이 페이지에서는 Spanner의 동반 도구로 사용할 수 있는 오픈소스 도구인 Spanner(자동 확장 처리)용 자동 확장 처리 도구를 소개합니다. 이 도구를 사용하면 사용 중인 용량을 기준으로 Spanner 인스턴스 하나 이상에서 컴퓨팅 용량을 자동으로 늘리거나 줄일 수 있습니다.
Spanner 확장에 대한 자세한 내용은 Spanner 자동 확장을 참조하세요. 자동 확장 처리 도구 배포에 대한 자세한 내용은 다음을 참조하세요.
- Spanner용 자동 확장 처리 도구를 Cloud Run Functions에 배포합니다.
- Spanner용 자동 확장 처리 도구를 Google Kubernetes Engine(GKE)에 배포합니다.
이 페이지에서는 자동 확장 처리의 기능, 아키텍처, 대략적인 구성을 보여줍니다. 이 주제에서는 서로 다른 토폴로지에서 지원되는 런타임 중 하나에 자동 확장 처리를 배포하는 과정을 안내합니다.
자동 확장 처리
자동 확장 처리 도구는 Spanner 배포의 사용량과 성능을 관리하는 데 유용합니다. 성능 요구 사항에 맞춰 비용 관리를 돕기 위해 자동 확장 처리 도구는 인스턴스를 모니터링하고 다음 매개변수가 유지되도록 노드 또는 처리 단위를 자동으로 추가하거나 삭제합니다.
구성 가능한 마진을 더하거나 뺍니다.
Spanner 배포를 자동 확장하면 인프라가 간섭에 거의 또는 전혀 없이 부하 요구사항을 충족하도록 자동으로 조정하거나 확장할 수 있습니다. 자동 확장 기능은 프로비저닝된 인프라 크기를 올바르게 조정하므로 요금이 최소한으로 청구될 수 있습니다.
아키텍처
자동 확장 처리에는 Poller 및 Scaler라는 두 가지 주요 구성요소가 있습니다. 구성이 다른 여러 토폴로지의 런타임 여러 개에 구성이 다른 자동 확장 처리를 배포할 수 있지만 이러한 핵심 구성요소 기능은 동일합니다.
이 섹션에서는 이러한 두 구성요소와 용도를 자세히 설명합니다.
Poller
Poller는 Spanner 인스턴스 하나 이상에 대한 시계열 측정항목을 수집하고 처리합니다. Poller는 각 Spanner 인스턴스의 측정항목 데이터를 사전 처리하므로 가장 관련성이 높은 데이터 포인트만 평가되고 Scaler로 전송됩니다. Poller에서 수행하는 사전 처리도 리전, 이중 리전, 멀티 리전 Spanner 인스턴스의 기준점 평가 프로세스를 간소화합니다.
Scaler
Scaler는 Poller 구성요소에서 수신한 데이터 포인트를 평가하고 노드 수나 처리 단위 수를 조정해야 하는지 여부와 조정해야 하는 경우 그 양을 결정합니다. 측정항목 값과 기준점을 비교하고 허용 마진을 더하거나 빼고 구성된 확장 방법에 따라 노드 수나 처리 단위 수를 조정합니다. 자세한 내용은 확장 방법을 참조하세요.
이 과정에서 자동 확장 처리 도구는 추적 및 감사할 수 있도록 해당 권장사항과 작업에 대한 요약을 Cloud Logging에 작성합니다.
자동 확장 처리 기능
이 섹션에서는 자동 확장 처리 도구의 주요 기능을 설명합니다.
여러 인스턴스 관리
자동 확장 처리 도구는 여러 프로젝트에서 Spanner 인스턴스 여러 개를 관리할 수 있습니다. 멀티 리전, 이중 리전, 리전 인스턴스는 모두 확장 시 사용되는 여러 다른 사용률 기준점이 포함됩니다. 예를 들어 멀티 리전 및 이중 리전 배포는 우선순위가 높은 CPU 사용량 45%로 확장되는 반면 리전 배포는 우선순위가 높은 CPU 사용량 65%로 확장되며 둘 다 허용 margin을 더하거나 뺍니다. 확장을 위한 다양한 기준점에 대한 자세한 내용은 높은 CPU 사용량 알림을 참조하세요.
독립 구성 매개변수
자동 확장된 각 Spanner 인스턴스에는 하나 이상의 폴링 일정이 있을 수 있습니다. 각 폴링 일정에는 고유한 구성 매개변수 집합이 있습니다.
이러한 매개변수는 다음 요소를 결정합니다.
- 최대 및 최소 노드 수나 처리 단위 수로, 인스턴스 확장 또는 축소 정도를 제어하여 비용 청구를 관리할 수 있습니다.
- 확장 방법은 워크로드와 관련된 Spanner 인스턴스를 조정하는 데 사용됩니다.
- 대기 기간을 통해 Spanner가 데이터 분할을 관리하도록 허용합니다.
확장 방법
자동 확장 처리 도구는 단계식, 선형, 직접식 등 Spanner 인스턴스를 확장하고 축소할 수 있는 3가지 확장 방법을 제공합니다. 각 방법은 다양한 유형의 워크로드를 지원하도록 설계되었습니다. 독립적인 폴링 일정을 만들 때 자동 확장되는 Spanner 인스턴스마다 방법을 한 가지 이상 적용할 수 있습니다.
다음 섹션에는 이러한 확장 방법을 자세히 설명합니다.
단계식
단계식 확장은 피크가 작거나 여러 개인 워크로드에 유용합니다. 단일 자동 확장 이벤트로 모든 작업을 원활하게 처리하도록 용량을 프로비저닝합니다.
다음 차트는 여러 개의 부하 정체 또는 단계가 있는 패턴을 보여줍니다. 각 단계에는 여러 개의 작은 피크가 있습니다. 이 패턴은 단계식 방법에 적합합니다.
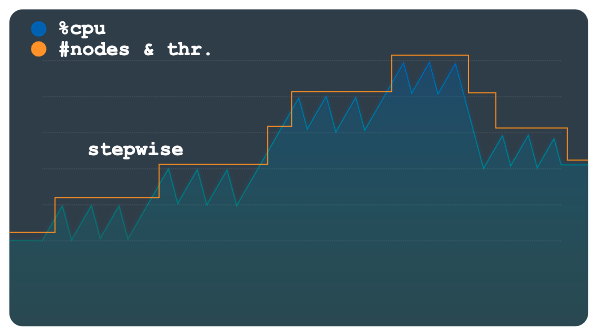
부하 기준점을 초과하는 경우 이 방법에서는 고정되지만 구성 가능한 수를 사용하여 노드나 처리 단위를 프로비저닝하고 삭제합니다. 예를 들어 확장 작업마다 노드 3개가 추가되거나 삭제됩니다. 구성을 변경하여 언제든지 더 큰 용량 증분을 추가하거나 삭제할 수 있습니다.
선형
선형 확장은 더 점진적으로 변경되거나 몇 개의 큰 피크가 있는 부하 패턴에 가장 적합합니다. 이 방법은 사용량을 확장 기준점 미만으로 유지하는 데 필요한 최소 노드 또는 처리 단위 수를 계산합니다. 각 확장 이벤트에서 추가되거나 삭제된 노드 또는 처리 단위 수는 고정 단계 금액으로 제한되지 않습니다.
다음 차트의 샘플 부하 패턴에서는 부하의 갑작스런 증가와 감소를 보여줍니다. 이러한 변동은 이전 차트에서와 같이 식별 가능한 단계로 그룹화되지 않습니다. 선형 확장을 사용하면 이 패턴을 더 쉽게 처리할 수 있습니다.
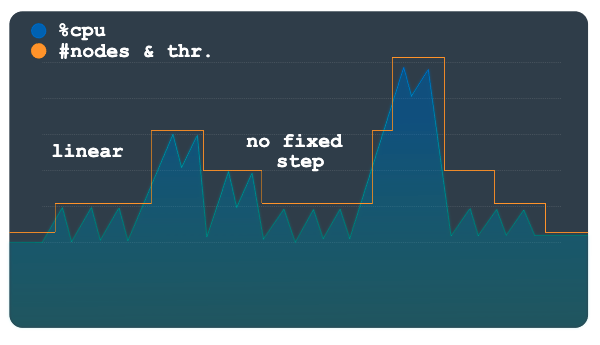
자동 확장 처리 도구는 사용률 기준점에 대한 관찰된 사용량의 비율을 사용하여 현재 총 개수에서 노드나 처리 단위를 추가할 것인지 뺄 것인지 여부를 계산합니다.
새 노드 또는 처리 단위 수를 계산하는 수식은 다음과 같습니다.
newSize = currentSize * currentUtilization / utilizationThreshold
직접식
직접식 확장을 사용하면 용량이 즉각적으로 늘어납니다. 이 방법은 시작 시간이 알려진 일정에서 미리 결정된 더 높은 노드 수가 주기적으로 필요한 일괄 워크로드를 지원하기 위한 것입니다. 이 방법은 인스턴스를 일정에 지정된 최대 노드 또는 처리 단위 수까지 확장하며 선형 또는 단계식 방법에 추가로 사용됩니다.
다음 차트에서는 자동 확장 처리가 직접식 방법을 사용하기 위해 용량을 사전 프로비저닝한 대규모 계획된 부하 증가를 보여줍니다.
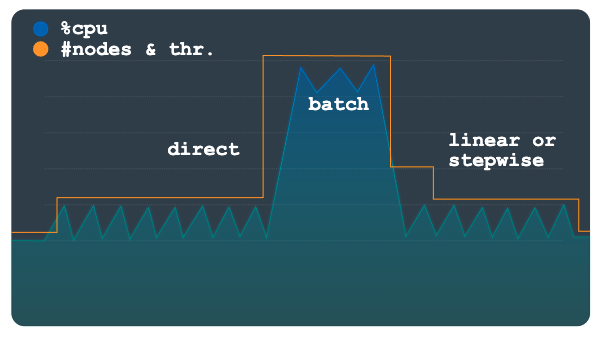
일괄 워크로드가 완료되고 사용량이 정상 수준으로 돌아가면 구성에 따라 선형 또는 단계식 확장이 적용되어 인스턴스가 자동으로 축소됩니다.
구성
자동 확장 처리 도구에는 Spanner 배포 확장을 관리하는 데 사용할 수 있는 다양한 구성 옵션이 있습니다. Cloud Run Functions와 GKE 파라미터는 비슷하지만 다르게 제공됩니다. 자동 확장 처리 도구를 구성하는 방법에 대한 자세한 내용은 Cloud Run Functions 배포 구성 및 GKE 배포 구성을 참조하세요.
고급 구성
자동 확장 처리 도구에는 Spanner 인스턴스 관리 시기와 방법을 더욱 세밀하게 관리할 수 있게 해주는 고급 구성 옵션이 있습니다. 다음 섹션에서는 이러한 제어 선택을 소개합니다.
커스텀 임곗값
자동 확장 처리 도구는 다음 부하 측정항목에 권장되는 Spanner 기준점을 사용하여 인스턴스에 추가하거나 뺄 노드 또는 처리 단위 수를 결정합니다.
- 우선순위가 높은 CPU
- 24시간 이동 평균 CPU
- 스토리지 사용량
Spanner 측정항목에 대한 알림 만들기의 설명대로 기본 기준점을 사용하는 것이 좋습니다. 하지만 자동 확장 처리 도구에서 사용하는 임곗값을 수정하려는 경우도 있습니다. 예를 들어 낮은 기준점을 사용하여 자동 확장 처리 도구가 높은 기준점일 때보다 더 빠르게 반응하도록 할 수 있습니다. 이러한 수정은 더 높은 기준점에서 알림이 트리거되는 것을 방지하는 데 도움이 됩니다.
커스텀 측정항목
자동 확장 처리 도구의 기본 측정항목은 대부분의 성능과 확장 시나리오를 처리하지만 수평 축소 및 확장 시기를 결정하는 데 사용되는 자체 측정항목을 지정해야 하는 경우도 있습니다. 이러한 시나리오의 경우 metrics 속성을 사용하여 구성에서 커스텀 측정항목을 정의합니다.
마진
마진은 기준점 주변의 상한 및 하한을 정의합니다. 자동 확장 처리 도구는 측정항목 값이 상한값을 초과하거나 하한값 미만인 경우에만 자동 확장 이벤트를 트리거합니다.
이 파라미터의 목적은 기준점 주변의 작은 워크로드 변동으로 인해 자동 확장 이벤트가 트리거되지 않도록 하여 자동 확장 처리 작업 변동량을 줄이는 것입니다. 기준점과 마진은 측정항목 값이 원하는 바에 따라 다음 범위를 함께 정의합니다.
[threshold - margin, threshold + margin]
마진이 작을수록 범위가 좁아져 자동 확장 이벤트가 트리거될 가능성이 높아집니다.
측정항목의 마진 매개변수를 지정하는 것은 선택사항이며, 기본값은 매개변수 앞뒤에 모두 5% 포인트입니다.
데이터 분할
Spanner는 분할이라는 데이터 범위를 노드 또는 처리 단위라고 부르는 노드의 하위 영역에 할당합니다. 노드나 처리 단위는 할당된 분할의 데이터를 독립적으로 관리하고 제공합니다. 데이터 분할은 데이터 볼륨과 액세스 패턴을 포함한 여러 가지 요소를 기반으로 생성됩니다. 자세한 내용은 Spanner - 스키마 및 데이터 모델을 참조하세요.
데이터는 분할되어 구성되며 Spanner는 분할을 자동으로 관리합니다. 따라서 자동 확장 처리 도구에서 노드 또는 처리 단위를 추가하거나 삭제할 때 새 용량이 추가되거나 인스턴스에서 삭제되므로 Spanner 백엔드가 분할을 다시 할당하고 재구성할 수 있도록 충분한 시간을 허용해야 합니다.
자동 확장 처리 도구는 확장 및 축소 이벤트 모두에서 대기 기간을 사용하여 인스턴스에서 노드 또는 처리 단위를 추가하거나 삭제할 수 있는 속도를 제어합니다. 이 방법을 사용하면 인스턴스에서 컴퓨팅 메모 또는 처리 단위와 데이터 분할 사이의 관계를 재구성하는 데 필요한 시간을 확보할 수 있습니다. 기본적으로 확장 및 축소 대기 기간은 다음과 같은 최솟값으로 설정됩니다.
- 수직 확장 값: 5분
- 축소 값: 30분
확장 권장사항과 대기 기간에 대한 자세한 내용은 Spanner 인스턴스 확장을 참조하세요.
가격 책정
자동 확장 처리 도구의 리소스 소비량은 컴퓨팅, 메모리, 스토리지 측면에서 미미합니다. 자동 확장 처리 구성에 따라 Cloud Run Functions에 배포된 경우 자동 확장 처리 리소스 사용량은 일반적으로 종속 서비스(Cloud Run Functions, Cloud Scheduler, Pub/Sub, Firestore)의 무료 등급에 해당됩니다.
가격 계산기를 사용하면 예상 사용량을 기준으로 환경의 예상 비용을 산출할 수 있습니다.
다음 단계
- Cloud Run Functions에 자동 확장 처리 도구를 배포하는 방법 알아보기
- GKE에 자동 확장 처리 도구를 배포하는 방법 알아보기
- Spanner 권장 기준에 대해 자세히 알아보기
- Spanner CPU 사용률 측정항목 및 지연 시간 측정항목 자세히 알아보기
- 핫스팟을 방지하고 Spanner에 데이터를 로드하기 위한 Spanner 스키마 설계 권장사항 알아보기
- Google Cloud에 대한 참조 아키텍처, 다이어그램, 권장사항 살펴보기 Cloud 아키텍처 센터 살펴보기