Cette page explique comment importer des bases de données Spanner dans Spanner à l'aide de la console Google Cloud . Si vous souhaitez importer des fichiers Avro à partir d'une autre source, consultez Importer des données à partir de bases de données autres que Spanner.
Ce processus fait appel à Dataflow. Il consiste à importer des données à partir d'un dossier de bucket Cloud Storage contenant un ensemble de fichiers Avro et de fichiers manifestes JSON. Le processus d'importation n'accepte que les fichiers Avro exportés à partir de Spanner.
Pour importer une base de données Spanner à l'aide de l'API REST ou de gcloud CLI, suivez les étapes de la section Avant de commencer sur cette page, puis consultez les instructions détaillées de Cloud Storage Avro vers Spanner.
Avant de commencer
Pour importer une base de données Spanner, vous devez d'abord activer les API Spanner, Cloud Storage, Compute Engine et Dataflow :
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Vous devez également disposer d'un quota suffisant, ainsi que des autorisations IAM requises.
Exigences en matière de quota
Voici les exigences de quota pour les tâches d'importation :
- Spanner : vous devez disposer d'une capacité de calcul suffisante pour prendre en charge la quantité de données que vous importez. Aucune capacité de calcul supplémentaire n'est requise pour importer une base de données, mais il peut s'avérer nécessaire d'ajouter de la capacité de calcul pour que la tâche se termine dans un délai raisonnable. Pour en savoir plus, consultez Optimiser les tâches.
- Cloud Storage : pour effectuer des importations, vous devez disposer d'un bucket contenant les fichiers que vous avez exportés auparavant. Il n'est pas nécessaire de spécifier une taille pour ce bucket.
- Dataflow : les tâches d'importation sont soumises aux mêmes exigences que les autres tâches Dataflow en ce qui concerne les quotas Compute Engine, aussi bien pour l'utilisation de processeurs et d'espace disque que pour le nombre d'adresses IP.
Compute Engine : avant d'exécuter une tâche d'importation, vous devez définir les quotas initiaux Compute Engine utilisés par Dataflow. Ces quotas représentent les quantités maximales de ressources que Dataflow pourra utiliser pour votre tâche. Les valeurs de départ recommandées sont les suivantes :
- Processeurs : 200
- Adresses IP en cours d'utilisation : 200
- Disque persistant standard : 50 To
En règle générale, vous n'avez pas d'autres réglages à effectuer. Dataflow assure un autoscaling qui vous permet de ne payer que pour les ressources réellement utilisées lors de l'importation. S'il apparaît que votre tâche pourrait utiliser davantage de ressources, l'interface utilisateur de Dataflow affiche une icône d'avertissement, mais cela n'empêche normalement pas la tâche d'aboutir.
Rôles requis
Pour obtenir les autorisations nécessaires pour exporter une base de données, demandez à votre administrateur de vous accorder les rôles IAM suivants sur le compte de service de l'utilisateur Dataflow :
-
Lecteur Cloud Spanner (
roles/spanner.viewer) -
Nœud de calcul Dataflow (
roles/dataflow.worker) -
Administrateur de l'espace de stockage (
roles/storage.admin) -
Lecteur de bases de données Spanner (
roles/spanner.databaseReader) -
Administrateur de base de données (
roles/spanner.databaseAdmin)
Rechercher le dossier de votre base de données dans Cloud Storage (facultatif)
Pour trouver le dossier contenant votre base de données exportée dans la consoleGoogle Cloud , accédez au navigateur Cloud Storage, puis cliquez sur le bucket contenant le dossier exporté.
Accéder au navigateur Cloud Storage
Le nom du dossier contenant vos données exportées commence par l'ID de votre instance, suivi du nom de la base de données et de l'horodatage de la tâche d'exportation. Ce dossier contient :
- Un fichier
spanner-export.json. - Un fichier
TableName-manifest.jsonpour chaque table de la base de données que vous avez exportée. Un ou plusieurs fichiers
TableName.avro-#####-of-#####. Le premier nombre figurant dans l'extension.avro-#####-of-#####représente l'index du fichier Avro compté à partir de zéro, tandis que le second correspond au nombre de fichiers Avro générés pour chaque table.Par exemple,
Songs.avro-00001-of-00002est le deuxième des deux fichiers contenant les données de la tableSongs.Un fichier
ChangeStreamName-manifest.jsonpour chaque flux de modifications de la base de données que vous avez exportée.Un fichier
ChangeStreamName.avro-00000-of-00001pour chaque flux de modifications. Ce fichier contient des données vides avec uniquement le schéma Avro du flux de modifications.
Importer une base de données
Pour importer votre base de données Spanner dans votre instance à partir de Cloud Storage, procédez comme suit.
Accédez à la page Instances de Spanner.
Cliquez sur le nom de l'instance qui contiendra la base de données importée.
Cliquez sur l'élément de menu Importer/Exporter dans le volet de gauche, puis sur le bouton Importer.
Sous Sélectionner un dossier source, cliquez sur Parcourir.
Recherchez le bucket contenant votre exportation dans la liste initiale, ou cliquez sur Rechercher
 pour le retrouver en filtrant la liste. Double-cliquez sur le bucket pour afficher les dossiers qu'il contient.
pour le retrouver en filtrant la liste. Double-cliquez sur le bucket pour afficher les dossiers qu'il contient.Recherchez le dossier contenant vos fichiers exportés et cliquez dessus pour le sélectionner.
Cliquez sur Sélectionner.
Saisissez un nom pour la base de données qui sera créée par Spanner lors du processus d'importation. Vous ne pouvez pas spécifier un nom de base de données existant déjà dans votre instance.
Choisissez le dialecte de la nouvelle base de données (GoogleSQL ou PostgreSQL).
(Facultatif) Pour protéger la nouvelle base de données à l'aide d'une clé de chiffrement gérée par le client, cliquez surAfficher les options de chiffrement et sélectionnez Utiliser une clé de chiffrement gérée par le client (CMEK). Sélectionnez ensuite une clé dans la liste déroulante.
Sélectionnez une région dans le menu déroulant Sélectionner une région pour la tâche d'importation.
(Facultatif) Pour chiffrer l'état du pipeline Dataflow avec une clé de chiffrement gérée par le client, cliquez sur Afficher les options de chiffrement puis sélectionnez Utiliser une clé de chiffrement gérée par le client (CMEK). Sélectionnez ensuite une clé dans la liste déroulante.
Cochez la case située sous Confirmer les frais pour accepter la facturation de frais supplémentaires en plus des frais relatifs à vos instances Spanner existantes.
Cliquez sur Importer.
La console Google Cloud affiche la page Détails de la base de données, qui comporte à présent une zone décrivant votre tâche d'importation et indiquant le temps écoulé.

Lorsque la tâche se termine ou est interrompue, la console Google Cloud affiche un message sur la page Détails de la base de données. Si la tâche a abouti, un message tel que celui-ci apparaît :

Si la tâche n'a pas abouti, un message d'échec apparaît :

En cas d'échec, consultez les journaux Dataflow de cette tâche pour connaître les détails de l'erreur et consultez la section Résoudre les problèmes liés aux tâches d'importation ayant échoué.
Remarque sur l'importation des colonnes générées et des flux de modifications
Spanner utilise la définition de chaque colonne générée dans le schéma Avro pour recréer cette colonne. Spanner calcule automatiquement les valeurs de colonne générées lors de l'importation.
De même, Spanner utilise la définition de chaque flux de modifications dans le schéma Avro pour le recréer lors de l'importation. Les données de flux de modifications ne sont ni exportées ni importées via Avro. Par conséquent, tous les flux de modifications associés à une base de données récemment importée ne comporteront aucun enregistrement de données de modifications.
Remarque sur l'importation de séquences
Chaque séquence (GoogleSQL, PostgreSQL) exportée par Spanner utilise la fonction GET_INTERNAL_SEQUENCE_STATE() (GoogleSQL, PostgreSQL) pour capturer son état actuel.
Spanner ajoute un tampon de 1 000 au compteur et écrit la nouvelle valeur du compteur dans les propriétés du champ d'enregistrement. Notez qu'il s'agit uniquement d'une approche optimale pour éviter les erreurs de valeurs en double qui peuvent se produire après l'importation.
Ajustez le compteur de séquence réel si la base de données source fait l'objet d'écritures supplémentaires pendant l'exportation des données.
Lors de l'importation, la séquence commence à partir de ce nouveau compteur au lieu de celui trouvé dans le schéma. Si nécessaire, vous pouvez utiliser l'instruction ALTER SEQUENCE (GoogleSQL, PostgreSQL) pour passer à un nouveau compteur.
Remarque sur l'importation de tables entrelacées et de clés étrangères
La tâche Dataflow peut importer des tables entrelacées, ce qui vous permet de conserver les relations parent-enfant de votre fichier source. Toutefois, les contraintes de clé étrangère ne sont pas appliquées lors du chargement des données. La tâche Dataflow crée toutes les clés étrangères nécessaires une fois le chargement des données terminé.
Si vous avez des contraintes de clé étrangère sur la base de données Spanner avant le début de l'importation, vous pouvez rencontrer des erreurs d'écriture en raison de violations de l'intégrité référentielle. Pour éviter les erreurs d'écriture, envisagez de supprimer les clés étrangères existantes avant de lancer le processus d'importation.
Sélectionner une région pour votre tâche d'importation
Vous pouvez être amené à choisir une région différente en fonction de l'emplacement de votre bucket Cloud Storage. Pour éviter les frais de transfert de données sortantes, choisissez une région qui correspond à l'emplacement de votre bucket Cloud Storage.
Si l'emplacement de votre bucket Cloud Storage est une région, vous pouvez bénéficier de l'utilisation gratuite du réseau en choisissant la même région pour votre tâche d'importation, à condition que cette région soit disponible.
Si l'emplacement de votre bucket Cloud Storage est birégional, vous pouvez bénéficier de l'utilisation gratuite du réseau en choisissant l'une des deux régions qui composent l'emplacement birégional pour votre tâche d'importation, à condition que l'une des régions soit disponible.
- Si aucune région colocalisée n'est disponible pour votre tâche d'importation ou si l'emplacement de votre bucket Cloud Storage est multirégional, des frais de transfert de données sortantes s'appliquent. Consultez les tarifs de transfert de données de Cloud Storage pour choisir la région qui générera les frais de transfert de données les plus bas.
Afficher ou dépanner des tâches dans l'interface utilisateur de Dataflow
Après avoir démarré une tâche d'importation, vous pouvez consulter les détails de cette tâche et les journaux associés dans la section Dataflow de la console Google Cloud .
Afficher les détails d'un job Dataflow
Pour afficher les détails des tâches d'importation ou d'exportation exécutées au cours de la dernière semaine, y compris les tâches en cours d'exécution :
- Accédez à la page Présentation de la base de données correspondant à la base de données.
- Cliquez sur l'élément de menu du volet Importations/Exportations à gauche. La page Importations/Exportations de la base de données affiche la liste des tâches récentes.
Sur la page Importations/Exportations de la base de données, cliquez sur le nom de la tâche dans la colonne Nom de la tâche Dataflow :
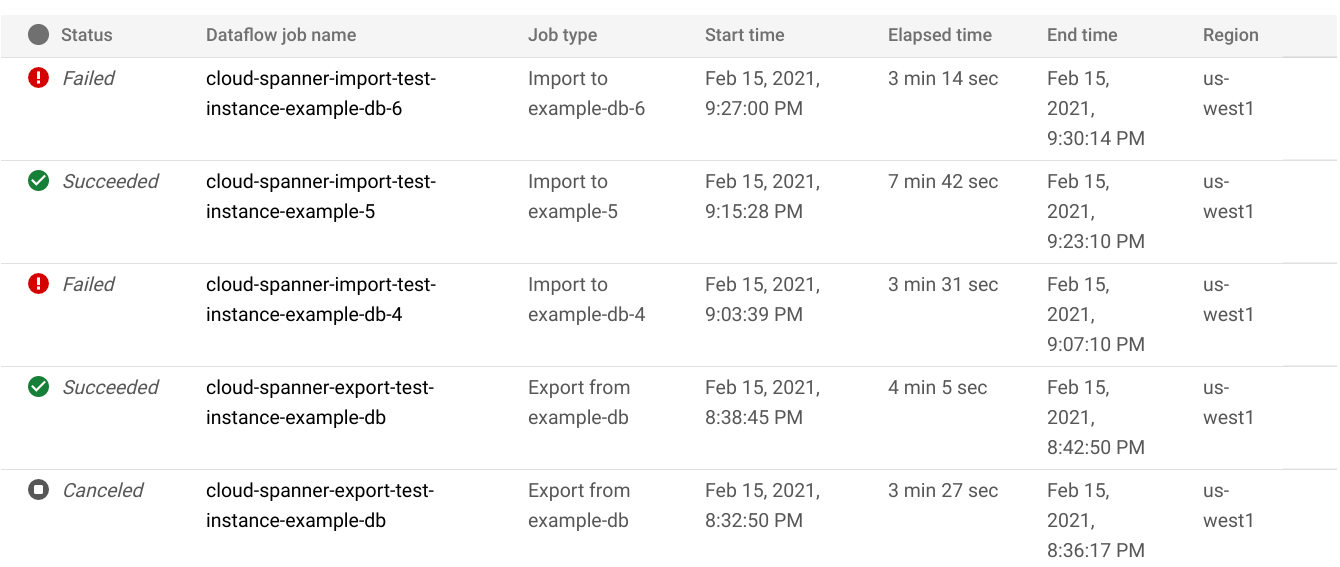
La console Google Cloud affiche les détails de la tâche Dataflow.
Pour afficher une tâche que vous avez exécutée il y a plus d'une semaine :
Accédez à la page des jobs Dataflow dans la console Google Cloud .
Recherchez votre tâche dans la liste, puis cliquez sur son nom.
La console Google Cloud affiche les détails de la tâche Dataflow.
Afficher les journaux Dataflow correspondant à votre tâche
Pour afficher les journaux d'une tâche Dataflow, accédez à la page des détails de la tâche, puis cliquez sur Journaux à droite du nom de la tâche.
Si une tâche échoue, recherchez les erreurs dans les journaux. Si des erreurs ont été enregistrées, leur nombre s'affiche à côté du bouton Logs (Journaux) :

Pour afficher les erreurs relatives à une tâche :
Cliquez sur le nombre d'erreurs à côté de Journaux.
La console Google Cloud affiche les journaux de la tâche. Vous devrez éventuellement faire défiler l'affichage pour voir les erreurs.
Repérez les entrées signalées par l'icône d'erreur
 .
.Cliquez sur une entrée de journal pour développer son contenu.
Pour en savoir plus sur le dépannage lié aux tâches Dataflow, consultez Résoudre les problèmes liés à votre pipeline.
Résoudre les problèmes liés aux tâches d'importation ayant échoué
Si les erreurs suivantes s'affichent dans les journaux de vos tâches :
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Vérifiez la latence d'écriture de 99 % dans l'onglet Surveillance de votre base de données Spanner dans la consoleGoogle Cloud . Si elle affiche des valeurs élevées (plusieurs secondes), cela signifie que l'instance est surchargée, ce qui entraîne l'expiration et l'échec de l'écriture.
Cette latence élevée peut s'expliquer notamment par le fait que la tâche Dataflow s'exécute à l'aide d'un trop grand nombre de nœuds de calcul, ce qui surcharge l'instance Spanner.
Pour spécifier une limite de nœuds de calcul Dataflow, au lieu d'utiliser l'onglet "Importer/Exporter" sur la page des détails de l'instance de votre base de données Spanner dans la console Google Cloud , vous devez démarrer l'importation à l'aide du modèle Cloud Storage Avro vers Spanner Dataflow et spécifier le nombre maximal de nœuds de calcul, comme décrit ci-dessous :Console
Si vous utilisez la console Dataflow, le paramètre Nombre maximal de nœuds de calcul se trouve dans la section Paramètres facultatifs de la page Créer une tâche à partir d'un modèle.
gcloud
Exécutez la commande gcloud dataflow jobs run et spécifiez l'argument max-workers. Exemple :
gcloud dataflow jobs run my-import-job \
--gcs-location='gs://dataflow-templates/latest/GCS_Avro_to_Cloud_Spanner' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,inputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Résoudre les problèmes de réseau
L'erreur suivante peut se produire lorsque vous exportez vos bases de données Spanner :
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
Cette erreur se produit, car Spanner part du principe que vous avez l'intention d'utiliser un réseau VPC en mode automatique nommé default dans le même projet que le job Dataflow. Si vous n'avez pas de réseau VPC par défaut dans le projet, ou si votre réseau VPC est en mode personnalisé, vous devez créer un job Dataflow et spécifier un autre réseau ou sous-réseau.
Optimiser les tâches d'importation lentes
Si vous avez adopté les paramètres initiaux suggérés plus haut, vous n'avez en principe aucun autre réglage à effectuer. Voici toutefois quelques possibilités d'optimisation supplémentaires à envisager si l'exécution de votre tâche est lente :
Optimisez l'emplacement de la tâche et des données : exécutez la tâche Dataflow dans la même région que celle où se trouvent votre instance Spanner et votre bucket Cloud Storage.
Veillez à ce que les ressources Dataflow soient suffisantes : si les ressources de votre job Dataflow sont limitées par les quotas Compute Engine pertinents, la page Dataflow correspondant à ce job dans la console Google Cloud affiche une icône d'avertissement
 ainsi qu'un message de journalisation :
ainsi qu'un message de journalisation :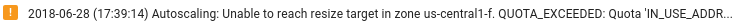
Dans ce cas, l'augmentation des quotas en termes de processeurs, d'adresses IP en cours d'utilisation et de disques persistants standards peut accélérer l'exécution de votre tâche, mais également augmenter les frais facturés pour Compute Engine.
Vérifiez l'utilisation du processeur associée à Spanner : si vous constatez qu'une instance présente un taux d'utilisation du processeur supérieur à 65 %, vous pouvez augmenter la capacité de calcul pour cette instance. La capacité ajoute davantage de ressources Spanner et la tâche devrait accélérer, mais vous devrez payer plus de frais pour Spanner.
Facteurs affectant les performances des tâches d'importation
Plusieurs facteurs influent sur le temps nécessaire pour mener à bien une tâche d'importation.
Taille de la base de données Spanner : le temps de traitement et les ressources requises augmentent avec la quantité de données à traiter.
Le schéma de la base de données Spanner, y compris :
- Nombre de tables
- Taille des lignes
- Nombre d'index secondaires
- Nombre de clés étrangères
- Nombre de flux de modifications
Notez que le processus de création d'index et de clés étrangères se poursuit une fois la tâche d'importation Dataflow terminée. Les flux de modifications sont créés avant la fin du job d'importation, mais après l'importation de toutes les données.
Emplacement des données : les données sont transférées de Spanner à Cloud Storage à l'aide de Dataflow. Dans l'idéal, ces trois composants doivent se trouver dans la même région. Dans le cas contraire, le déplacement des données entre les régions ralentit l'exécution de la tâche.
Nombre de nœuds de calcul Dataflow : les nœuds de calcul Dataflow optimaux sont nécessaires pour de bonnes performances. En utilisant l'autoscaling, Dataflow choisit le nombre de nœuds de calcul pour la tâche en fonction de la quantité de travail à effectuer. Le nombre de nœuds de calcul sera toutefois limité par les quotas en matière de processeurs, d'adresses IP en cours d'utilisation et de disques persistants standards. L'interface utilisateur de Dataflow affiche une icône d'avertissement lorsque des limites de quota sont atteintes. Dans ce cas, la progression est ralentie, mais la tâche doit néanmoins aboutir. L'autoscaling peut surcharger Spanner, ce qui entraîne des erreurs lorsque le volume de données est particulièrement important.
Charge existante sur Spanner : une tâche d'importation ajoute une charge de processeur importante sur une instance Spanner. Si cette instance présentait déjà une charge importante, l'exécution de la tâche est ralentie.
Quantité de capacité de calcul Spanner : si l'instance présente un taux d'utilisation du processeur supérieur à 65 %, l'exécution de la tâche est ralentie.
Régler les nœuds de calcul afin d'obtenir de bonnes performances pour l'importation
Lorsque vous démarrez une tâche d'importation Spanner, les nœuds de calcul Dataflow doivent être définis sur une valeur optimale pour optimiser les performances. Un trop grand nombre de nœuds de calcul peut surcharger Spanner, et un nombre trop faible de nœuds de calcul entraîne une baisse des performances d'importation.
Le nombre maximal de nœuds de calcul dépend fortement de la taille des données. Idéalement, l'utilisation totale du processeur associée à Spanner doit être comprise entre 70 % et 90 %. Cela permet d'obtenir un bon équilibre entre l'efficacité de Spanner et l'exécution d'une tâche sans erreur.
Pour atteindre cet objectif d'utilisation dans la majorité des schémas et des scénarios, nous recommandons un nombre maximal de processeurs virtuels de nœud de calcul compris entre 4 et 6 fois le nombre de nœuds Spanner.
Par exemple, pour une instance Spanner à 10 nœuds utilisant des nœuds de calcul n1-standard-2, vous devez définir un nombre maximal de nœuds de calcul sur 25, ce qui donne 50 processeurs virtuels.