Questa pagina spiega come eseguire la migrazione del tuo database NoSQL da Cassandra a Spanner.
Cassandra e Spanner sono entrambi database distribuiti su larga scala creati per applicazioni che richiedono elevata scalabilità e bassa latenza. Sebbene entrambi i database possano supportare carichi di lavoro NoSQL impegnativi, Spanner offre funzionalità avanzate per la modellazione, l'interrogazione e le operazioni transazionali dei dati. Spanner supporta il Cassandra Query Language (CQL).
Per saperne di più su come Spanner soddisfa i criteri dei database NoSQL, consulta Spanner per carichi di lavoro non relazionali.
Vincoli di migrazione
Per una migrazione riuscita da Cassandra all'endpoint Cassandra su Spanner, consulta Spanner per gli utenti Cassandra per scoprire in che modo l'architettura, modello dei dati e i tipi di dati di Spanner differiscono da Cassandra. Valuta attentamente le differenze funzionali tra Spanner e Cassandra prima di iniziare la migrazione.
Processo di migrazione
La procedura di migrazione è suddivisa nei seguenti passaggi:
- Converti lo schema e il modello di dati.
- Configura la doppia scrittura per i dati in entrata.
- Esporta collettivamente i dati storici da Cassandra a Spanner.
- Convalida i dati per garantire la loro integrità durante l'intero processo di migrazione.
- Punta l'applicazione a Spanner anziché a Cassandra.
- Facoltativo. Esegui la replica inversa da Spanner a Cassandra.
Converti lo schema e il modello dei dati
Il primo passaggio per la migrazione dei dati da Cassandra a Spanner consiste nell'adattare lo schema dei dati di Cassandra allo schema di Spanner, gestendo le differenze nei tipi di dati e nella modellazione.
La sintassi della dichiarazione della tabella è abbastanza simile in Cassandra e Spanner. Specifichi il nome della tabella, i nomi e i tipi delle colonne e la chiave primaria che identifica in modo univoco una riga. La differenza principale è che Cassandra è partizionata in base all'hash e distingue tra le due parti della chiave primaria: la chiave di partizione con hash e le colonne di clustering ordinate, mentre Spanner è partizionato in base all'intervallo. Puoi considerare la chiave primaria di Spanner come se avesse solo colonne di clustering, con le partizioni gestite automaticamente in background. Come Cassandra, Spanner supporta le chiavi primarie composite.
Ti consigliamo di seguire questi passaggi per convertire lo schema dei dati Cassandra in Spanner:
- Consulta la panoramica di Cassandra per comprendere le somiglianze e le differenze tra gli schemi di dati di Cassandra e Spanner e per scoprire come mappare diversi tipi di dati.
- Utilizza lo strumento di conversione dello schema da Cassandra a Spanner per estrarre e convertire lo schema dei dati Cassandra in Spanner.
- Prima di iniziare la migrazione dei dati, assicurati che le tabelle Spanner siano state create con gli schemi di dati appropriati.
Configurare la migrazione live per i dati in entrata
Per eseguire una migrazione senza tempi di inattività da Cassandra a Spanner, configura la migrazione live per i dati in entrata. La migrazione live si concentra sulla riduzione al minimo del tempo di inattività e sulla garanzia della disponibilità continua delle applicazioni utilizzando la replica in tempo reale.
Inizia con il processo di migrazione live prima della migrazione collettiva. Il seguente diagramma mostra la visualizzazione dell'architettura di una migrazione live.
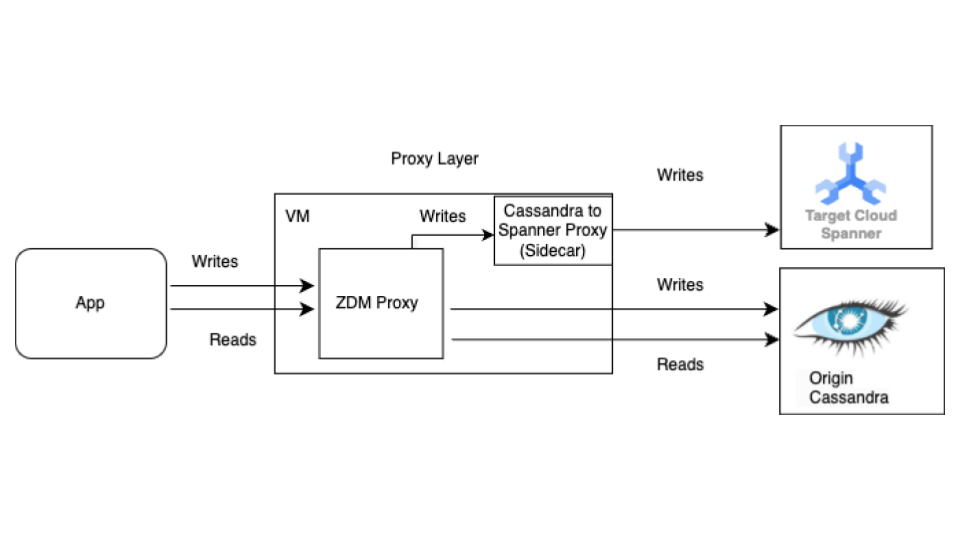
L'architettura di migrazione live ha i seguenti componenti chiave:
- Origine:il database Cassandra di origine.
- Destinazione:il database Spanner di destinazione a cui stai eseguendo la migrazione. Si presuppone che tu abbia già eseguito il provisioning dell' istanza Spanner e del database con uno schema compatibile con lo schema Cassandra (con gli adattamenti necessari per il modello dei dati e le funzionalità di Spanner).
Proxy ZDM di DataStax: il proxy ZDM è un proxy a doppia scrittura creato da DataStax per le migrazioni da Cassandra a Cassandra. Il proxy simula un cluster Cassandra, il che consente a un'applicazione di utilizzarlo senza modifiche. Questo strumento è quello con cui comunica la tua applicazione e che utilizza internamente per eseguire scritture doppie nei database di origine e di destinazione. Sebbene venga in genere utilizzato con i cluster Cassandra sia come origine che come destinazione, la nostra configurazione lo configura per utilizzare il proxy Cassandra-Spanner (in esecuzione come sidecar) come destinazione. In questo modo, ogni lettura in entrata viene inoltrata solo all'origine e la risposta dell'origine viene restituita all'applicazione. Inoltre, ogni scrittura in entrata viene indirizzata sia all'origine che alla destinazione.
- Se le scritture sia nell'origine che nella destinazione vanno a buon fine, l'applicazione riceve un messaggio di esito positivo.
- Se le scritture sull'origine non riescono e quelle sulla destinazione vanno a buon fine, l'applicazione riceve il messaggio di errore dell'origine.
- Se le scritture sulla destinazione non riescono e quelle sull'origine vanno a buon fine, l'applicazione riceve il messaggio di errore della destinazione.
- Se le scritture sia nell'origine che nella destinazione non vanno a buon fine, l'applicazione riceve il messaggio di errore dell'origine.
Proxy Cassandra-Spanner: Un'applicazione sidecar che intercetta il traffico Cassandra Query Language (CQL) destinato a Cassandra e lo traduce in chiamate API Spanner. Consente ad applicazioni e strumenti di interagire con Spanner utilizzando il client Cassandra.
Applicazione client:l'applicazione che legge e scrive dati nel cluster Cassandra di origine.
configurazione del proxy
Il primo passaggio per eseguire una migrazione live consiste nel deployment e nella configurazione dei proxy. Il proxy Cassandra-Spanner viene eseguito come sidecar del proxy ZDM. Il proxy sidecar funge da destinazione per le operazioni di scrittura del proxy ZDM in Spanner.
Test di una singola istanza utilizzando Docker
Puoi eseguire una singola istanza del proxy localmente o su una VM per i test iniziali utilizzando Docker.
Prerequisiti
- Verifica che la VM in cui viene eseguito il proxy abbia connettività di rete all'applicazione, al database Cassandra di origine e al database Spanner.
- Installa Docker.
- Verifica che esista un file di chiavi del account di servizio con le autorizzazioni necessarie per scrivere nell'istanza e nel database Spanner.
- Configura l'istanza, il database e lo schema Spanner.
- Assicurati che il nome del database Spanner sia uguale al nome dello spazio delle chiavi Cassandra di origine.
- Clona il repository spanner-migration-tool.
Scaricare e configurare il proxy ZDM
- Vai alla directory
sources/cassandra. - Assicurati che i file
entrypoint.sheDockerfilesi trovino nella stessa directory del Dockerfile. Esegui questo comando per creare un'immagine locale:
docker build -t zdm-proxy:latest .
Esegui il proxy ZDM
- Assicurati che
zdm-config.yamlekeyfilessiano presenti localmente dove viene eseguito il comando seguente. - Apri il file zdm-config yaml di esempio.
- Consulta l'elenco dettagliato dei flag accettati da ZDM.
Utilizza il seguente comando per eseguire il container:
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
Verificare la configurazione del proxy
Utilizza il comando
docker logsper controllare la presenza di errori nei log del proxy durante l'avvio:docker logs container-idEsegui il comando
cqlshper verificare che il proxy sia configurato correttamente:cqlsh VM-IP 14002Sostituisci VM-IP con l'indirizzo IP della tua VM.
Configurazione di produzione utilizzando Terraform:
Per un ambiente di produzione, ti consigliamo di utilizzare i modelli Terraform forniti per orchestrare il deployment del proxy Cassandra-Spanner.
Prerequisiti
- Installa Terraform.
- Verifica che l'applicazione disponga di credenziali predefinite con autorizzazioni appropriate per creare risorse.
- Verifica che il file della chiave di servizio disponga delle autorizzazioni pertinenti per scrivere in Spanner. Questo file viene utilizzato dal proxy.
- Configura l'istanza, il database e lo schema Spanner.
- Verifica che il Dockerfile,
entrypoint.she il file della chiave di servizio si trovino nella stessa directory del filemain.tf.
Configura le variabili Terraform
- Assicurati di avere il modello Terraform per il deployment del proxy.
- Aggiorna il file
terraform.tfvarscon le variabili per la tua configurazione.
Deployment del modello utilizzando Terraform
Lo script Terraform esegue le seguenti operazioni:
- Crea VM ottimizzate per i container in base a un conteggio specificato.
- Crea file
zdm-config.yamlper ogni VM e assegna un indice di topologia. ZDM Proxy richiede configurazioni multi-VM per configurare la topologia utilizzando i campiPROXY_TOPOLOGY_ADDRESSESePROXY_TOPOLOGY_INDEXnel file di configurazioneyaml. - Trasferisce i file pertinenti a ogni VM, esegue Docker Build in remoto e avvia i container.
Per eseguire il deployment del modello:
Utilizza il comando
terraform initper inizializzare Terraform:terraform initEsegui il comando
terraform planper vedere quali modifiche Terraform prevede di apportare alla tua infrastruttura:terraform plan -var-file="terraform.tfvars"Quando le risorse sono a posto, esegui il comando
terraform apply:terraform apply -var-file="terraform.tfvars"Dopo l'arresto dello script Terraform, esegui il comando
cqlshper assicurarti che le VM siano accessibili.cqlsh VM-IP 14002Sostituisci VM-IP con l'indirizzo IP della tua VM.
Indirizza le applicazioni client al proxy ZDM
Modifica la configurazione dell'applicazione client impostando i punti di contatto come le VM che eseguono i proxy anziché il cluster Cassandra di origine.
Testa l'applicazione con attenzione. Verifica che le operazioni di scrittura vengano applicate sia al cluster Cassandra di origine sia, controllando il database Spanner, che raggiungano anche Spanner utilizzando il proxy Cassandra-Spanner. Le letture vengono pubblicate dall'origine Cassandra.
Esportare collettivamente i dati in Spanner
La migrazione collettiva dei dati comporta il trasferimento di grandi volumi di dati tra i database, spesso richiedendo un'attenta pianificazione ed esecuzione per ridurre al minimo i tempi di inattività e garantire l'integrità dei dati. Le tecniche includono processi ETL (estrazione, trasformazione e caricamento), replicazione diretta del database e strumenti di migrazione specializzati, tutti volti a spostare i dati in modo efficiente preservandone la struttura e l'accuratezza.
Ti consigliamo di utilizzare il modello Dataflow SourceDB To Spanner di Spanner per eseguire la migrazione collettiva dei dati da Cassandra a Spanner. Dataflow è il Google Cloud servizio di estrazione, trasformazione e caricamento (ETL) distribuito che fornisce una piattaforma per l'esecuzione di pipeline di dati per leggere ed elaborare grandi quantità di dati in parallelo su più macchine. Il modello Dataflow SourceDB To Spanner è progettato per eseguire letture altamente parallelizzate da Cassandra, trasformare i dati di origine in base alle esigenze e scrivere in Spanner come database di destinazione.
Esegui i passaggi descritti nelle istruzioni per la migrazione collettiva da Cassandra a Spanner utilizzando il file di configurazione di Cassandra.
Convalidare i dati per garantirne l'integrità
La convalida dei dati durante la migrazione del database è fondamentale per garantirne l'accuratezza e l'integrità. Consiste nel confrontare i dati tra i database Cassandra di origine e Spanner di destinazione per identificare discrepanze, ad esempio dati mancanti, danneggiati o non corrispondenti. Le tecniche generali di convalida dei dati includono checksum, conteggi delle righe e confronti dettagliati dei dati, tutti volti a garantire che i dati di cui è stata eseguita la migrazione siano una rappresentazione accurata di quelli originali.
Al termine della migrazione collettiva dei dati e mentre le scritture doppie sono ancora attive, devi convalidare la coerenza dei dati e correggere le discrepanze. Durante la fase di doppia scrittura possono verificarsi differenze tra Cassandra e Spanner per vari motivi, tra cui:
- Scritture doppie non riuscite. Un'operazione di scrittura potrebbe riuscire in un database, ma non nell'altro a causa di problemi di rete temporanei o altri errori.
- Transazioni leggere (LWT). Se la tua applicazione utilizza operazioni LWT (confronta e imposta), queste potrebbero riuscire su un database, ma non sull'altro a causa di differenze nei set di dati.
- Query al secondo (QPS) elevato su una singola chiave primaria. In caso di carichi di scrittura molto elevati sulla stessa chiave di partizione, l'ordine degli eventi potrebbe differire tra l'origine e la destinazione a causa di tempi di andata e ritorno della rete diversi, il che potrebbe portare a incoerenze.
Job collettivo e doppia scrittura eseguiti in parallelo: la migrazione collettiva eseguita in parallelo con la doppia scrittura potrebbe causare divergenze a causa di varie condizioni di competizione, ad esempio:
- Righe aggiuntive su Spanner: se la migrazione collettiva viene eseguita mentre le scritture duali sono attive, l'applicazione potrebbe eliminare una riga che è già stata letta dal job di migrazione collettiva e scritta nella destinazione.
- Condizioni di competizione tra scritture collettive e doppie: potrebbero verificarsi altre condizioni di competizione varie in cui il job collettivo legge una riga da Cassandra e i dati della riga diventano obsoleti quando le scritture in entrata aggiornano la riga su Spanner al termine delle doppie scritture.
- Aggiornamenti parziali delle colonne: l'aggiornamento di un sottoinsieme di colonne in una riga esistente crea una voce in Spanner con le altre colonne impostate su null. Poiché gli aggiornamenti collettivi non sovrascrivono le righe esistenti, le righe divergono tra Cassandra e Spanner.
Questo passaggio si concentra sulla convalida e sulla riconciliazione dei dati tra i database di origine e di destinazione. La convalida prevede il confronto tra l'origine e la destinazione per identificare le incoerenze, mentre la riconciliazione si concentra sulla risoluzione di queste incoerenze per ottenere la coerenza dei dati.
Confronta i dati tra Cassandra e Spanner
Ti consigliamo di eseguire le convalide sia sul conteggio delle righe sia sul contenuto effettivo delle righe.
La scelta della modalità di confronto dei dati (corrispondenza di conteggio e righe) dipende dalla tolleranza della tua applicazione alle incongruenze dei dati e dai tuoi requisiti per la convalida esatta.
Esistono due modi per convalidare i dati:
La convalida attiva viene eseguita mentre le scritture doppie sono attive. In questo scenario, i dati nei tuoi database sono ancora in fase di aggiornamento. Potrebbe non essere possibile ottenere una corrispondenza esatta nel conteggio delle righe o nel contenuto delle righe tra Cassandra e Spanner. L'obiettivo è garantire che le differenze siano dovute solo al carico attivo sui database e non ad altri errori. Se le discrepanze rientrano in questi limiti, puoi procedere con il cutover.
La convalida statica richiede tempi di inattività. Se i tuoi requisiti richiedono una convalida statica e rigorosa con la garanzia di una coerenza esatta dei dati, potresti dover interrompere temporaneamente tutte le scritture in entrambi i database. Puoi quindi convalidare i dati e riconciliare le differenze nel tuo database Spanner.
Scegli il momento della convalida e gli strumenti appropriati in base ai tuoi requisiti specifici di coerenza dei dati e tempi di inattività accettabili.
Confrontare il numero di righe in Cassandra e Spanner
Un metodo di convalida dei dati consiste nel confrontare il numero di righe nelle tabelle dei database di origine e di destinazione. Esistono diversi modi per eseguire le convalide del conteggio:
Quando esegui la migrazione con piccoli set di dati (meno di 10 milioni di righe per tabella), puoi utilizzare questo script di corrispondenza del conteggio per conteggiare le righe in Cassandra e Spanner. Questo approccio restituisce conteggi esatti in breve tempo. Il timeout predefinito in Cassandra è di 10 secondi. Valuta la possibilità di aumentare il timeout della richiesta del driver e il timeout lato server se lo script va in timeout prima di terminare il conteggio.
Quando esegui la migrazione di set di dati di grandi dimensioni (più di 10 milioni di righe per tabella), tieni presente che, mentre le query di conteggio di Spanner vengono scalate correttamente, le query Cassandra tendono a scadere. In questi casi, consigliamo di utilizzare lo strumento DataStax Bulk Loader per ottenere il conteggio delle righe dalle tabelle Cassandra. Per i conteggi di Spanner, l'utilizzo della funzione SQL
count(*)è sufficiente per la maggior parte dei carichi su larga scala. Ti consigliamo di eseguire Bulk Loader per ogni tabella Cassandra, recuperare i conteggi dalla tabella Spanner e confrontarli. Puoi farlo manualmente o utilizzando uno script.
Convalida per una mancata corrispondenza di righe
Ti consigliamo di confrontare le righe dei database di origine e di destinazione per identificare le mancate corrispondenze tra le righe. Esistono due modi per eseguire le convalide delle righe. Quello che utilizzi dipende dai requisiti della tua applicazione:
- Convalida un insieme casuale di righe.
- Convalida l'intero set di dati.
Convalidare un campione casuale di righe
La convalida di un intero set di dati è costosa e richiede molto tempo per i carichi di lavoro di grandi dimensioni. In questi casi, puoi utilizzare il campionamento per convalidare un sottoinsieme casuale dei dati e verificare la presenza di discrepanze nelle righe. Un modo per farlo è scegliere righe casuali in Cassandra e recuperare le righe corrispondenti in Spanner, quindi confrontare i valori (o l'hash della riga).
I vantaggi di questo metodo sono che completi la verifica più rapidamente rispetto al controllo di un intero set di dati ed è semplice da eseguire. Lo svantaggio è che, trattandosi di un sottoinsieme dei dati, potrebbero comunque esserci differenze nei dati presenti per i casi limite.
Per campionare righe casuali da Cassandra, devi:
- Genera numeri casuali nell'intervallo di token [
-2^63,2^63 - 1]. - Recupera righe
WHERE token(PARTITION_KEY) > GENERATED_NUMBER.
Lo validation.goscript di esempio recupera righe in modo casuale e le convalida con le righe nel database Spanner.
Convalidare l'intero set di dati
Per convalidare un intero set di dati, recupera tutte le righe nel database Cassandra di origine. Utilizza le chiavi primarie per recuperare tutte le righe del database Spanner corrispondenti. Puoi quindi confrontare le righe per individuare le differenze. Per i set di dati di grandi dimensioni, puoi utilizzare un framework basato su MapReduce, come Apache Spark o Apache Beam, per convalidare in modo affidabile ed efficiente l'intero set di dati.
Il vantaggio è che la convalida completa offre una maggiore affidabilità della coerenza dei dati. Gli svantaggi sono che aggiunge un carico di lettura su Cassandra e richiede un investimento per creare strumenti complessi per set di dati di grandi dimensioni. Potrebbe anche richiedere molto più tempo per completare la convalida su un set di dati di grandi dimensioni.
Un modo per farlo è partizionare gli intervalli di token ed eseguire query sull'anello Cassandra in parallelo. Per ogni riga Cassandra, viene recuperata la riga Spanner equivalente utilizzando la chiave di partizione. Queste due righe vengono quindi confrontate per verificare la presenza di discrepanze. Per suggerimenti da seguire durante la creazione di job di convalida, consulta Suggerimenti per convalidare Cassandra utilizzando la corrispondenza delle righe.
Riconciliare le incoerenze nei dati o nel conteggio delle righe
A seconda del requisito di coerenza dei dati, puoi copiare le righe da Cassandra a Spanner per riconciliare le discrepanze identificate durante la fase di convalida. Un modo per eseguire la riconciliazione è estendere lo strumento utilizzato per la convalida del set di dati completo e copiare la riga corretta da Cassandra al database Spanner di destinazione se viene rilevata una mancata corrispondenza. Per ulteriori informazioni, vedi Considerazioni sull'implementazione.
Punta la tua applicazione a Spanner anziché a Cassandra
Dopo aver convalidato l'accuratezza e l'integrità dei dati dopo la migrazione, scegli un momento per eseguire la migrazione dell'applicazione in modo che punti a Spanner anziché a Cassandra (o all'adattatore proxy utilizzato per la migrazione dei dati live). Questa operazione viene chiamata cutover.
Per eseguire il cutover, segui questi passaggi:
Crea una modifica della configurazione per l'applicazione client che le consenta di connettersi direttamente all'istanza Spanner utilizzando uno dei seguenti metodi:
- Connetti Cassandra all'adattatore Cassandra in esecuzione come sidecar.
- Modifica il file JAR del driver con il client endpoint.
Applica la modifica preparata nel passaggio precedente per indirizzare l'applicazione a Spanner.
Configura il monitoraggio per la tua applicazione per monitorare errori o problemi di prestazioni. Monitora le metriche di Spanner utilizzando Cloud Monitoring. Per ulteriori informazioni, consulta Monitorare le istanze con Cloud Monitoring.
Dopo un cutover riuscito e un funzionamento stabile, ritira le istanze di ZDM Proxy e Cassandra-Spanner Proxy.
Eseguire la replica inversa da Spanner a Cassandra
Puoi eseguire la replica inversa utilizzando il modello Dataflow
Spanner to
SourceDB.
La replica inversa è utile quando si verificano problemi imprevisti con
Spanner e devi eseguire il failback al database Cassandra
originale con interruzioni minime del servizio.
Suggerimenti per convalidare Cassandra utilizzando la corrispondenza delle righe
Eseguire scansioni complete delle tabelle in Cassandra (o
in qualsiasi altro database) utilizzando SELECT * è lento e inefficiente. Per risolvere questo problema, dividi il set di dati Cassandra in partizioni gestibili ed elabora le partizioni contemporaneamente. Per farlo, devi:
- Dividere il set di dati in intervalli di token
- Partizioni di query in parallelo
- Lettura dei dati all'interno di ogni partizione
- Recuperare le righe corrispondenti da Spanner
- Strumenti di convalida della progettazione per l'estensibilità
- Report e log non corrispondenti
Dividere il set di dati in intervalli di token
Cassandra distribuisce i dati tra i nodi in base ai token della chiave di partizione.
L'intervallo di token per un cluster Cassandra va da -2^63 a 2^63 -
1. Puoi definire un numero fisso di intervalli di token di dimensioni uguali per dividere l'intero spazio delle chiavi in partizioni più piccole. Ti consigliamo di dividere l'intervallo di token
con un parametro partition_size configurabile che puoi ottimizzare per
elaborare rapidamente l'intero intervallo.
Esecuzione di query sulle partizioni in parallelo
Dopo aver definito gli intervalli di token, puoi avviare più processi o
thread paralleli, ognuno responsabile della convalida dei dati all'interno di un intervallo specifico. Per ogni
intervallo, puoi creare query CQL utilizzando la
funzione token()
sulla chiave di partizione (pk).
Una query di esempio per un determinato intervallo di token potrebbe essere simile alla seguente:
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
Iterando gli intervalli di token definiti ed eseguendo queste query in parallelo sul cluster Cassandra di origine (o tramite il proxy ZDM configurato per la lettura da Cassandra), puoi leggere i dati in modo distribuito.
Leggere i dati all'interno di ogni partizione
Ogni processo parallelo esegue la query basata sull'intervallo e recupera un sottoinsieme dei dati da Cassandra. Controlla la quantità di dati recuperati dalla partizione per garantire l'equilibrio tra parallelismo e utilizzo della memoria.
Recupera le righe corrispondenti da Spanner
Per ogni riga recuperata da Cassandra, recupera la riga corrispondente dal database Spanner di destinazione utilizzando la chiave di riga di origine.
Confrontare le righe per identificare le mancate corrispondenze
Dopo aver recuperato sia la riga Cassandra sia la riga Spanner corrispondente (se esiste), devi confrontare i relativi campi per identificare eventuali discrepanze. Questo confronto deve tenere conto delle potenziali differenze tra i tipi di dati e di eventuali trasformazioni applicate durante la migrazione. Ti consigliamo di definire criteri chiari per ciò che costituisce una mancata corrispondenza in base ai requisiti della tua applicazione.
Strumenti di convalida della progettazione per l'estensibilità
Progetta lo strumento di convalida con la possibilità di estenderlo per la riconciliazione. Ad esempio, puoi aggiungere funzionalità per scrivere i dati corretti da Cassandra a Spanner per le mancate corrispondenze identificate.
Segnalare e registrare le mancate corrispondenze
Ti consigliamo di registrare eventuali discrepanze identificate con un contesto sufficiente per consentire l'indagine e la riconciliazione. Questi potrebbero includere le chiavi primarie, i campi specifici che differiscono e i valori di Cassandra e Spanner. Potresti anche voler aggregare le statistiche sul numero e sui tipi di mancata corrispondenza riscontrati.
Attivare e disattivare il TTL sui dati Cassandra
Questa sezione descrive come attivare e disattivare durata (TTL) sui dati Cassandra nelle tabelle Spanner. Per una panoramica, consulta Durata (TTL).
Abilitare il TTL sui dati Cassandra
Per gli esempi in questa sezione, supponiamo di avere una tabella con il seguente schema:
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
Per attivare il TTL a livello di riga in una tabella esistente:
Aggiungi la colonna del timestamp per memorizzare il timestamp di scadenza per ogni riga. In questo esempio, la colonna si chiama
ExpiredAt, ma puoi utilizzare qualsiasi nome.ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;Aggiungi il criterio di eliminazione delle righe per eliminare automaticamente le righe precedenti alla data di scadenza.
INTERVAL 0 DAYsignifica che le righe vengono eliminate immediatamente al raggiungimento dell'ora di scadenza.ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));Imposta
cassandra_ttl_modesurowper attivare il TTL a livello di riga.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');(Facoltativo) Imposta
cassandra_default_ttlper configurare il valore TTL predefinito. Il valore è in secondi.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
Disabilitare il TTL sui dati Cassandra
Per gli esempi in questa sezione, supponiamo di avere una tabella con il seguente schema:
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
Per disattivare il TTL a livello di riga in una tabella esistente:
Se vuoi, imposta
cassandra_default_ttlsu zero per eliminare il valore TTL predefinito.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);Imposta
cassandra_ttl_modesunoneper disattivare il TTL a livello di riga.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');Rimuovi la policy di eliminazione delle righe.
ALTER TABLE Singers DROP ROW DELETION POLICY;Rimuovi la colonna del timestamp di scadenza.
ALTER TABLE Singers DROP COLUMN ExpiredAt;
Considerazioni sull'implementazione
- Framework e librerie:per la convalida personalizzata scalabile, utilizza framework basati su MapReduce come Apache Spark o Dataflow (Beam). Scegli un linguaggio supportato (Python, Scala, Java) e utilizza i connettori per Cassandra e Spanner, ad esempio utilizzando un proxy. Questi framework consentono l'elaborazione parallela efficiente di grandi set di dati per una convalida completa.
- Gestione degli errori e tentativi: implementa una gestione degli errori efficace per gestire potenziali problemi come problemi di connettività di rete o indisponibilità temporanea di uno dei database. Valuta l'implementazione di meccanismi di ripetizione per gli errori temporanei.
- Configurazione:rendi configurabili gli intervalli di token, i dettagli di connessione per entrambi i database e la logica di confronto.
- Ottimizzazione delle prestazioni:sperimenta il numero di processi paralleli e le dimensioni degli intervalli di token per ottimizzare il processo di convalida per il tuo ambiente specifico e il volume di dati. Monitora il carico sui cluster Cassandra e Spanner durante la convalida.
Passaggi successivi
- Consulta un confronto tra Spanner e Cassandra nella panoramica di Cassandra.
- Scopri come connetterti a Spanner utilizzando l'adattatore Cassandra.