Cette page présente l'outil Autoscaler pour Spanner, un outil Open Source que vous pouvez utiliser comme élément associé à Spanner. Cet outil vous permet d'augmenter ou de réduire automatiquement la capacité de calcul d'une ou de plusieurs instances Spanner en fonction de la capacité utilisée.
Pour en savoir plus sur le scaling dans Spanner, consultez Autoscaling Spanner. Pour en savoir plus sur le déploiement de l'outil Autoscaler, consultez les ressources suivantes :
- Déployez l'outil Autoscaler pour Spanner dans les fonctions Cloud Run.
- Déployez l'outil Autoscaler pour Spanner sur Google Kubernetes Engine (GKE).
Cette page présente les fonctionnalités, l'architecture et la configuration générale d'Autoscaler. Ces thèmes vous guident tout au long du déploiement d'Autoscaler sur l'un des environnements d'exécution compatibles dans chacune des différentes topologies.
Autoscaler
L'outil Autoscaler est utile pour gérer l'utilisation et les performances de vos déploiements Spanner. Pour vous aider à équilibrer les coûts en fonction des besoins en termes de performances, l'outil Autoscaler surveille vos instances, et ajoute ou supprime automatiquement des nœuds ou des unités de traitement afin de garantir qu'ils restent dans les paramètres suivants :
- Les valeurs maximales recommandées pour l'utilisation du processeur.
- La limite recommandée pour le stockage par nœud.
Plus ou moins une marge configurable.
L'autoscaling des déploiements Spanner permet à votre infrastructure de s'adapter et d'effectuer des scalings automatiquement pour répondre aux exigences de charge, avec peu ou pas d'intervention. L'autoscaling redimensionne également l'infrastructure provisionnée, ce qui peut vous aider à minimiser les frais encourus.
Architecture
L'autoscaler comporte deux composants principaux : le Poller et le Scaler. Bien que vous puissiez déployer l'autoscaler avec différentes configurations sur plusieurs runtimes dans plusieurs topologies avec différentes configurations, la fonctionnalité de ces composants principaux est la même.
Cette section décrit plus en détail ces deux composants et leurs objectifs.
Sondeur
L'outil d'interrogation collecte et traite les métriques de séries temporelles pour une ou plusieurs instances Spanner. Elle prétraite les données des métriques pour chaque instance Spanner de sorte que seuls les points de données les plus pertinents soient évalués et envoyés au Scaler. Le prétraitement effectué par le collecteur simplifie également le processus d'évaluation des seuils pour les instances Spanner régionales, birégionales et multirégionales.
Scaler
Le scaler évalue les points de données reçus du composant Poller et détermine si vous devez ajuster le nombre de nœuds ou d'unités de traitement et, le cas échéant, dans quelle mesure. Elle compare les valeurs des métriques au seuil, plus ou moins une marge autorisée, et ajuste le nombre de nœuds ou d'unités de traitement en fonction de la méthode de scaling configurée. Pour en savoir plus, consultez Méthodes de scaling.
Tout au long du flux, l'outil Autoscaler écrit un résumé de ses recommandations et actions dans Cloud Logging à des fins de suivi et d'audit.
Fonctionnalités d'Autoscaler
Cette section décrit les principales fonctionnalités de l'outil Autoscaler.
Gérer plusieurs instances
L'outil Autoscaler est capable de gérer plusieurs instances Spanner sur plusieurs projets. Les instances multirégionales, birégionales et régionales ont toutes des seuils d'utilisation différents qui sont utilisés lors du scaling. Par exemple, le scaling des déploiements multirégionaux et birégionaux est de 45 % de l'utilisation du processeur par les tâches à priorité élevée, tandis que le scaling des déploiements régionaux est de 65 % de l'utilisation du processeur par les tâches à priorité élevée, plus ou moins une marge autorisée. Pour en savoir plus sur les différents seuils de scaling, consultez Alertes en cas d'utilisation intensive du processeur.
Paramètres de configuration indépendants
Chaque instance Spanner avec autoscaling peut avoir une ou plusieurs planifications d'interrogation. Chaque planification d'interrogation possède son propre ensemble de paramètres de configuration.
Ces paramètres déterminent les facteurs suivants :
- Nombre minimal et maximal de nœuds ou d'unités de traitement qui permet de contrôler les tailles maximale et minimale de votre instance, et ainsi contrôler les frais encourus.
- La méthode de scaling utilisée pour ajuster votre instance Spanner en fonction de votre charge de travail.
- Les périodes de transition pour permettre à Spanner de gérer les divisions des données.
Méthodes de scaling
L'outil Autoscaler fournit trois méthodes de scaling différentes pour les instances Spanner en termes de scaling à la hausse et à la baisse : par étapes, linéaire et directe. Chaque méthode est conçue pour accepter différents types de charges de travail. Vous pouvez appliquer une ou plusieurs méthodes à chaque instance Spanner qui subit un autoscaling lorsque vous créez des planifications d'interrogation indépendantes.
Les sections suivantes contiennent plus d'informations sur ces méthodes de mise à l'échelle.
Par étapes
Le scaling par étapes est utile pour les charges de travail qui présentent des pics petits ou nombreux. Il provisionne la capacité pour les éliminer à l'aide d'un seul événement d'autoscaling.
Le graphique suivant présente un modèle de charge avec des plateaux ou étapes de charge multiples, où chaque étape comporte plusieurs petits pics. Ce modèle est particulièrement adapté à la méthode par étapes.
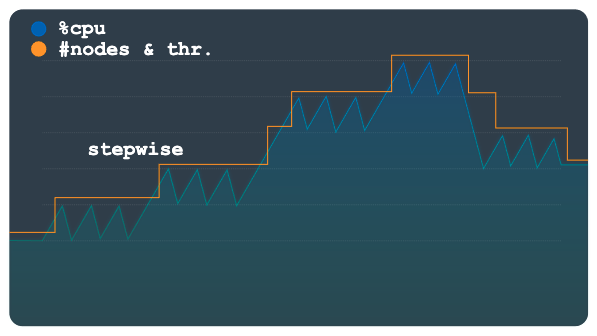
Lorsque le seuil de charge est dépassé, cette méthode provisionne et supprime des nœuds ou des unités de traitement en utilisant un nombre fixe mais configurable. Par exemple, trois nœuds sont ajoutés ou supprimés pour chaque action de scaling. En modifiant la configuration, vous pouvez autoriser l'ajout ou la suppression d'incréments de capacité supérieurs à tout moment.
Linéaire
Le scaling linéaire est préférable avec des modèles de charge qui changent plus progressivement ou présentent quelques pics importants. La méthode calcule le nombre minimal de nœuds ou d'unités de traitement requis pour maintenir l'utilisation en dessous du seuil de scaling. Le nombre de nœuds ou d'unités de traitement à ajouter ou supprimer pour chaque événement de scaling n'est pas soumis à un incrément fixe.
L'exemple de modèle de charge dans le graphique suivant montre des augmentations et des diminutions soudaines importantes de la charge. Ces fluctuations ne sont pas regroupées dans des étapes perceptibles, comme elles l'étaient dans le graphique précédent. Ce modèle est peut-être plus facile à gérer à l'aide du scaling linéaire.
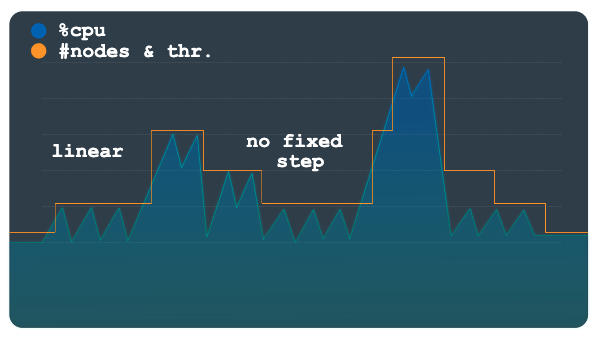
L'outil Autoscaler utilise le ratio de l'utilisation observée par rapport au seuil d'utilisation pour déterminer s'il faut ajouter ou soustraire des nœuds ou des unités de traitement au nombre total actuel.
La formule permettant de calculer le nouveau nombre de nœuds ou d'unités de traitement se présente comme suit :
newSize = currentSize * currentUtilization / utilizationThreshold
Direct
Le scaling direct offre une augmentation immédiate de la capacité. Cette méthode est destinée à gérer les charges de travail par lots dans lesquelles un nombre de nœuds prédéterminé plus élevé est périodiquement exigé dans une planification avec une heure de début connue. Cette méthode procède au scaling à la hausse de l'instance jusqu'à atteindre le nombre maximal de nœuds ou d'unités de traitement spécifié dans la planification. Elle est prévue pour être utilisée en plus d'une méthode linéaire ou par étapes.
Le graphique suivant décrit l'augmentation planifiée importante de la charge, pour laquelle Autoscaler a préprovisionné la capacité à l'aide de la méthode directe.
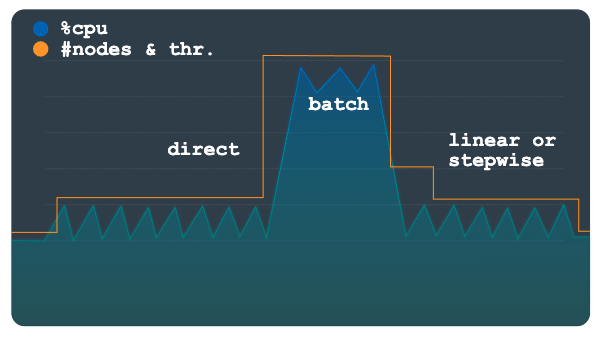
Une fois la charge de travail par lot terminée et l'utilisation repassée à un niveau normal, selon votre configuration, le scaling linéaire ou par étapes est appliqué pour effectuer un scaling à la baisse de l'instance automatiquement.
Configuration
L'outil Autoscaler dispose de différentes options de configuration que vous pouvez utiliser pour gérer le scaling de vos déploiements Spanner. Bien que les paramètres Cloud Run Functions et GKE soient similaires, ils sont fournis différemment. Pour en savoir plus sur la configuration de l'outil Autoscaler, consultez Configurer un déploiement de fonctions Cloud Run et Configurer un déploiement GKE.
Configuration avancée
L'outil Autoscaler dispose d'options de configuration avancées vous permettant de contrôler plus précisément quand et comment vos instances Spanner sont gérées. Les sections suivantes présentent une sélection de ces commandes.
Seuils personnalisés
L'outil Autoscaler détermine le nombre de nœuds ou d'unités de traitement à ajouter ou à soustraire d'une instance à l'aide des seuils Spanner recommandés pour les métriques de charge suivantes :
- Processeur à priorité élevée
- Utilisation du processeur, moyenne glissante de 24 heures
- Utilisation du stockage
Nous vous recommandons d'utiliser les seuils par défaut, comme décrit dans Créer des alertes pour les métriques Spanner. Toutefois, dans certains cas, vous souhaiterez peut-être modifier les seuils utilisés par l'outil Autoscaler. Par exemple, vous pouvez définir des seuils inférieurs pour que l'outil Autoscaler réagisse plus rapidement que pour des seuils plus élevés. Cette modification permet d'éviter le déclenchement d'alertes à des seuils plus élevés.
Métriques personnalisées
Bien que les métriques par défaut de l'outil Autoscaler répondent à la plupart des scénarios de scaling et de performances, il peut arriver que vous deviez spécifier vos propres métriques pour déterminer quand effectuer un scaling à la hausse et à la baisse. Pour de tels scénarios, vous définissez des métriques personnalisées dans la configuration à l'aide de la propriété metrics.
Marges
Une marge définit une limite supérieure et inférieure au seuil. L'outil Autoscaler ne déclenche un événement d'autoscaling que si la valeur de la métrique est supérieure à la limite supérieure ou inférieure à la limite inférieure.
L'objectif de ce paramètre est d'éviter les déclenchements d'événements d'autoscaling pour les fluctuations de charge de travail mineures autour du seuil, réduisant ainsi la fluctuation des actions d'Autoscaler. Le seuil et la marge définissent la plage suivante, en fonction de la valeur de métrique souhaitée :
[threshold - margin, threshold + margin]
Plus la marge est faible, plus la plage est réduite, ce qui augmente la probabilité qu'un événement d'autoscaling soit déclenché.
La spécification d'un paramètre de marge pour une métrique est facultative et sa valeur par défaut est de cinq points de pourcentage, avant et sous le paramètre.
Divisions des données
Spanner attribue des plages de données appelées divisions aux nœuds ou aux subdivisions d'un nœud appelé unités de traitement. Le nœud ou les unités de traitement gèrent et diffusent indépendamment les données selon les divisions définies. Les divisions des données sont créées en fonction de plusieurs facteurs, y compris le volume de données et les modèles d'accès. Pour en savoir plus, consultez Spanner : schéma et modèle de données.
Les données sont organisées en divisions, et Spanner gère celles-ci automatiquement. Ainsi, lorsque l'outil Autoscaler ajoute ou supprime des nœuds ou des unités de traitement, il doit laisser suffisamment de temps au backend Spanner pour réattribuer et réorganiser les divisions en fonction de la capacité ajoutée ou supprimée des instances.
L'outil Autoscaler utilise des périodes de transition pour les événements de scaling à la hausse et à la baisse afin de contrôler la vitesse à laquelle il peut ajouter ou supprimer des nœuds ou des unités de traitement dans une instance. Avec cette méthode, l'instance dispose du temps nécessaire pour réorganiser les relations entre les notes de calcul ou unités de traitement et les divisions de données. Par défaut, les périodes de transition d'autoscaling à la hausse et à la baisse sont définies sur les valeurs minimales suivantes :
- Valeur de scaling à la hausse : 5 minutes
- Valeur de scaling à la baisse : 30 minutes
Pour en savoir plus sur les recommandations de scaling et les périodes de transition, consultez la page Scaling des instances Spanner.
Tarifs
La consommation de ressources de l'outil Autoscaler est minime en termes de calcul, de mémoire et de stockage. En fonction de la configuration d'Autoscaler, lorsque l'autoscaler est déployé sur les fonctions Cloud Run, l'utilisation des ressources est généralement comprise dans la version gratuite de ses services dépendants (fonctions Cloud Run, Cloud Scheduler, Pub/Sub et Firestore).
Utilisez le simulateur de coût pour générer une estimation des coûts de vos environnements en fonction de votre utilisation prévue.
Étapes suivantes
- Découvrez comment déployer l'outil Autoscaler sur les fonctions Cloud Run.
- Découvrez comment déployer l'outil Autoscaler sur GKE.
- En savoir plus sur les seuils recommandés de Spanner
- En savoir plus sur les métriques d'utilisation du processeur et les métriques de latence de Spanner
- Découvrez les bonnes pratiques pour la conception de schéma Spanner afin d'éviter les hotspots et de charger des données dans Spanner.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.