本頁說明如何將 NoSQL 資料庫從 Cassandra 遷移至 Spanner。
Cassandra 和 Spanner 都是大規模分散式資料庫,專為需要高擴充性和低延遲時間的應用程式而建。雖然這兩種資料庫都支援要求嚴苛的 NoSQL 工作負載,但 Spanner 提供資料模型化、查詢和交易作業的進階功能。Spanner 支援 Cassandra 查詢語言 (CQL)。
如要進一步瞭解 Spanner 如何符合 NoSQL 資料庫條件,請參閱「適用於非關聯式工作負載的 Spanner」。
遷移限制條件
如要順利從 Cassandra 遷移至 Spanner 上的 Cassandra 端點,請參閱「Spanner for Cassandra users」,瞭解 Spanner 架構、資料模型和資料類型與 Cassandra 的差異。開始遷移作業前,請先仔細考量 Spanner 和 Cassandra 之間的功能差異。
遷移流程
遷移程序可細分為下列步驟:
- 轉換結構定義和資料模型。
- 為傳入資料設定雙重寫入。
- 從 Cassandra 大量匯出歷來資料至 Spanner。
- 驗證資料,確保整個遷移程序中的資料完整性。
- 將應用程式指向 Spanner,而非 Cassandra。
- (選用步驟) 從 Spanner 對 Cassandra 執行反向複製作業。
轉換結構定義和資料模型
從 Cassandra 遷移資料至 Spanner 的第一步,是將 Cassandra 資料結構定義調整為 Spanner 的結構定義,同時處理資料類型和模型建立方面的差異。
Cassandra 和 Spanner 的資料表宣告語法相當類似。您可指定資料表名稱、資料欄名稱和類型,以及唯一識別資料列的主鍵。主要差異在於 Cassandra 是雜湊分區,並區分主鍵的兩個部分:雜湊分區鍵和排序叢集欄,而 Spanner 則是範圍分區。您可以將 Spanner 的主鍵視為只有叢集資料欄,系統會在幕後自動維護分割區。與 Cassandra 類似,Spanner 支援複合主鍵。
建議您按照下列步驟,將 Cassandra 資料結構定義轉換為 Spanner:
- 請參閱 Cassandra 總覽,瞭解 Cassandra 和 Spanner 資料結構定義的相似與不同之處,以及如何對應不同的資料類型。
- 使用 Cassandra 至 Spanner 結構定義工具,擷取 Cassandra 資料結構定義並轉換為 Spanner。
- 開始遷移資料前,請確認已使用適當的資料結構定義建立 Spanner 表格。
設定即時遷移傳入資料
如要從 Cassandra 遷移至 Spanner,且停機時間為零,請為傳入資料設定即時遷移。即時遷移技術著重於盡量縮短停機時間,並透過即時複製功能確保應用程式持續可用。
請先進行即時遷移程序,再進行大量遷移。下圖顯示即時遷移的架構視圖。
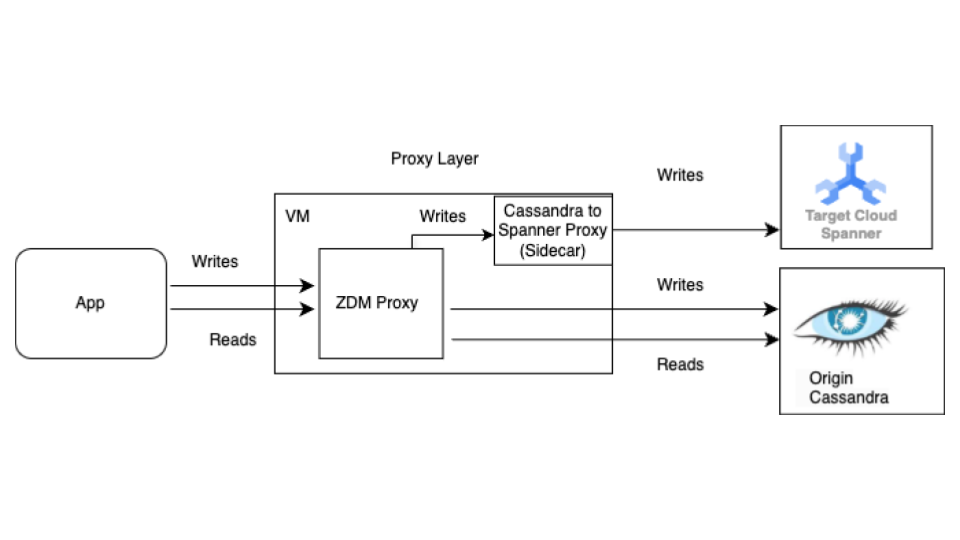
即時遷移架構包含下列重要元件:
- 來源:來源 Cassandra 資料庫。
- 目標:要遷移至的目標 Spanner 資料庫。假設您已佈建 Spanner 執行個體和資料庫,且結構定義與 Cassandra 結構定義相容 (並已根據 Spanner 的資料模型和功能進行必要調整)。
Datastax ZDM Proxy: ZDM Proxy 是由 DataStax 建構的雙重寫入 Proxy,適用於 Cassandra 對 Cassandra 的遷移作業。Proxy 會模擬 Cassandra 叢集,讓應用程式使用 Proxy,而不必變更應用程式。應用程式會與這項工具通訊,並在內部使用這項工具,對來源和目標資料庫執行雙重寫入作業。雖然這項工具通常會搭配 Cassandra 叢集使用,做為來源和目標,但我們的設定會將 Cassandra-Spanner Proxy (以 Sidecar 形式執行) 設為目標。這樣可確保每個傳入的讀取作業只會轉送至來源,並將來源回應傳回應用程式。此外,每個傳入的寫入作業都會導向來源和目標。
- 如果來源和目標的寫入作業都成功,應用程式就會收到成功訊息。
- 如果寫入來源失敗,但寫入目標成功,應用程式會收到來源的失敗訊息。
- 如果寫入目標失敗,但寫入來源成功,應用程式會收到目標的失敗訊息。
- 如果寫入來源和目標都失敗,應用程式會收到來源的失敗訊息。
Cassandra-Spanner Proxy: 攔截傳送至 Cassandra 的 Cassandra 查詢語言 (CQL) 流量,並將其轉換為 Spanner API 呼叫的輔助應用程式。應用程式和工具可透過 Cassandra 用戶端與 Spanner 互動。
用戶端應用程式:讀取及寫入來源 Cassandra 叢集資料的應用程式。
設定 Proxy
執行即時遷移的第一步是部署及設定 Proxy。Cassandra-Spanner Proxy 會以 ZDM Proxy 的邊車形式執行。側車 Proxy 會做為 ZDM Proxy 寫入 Spanner 作業的目標。
使用 Docker 進行單一執行個體測試
您可以在本機或 VM 上執行單一 Proxy 執行個體,以便使用 Docker 進行初步測試。
必要條件
- 確認執行 Proxy 的 VM 與應用程式、原始 Cassandra 資料庫和 Spanner 資料庫之間有網路連線。
- 安裝 Docker。
- 確認服務帳戶金鑰檔案具備寫入 Spanner 執行個體和資料庫的必要權限。
- 設定 Spanner 執行個體、資料庫和結構定義。
- 確認 Spanner 資料庫名稱與原始 Cassandra 鍵空間名稱相同。
- 複製 spanner-migration-tool 存放區。
下載及設定 ZDM Proxy
- 前往
sources/cassandra目錄。 - 確認
entrypoint.sh和Dockerfile檔案與 Dockerfile 位於同一目錄中。 執行下列指令來建構本機映像檔:
docker build -t zdm-proxy:latest .
執行 ZDM Proxy
- 請確認
zdm-config.yaml和keyfiles位於執行下列指令的本機。 - 開啟範例 zdm-config.yaml 檔案。
- 請參閱詳細的旗標清單,瞭解 ZDM 接受的旗標。
使用下列指令執行容器:
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
確認 Proxy 設定
使用
docker logs指令檢查 Proxy 記錄,瞭解啟動期間是否有任何錯誤:docker logs container-id執行
cqlsh指令,確認 Proxy 設定正確無誤:cqlsh VM-IP 14002將 VM-IP 替換為 VM 的 IP 位址。
使用 Terraform 設定正式環境:
在實際工作環境中,建議使用提供的 Terraform 範本,自動化調度管理 Cassandra-Spanner 代理程式的部署作業。
必要條件
- 安裝 Terraform。
- 確認應用程式具有預設憑證,且具備建立資源的適當權限。
- 確認服務金鑰檔案具備寫入 Spanner 的相關權限。這個檔案是由 Proxy 使用。
- 設定 Spanner 執行個體、資料庫和結構定義。
- 確認 Dockerfile、
entrypoint.sh和服務金鑰檔案與main.tf檔案位於同一目錄中。
設定 Terraform 變數
- 確認您擁有用於部署 Proxy 的 Terraform 範本。
- 使用設定的變數更新
terraform.tfvars檔案。
使用 Terraform 部署範本
Terraform 指令碼會執行下列作業:
- 根據指定數量建立容器最佳化 VM。
- 為每個 VM 建立
zdm-config.yaml檔案,並為其分配拓撲索引。ZDM Proxy 需要多個 VM 設定,才能使用設定yaml檔案中的PROXY_TOPOLOGY_ADDRESSES和PROXY_TOPOLOGY_INDEX欄位設定拓撲。 - 將相關檔案轉移至各個 VM、從遠端執行 Docker 建構作業,並啟動容器。
如要部署範本,請按照下列步驟操作:
使用
terraform init指令初始化 Terraform:terraform init執行
terraform plan指令,查看 Terraform 預計對基礎架構進行哪些變更:terraform plan -var-file="terraform.tfvars"確認資源沒問題後,請執行
terraform apply指令:terraform apply -var-file="terraform.tfvars"Terraform 指令碼停止後,請執行
cqlsh指令,確保 VM 可供存取。cqlsh VM-IP 14002將 VM-IP 替換為 VM 的 IP 位址。
將用戶端應用程式指向 ZDM Proxy
修改用戶端應用程式的設定,將聯絡點設為執行 Proxy 的 VM,而非原始 Cassandra 叢集。
全面測試應用程式。確認寫入作業已套用至原始 Cassandra 叢集,並檢查 Spanner 資料庫,確認作業也已透過 Cassandra-Spanner Proxy 傳送至 Spanner。系統會從原始 Cassandra 提供讀取作業。
大量匯出資料至 Spanner
大量資料遷移是指在資料庫之間轉移大量資料,通常需要仔細規劃和執行,才能盡量縮短停機時間並確保資料完整性。這些技術包括 ETL (擷取、轉換、載入) 程序、直接資料庫複製,以及專用遷移工具,目的都是有效率地移動資料,同時保留資料結構和準確度。
建議使用 Spanner 的 SourceDB To Spanner Dataflow 範本,將資料從 Cassandra 大量遷移至 Spanner。Dataflow 是分散式擷取、轉換及載入 (ETL) 服務,可提供平台來執行資料管道,以便在多部機器上平行讀取和處理大量資料。 Google Cloud SourceDB To Spanner Dataflow 範本的設計,是為了從 Cassandra 執行高度平行化的讀取作業、視需要轉換來源資料,以及寫入 Spanner 做為目標資料庫。
使用 Cassandra 設定檔,按照「從 Cassandra 大量遷移至 Spanner」一文中的步驟操作。
驗證資料,確保完整性
在資料庫遷移期間進行資料驗證,對於確保資料準確性和完整性至關重要。這項作業會比較來源 Cassandra 和目標 Spanner 資料庫之間的資料,找出差異,例如遺失、損毀或不相符的資料。一般資料驗證技術包括檢查碼、列數和詳細資料比較,目的都是為了確保遷移的資料能準確呈現原始資料。
大量資料遷移完成後,在雙重寫入仍處於啟用狀態時,您需要驗證資料一致性並修正差異。在雙重寫入階段,Cassandra 和 Spanner 可能會因為各種原因出現差異,包括:
- 雙重寫入失敗。由於暫時性網路問題或其他錯誤,寫入作業可能在一個資料庫中成功,但在另一個資料庫中失敗。
- 輕量交易 (LWT)。如果應用程式使用 LWT (比較並設定) 作業,這些作業可能會在一個資料庫中成功,但在另一個資料庫中失敗,這是因為資料集有所差異。
- 單一主鍵的每秒查詢次數 (QPS) 較高。如果對相同分割區鍵的寫入負載非常高,由於網路往返時間不同,來源和目標的事件順序可能會有所差異,進而導致不一致。
大量工作和雙重寫入作業並行執行:大量遷移作業與雙重寫入作業並行執行時,可能會因各種競爭條件而導致差異,例如:
- Spanner 上的額外資料列:如果大量遷移作業在雙重寫入作業啟用時執行,應用程式可能會刪除已由大量遷移作業讀取並寫入目標的資料列。
- 大量寫入和雙重寫入之間的競爭狀況:可能還有其他雜項競爭狀況,例如大量工作從 Cassandra 讀取資料列,而雙重寫入完成後,傳入的寫入作業更新 Spanner 上的資料列,導致資料列中的資料過時。
- 部分資料欄更新:更新現有資料列的部分資料欄時,系統會在 Spanner 中建立項目,其他資料欄則為空值。由於大量更新不會覆寫現有資料列,因此 Cassandra 和 Spanner 之間的資料列會有所差異。
這個步驟的重點是驗證及比對來源和目標資料庫之間的資料。驗證是比較來源和目標,找出不一致之處;協調則是著重於解決這些不一致之處,以確保資料一致性。
比較 Cassandra 和 Spanner 的資料
建議您驗證列數和列的實際內容。
選擇如何比較資料 (包括計數和資料列比對) 取決於應用程式對資料不一致的容許程度,以及對精確驗證的要求。
驗證資料的方式有兩種:
雙重寫入作業啟用時,系統會執行主動驗證。在此情境中,資料庫中的資料仍在更新。Cassandra 和 Spanner 之間的資料列計數或資料列內容可能無法完全一致。目標是確保差異只來自資料庫上的有效負載,而非其他錯誤。如果差異在這些限制內,即可繼續進行轉換。
靜態驗證需要停機時間。如果您的需求是進行嚴格的靜態驗證,並確保資料完全一致,可能需要暫時停止對兩個資料庫的所有寫入作業。然後,您可以在 Spanner 資料庫中驗證資料並調解差異。
根據資料一致性和可接受的停機時間,選擇驗證時間和適當的工具。
比較 Cassandra 和 Spanner 中的資料列數
資料驗證方法之一是比較來源和目標資料庫中資料表的資料列數。您可以透過下列幾種方式執行計數驗證:
如果遷移的資料集較小 (每個資料表少於 1 千萬列),可以使用這個計數比對指令碼計算 Cassandra 和 Spanner 中的資料列。這種方法可在短時間內傳回確切的計數值。Cassandra 的預設逾時時間為 10 秒。如果指令碼在完成計數前逾時,請考慮提高驅動程式要求逾時和伺服器端逾時。
遷移大型資料集 (每個資料表超過 1,000 萬列) 時,請注意,雖然 Spanner 計數查詢可順利擴充,但 Cassandra 查詢往往會逾時。在這種情況下,建議使用 DataStax Bulk Loader 工具,從 Cassandra 表格取得資料列計數。對於 Spanner 計數,使用 SQL
count(*)函式就足以應付大多數的大規模負載。建議您針對每個 Cassandra 資料表執行大量載入器,並從 Spanner 資料表擷取計數,然後比較兩者。您可以手動執行這項操作,也可以使用指令碼。
驗證資料列不符的情況
建議您比較來源和目標資料庫中的資料列,找出資料列之間的差異。有兩種方法可以執行列驗證。 您使用的項目取決於應用程式需求:
- 驗證隨機選取的資料列。
- 驗證整個資料集。
驗證隨機資料列樣本
驗證整個資料集既耗時又所費不貲,不適合大型工作負載。在這種情況下,您可以透過抽樣驗證隨機資料子集,檢查資料列是否不相符。其中一種做法是在 Cassandra 中隨機挑選資料列,然後擷取 Spanner 中對應的資料列,再比較值 (或資料列雜湊)。
這個方法的優點是比檢查整個資料集更快完成,而且執行方式很簡單。缺點是,由於這是資料子集,邊緣情況的資料可能仍有差異。
如要從 Cassandra 隨機取樣資料列,請執行下列操作:
- 在權杖範圍 [
-2^63,2^63 - 1] 中產生隨機數字。 - 擷取資料列
WHERE token(PARTITION_KEY) > GENERATED_NUMBER。
validation.go範例指令碼會隨機擷取資料列,並與 Spanner 資料庫中的資料列進行驗證。
驗證整個資料集
如要驗證整個資料集,請擷取來源 Cassandra 資料庫中的所有資料列。使用主鍵擷取所有對應的 Spanner 資料庫資料列。然後比較各列的差異。如果是大型資料集,可以使用以 MapReduce 為基礎的架構 (例如 Apache Spark 或 Apache Beam),可靠且有效率地驗證整個資料集。
這麼做的好處是,完整驗證可提高資料一致性的可信度。缺點是會增加 Cassandra 的讀取負載,且需要投入資源,為大型資料集建構複雜的工具。如果資料集很大,驗證時間可能會更長。
其中一種做法是將權杖範圍分區,並平行查詢 Cassandra 環。系統會使用分區鍵擷取每個 Cassandra 資料列的對應 Spanner 資料列。然後比較這兩列資料的差異。如要瞭解如何建構驗證器工作,請參閱「使用資料列比對驗證 Cassandra 的提示」。
解決資料或列數不一致的問題
視資料一致性需求而定,您可以將資料列從 Cassandra 複製到 Spanner,以解決驗證階段發現的差異。其中一種做法是擴充用於完整資料集驗證的工具,並在發現不符時,將正確的資料列從 Cassandra 複製到目標 Spanner 資料庫。詳情請參閱導入注意事項。
將應用程式指向 Spanner,而非 Cassandra
驗證遷移後資料的準確度和完整性後,請選擇將應用程式遷移至 Spanner 的時間,而非 Cassandra (或用於即時資料遷移的 Proxy 轉接程式)。這就是所謂的轉換。
如要執行轉換作業,請按照下列步驟操作:
為用戶端應用程式建立設定變更,讓應用程式使用下列其中一種方法,直接連線至 Spanner 執行個體:
- 將 Cassandra 連線至以 Sidecar 形式執行的 Cassandra Adapter。
- 使用端點用戶端變更驅動程式 JAR。
套用您在上一個步驟中準備的變更,將應用程式指向 Spanner。
設定應用程式的監控功能,監控錯誤或效能問題。使用 Cloud Monitoring 監控 Spanner 指標。詳情請參閱「使用 Cloud Monitoring 監控執行個體」。
順利完成轉換並穩定運作後,請停用 ZDM Proxy 和 Cassandra-Spanner Proxy 執行個體。
從 Spanner 執行反向複製到 Cassandra
您可以使用 Spanner to
SourceDB Dataflow 範本執行反向複製作業。如果 Spanner 發生無法預料的問題,需要回溯至原始 Cassandra 資料庫,且希望服務中斷時間盡量縮短,反向複製功能就非常實用。
使用資料列比對驗證 Cassandra 的訣竅
在 Cassandra (或其他資料庫) 中使用 SELECT * 執行全資料表掃描,速度緩慢且效率不彰。如要解決這個問題,請將 Cassandra 資料集劃分為可管理的分區,並同時處理這些分區。如要這麼做,請按照下列步驟操作:
將資料集分割為權杖範圍
Cassandra 會根據分割區鍵權杖,將資料分配到各個節點。Cassandra 叢集的權杖範圍從 -2^63 到 2^63 -
1。您可以定義固定數量的同等大小權杖範圍,將整個鍵空間劃分為較小的分割區。建議您使用可設定的 partition_size 參數分割權杖範圍,以便調整參數,快速處理整個範圍。
平行查詢分區
定義權杖範圍後,您可以啟動多個平行程序或執行緒,每個程序或執行緒負責驗證特定範圍內的資料。針對每個範圍,您可以使用分割區鍵 (pk) 上的 token() 函式建構 CQL 查詢。
以下是指定權杖範圍的查詢範例:
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
透過疊代定義的權杖範圍,並針對原始 Cassandra 叢集 (或透過設定為從 Cassandra 讀取的 ZDM 代理伺服器) 平行執行這些查詢,您就能以分散式方式有效讀取資料。
讀取每個分區內的資料
每個平行程序都會執行以範圍為準的查詢,並從 Cassandra 擷取部分資料。檢查擷取的資料分割區數量,確保平行處理和記憶體用量之間達到平衡。
從 Spanner 擷取對應資料列
針對從 Cassandra 擷取的每個資料列,使用來源資料列索引鍵,從目標 Spanner 資料庫擷取對應的資料列。
比較資料列,找出不相符的項目
取得 Cassandra 資料列和對應的 Spanner 資料列 (如有) 後,您需要比較兩者的欄位,找出任何不符之處。這項比較應考量潛在的資料類型差異,以及遷移期間套用的任何轉換。建議您根據應用程式需求,清楚定義不符條件的標準。
設計可擴充性的驗證工具
設計驗證工具時,請考慮是否要擴充工具,以便進行對帳。舉例來說,您可以新增功能,將 Cassandra 中的正確資料寫入 Spanner,以修正已識別的不符項目。
回報並記錄不符情形
建議您記錄所有發現的不符之處,並提供足夠的背景資訊,以利調查及對帳。這可能包括主鍵、不同的特定欄位,以及 Cassandra 和 Spanner 的值。您可能也想匯總找到的不符數量和類型統計資料。
啟用及停用 Cassandra 資料的存留時間
本節說明如何在 Spanner 資料表上啟用及停用 Cassandra 資料的存留時間 (TTL)。如需總覽,請參閱「存留時間 (TTL)」。
啟用 Cassandra 資料的存留時間
本節範例假設您有一個結構定義如下的資料表:
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
如要在現有資料表上啟用資料列層級的存留時間,請執行下列操作:
新增時間戳記資料欄,用於儲存每個資料列的到期時間戳記。 在本範例中,資料欄名為
ExpiredAt,但您可以使用任何名稱。ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;新增資料列刪除政策,自動刪除超過到期時間的資料列。
INTERVAL 0 DAY表示系統會在到期時間一到,立即刪除資料列。ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));將
cassandra_ttl_mode設為row,即可啟用資料列層級的存留時間。ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');您可以選擇設定
cassandra_default_ttl,以設定預設 TTL 值。 這個值以秒為單位。ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
停用 Cassandra 資料的 TTL
本節範例假設您有一個結構定義如下的資料表:
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
如要停用現有資料表的列層級 TTL,請執行下列步驟:
您可以選擇將
cassandra_default_ttl設為零,清除預設存留時間值。ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);將
cassandra_ttl_mode設為none,即可停用資料列層級的存留時間。ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');移除資料列刪除政策。
ALTER TABLE Singers DROP ROW DELETION POLICY;移除到期時間戳記欄。
ALTER TABLE Singers DROP COLUMN ExpiredAt;
實作的考量
- 架構和程式庫:如要進行可擴充的自訂驗證,請使用以 MapReduce 為基礎的架構,例如 Apache Spark 或 Dataflow (Beam)。選擇支援的語言 (Python、Scala、Java),並使用 Cassandra 和 Spanner 的連接器,例如使用 Proxy。這些架構可有效平行處理大型資料集,以進行全面驗證。
- 錯誤處理和重試:實作健全的錯誤處理機制,管理潛在問題,例如網路連線問題或任一資料庫暫時無法使用。建議您針對暫時性失敗實作重試機制。
- 設定:設定權杖範圍、兩個資料庫的連線詳細資料,以及比較邏輯。
- 調整效能:嘗試使用並行程序數量和權杖範圍大小,針對特定環境和資料量調整驗證程序。在驗證期間,監控 Cassandra 和 Spanner 叢集的負載。
後續步驟
- 如要比較 Spanner 和 Cassandra,請參閱 Cassandra 總覽。
- 瞭解如何使用 Cassandra 介面卡連線至 Spanner。