En esta página se describe cómo exportar bases de datos de Spanner con la consola deGoogle Cloud .
Para exportar una base de datos de Spanner mediante la API REST o la CLI de Google Cloud, sigue los pasos de la sección Antes de empezar de esta página y, a continuación, consulta las instrucciones detalladas en Spanner a Avro de Cloud Storage en la documentación de Dataflow. El proceso de exportación usa Dataflow y escribe los datos en una carpeta de un segmento de Cloud Storage. La carpeta resultante contiene un conjunto de archivos Avro y archivos de manifiesto JSON.
Antes de empezar
Para exportar una base de datos de Spanner, primero debes habilitar las APIs de Spanner, Cloud Storage, Compute Engine y Dataflow:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
También necesitas suficiente cuota y los permisos de gestión de identidades y accesos necesarios.
Requisitos de cuota
Los requisitos de cuota de las tareas de exportación son los siguientes:
- Spanner: no se necesita capacidad de computación adicional para exportar una base de datos, aunque es posible que tengas que añadir más capacidad de computación para que tu tarea finalice en un plazo razonable. Para obtener más información, consulta Trabajos de Optimize.
- Cloud Storage: para exportar, debes crear un segmento para los archivos exportados si aún no tienes ninguno. Puede hacerlo en la Google Cloud consola, ya sea en la página de Cloud Storage o al crear la exportación en la página de Spanner. No es necesario que defina un tamaño para el segmento.
- Dataflow: las tareas de exportación están sujetas a las mismas cuotas de CPU, uso de disco y dirección IP de Compute Engine que otras tareas de Dataflow.
Compute Engine: antes de ejecutar el trabajo de exportación, debes configurar las cuotas iniciales de Compute Engine, que utiliza Dataflow. Estas cuotas representan el número máximo de recursos que permites que Dataflow use en tu trabajo. Los valores iniciales recomendados son los siguientes:
- CPUs: 200
- Direcciones IP en uso: 200
- Disco persistente estándar: 50 TB
Por lo general, no tienes que hacer ningún otro ajuste. Dataflow proporciona escalado automático para que solo pagues por los recursos reales utilizados durante la exportación. Si tu trabajo puede usar más recursos, la interfaz de usuario de Dataflow muestra un icono de advertencia. El trabajo debería finalizar aunque haya un icono de advertencia.
Roles obligatorios
Para obtener los permisos que necesitas para exportar una base de datos, pide a tu administrador que te conceda los siguientes roles de gestión de identidades y accesos en la cuenta de servicio de trabajador de Dataflow:
-
Lector de Cloud Spanner (
roles/spanner.viewer) -
Trabajador de Dataflow (
roles/dataflow.worker) -
Administrador de almacenamiento (
roles/storage.admin) -
Lector de las bases de datos de Spanner (
roles/spanner.databaseReader) -
Administrador de bases de datos (
roles/spanner.databaseAdmin)
Para usar los recursos de computación independientes de Spanner Data Boost durante una exportación, también necesitas el permiso spanner.databases.useDataBoost de gestión de identidades y accesos. Para obtener más información, consulta el artículo sobre Data Boost.
Exportar una base de datos
Una vez que hayas cumplido los requisitos de cuota y de gestión de identidades y accesos descritos anteriormente, podrás exportar una base de datos de Spanner.
Para exportar tu base de datos de Spanner a un segmento de Cloud Storage, sigue estos pasos:
Ve a la página Instancias de Spanner.
Haga clic en el nombre de la instancia que contiene su base de datos.
En el panel de la izquierda, haz clic en Importar/Exportar y, a continuación, en el botón Exportar.
En Selecciona dónde quieres almacenar tu exportación, haz clic en Examinar.
Si aún no tienes un segmento de Cloud Storage para la exportación, sigue estos pasos:
- Haz clic en Nuevo contenedor
 .
. - Introduce un nombre para el contenedor. Los nombres de los segmentos deben ser únicos en Cloud Storage.
- Selecciona una clase de almacenamiento y una ubicación predeterminadas y, a continuación, haz clic en Crear.
- Haz clic en el contenedor para seleccionarlo.
Si ya tienes un contenedor, selecciónalo de la lista inicial o haz clic en Buscar
 para filtrar la lista y, a continuación, haz clic en el contenedor para seleccionarlo.
para filtrar la lista y, a continuación, haz clic en el contenedor para seleccionarlo.- Haz clic en Nuevo contenedor
Haz clic en Seleccionar.
En el menú desplegable Elige una base de datos para exportar, selecciona la base de datos que quieras exportar.
Opcional: Para exportar tu base de datos desde un momento anterior, marca la casilla e introduce una marca de tiempo.
Selecciona una región en el menú desplegable Selecciona una región para la tarea de exportación.
.Opcional: Para cifrar el estado de la canalización de Dataflow con una clave de cifrado gestionada por el cliente, haz lo siguiente:
- Haz clic en Mostrar opciones de cifrado.
- Selecciona Usar una clave de cifrado gestionada por el cliente (CMEK).
- Selecciona tu clave en la lista desplegable.
Esta opción no afecta al cifrado a nivel del segmento de destino de Cloud Storage. Para habilitar la clave CMEK en tu segmento de Cloud Storage, consulta el artículo Usar la clave CMEK con Cloud Storage.
Opcional: Para exportar datos con Spanner Data Boost, selecciona la casilla Usar Spanner Data Boost. Para obtener más información, consulta el artículo sobre Data Boost.
Seleccione la casilla de verificación de Confirm charges (Confirmar cargos) para confirmar que se aplicarán cargos adicionales a los de su instancia de Spanner.
Haz clic en Exportar.
En la consola se muestra la página Importación/exportación de bases de datos, en la que ahora se muestra una línea de pedido de su trabajo de exportación en la lista Trabajos de importación/exportación, incluida la duración del trabajo: Google Cloud
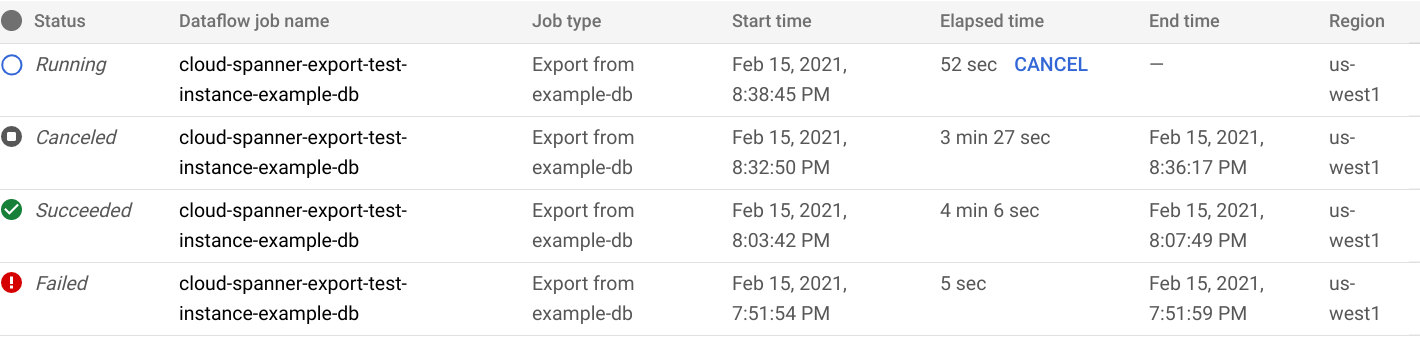
Cuando el trabajo finalice o termine, el estado se actualizará en la lista Importar/Exportar. Si el trabajo se ha completado correctamente, se muestra el estado Completado:

Si la tarea ha fallado, se muestra el estado Failed (Fallida):

Para ver los detalles de la operación de Dataflow de tu trabajo, haz clic en el nombre del trabajo en la columna Nombre del trabajo de Dataflow.
Si la tarea falla, consulta los registros de Dataflow de la tarea para obtener información sobre el error.
Para evitar que se te cobre por los archivos de Cloud Storage que haya creado el trabajo de exportación fallido, elimina la carpeta y sus archivos. Consulta Ver tu exportación para obtener información sobre cómo encontrar la carpeta.
Nota sobre la exportación de columnas generadas y secuencias de cambios
Los valores de una columna generada almacenada no se exportan. La definición de la columna se exporta al esquema de Avro como un campo de registro de tipo nulo, con la definición de la columna como propiedades personalizadas del campo. Hasta que se complete la operación de relleno de una columna generada recién añadida, la columna generada se ignora como si no existiera en el esquema.
Los flujos de cambios exportados como archivos Avro solo contienen el esquema de los flujos de cambios, no los registros de cambios de datos.
Nota sobre la exportación de secuencias
Las secuencias (GoogleSQL y PostgreSQL) son objetos de esquema que se usan para generar valores enteros únicos.
Spanner exporta cada objeto de esquema al esquema Avro como un campo de registro, con su tipo de secuencia, intervalo omitido y contador como propiedades del campo. Ten en cuenta que, para evitar que se restablezca una secuencia y se generen valores duplicados después de la importación, durante la exportación del esquema, la función GET_INTERNAL_SEQUENCE_STATE() (GoogleSQL, PostgreSQL) captura el contador de la secuencia. Spanner añade un búfer de 1000 al contador y escribe el nuevo valor del contador en el campo de registro. De esta forma, se evitan errores de valores duplicados que pueden producirse después de la importación.
Si se realizan más escrituras en la base de datos de origen durante la exportación de datos, debes ajustar el contador de secuencia real mediante la instrucción ALTER SEQUENCE
(GoogleSQL,
PostgreSQL).
Durante la importación, la secuencia empieza a partir de este nuevo contador en lugar del contador que se encuentra en el esquema. También puedes usar la instrucción ALTER SEQUENCE
(GoogleSQL,
PostgreSQL)
para actualizar la secuencia con un nuevo contador.
Ver la exportación en Cloud Storage
Para ver la carpeta que contiene la base de datos exportada en la consolaGoogle Cloud , ve al navegador de Cloud Storage y elige el segmento que has seleccionado anteriormente:
Ir al navegador de almacenamiento
El contenedor ahora incluye una carpeta con la base de datos exportada. El nombre de la carpeta empieza por el ID de tu instancia, el nombre de la base de datos y la marca de tiempo de tu tarea de exportación. La carpeta contiene lo siguiente:
- Un archivo
spanner-export.json - Un archivo
TableName-manifest.jsonpor cada tabla de la base de datos que hayas exportado. Uno o varios archivos
TableName.avro-#####-of-#####. El primer número de la extensión.avro-#####-of-#####representa el índice del archivo Avro, que empieza por cero, y el segundo representa el número de archivos Avro generados para cada tabla.Por ejemplo,
Songs.avro-00001-of-00002es el segundo de los dos archivos que contienen los datos de la tablaSongs.Un archivo
ChangeStreamName-manifest.jsonpor cada flujo de cambios de la base de datos que hayas exportado.Un archivo
ChangeStreamName.avro-00000-of-00001por cada flujo de cambios. Este archivo contiene datos vacíos con solo el esquema Avro del flujo de cambios.
Selecciona una región para la tarea de importación
Puede que quieras elegir otra región en función de la ubicación de tu segmento de Cloud Storage. Para evitar cargos por transferencia de datos saliente, elige una región que coincida con la ubicación de tu segmento de Cloud Storage.
Si la ubicación de tu segmento de Cloud Storage es una región, puedes aprovechar el uso de red gratuito eligiendo la misma región para tu tarea de importación, siempre que esté disponible.
Si la ubicación de tu segmento de Cloud Storage es una región doble, puedes aprovechar el uso de red gratuito eligiendo una de las dos regiones que componen la región doble para tu tarea de importación, siempre que una de las regiones esté disponible.
- Si no hay ninguna región colocada disponible para tu tarea de importación o si la ubicación de tu segmento de Cloud Storage es una multirregión, se aplicarán cargos por transferencia de datos saliente. Consulta los precios de la transferencia de datos de Cloud Storage para elegir una región que genere los cargos más bajos por transferencia de datos.
Exportar un subconjunto de tablas
Si solo quieres exportar los datos de determinadas tablas y no de toda la base de datos, puedes especificar esas tablas durante la exportación. En este caso, Spanner exporta todo el esquema de la base de datos, incluidos los datos de las tablas que especifiques, y deja todas las demás tablas presentes, pero vacías, en el archivo exportado.
Puedes especificar un subconjunto de tablas para exportar mediante la página Dataflow de la Google Cloud consola o la CLI de gcloud. (La página de Spanner no ofrece esta acción).
Si exportas los datos de una tabla secundaria de otra tabla, también debes exportar los datos de la tabla principal. Si no se exportan los padres, la tarea de exportación fallará.
Para exportar un subconjunto de tablas, inicia la exportación con la plantilla de Spanner a Cloud Storage Avro de Dataflow y especifica las tablas mediante la página de Dataflow de la Google Cloud consola o con gcloud CLI, tal como se describe a continuación:
Consola
Si usas la página de Dataflow en la consola, el parámetro Nombre(s) de tabla de Cloud Spanner se encuentra en la sección Parámetros opcionales de la página Crear trabajo a partir de plantilla. Google Cloud Se pueden especificar varias tablas en un formato separado por comas.
gcloud
Ejecuta el comando gcloud dataflow jobs run
y especifica el argumento tableNames. Por ejemplo:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=table1,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Para especificar varias tablas en gcloud, es necesario escapar los argumentos de tipo diccionario.
En el siguiente ejemplo se usa "|" como carácter de escape:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='^|^instanceId=test-instance|databaseId=example-db|tableNames=table1,table2|outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
El parámetro shouldExportRelatedTables es una opción práctica para exportar automáticamente todas las tablas principales de las tablas elegidas. Por ejemplo, en esta jerarquía de esquemas
con las tablas Singers, Albums y Songs, solo tiene que especificar
Songs. La opción shouldExportRelatedTables también exportará Singers y Albums, ya que Songs es descendiente de ambos.
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,tableNames=Songs,shouldExportRelatedTables=true,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Ver o solucionar problemas de trabajos en la interfaz de Dataflow
Una vez que hayas iniciado un trabajo de exportación, puedes ver los detalles del trabajo, incluidos los registros, en la sección Dataflow de la Google Cloud consola.
Ver los detalles de una tarea de Dataflow
Para ver los detalles de las tareas de importación o exportación que hayas ejecutado en la última semana, incluidas las que se estén ejecutando en este momento, sigue estos pasos:
- Vaya a la página Resumen de la base de datos de la base de datos.
- Haz clic en la opción de menú Importar/Exportar del panel de la izquierda. En la página Importar/Exportar de la base de datos se muestra una lista de las tareas recientes.
En la página Importar/Exportar de la base de datos, haga clic en el nombre del trabajo de la columna Nombre del trabajo de Dataflow:
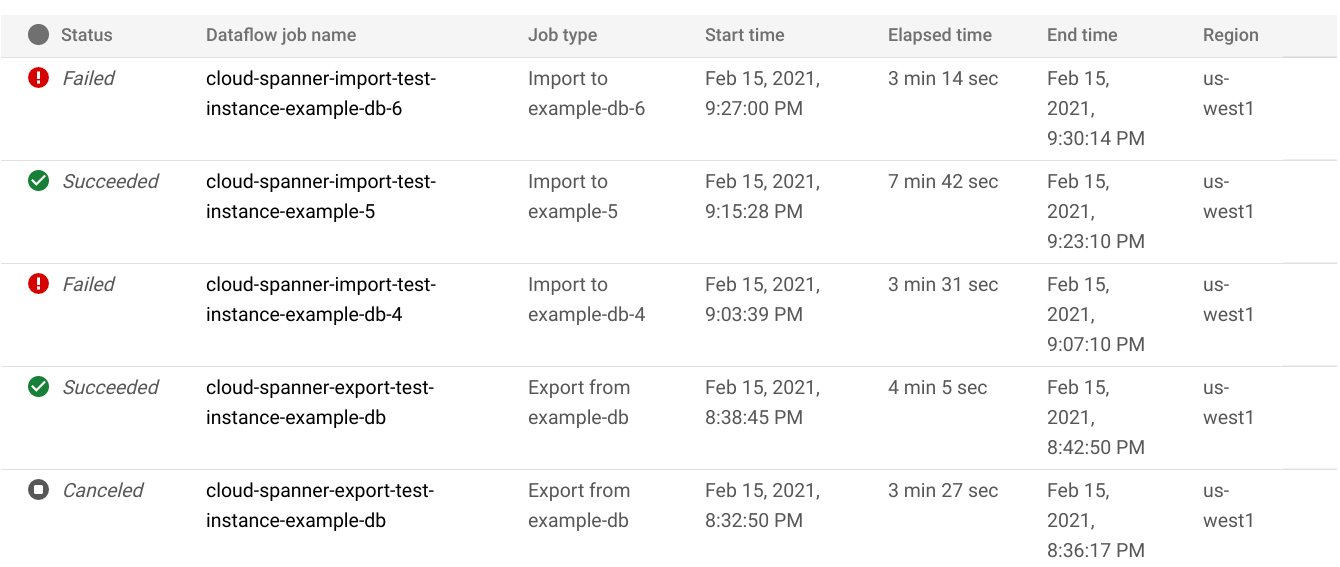
La consola Google Cloud muestra los detalles del trabajo de Dataflow.
Para ver un trabajo que ejecutaste hace más de una semana, sigue estos pasos:
Ve a la página de trabajos de Dataflow de la Google Cloud consola.
Busca el trabajo en la lista y haz clic en su nombre.
La consola Google Cloud muestra los detalles del trabajo de Dataflow.
Ver los registros de Dataflow de tu trabajo
Para ver los registros de un trabajo de Dataflow, ve a la página de detalles del trabajo y haz clic en Registros a la derecha del nombre del trabajo.
Si una tarea falla, busca errores en los registros. Si hay errores, el número de errores se mostrará junto a Registros:

Para ver los errores de las tareas, sigue estos pasos:
Haz clic en el número de errores situado junto a Registros.
La Google Cloud consola muestra los registros del trabajo. Puede que tengas que desplazarte para ver los errores.
Busca las entradas que tengan el icono de error
 .
.Haz clic en una entrada de registro para ver su contenido.
Para obtener más información sobre cómo solucionar problemas de trabajos de Dataflow, consulta el artículo Solucionar problemas de una canalización.
Solucionar problemas con tareas de exportación fallidas
Si ves los siguientes errores en los registros de tu trabajo:
com.google.cloud.spanner.SpannerException: NOT_FOUND: Session not found --or-- com.google.cloud.spanner.SpannerException: DEADLINE_EXCEEDED: Deadline expired before operation could complete.
Consulta la latencia de lectura del percentil 99 en la pestaña Monitorización de tu base de datos de Spanner en la consola.Google Cloud Si muestra valores altos (varios segundos), significa que la instancia está sobrecargada, lo que provoca que las lecturas se agoten y fallen.
Una de las causas de la alta latencia es que la tarea de Dataflow se ejecuta con demasiados trabajadores, lo que supone una carga excesiva para la instancia de Spanner.
Para especificar un límite en el número de trabajadores de Dataflow, en lugar de usar la pestaña Importar/Exportar de la página de detalles de la instancia de tu base de datos de Spanner en la consola de Google Cloud , debes iniciar la exportación con la plantilla de Spanner a Cloud Storage Avro y especificar el número máximo de trabajadores, tal como se describe a continuación:Consola
Si usas la consola de Dataflow, el parámetro Máximo de trabajadores se encuentra en la sección Parámetros opcionales de la página Crear trabajo a partir de plantilla.
gcloud
Ejecuta el comando gcloud dataflow jobs run
y especifica el argumento max-workers. Por ejemplo:
gcloud dataflow jobs run my-export-job \
--gcs-location='gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro' \
--region=us-central1 \
--parameters='instanceId=test-instance,databaseId=example-db,outputDir=gs://my-gcs-bucket' \
--max-workers=10 \
--network=network-123
Solucionar un error de red
Puede que se produzca el siguiente error al exportar tus bases de datos de Spanner:
Workflow failed. Causes: Error: Message: Invalid value for field 'resource.properties.networkInterfaces[0].subnetwork': ''. Network interface must specify a subnet if the network resource is in custom subnet mode. HTTP Code: 400
Este error se produce porque Spanner da por hecho que quieres usar una red VPC de modo automático llamada default en el mismo proyecto que el trabajo de Dataflow. Si no tienes una red de VPC predeterminada en el proyecto o si tu red de VPC está en una red de VPC de modo personalizado, debes crear un trabajo de Dataflow y especificar una red o subred alternativa.
Optimizar las tareas de exportación lentas
Si has seguido las sugerencias de la sección Configuración inicial, no deberías tener que hacer ningún otro ajuste. Si tu trabajo se ejecuta lentamente, puedes probar otras optimizaciones:
Optimizar la ubicación de la tarea y de los datos: ejecuta la tarea de Dataflow en la misma región en la que se encuentran tu instancia de Spanner y tu segmento de Cloud Storage.
Asegúrate de que haya suficientes recursos de Dataflow: si las cuotas de Compute Engine pertinentes limitan los recursos de tu tarea de Dataflow, en la página de Dataflow de la Google Cloud consola se mostrará un icono de advertencia
 y mensajes de registro:
y mensajes de registro: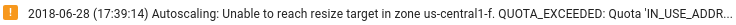
En esta situación, aumentar las cuotas de CPUs, direcciones IP en uso y discos persistentes estándar podría acortar el tiempo de ejecución del trabajo, pero es posible que incurras en más cargos de Compute Engine.
Comprueba la utilización de la CPU de Spanner: si ves que la utilización de la CPU de la instancia supera el 65%, puedes aumentar la capacidad de computación de esa instancia. La capacidad añade más recursos de Spanner y el trabajo debería acelerarse, pero incurrirás en más cargos de Spanner.
Factores que afectan al rendimiento de los trabajos de exportación
Hay varios factores que influyen en el tiempo que se tarda en completar una tarea de exportación.
Tamaño de la base de datos de Spanner: procesar más datos requiere más tiempo y recursos.
Esquema de la base de datos de Spanner, que incluye lo siguiente:
- El número de tablas
- El tamaño de las filas
- Número de índices secundarios
- Número de claves externas
- El número de flujos de cambios
Ubicación de los datos: los datos se transfieren entre Spanner y Cloud Storage mediante Dataflow. Lo ideal es que los tres componentes estén en la misma región. Si los componentes no están en la misma región, mover los datos entre regiones ralentiza el trabajo.
Número de trabajadores de Dataflow: se necesitan trabajadores de Dataflow óptimos para conseguir un buen rendimiento. Con el autoescalado, Dataflow elige el número de trabajadores de la tarea en función de la cantidad de trabajo que se debe realizar. Sin embargo, el número de trabajadores estará limitado por las cuotas de CPUs, direcciones IP en uso y discos persistentes estándar. La interfaz de usuario de Dataflow muestra un icono de advertencia si se encuentra con límites de cuota. En esta situación, el progreso es más lento, pero el trabajo debería completarse igualmente.
Carga existente en Spanner: una tarea de exportación suele añadir una carga ligera a una instancia de Spanner. Si la instancia ya tiene una carga considerable, la tarea se ejecutará más lentamente.
Cantidad de capacidad de computación de Spanner: si la utilización de la CPU de la instancia supera el 65%, el trabajo se ejecuta más lentamente.