O Spanner Data Boost é um serviço sem servidor totalmente gerido que fornece recursos de computação independentes para cargas de trabalho do Spanner suportadas. O Data Boost permite-lhe executar consultas de estatísticas e exportações de dados com um impacto quase nulo nas cargas de trabalho existentes na instância do Spanner aprovisionada. O serviço consiste em clusters do Spanner que a Google gere ao nível da região. Para consultas elegíveis que solicitam o Data Boost, o Spanner encaminha a carga de trabalho para estes servidores de forma transparente. As consultas elegíveis são aquelas para as quais o primeiro operador no plano de execução da consulta é uma união distribuída. Não tem de alterar estas consultas para tirar partido do aumento de dados.
O aumento de dados é mais eficaz nos seguintes cenários em que quer evitar impactos negativos no sistema transacional existente devido a contenção de recursos:
- Consultas ad hoc ou pouco frequentes que envolvem o processamento de grandes quantidades de dados. Um exemplo típico é uma consulta federada do BigQuery para o Spanner.
- Tarefas de exportação de dados ou relatórios. Um exemplo é uma tarefa do Dataflow para exportar dados do Spanner para o Cloud Storage.
O diagrama seguinte ilustra como o Data Boost se coordena com a instância do Spanner para fornecer recursos de computação independentes.
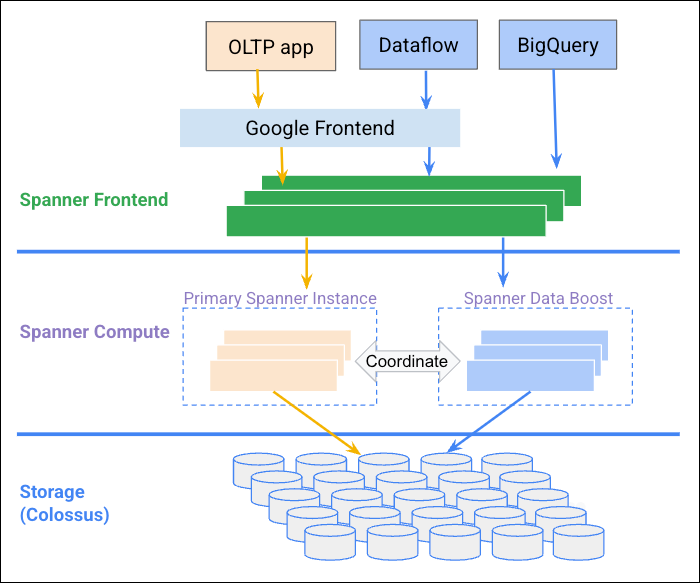
Vantagens
O aumento de dados oferece as seguintes vantagens:
- Oferece isolamento da carga de trabalho. Pode executar consultas suportadas nos dados mais recentes com um impacto quase nulo nas cargas de trabalho transacionais existentes, independentemente da complexidade da consulta ou da quantidade de dados processados.
- Oferece uma latência igual ou melhor.
- Impede o aprovisionamento excessivo de instâncias do Spanner apenas para suportar consultas de estatísticas ocasionais.
- Oferece um elevado grau de escalabilidade com um maior paralelismo de consultas que é escalável de forma elástica com cargas de picos.
- Fornece métricas abrangentes que permitem aos administradores identificar as consultas mais caras e determinar o componente de custo a otimizar. Em seguida, os administradores podem validar o impacto das respetivas otimizações monitorizando o consumo de unidades de processamento sem servidor da consulta na execução seguinte.
- Não requer custos operacionais adicionais. Não existe nenhum serviço adicional para gerir, nenhum planeamento ou aprovisionamento de capacidade, não é necessário esperar pela escalabilidade e não existe manutenção.
Autorizações
Qualquer principal que execute uma consulta ou uma exportação que peça o Data Boost tem de ter a autorização da spanner.databases.useDataBoost gestão de identidade e de acesso (IAM)
. Recomendamos que use a função de IAM
Cloud Spanner Database Reader With DataBoost (roles/spanner.databaseReaderWithDataBoost).
Faturação e quotas
Paga apenas as unidades de processamento reais usadas por consultas executadas no Data Boost. Os administradores podem definir limites de utilização para evitar exceder os custos.
O que se segue?
- Execute consultas federadas com o Data Boost
- Exporte dados com o aumento de dados
- Use a Otimização de dados nas suas aplicações
- Monitorize a utilização do aumento de dados
- Monitorize e faça a gestão da utilização da quota do Aumento de dados