En esta página se ofrecen directrices para migrar una base de datos de PostgreSQL de código abierto a Spanner.
La migración implica las siguientes tareas:
- Asignar un esquema de PostgreSQL a un esquema de Spanner.
- Crear una instancia, una base de datos y un esquema de Spanner.
- Refactorizar la aplicación para que funcione con tu base de datos de Spanner.
- Migrando tus datos.
- Verificar el nuevo sistema y cambiarlo al estado de producción.
En esta página también se proporcionan algunos esquemas de ejemplo con tablas de la base de datos de PostgreSQL MusicBrainz.
Asignar tu esquema de PostgreSQL a Spanner
El primer paso para mover una base de datos de PostgreSQL a Spanner es determinar qué cambios de esquema debes hacer. Usa pg_dump para crear instrucciones del lenguaje de definición de datos (DDL) que definan los objetos de tu base de datos PostgreSQL y, a continuación, modifica las instrucciones como se describe en las siguientes secciones. Después de actualizar las instrucciones DDL, úsalas para crear tu base de datos en una instancia de Spanner.
Tipos de datos
En la siguiente tabla se describe cómo se asignan los tipos de datos de PostgreSQL a los tipos de datos de Spanner. Actualiza los tipos de datos de tus instrucciones DDL de PostgreSQL a tipos de datos de Spanner.
| PostgreSQL | Spanner |
|---|---|
Bigint
|
INT64 |
Bigserial
|
INT64 |
bit [ (n) ] |
ARRAY<BOOL> |
bit varying [ (n) ]
|
ARRAY<BOOL> |
Boolean
|
BOOL |
box |
ARRAY<FLOAT64> |
bytea |
BYTES |
character [ (n) ]
|
STRING |
character varying [ (n) ]
|
STRING |
cidr |
STRING, con la notación CIDR estándar. |
circle |
ARRAY<FLOAT64> |
date |
DATE |
double precision
|
FLOAT64 |
inet |
STRING |
Integer
|
INT64 |
interval[ fields ] [ (p) ] |
INT64 si almacena el valor en milisegundos o STRING si lo almacena en un formato de intervalo definido por la aplicación. |
json |
STRING |
jsonb |
JSON |
line |
ARRAY<FLOAT64> |
lseg |
ARRAY<FLOAT64> |
macaddr |
STRING, con la notación estándar de dirección MAC. |
money |
INT64 o STRING para números de precisión arbitraria. |
numeric [ (p, s) ]
|
En PostgreSQL, los tipos de datos NUMERIC y DECIMAL admiten hasta 217 dígitos de precisión y 214-1 de escala, tal como se define en la declaración de la columna.El tipo de datos NUMERIC de Spanner admite hasta 38 dígitos de precisión y 9 dígitos decimales de escala.Si necesitas una mayor precisión, consulta Almacenar datos numéricos de precisión arbitraria para ver otros mecanismos. |
path |
ARRAY<FLOAT64> |
pg_lsn |
Este tipo de datos es específico de PostgreSQL, por lo que no hay un equivalente en Spanner. |
point |
ARRAY<FLOAT64> |
polygon |
ARRAY<FLOAT64> |
Real
|
FLOAT64 |
Smallint
|
INT64 |
Smallserial
|
INT64 |
Serial
|
INT64 |
text |
STRING |
time [ (p) ] [ without time zone ] |
STRING, usando la notación HH:MM:SS.sss. |
time [ (p) ] with time zone
|
STRING, usando la notación HH:MM:SS.sss+ZZZZ. También se puede dividir en dos columnas: una de tipo TIMESTAMP y otra con la zona horaria. |
timestamp [ (p) ] [ without time zone ] |
Sin equivalente. Puedes almacenarlos como STRING o TIMESTAMP, según lo que prefieras. |
timestamp [ (p) ] with time zone
|
TIMESTAMP |
tsquery |
Sin equivalente. Define un mecanismo de almacenamiento en tu aplicación. |
tsvector |
Sin equivalente. Define un mecanismo de almacenamiento en tu aplicación. |
txid_snapshot |
Sin equivalente. Define un mecanismo de almacenamiento en tu aplicación. |
uuid |
STRING o BYTES |
xml |
STRING |
Claves principales
En las tablas de tu base de datos de Spanner a las que añadas datos con frecuencia, no uses claves principales que aumenten o disminuyan de forma monótona, ya que este enfoque provoca puntos de acceso durante las escrituras. En su lugar, modifique las instrucciones DDL CREATE TABLE para que usen estrategias de clave principal admitidas. Si usas una función de PostgreSQL, como un tipo de datos UUID o una función, tipos de datos SERIAL, una columna IDENTITY o una secuencia, puedes usar las estrategias de migración de claves generadas automáticamente que te recomendamos.
Ten en cuenta que, después de designar la clave principal, no podrás añadir ni quitar una columna de clave principal, ni cambiar el valor de una clave principal más adelante sin eliminar y volver a crear la tabla. Para obtener más información sobre cómo designar tu clave principal, consulta Esquema y modelo de datos: claves principales.
Durante la migración, es posible que tengas que conservar algunas claves de números enteros que aumenten de forma monótona. Si necesitas conservar este tipo de claves en una tabla que se actualiza con frecuencia y en la que se realizan muchas operaciones con estas claves, puedes evitar crear puntos de acceso prefijando la clave con un número pseudoaleatorio. Esta técnica hace que Spanner redistribuya las filas. Consulta Qué deben saber los administradores de bases de datos sobre Spanner (parte 1): claves e índices para obtener más información sobre cómo usar este enfoque.
Claves externas e integridad referencial
Consulta información sobre la compatibilidad con claves externas en Spanner.
Índices
Los índices de árbol B de PostgreSQL son similares a los índices secundarios de Spanner. En una base de datos de Spanner, se usan índices secundarios para indexar las columnas que se buscan con frecuencia y así mejorar el rendimiento, así como para sustituir las restricciones UNIQUE especificadas en las tablas. Por ejemplo, si tu DDL de PostgreSQL tiene esta instrucción:
CREATE TABLE customer (
id CHAR (5) PRIMARY KEY,
first_name VARCHAR (50),
last_name VARCHAR (50),
email VARCHAR (50) UNIQUE
);
Usarías esta instrucción en tu DDL de Spanner:
CREATE TABLE customer (
id STRING(5),
first_name STRING(50),
last_name STRING(50),
email STRING(50)
) PRIMARY KEY (id);
CREATE UNIQUE INDEX customer_emails ON customer(email);
Puedes encontrar los índices de cualquiera de tus tablas de PostgreSQL ejecutando el
\di
metacomando en psql.
Una vez que hayas determinado los índices que necesitas, añade instrucciones CREATE INDEX para crearlos. Sigue las instrucciones de Crear índices.
Spanner implementa los índices como tablas, por lo que indexar columnas que aumentan de forma monótona (como las que contienen datos TIMESTAMP) puede provocar un punto de acceso.
Consulta el artículo Lo que los administradores de bases de datos deben saber sobre Spanner (parte 1): claves e índices para obtener más información sobre los métodos para evitar los puntos de acceso.
Comprobar las restricciones
Consulta información sobre la compatibilidad con restricciones CHECK en Spanner.
Otros objetos de la base de datos
Debes crear la funcionalidad de los siguientes objetos en la lógica de tu aplicación:
- Vistas
- Activadores
- Procedimientos almacenados
- Funciones definidas por el usuario (UDF)
- Columnas que usan
serialtipos de datos como generadores de secuencias
Ten en cuenta los siguientes consejos al migrar esta función a la lógica de la aplicación:
- Debes migrar las instrucciones SQL que utilices del dialecto SQL de PostgreSQL al dialecto GoogleSQL.
- Si usas cursores, puedes modificar la consulta para usar desplazamientos y límites.
Crea tu instancia de Spanner
Una vez que hayas actualizado tus instrucciones DDL para que cumplan los requisitos del esquema de Spanner, úsalas para crear tu base de datos en Spanner.
Crea una instancia de Spanner. Sigue las instrucciones de Instancias para determinar la configuración regional y la capacidad de computación correctas que te permitan alcanzar tus objetivos de rendimiento.
Crea la base de datos con la consola Google Cloud o la herramienta de línea de comandos
gcloud:
Consola
- Ir a la página de instancias
- Haz clic en el nombre de la instancia en la que quieras crear la base de datos de ejemplo para abrir la página Detalles de la instancia.
- Haz clic en Crear base de datos.
- Escribe un nombre para la base de datos y haz clic en Continuar.
- En la sección Define your database schema (Define el esquema de tu base de datos), activa el control Edit as text (Editar como texto).
- Copia y pega las instrucciones DDL en el campo DDL statements (Instrucciones DDL).
- Haz clic en Crear.
gcloud
- Instala gcloud CLI.
- Usa el comando
gcloud spanner databases createpara crear la base de datos:gcloud spanner databases create DATABASE_NAME --instance=INSTANCE_NAME --ddl='DDL1' --ddl='DDL2'
- DATABASE_NAME es el nombre de tu base de datos.
- INSTANCE_NAME es la instancia de Spanner que has creado.
- DDLn son las instrucciones DDL modificadas.
Después de crear la base de datos, sigue las instrucciones de Aplicar roles de gestión de identidades y accesos para crear cuentas de usuario y conceder permisos a la instancia y a la base de datos de Spanner.
Refactorizar las capas de aplicaciones y de acceso a datos
Además del código necesario para sustituir los objetos de la base de datos anteriores, debes añadir lógica de aplicación para gestionar las siguientes funciones:
- Aplicar hash a las claves principales de las escrituras en tablas que tienen altas tasas de escritura en claves secuenciales.
- Validar datos que no estén cubiertos por las restricciones de
CHECK. - Comprobaciones de integridad referencial que no estén cubiertas por claves externas, intercalación de tablas o lógica de aplicaciones, incluida la funcionalidad gestionada por activadores en el esquema de PostgreSQL.
Te recomendamos que sigas este proceso al refactorizar:
- Busca todo el código de tu aplicación que acceda a la base de datos y refactorízalo en un solo módulo o biblioteca. De esta forma, sabrás exactamente qué código accede a la base de datos y, por lo tanto, qué código se debe modificar.
- Escribe código que realice lecturas y escrituras en la instancia de Spanner, lo que proporciona una funcionalidad paralela al código original que lee y escribe en PostgreSQL. Durante las escrituras, actualiza toda la fila, no solo las columnas que se hayan cambiado, para asegurarte de que los datos de Spanner sean idénticos a los de PostgreSQL.
- Escribe código que sustituya las funciones y los objetos de la base de datos que no estén disponibles en Spanner.
Migrar datos
Una vez que hayas creado tu base de datos de Spanner y refactorizado el código de tu aplicación, podrás migrar tus datos a Spanner.
- Usa el comando
COPYde PostgreSQL para volcar datos en archivos .csv. Sube los archivos .csv a Cloud Storage.
- Crea un segmento de Cloud Storage.
- En la consola de Cloud Storage, haz clic en el nombre del segmento para abrir el navegador de segmentos.
- Haz clic en Subir archivos.
- Desplázate hasta el directorio que contiene los archivos .csv y selecciónalos.
- Haz clic en Abrir.
Crea una aplicación para importar datos a Spanner. Esta aplicación podría usar Dataflow o las bibliotecas de cliente directamente. Sigue las directrices de las prácticas recomendadas para la carga de datos en bloque para obtener el mejor rendimiento posible.
Pruebas
Prueba todas las funciones de la aplicación con la instancia de Spanner para verificar que funcionan correctamente. Ejecuta cargas de trabajo de nivel de producción para asegurarte de que el rendimiento se ajusta a tus necesidades. Actualiza la capacidad de computación según sea necesario para alcanzar tus objetivos de rendimiento.
Pasar al nuevo sistema
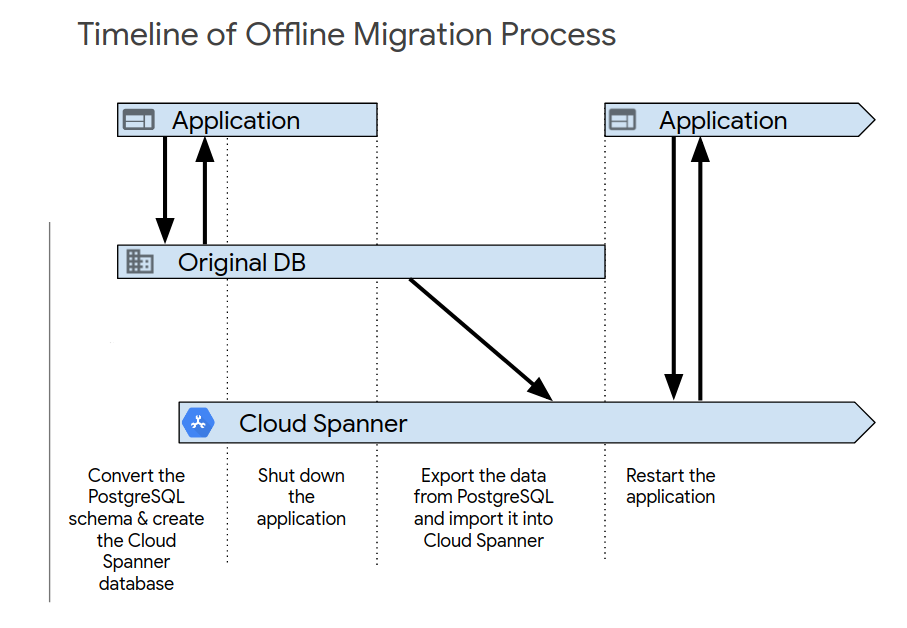
Una vez que hayas completado las pruebas iniciales de la aplicación, activa el nuevo sistema mediante uno de los siguientes procesos. La migración offline es la forma más sencilla de migrar. Sin embargo, con este método, tu aplicación no estará disponible durante un periodo y no podrás volver a la versión anterior si detectas problemas con los datos más adelante. Para llevar a cabo una migración sin conexión, sigue estos pasos:
- Elimina todos los datos de la base de datos de Spanner.
- Cierra la aplicación que tiene como destino la base de datos PostgreSQL.
- Exporta todos los datos de la base de datos de PostgreSQL e impórtalos en la base de datos de Spanner, tal como se describe en la descripción general de la migración.
Inicia la aplicación que tiene como destino la base de datos de Spanner.
Es posible realizar una migración activa, pero requiere hacer grandes cambios en tu aplicación para que sea compatible con la migración.
Ejemplos de migración de esquemas
En estos ejemplos se muestran las instrucciones CREATE TABLE de varias tablas de la MusicBrainz MusicBrainz.
Cada ejemplo incluye el esquema de PostgreSQL y el de Spanner.
Tabla artist_credit
GoogleSQL
CREATE TABLE artist_credit (
hashed_id STRING(4),
id INT64,
name STRING(MAX) NOT NULL,
artist_count INT64 NOT NULL,
ref_count INT64,
created TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE artist_credit (
id SERIAL,
name VARCHAR NOT NULL,
artist_count SMALLINT NOT NULL,
ref_count INTEGER DEFAULT 0,
created TIMESTAMP WITH TIME ZONE DEFAULT NOW()
);
tabla de registro
GoogleSQL
CREATE TABLE recording (
hashed_id STRING(36),
id INT64,
gid STRING(36) NOT NULL,
name STRING(MAX) NOT NULL,
artist_credit_hid STRING(36) NOT NULL,
artist_credit_id INT64 NOT NULL,
length INT64,
comment STRING(255) NOT NULL,
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP OPTIONS (
allow_commit_timestamp = true
),
video BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id);
PostgreSQL
CREATE TABLE recording (
id SERIAL,
gid UUID NOT NULL,
name VARCHAR NOT NULL,
artist_credit INTEGER NOT NULL, -- references artist_credit.id
length INTEGER CHECK (length IS NULL OR length > 0),
comment VARCHAR(255) NOT NULL DEFAULT '',
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >= 0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
video BOOLEAN NOT NULL DEFAULT FALSE
);
Tabla recording-alias
GoogleSQL
CREATE TABLE recording_alias (
hashed_id STRING(36) NOT NULL,
id INT64 NOT NULL,
alias_id INT64,
name STRING(MAX) NOT NULL,
locale STRING(MAX),
edits_pending INT64 NOT NULL,
last_updated TIMESTAMP NOT NULL OPTIONS (
allow_commit_timestamp = true
),
type INT64,
sort_name STRING(MAX) NOT NULL,
begin_date_year INT64,
begin_date_month INT64,
begin_date_day INT64,
end_date_year INT64,
end_date_month INT64,
end_date_day INT64,
primary_for_locale BOOL NOT NULL,
ended BOOL NOT NULL,
) PRIMARY KEY(hashed_id, id, alias_id),
INTERLEAVE IN PARENT recording ON DELETE NO ACTION;
PostgreSQL
CREATE TABLE recording_alias (
id SERIAL, --PK
recording INTEGER NOT NULL, -- references recording.id
name VARCHAR NOT NULL,
locale TEXT,
edits_pending INTEGER NOT NULL DEFAULT 0 CHECK (edits_pending >=0),
last_updated TIMESTAMP WITH TIME ZONE DEFAULT NOW(),
type INTEGER, -- references recording_alias_type.id
sort_name VARCHAR NOT NULL,
begin_date_year SMALLINT,
begin_date_month SMALLINT,
begin_date_day SMALLINT,
end_date_year SMALLINT,
end_date_month SMALLINT,
end_date_day SMALLINT,
primary_for_locale BOOLEAN NOT NULL DEFAULT false,
ended BOOLEAN NOT NULL DEFAULT FALSE
-- CHECK constraint skipped for brevity
);