En este artículo se explica cómo migrar tu base de datos desde los sistemas de procesamiento de transacciones online (OLTP) de Oracle® a Spanner.
Spanner usa ciertos conceptos de forma diferente a otras herramientas de gestión de bases de datos empresariales, por lo que es posible que tengas que ajustar tu aplicación para aprovechar al máximo sus funciones. También es posible que tengas que complementar Spanner con otros servicios de Google Cloud para satisfacer tus necesidades.
Restricciones de migración
Cuando migres tu aplicación a Spanner, debes tener en cuenta las diferentes funciones disponibles. Probablemente tengas que rediseñar la arquitectura de tu aplicación para que se ajuste al conjunto de funciones de Spanner e integrarla con otros Google Cloud servicios.
Procedimientos almacenados y activadores
Spanner no admite la ejecución de código de usuario a nivel de base de datos, por lo que, como parte de la migración, debe mover la lógica empresarial implementada por los procedimientos y los activadores almacenados a nivel de base de datos a la aplicación.
Secuencias
Te recomendamos que utilices la versión 4 de UUID como método predeterminado para generar valores de clave principal.
La función GENERATE_UUID() (GoogleSQL,
PostgreSQL)
devuelve valores de la versión 4 de UUID como un tipo STRING.
Si necesitas generar valores enteros de 64 bits, Spanner admite secuencias invertidas de bits positivas (GoogleSQL y PostgreSQL), que producen valores que se distribuyen de forma uniforme en el espacio de números positivos de 64 bits. Puedes usar estos números para evitar problemas de hotspotting.
Para obtener más información, consulte las estrategias de valor predeterminado de clave principal.
Controles de acceso
Gestión de Identidades y Accesos (IAM) te permite controlar el acceso de usuarios y grupos a los recursos de Spanner a nivel de proyecto, instancia de Spanner y base de datos de Spanner. Para obtener más información, consulta la información general sobre IAM.
Revisa e implementa las políticas de gestión de identidades y accesos siguiendo el principio de privilegio mínimo para todos los usuarios y cuentas de servicio que accedan a tu base de datos. Si la aplicación requiere acceso restringido a tablas, columnas, vistas o flujos de cambios específicos, implementa el control de acceso pormenorizado (FGAC). Para obtener más información, consulta la descripción general del control de acceso pormenorizado.
Restricciones de validación de datos
Spanner puede admitir un conjunto limitado de restricciones de validación de datos en la capa de la base de datos.
Si necesitas restricciones de datos más complejas, impleméntalas en la capa de aplicación.
En la siguiente tabla se describen los tipos de restricciones que se suelen encontrar en las bases de datos de Oracle® y cómo implementarlas con Spanner.
| Restricción | Implementación con Spanner |
|---|---|
| No nulo | NOT NULLrestricción de columna |
| Identificador único | Índice secundario con la restricción UNIQUE |
| Clave externa (para tablas normales) | Consulta Crear y gestionar relaciones de claves externas. |
Acciones de clave externa ON DELETE/ON UPDATE |
Solo es posible en tablas intercaladas. De lo contrario, se implementa en la capa de aplicación. |
Comprobaciones y validaciones de valores mediante CHECK restricciones o activadores
|
Implementado en la capa de aplicación |
Tipos de datos admitidos
Las bases de datos Oracle® y Spanner admiten diferentes conjuntos de tipos de datos. En la siguiente tabla se enumeran los tipos de datos de Oracle y sus equivalentes en Spanner. Para obtener definiciones detalladas de cada tipo de datos de Spanner, consulta Tipos de datos.
También es posible que tengas que realizar transformaciones adicionales en los datos, tal como se describe en la columna Notas, para que los datos de Oracle se ajusten a tu base de datos de Spanner.
Por ejemplo, puedes almacenar un BLOB grande como un objeto en un segmento de Cloud Storage en lugar de en la base de datos y, a continuación, almacenar la referencia URI al objeto de Cloud Storage en la base de datos como un STRING.
| Tipo de datos de Oracle | Equivalente de Spanner | Notas |
|---|---|---|
Tipos de caracteres (CHAR, VARCHAR, NCHAR y NVARCHAR)
|
STRING
|
Nota: Spanner usa cadenas Unicode en todo el sistema. Oracle admite una longitud máxima de 32.000 bytes o caracteres (según el tipo), mientras que Spanner admite hasta 2.621.440 caracteres. |
BLOB, LONG RAW, BFILE
|
BYTES o STRING que contiene el URI del objeto.
|
Los objetos pequeños (menos de 10 MiB) se pueden almacenar como BYTES.Considera usar ofertas alternativas Google Cloud , como Cloud Storage, para almacenar objetos de mayor tamaño. |
CLOB, NCLOB, LONG
|
STRING (que contiene datos o un URI a un objeto externo)
|
Los objetos pequeños (menos de 2.621.440 caracteres) se pueden almacenar como STRING. Puedes usar otras Google Cloud ofertas, como Cloud Storage, para almacenar objetos de mayor tamaño.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
El tipo de datos NUMBER de Oracle es equivalente al tipo de datos NUMERIC de GoogleSQL. Cada uno de ellos admite 38 dígitos de precisión y 9 de escala: (P,S) = (38,9). El tipo de datos PostgreSQL
NUMERIC almacena
datos numéricos de precisión arbitraria.
El tipo de datos FLOAT64GoogleSQL admite hasta 16 dígitos de precisión. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE
|
FLOAT64
|
|
DATE
|
DATE
|
La representación STRING predeterminada del tipo DATE de Spanner es yyyy-mm-dd, que es diferente de la de Oracle, por lo que debes tener cuidado al convertir automáticamente representaciones de fechas a y desde STRING. Se proporcionan funciones SQL para convertir fechas en una cadena con formato.
|
DATETIME
|
TIMESTAMP
|
Spanner almacena el tiempo independientemente de la zona horaria. Si necesitas almacenar una zona horaria, debes usar una columna STRING independiente.
Se proporcionan funciones de SQL para convertir marcas de tiempo en una cadena con formato mediante zonas horarias.
|
XML
|
STRING (que contiene datos o un URI a un objeto externo)
|
Los objetos XML pequeños (menos de 2.621.440 caracteres) se pueden almacenar como
STRING. Puedes usar otras Google Cloud ofertas
como Cloud Storage para almacenar objetos de mayor tamaño. |
URI, DBURI, XDBURI,
HTTPURI
|
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner usa la clave principal de la tabla para ordenar y hacer referencia a las filas internamente, por lo que en Spanner es lo mismo que el tipo de datos ROWID. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER
|
Spanner no admite tipos de datos geoespaciales. Tendrás que almacenar estos datos con tipos de datos estándar e implementar cualquier lógica de búsqueda y filtrado en la capa de aplicación. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature
|
Spanner no admite tipos de datos multimedia. Puedes usar Cloud Storage para almacenar datos multimedia. |
Proceso de migración
El calendario general del proceso de migración sería el siguiente:
- Convierte tu esquema y tu modelo de datos.
- Traduce cualquier consulta de SQL.
- Migra tu aplicación para que use Spanner además de Oracle.
- Exporta tus datos de Oracle de forma masiva e impórtalos a Spanner con Dataflow.
- Mantén la coherencia entre ambas bases de datos durante la migración.
- Migra tu aplicación de Oracle.
Paso 1: Convierte tu base de datos y tu esquema
Convierte tu esquema en un esquema de Spanner para almacenar tus datos. Debe coincidir con el esquema de Oracle lo más posible para simplificar las modificaciones de la aplicación. Sin embargo, debido a las diferencias en las funciones, será necesario hacer algunos cambios.
Si sigues las prácticas recomendadas para diseñar esquemas, puedes aumentar el rendimiento y reducir los puntos de acceso en tu base de datos de Spanner.
Claves principales
En Spanner, todas las tablas que deban almacenar más de una fila deben tener una clave principal compuesta por una o varias columnas de la tabla. La clave principal de una tabla identifica de forma única cada fila de la tabla, y las filas de la tabla se ordenan por clave principal. Como Spanner está muy distribuido, es importante que elijas una técnica de generación de claves principales que se adapte bien al crecimiento de tus datos. Para obtener más información, consulta las estrategias de migración de claves principales recomendadas.
Ten en cuenta que, después de designar la clave principal, no podrás añadir ni quitar una columna de clave principal, ni cambiar el valor de una clave principal más adelante sin eliminar y volver a crear la tabla. Para obtener más información sobre cómo designar tu clave principal, consulta Esquema y modelo de datos: claves principales.
Entrelazar tus tablas
Spanner tiene una función que te permite definir dos tablas como si tuvieran una relación de uno a muchos, es decir, una relación entre un elemento superior y otro secundario. De esta forma, las filas de datos secundarios se intercalan con su fila superior en el almacenamiento, lo que permite combinar la tabla de forma eficaz y mejorar la eficiencia de la recuperación de datos cuando se consultan la tabla superior y las secundarias juntas.
La clave principal de la tabla secundaria debe empezar por las columnas de clave principal de la tabla superior. Desde la perspectiva de la fila secundaria, la clave principal de la fila superior se denomina clave externa. Puede definir hasta 6 niveles de relaciones entre elementos principales y secundarios.
Puedes definir acciones de eliminación para las tablas secundarias y determinar qué ocurre cuando se elimina la fila superior: se eliminan todas las filas secundarias o se bloquea la eliminación de la fila superior mientras haya filas secundarias.
A continuación se muestra un ejemplo de cómo crear una tabla Albums intercalada en la tabla Singers principal definida anteriormente:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Crear índices secundarios
También puedes crear índices secundarios para indexar datos de la tabla que no sean la clave principal.
Spanner implementa los índices secundarios de la misma forma que las tablas, por lo que los valores de las columnas que se van a usar como claves de índice tienen las mismas restricciones que las claves principales de las tablas. Esto también significa que los índices tienen las mismas garantías de coherencia que las tablas de Spanner.
Las búsquedas de valores que usan índices secundarios son prácticamente iguales a una consulta con una combinación de tablas. Para mejorar el rendimiento de las consultas mediante índices, puede almacenar copias de los valores de las columnas de la tabla original en el índice secundario con la cláusula STORING, lo que lo convierte en un índice de cobertura.
El optimizador de consultas de Spanner solo usará automáticamente los índices secundarios cuando el índice en sí almacene todas las columnas de la consulta (una consulta cubierta). Para forzar el uso de un índice al consultar columnas de la tabla original, debes usar una directiva FORCE INDEX en la instrucción SQL. Por ejemplo:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Los índices se pueden usar para aplicar valores únicos en una columna de una tabla. Para ello, se define un UNIQUEíndice
en esa columna. El índice evitará que se añadan valores duplicados.
A continuación, se muestra un ejemplo de una instrucción DDL que crea un índice secundario para la tabla Albums:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Ten en cuenta que, si creas índices adicionales después de cargar los datos, puede que el índice tarde un tiempo en rellenarse. Debes limitar la frecuencia con la que los añades a una media de tres al día. Para obtener más información sobre cómo crear índices secundarios, consulta Índices secundarios. Para obtener más información sobre las limitaciones de la creación de índices, consulta Actualizaciones de esquemas.
Paso 2: Traduce las consultas de SQL
Spanner usa el dialecto ANSI 2011 de SQL con extensiones y tiene muchas funciones y operadores para ayudarte a traducir y agregar tus datos. Debes convertir las consultas de SQL que usen sintaxis, funciones y tipos específicos de Oracle para que sean compatibles con Spanner.
Aunque Spanner no admite datos estructurados como definiciones de columnas, se pueden usar datos estructurados en consultas de SQL con los tipos ARRAY y STRUCT.
Por ejemplo, se puede escribir una consulta para devolver todos los álbumes de un artista usando un ARRAY de STRUCTs en una sola consulta (aprovechando los datos precombinados).
Para obtener más información, consulta la sección Notas sobre las subconsultas de la documentación.
Las consultas SQL se pueden perfilar mediante la página Spanner Studio de la Google Cloud consola para ejecutar la consulta. En general, las consultas que realizan análisis de tabla completa en tablas grandes son muy costosas y deben usarse con moderación.
Consulta la documentación sobre prácticas recomendadas de SQL para obtener más información sobre cómo optimizar las consultas de SQL.
Paso 3: Migra tu aplicación para que use Spanner
Spanner proporciona un conjunto de bibliotecas de cliente para varios lenguajes y la capacidad de leer y escribir datos mediante llamadas a la API específicas de Spanner, así como mediante consultas de SQL y declaraciones del lenguaje de modificación de datos (DML). Usar llamadas a la API puede ser más rápido para algunas consultas, como las lecturas directas de filas por clave, porque no es necesario traducir la instrucción SQL.
También puedes usar el controlador Java Database Connectivity (JDBC) para conectarte a Spanner y aprovechar las herramientas y la infraestructura que no tienen integración nativa.
Como parte del proceso de migración, las funciones que no estén disponibles en Spanner se deben implementar en la aplicación. Por ejemplo, un activador para verificar los valores de los datos y actualizar una tabla relacionada se tendría que implementar en la aplicación mediante una transacción de lectura/escritura para leer la fila, verificar la restricción y, a continuación, escribir las filas actualizadas en ambas tablas.
Spanner ofrece transacciones de lectura y escritura y de solo lectura, lo que garantiza la coherencia externa de tus datos. Además, se pueden aplicar límites de marca de tiempo a las transacciones de lectura, en las que se lee una versión coherente de los datos especificados de las siguientes formas:
- En un momento exacto del pasado (hace hasta 1 hora).
- En el futuro (donde la lectura se bloqueará hasta que llegue ese momento).
- Con una cantidad aceptable de obsolescencia limitada, que devolverá una vista coherente hasta hace un tiempo sin necesidad de comprobar que los datos posteriores estén disponibles en otra réplica. Esto puede mejorar el rendimiento, pero a costa de que los datos estén obsoletos.
Paso 4: Transfiere tus datos de Oracle a Spanner
Para transferir sus datos de Oracle a Spanner, deberá exportar su base de datos de Oracle a un formato de archivo portátil (por ejemplo, CSV) y, a continuación, importar esos datos a Spanner mediante Dataflow.
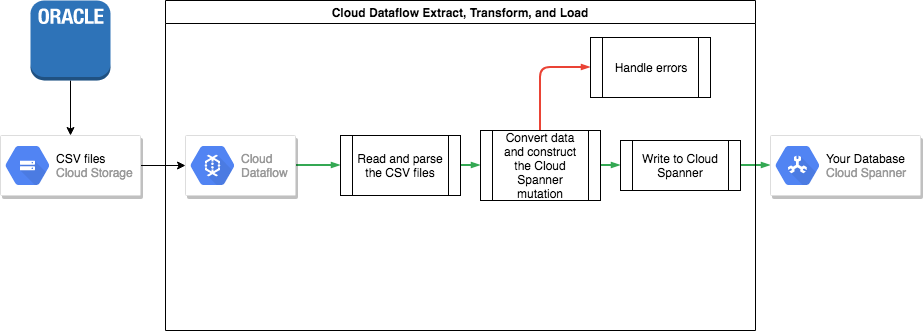
Exportación en bloque desde Oracle
Oracle no proporciona ninguna utilidad integrada para exportar o descargar toda la base de datos en un formato de archivo portátil.
En las preguntas frecuentes de Oracle se indican algunas opciones para realizar una exportación.
Por ejemplo:
- Usar SQL*Plus o SQLcl para enviar una consulta a un archivo de texto.
- Escribir una función PL/SQL con UTL_FILE para descargar una tabla en paralelo en archivos de texto.
- Usar funciones de Oracle APEX o Oracle SQL Developer para descargar una tabla en un archivo CSV o XML.
Cada uno de estos métodos tiene el inconveniente de que solo se puede exportar una tabla a la vez, lo que significa que debes pausar tu aplicación o detener tu base de datos para que la base de datos se mantenga en un estado coherente durante la exportación.
Otras opciones incluyen herramientas de terceros, como las que se indican en la página de preguntas frecuentes de Oracle, algunas de las cuales pueden descargar una vista coherente de toda la base de datos.
Una vez descargados, debes subir estos archivos de datos a un segmento de Cloud Storage para que se puedan importar.
Importación en bloque en Spanner
Como es probable que los esquemas de la base de datos de Oracle y Spanner sean diferentes, puede que tengas que convertir algunos datos durante el proceso de importación.
La forma más sencilla de realizar estas conversiones de datos e importar los datos a Spanner es mediante Dataflow.
Dataflow es el servicio de Google Cloud extracción, transformación y carga (ETL) distribuido. Proporciona una plataforma para ejecutar flujos de datos escritos con el SDK de Apache Beam para leer y procesar grandes cantidades de datos en paralelo en varias máquinas.
El SDK de Apache Beam requiere que escribas un programa Java sencillo para definir la lectura, la transformación y la escritura de los datos. Existen conectores de Beam para Cloud Storage y Spanner, por lo que el único código que se debe escribir es la propia transformación de datos.
Consulta un ejemplo de una canalización sencilla que lee archivos CSV y escribe en Spanner en el repositorio de código de ejemplo que acompaña a este artículo.
Si se usan tablas intercaladas entre padres e hijos en su esquema de Spanner, debe tener cuidado durante el proceso de importación para que la fila principal se cree antes que la secundaria. El código de la canalización de importación de Spanner se encarga de esto importando primero todos los datos de las tablas de nivel raíz, luego todas las tablas secundarias de nivel 1, después todas las tablas secundarias de nivel 2, y así sucesivamente.
La canalización de importación de Spanner se puede usar directamente para importar datos en bloque,pero para ello los datos deben estar en archivos Avro con el esquema correcto.
Paso 5: Mantener la coherencia entre ambas bases de datos
Muchas aplicaciones tienen requisitos de disponibilidad que hacen que sea imposible mantener la aplicación sin conexión durante el tiempo necesario para exportar e importar tus datos. Mientras transfieres tus datos a Spanner, tu aplicación sigue modificando la base de datos. Debes duplicar las actualizaciones de la base de datos de Spanner mientras se ejecuta la aplicación.
Hay varios métodos para mantener sincronizadas las dos bases de datos, como la captura de datos de cambios y la implementación de actualizaciones simultáneas en la aplicación.
Captura de datos de cambios
Oracle GoldenGate puede proporcionar un flujo de captura de datos de cambios (CDC) para tu base de datos Oracle. Oracle LogMiner u Oracle XStream Out son interfaces alternativas para la base de datos de Oracle que permiten obtener un flujo de CDC que no implica Oracle GoldenGate.
Puedes escribir una aplicación que se suscriba a uno de estos flujos y que aplique las mismas modificaciones (después de convertir los datos, por supuesto) a tu base de datos de Spanner. Una aplicación de procesamiento de flujo de este tipo debe implementar varias funciones:
- Conexión a la base de datos de Oracle (base de datos de origen).
- Conectarse a Spanner (base de datos de destino).
- Realizar repetidamente lo siguiente:
- Recibir los datos generados por uno de los flujos de CDC de la base de datos de Oracle.
- Interpretar los datos producidos por el flujo de CDC.
- Convierte los datos en instrucciones
INSERTde Spanner. - Ejecutar las instrucciones de Spanner
INSERT.
La tecnología de migración de bases de datos es una tecnología de middleware que ha implementado las funciones necesarias como parte de su funcionalidad. La plataforma de migración de bases de datos se instala como un componente independiente en la ubicación de origen o de destino, según los requisitos del cliente. La plataforma de migración de bases de datos solo requiere la configuración de la conectividad de las bases de datos implicadas para especificar e iniciar la transferencia continua de datos de la base de datos de origen a la de destino.
Striim es una plataforma tecnológica de migración de bases de datos disponible enGoogle Cloud. Proporciona conectividad a las secuencias de CDC de Oracle GoldenGate, así como de Oracle LogMiner y Oracle XStream Out. Striim proporciona una herramienta gráfica que te permite configurar la conectividad de la base de datos y las reglas de transformación necesarias para transferir datos de Oracle a Spanner.
Puedes instalar Striim desde Google Cloud Marketplace, conectarte a las bases de datos de origen y de destino, implementar las reglas de transformación que quieras y empezar a transferir datos sin tener que crear tú mismo una aplicación de procesamiento de flujo.
Actualizaciones simultáneas en ambas bases de datos desde la aplicación
Otra opción es modificar la aplicación para que escriba en ambas bases de datos. Una base de datos (inicialmente, Oracle) se consideraría la fuente de información y, después de cada escritura en la base de datos, se leería, convertiría y escribiría toda la fila en la base de datos de Spanner.
De esta forma, la aplicación sobrescribe constantemente las filas de Spanner con los datos más recientes.
Cuando estés seguro de que todos tus datos se han transferido correctamente, puedes cambiar la fuente de información a la base de datos de Spanner.
Este mecanismo proporciona una ruta de reversión si se detectan problemas al cambiar a Spanner.
Verificar la coherencia de los datos
A medida que los datos se transmiten a tu base de datos de Spanner, puedes comparar periódicamente los datos de Spanner con los de Oracle para asegurarte de que sean coherentes.
Para validar la coherencia, puede consultar ambas fuentes de datos y comparar los resultados.
Puedes usar Dataflow para hacer una comparación detallada de conjuntos de datos grandes con la transformación Join. Esta transformación toma dos conjuntos de datos con claves y relaciona los valores por clave. Los valores coincidentes se pueden comparar para comprobar si son iguales.
Puedes realizar esta verificación periódicamente hasta que el nivel de coherencia se ajuste a los requisitos de tu empresa.
Paso 6: Cambia a Spanner como fuente de información de tu aplicación
Cuando tengas confianza en la migración de datos, puedes cambiar tu aplicación para que use Spanner como fuente de información veraz. Sigue escribiendo los cambios en la base de datos de Oracle para mantenerla actualizada y tener una opción de reversión en caso de que surjan problemas.
Por último, puedes inhabilitar y eliminar el código de actualización de la base de datos de Oracle y cerrar la base de datos de Oracle.
Exportar e importar bases de datos de Spanner
También puede exportar sus tablas de Spanner a un segmento de Cloud Storage mediante una plantilla de Dataflow. La carpeta resultante contiene un conjunto de archivos Avro y archivos de manifiesto JSON con las tablas exportadas. Estos archivos pueden tener varios fines, como los siguientes:
- Crear copias de seguridad de tu base de datos para cumplir la política de conservación de datos o para la recuperación tras fallos.
- Importar el archivo Avro a otras Google Cloud ofertas, como BigQuery.
Para obtener más información sobre el proceso de exportación e importación, consulta los artículos Exportar bases de datos e Importar bases de datos.
Siguientes pasos
- Consulta cómo optimizar tu esquema de Spanner.
- Consulta cómo usar Dataflow en situaciones más complejas.