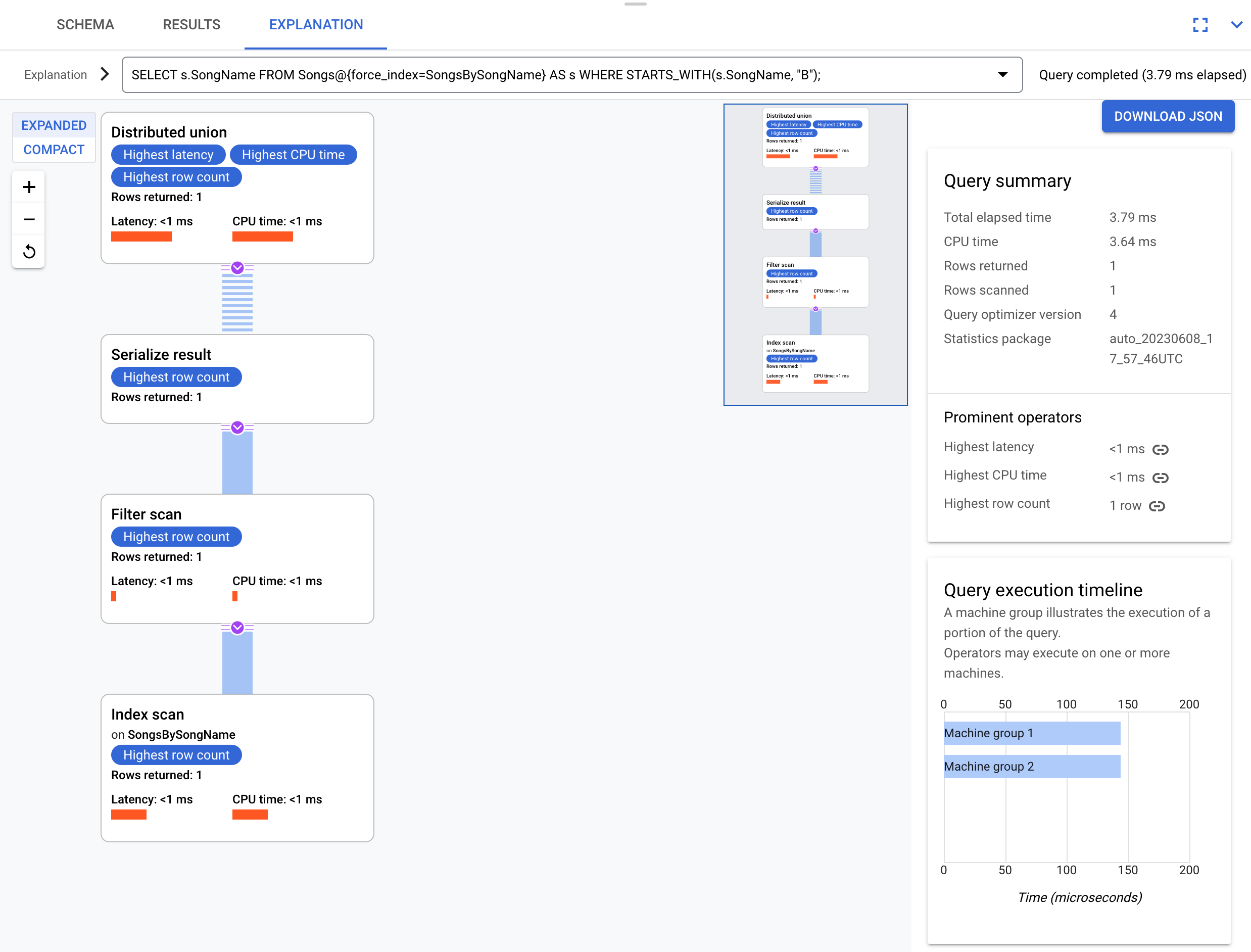
この実行プランでは、クエリによって要求されるすべての列がインデックスに存在するので、バック結合は必要ありません。
次のステップ
クエリ実行演算子について学習する
Spanner のクエリ オプティマイザーについて学習する
クエリ オプティマイザーを管理する方法を学習する