Esta página oferece orientações sobre como migrar um banco de dados PostgreSQL de código aberto para o Spanner.
A migração envolve as seguintes tarefas:
- Como mapear um esquema do PostgreSQL para um esquema do Spanner.
- Como criar uma instância, um banco de dados e um esquema do Spanner
- Como refatorar o aplicativo para funcionar com o banco de dados do Spanner
- Como migrar os dados
- Como verificar o novo sistema e movê-lo para o status de produção
Nesta página, também apresentamos alguns esquemas de exemplo usando tabelas do banco de dados PostgreSQL do MusicBrainz.
Mapear seu esquema do PostgreSQL para o Spanner
A primeira etapa para mover um banco de dados do PostgreSQL para o Spanner é
determinar quais alterações de esquema você precisa fazer. Use
pg_dump
para criar instruções de linguagem de definição de dados (DDL) que definem os objetos no
banco de dados do PostgreSQL e, em seguida, modifique as instruções conforme descrito nas
seções a seguir. Depois de atualizar as instruções DDL, use-as
para criar o banco de dados em uma instância do Spanner.
Tipos de dados
A tabela a seguir descreve como os tipos de dados do PostgreSQL são mapeados para os tipos de dados do Spanner. Atualize os tipos de dados nas instruções DDL dos tipos de dados do PostgreSQL para os tipos de dados do Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, usando a notação padrão CIDR. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 se armazenar o valor em milissegundos, ou STRING se armazenar o valor em um formato de intervalo definido pelo aplicativo. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, usando a notação padrão de endereço MAC. |
money |
INT64 ou STRING para números de precisão arbitrária. |
numeric [ (p, s) ]
|
No PostgreSQL, os tipos de dados NUMERIC e DECIMAL são compatíveis com até 217 dígitos de precisão e 214-1 de escala, conforme definido na coluna declaração.O tipo de dados do Spanner NUMERIC
aceita até 38 dígitos de precisão e 9 dígitos decimais de escala.Se você precisar de mais precisão, consulte Como armazenar dados numéricos de precisão arbitrária para mecanismos alternativos. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Esse tipo de dados é específico do PostgreSQL, portanto, não há um equivalente do Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, usando a notação HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, usando a notação HH:MM:SS.sss+ZZZZ. Como alternativa, isso pode ser dividido em duas colunas, uma do tipo TIMESTAMP e outra contendo o fuso horário. |
timestamp [ (p) ] [ without time zone ] |
Não há equivalente. Você pode armazenar STRING ou TIMESTAMP a seu critério. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Não há equivalente. Em vez disso, defina um mecanismo de armazenamento no aplicativo. |
tsvector |
Não há equivalente. Em vez disso, defina um mecanismo de armazenamento no aplicativo. |
txid_snapshot |
Não há equivalente. Em vez disso, defina um mecanismo de armazenamento no aplicativo. |
uuid |
STRING ou BYTES |
xml |
STRING |
Chaves primárias
Para tabelas no banco de dados do Spanner que você anexa com frequência, evite
usar chaves primárias que aumentem ou diminuam constantemente, porque essa abordagem
cria pontos de acesso durante as gravações. Em vez disso, modifique as instruções CREATE TABLE DDL para que usem estratégias de chaves primárias compatíveis. Se você estiver usando um recurso do PostgreSQL, como um tipo ou função de dados UUID, tipos de dados SERIAL, coluna IDENTITY ou sequência, use as estratégias de migração de chaves geradas automaticamente recomendadas.
Depois de designar a chave primária, não será possível adicionar ou remover uma coluna de chave primária ou alterar um valor de chave primária sem excluir e recriar a tabela. Para mais informações sobre como designar a chave primária, consulte Esquema e modelo de dados: chaves primárias.
Durante a migração, talvez seja necessário manter algumas chaves inteiras atuais que aumentem constantemente. Se precisar manter esses tipos de chaves em uma tabela que é sempre atualizada com muitas operações nessas chaves, evite a criação de pontos de acesso prefixando a chave atual com um número pseudoaleatório. Essa técnica faz com que o Spanner redistribua as linhas. Consulte O que os DBAs precisam saber sobre o Spanner, parte 1: chaves e índices para mais informações sobre o uso dessa abordagem.
Chaves estrangeiras e integridade referencial
Saiba mais sobre o suporte a chaves externas no Spanner.
Índices
Os índices de árvore B do PostgreSQL são semelhantes aos índices secundários no Spanner. Em um banco de dados do Spanner, você usa índices secundários para
indexar colunas comumente pesquisadas para ter melhor desempenho e para substituir qualquer
restrição UNIQUE especificada nas tabelas. Por exemplo, se a DDL do PostgreSQL tiver esta instrução:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Você usaria esta instrução no DDL do Spanner:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Para encontrar os índices de qualquer uma das tabelas do PostgreSQL, execute o
meta-comando \di
em psql.
Depois de determinar os índices necessários, adicione instruções CREATE INDEX para criá-los. Siga as orientações em Como criar índices.
O Spanner implementa índices como tabelas. Portanto, a indexação de colunas que crescem constantemente (como aquelas que contêm dados TIMESTAMP) pode criar um ponto de acesso.
Consulte
O que os DBAs precisam saber sobre o Spanner, parte 1: chaves e índices
para mais informações sobre métodos para evitar pontos de acesso.
Verificar restrições
Saiba mais sobre a compatibilidade com a restrição CHECK no Spanner.
Outros objetos de banco de dados
É preciso criar a funcionalidade dos seguintes objetos na lógica do aplicativo:
- Visualizações
- Acionadores
- Procedimentos armazenados
- Funções definidas pelo usuário (UDFs)
- Colunas que usam tipos de dados
serialcomo geradores de sequência
Tenha as seguintes dicas em mente ao migrar essa funcionalidade para a lógica do aplicativo:
- É preciso migrar todas as instruções SQL usadas do dialeto SQL do PostgreSQL para o dialeto GoogleSQL.
- Se você usar cursores, será possível refazer a consulta para usar compensações e limites.
Criar uma instância do Spanner
Depois de atualizar as instruções DDL para atender aos requisitos de esquema do Spanner, use-as para criar o banco de dados no Spanner.
Crie uma instância do Spanner. Siga as orientações em Instâncias para determinar a configuração regional correta e a capacidade de computação compatível com suas metas de desempenho.
Crie o banco de dados usando o console Google Cloud ou a ferramenta de linha de comando
gcloud:
Console
- Acesse a página "Instâncias".
- Clique no nome da instância na qual você quer criar o banco de dados de exemplo para abrir a página Detalhes da instância.
- Clique em Criar banco de dados.
- Digite um nome para o banco de dados e clique em Continuar.
- Na seção Definir seu esquema de banco de dados, ative o controle Editar como texto.
- Copie e cole as instruções DDL no campo Instruções DDL.
- Clique em Criar.
gcloud
- Instale a CLI gcloud.
- Use o comando
gcloud spanner databases createpara criar o banco de dados:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME é o nome do banco de dados.
- INSTANCE_NAME é a instância do Spanner que você criou.
- DDLn são as instruções DDL modificadas.
Depois de criar o banco de dados, siga as instruções em Aplicar papéis do IAM para criar contas de usuário e conceder permissões à instância e ao banco de dados do Spanner.
Refatorar os aplicativos e as camadas de acesso a dados
Além do código necessário para substituir os objetos de banco de dados anteriores, é preciso adicionar a lógica do aplicativo para processar a funcionalidade a seguir:
- Geração de hash de chaves primárias para gravações, em tabelas com altas taxas de gravação para chaves sequenciais.
- Validação de dados, ainda não coberta por restrições
CHECK. - Verificações de integridade referencial que ainda não são cobertas pela chave externa, intercalação de tabelas ou lógica de aplicativo, incluindo a funcionalidade executada por acionadores no esquema do PostgreSQL.
Recomendamos usar o seguinte processo ao refatorar:
- Encontre todo o código do aplicativo que acessa o banco de dados e refatore-o em um único módulo ou biblioteca. Desse modo, você sabe exatamente que código acessa o banco de dados e, portanto, o código exato que precisa ser modificado.
- Escreva um código que realize leituras e gravações na instância do Spanner, fornecendo funcionalidade paralela ao código original que lê e grava no PostgreSQL. Durante as gravações, atualize a linha inteira, não apenas as colunas que foram alteradas, para garantir que os dados no Spanner sejam idênticos aos do PostgreSQL.
- Escreva um código que substitua a funcionalidade dos objetos e funções do banco de dados que não estão disponíveis no Spanner.
Migrar dados
Depois de criar o banco de dados do Spanner e refatorar o código do aplicativo, migre os dados para o Spanner.
- Use o comando
COPYdo PostgreSQL para descarregar os dados em arquivos .csv. Faça upload dos arquivos .csv para o Cloud Storage.
- Crie um bucket do Cloud Storage.
- No console do Cloud Storage, clique no nome do bucket para abrir o navegador dele.
- Clique em Enviar arquivos.
- Navegue até o diretório que contém os arquivos .csv e selecione-os.
- Clique em Abrir.
Crie um aplicativo para importar dados para o Spanner. Este aplicativo pode usar Fluxo de dados ou as bibliotecas de cliente diretamente. Siga as orientações em Práticas recomendadas de carregamento de dados em lote para ter o melhor desempenho.
Testes
Teste todas as funções do aplicativo em relação à instância do Spanner para verificar se elas funcionam conforme o esperado. Execute cargas de trabalho no nível de produção para garantir que o desempenho atenda às suas necessidades. Atualize a capacidade de computação conforme necessário para atingir suas metas de desempenho.
Mover para o novo sistema
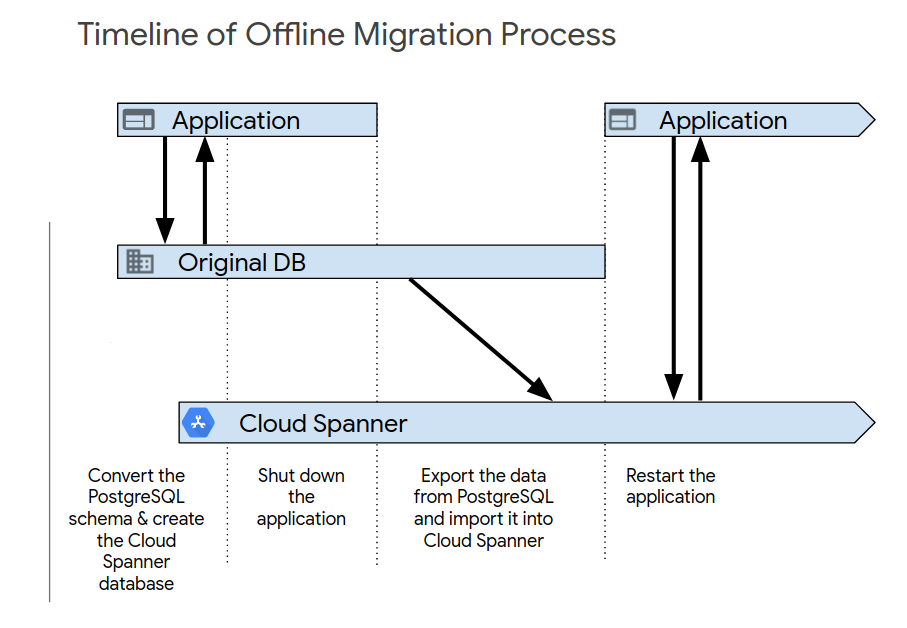
Depois de concluir o teste inicial do aplicativo, ative o novo sistema usando um dos seguintes processos. A migração off-line é o método mais simples. No entanto, essa abordagem torna o aplicativo indisponível por um período e não permite nenhum caminho de reversão se você encontrar problemas de dados posteriormente. Para executar uma migração off-line:
- Exclua todos os dados no banco de dados do Spanner.
- Encerre o aplicativo que tem como destino o banco de dados PostgreSQL.
- Exporte todos os dados do banco de dados PostgreSQL e importe-os para o banco de dados do Spanner, conforme descrito em Visão geral da migração.
Inicie o aplicativo que tem como destino o banco de dados do Spanner.
A migração em tempo real é possível e requer extensas alterações no aplicativo para oferecer suporte à migração.
Exemplos de migração de esquema
Estes exemplos mostram as instruções de CREATE TABLE para várias tabelas no esquema do banco de dados MusicBrainz do PostgreSQL.
Cada exemplo inclui o esquema do PostgreSQL e o esquema do Spanner.
tabela artist_credit
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
tabela recording
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
tabela recording-alias
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);