Auf dieser Seite wird das Autoscaling-Tool für Spanner (Autoscaler) vorgestellt, ein Open-Source-Tool, das Sie als Begleittool für Spanner verwenden können. Mit diesem Tool können Sie die Rechenkapazität in einer oder mehreren Spanner-Instanzen automatisch erhöhen oder reduzieren, je nachdem, wie viel Kapazität verwendet wird.
Weitere Informationen zum Skalieren in Spanner finden Sie unter Autoscaling von Spanner. Informationen zum Bereitstellen des Autoscaling-Tools finden Sie unter:
- Autoscaling-Tool für Spanner in Cloud Run-Funktionen bereitstellen.
- Autoscaler-Tool für Spanner in Google Kubernetes Engine (GKE) bereitstellen
Auf dieser Seite werden die Funktionen, die Architektur und die allgemeine Konfiguration des Autoscalings vorgestellt. In diesen Themen wird die Bereitstellung des Autoscalers für eine der unterstützten Laufzeiten in den verschiedenen Topologien beschrieben.
Autoscaling
Das Autoscaling-Tool ist nützlich, um die Auslastung und Leistung Ihrer Spanner-Bereitstellungen zu verwalten. Damit Sie die Kostenkontrolle im Hinblick auf die Leistungsanforderungen ausgleichen können, überwacht das Autoscaling-Tool Ihre Instanzen und fügt automatisch Knoten oder Verarbeitungseinheiten hinzu oder entfernt diese, um sicherzustellen, dass sie innerhalb der folgenden Parameter bleiben:
Plus oder minus einer konfigurierbaren Marge.
Mit Autoscaling-Cloud Spanner-Bereitstellungen können Sie Ihre Infrastruktur automatisch und flexibel an die Anforderungen von Arbeitslasten anpassen. Durch das Autoscaling wird auch die Größe der bereitgestellten Infrastruktur angepasst. So können Sie die Kosten senken.
Architektur
Der Autoscaler hat zwei Hauptkomponenten: den Poller und den Scaler. Sie können das Autoscaling zwar mit unterschiedlichen Konfigurationen für mehrere Laufzeiten in mehreren Topologien mit unterschiedlichen Konfigurationen bereitstellen, die Funktionalität dieser Kernkomponenten ist jedoch dieselbe.
In diesem Abschnitt werden diese beiden Komponenten und ihre Zwecke ausführlicher beschrieben.
Poller
Der Poller erfasst und verarbeitet die Zeitachsenmesswerte für eine oder mehrere Spanner-Instanzen. Der Poller verarbeitet die Messwertdaten für jede Spanner-Instanz vor, damit nur die relevantesten Datenpunkte ausgewertet und an den Scaler gesendet werden. Die Vorverarbeitung durch den Poller vereinfacht außerdem die Bewertung von Grenzwerten für regionale, Dual-Region- und multiregionale Spanner-Instanzen.
Scaler
Der Scaler wertet die Datenpunkte aus, die von der Poller-Komponente empfangen werden. Dabei wird ermittelt, ob die Anzahl der Knoten oder Verarbeitungseinheiten angepasst werden muss und, wenn ja, in welchem Umfang. Die Cloud Functions-Funktion vergleicht die Messwerte mit dem Grenzwert, plus oder minus einer zulässigen Marge und passt die Anzahl der Knoten oder Verarbeitungseinheiten basierend auf der konfigurierten Skalierungsmethode an. Weitere Informationen finden Sie unter Skalierungsmethoden.
Während des gesamten Ablaufs schreibt das Autoscaling-Tool eine Zusammenfassung der Empfehlungen und Aktionen in Cloud Logging für das Tracking und die Prüfung.
Autoscaling-Features
In diesem Abschnitt werden die wichtigsten Funktionen des Autoscaler-Tools beschrieben.
Mehrere Instanzen verwalten
Das Autoscaling-Tool kann mehrere Spanner-Instanzen projektübergreifend verwalten. Multiregionale, Dual-Region- und regionale Instanzen haben unterschiedliche Nutzungsgrenzwerte, die für die Skalierung verwendet werden. Beispielsweise werden multiregionale und biregionale Bereitstellungen mit 45% CPU-Auslastung mit hoher Priorität skaliert, während regionale Bereitstellungen auf 65% CPU-Auslastung mit hoher Priorität skaliert werden, jeweils plus oder minus einer zulässigen Marge. Weitere Informationen zu den verschiedenen Skalierungsgrenzwerten finden Sie unter Benachrichtigungen für eine hohe CPU-Auslastung.
Unabhängige Konfigurationsparameter
Jede automatisch skalierte Spanner-Instanz kann einen oder mehrere Abfragezeitpläne haben. Jeder Abfragezeitplan hat eigene Konfigurationsparameter.
Diese Parameter bestimmen die folgenden Faktoren:
- Die minimale und maximale Anzahl von Knoten oder Verarbeitungseinheiten, die steuern, wie klein oder groß Ihre Instanz sein kann, sodass Sie die anfallenden Gebühren kontrollieren können.
- Die Skalierungsmethode, mit der die spezielle Spanner-Instanz Ihrer Arbeitslast angepasst wird.
- Durch die Cooldown-Zeit kann Spanner Datenaufteilungen verwalten.
Skalierungsmethoden
Das Autoscaling-Tool bietet drei verschiedene Skalierungsmethoden zum Hoch- und Herunterskalieren von Spanner-Instanzen: schrittweise, linear und direkt. Jede Methode unterstützt unterschiedliche Arten von Arbeitslasten. Sie können eine oder mehrere Methoden auf jede Spanner-Instanz anwenden, die automatisch skaliert wird, wenn Sie unabhängige Abfragezeitpläne erstellen.
In den folgenden Abschnitten finden Sie weitere Informationen zu diesen Skalierungsmethoden.
Schrittweise
Die schrittweise Skalierung eignet sich für Arbeitslasten mit kleinen oder mehreren Spitzen. Dadurch werden Kapazitäten bereitgestellt, um sie mit einem einzigen Autoscaling-Ereignis auszugleichen.
Das folgende Diagramm zeigt ein Lastmuster mit mehreren Lastplateaus oder -schritten, bei denen jeder Schritt mehrere kleine Spitzen hat. Dieses Muster eignet sich gut für die schrittweise Methode.
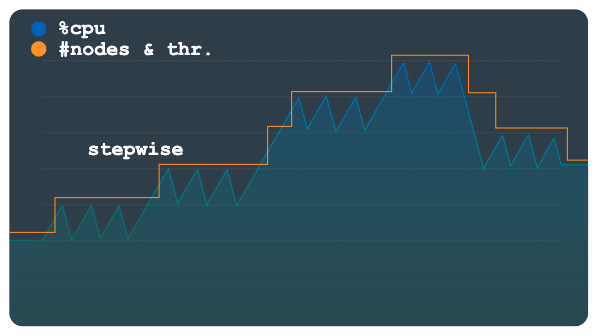
Wenn die Belastungsschwelle überschritten wird, stellt diese Methode Knoten oder Verarbeitungseinheiten bereit und entfernt diese mithilfe einer festen, aber konfigurierbaren Zahl. Beispielsweise werden für jede Skalierungsaktion drei Knoten hinzugefügt oder entfernt. Wenn Sie die Konfiguration ändern, können Sie jederzeit größere Kapazitätsinkremente hinzufügen oder entfernen.
Linear
Die lineare Skalierung eignet sich am besten für Lastmuster, die sich allmählich ändern oder nur wenige große Spitzen haben. Die Methode berechnet die Mindestanzahl an Knoten oder Verarbeitungseinheiten, die erforderlich sind, damit die Auslastung unter dem Skalierungsschwellenwert liegt. Die Anzahl der Knoten oder Verarbeitungseinheiten, die bei den einzelnen Skalierungsereignissen hinzugefügt oder entfernt werden, ist nicht auf einen festen Schritt beschränkt.
Das Beispiellastmuster im folgenden Diagramm zeigt große, plötzliche Zu- und Abnahmen der Last. Diese Schwankungen werden nicht wie im vorherigen Diagramm in diskreten Schritten gruppiert. Dieses Muster kann mit linearer Skalierung besser verarbeitet werden.
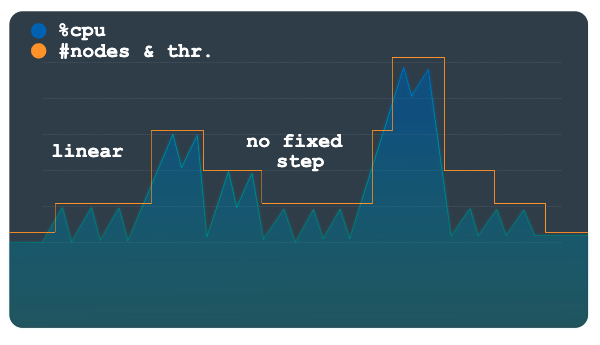
Das Autoscaling-Tool verwendet das Verhältnis der beobachteten Auslastung zum Auslastungsschwellenwert, um zu berechnen, ob Knoten oder Verarbeitungseinheiten von der aktuellen Gesamtzahl hinzugefügt oder subtrahiert werden sollen.
Die neue Formel zur Berechnung der neuen Anzahl von Knoten oder Verarbeitungseinheiten lautet:
newSize = currentSize * currentUtilization / utilizationThreshold
Direkt
Die direkte Skalierung bietet eine sofortige Erhöhung der Kapazität. Diese Methode ist für die Unterstützung von Batcharbeitslasten gedacht, bei denen gemäß einem Zeitplan mit einer bekannten Startzeit regelmäßig eine höhere Knotenzahl erforderlich ist. Bei dieser Methode wird die Instanz bis zur maximal zulässigen Anzahl von Knoten oder Verarbeitungseinheiten im Zeitplan skaliert. Die Methode soll zusätzlich zur linearen oder schrittweisen Methode verwendet werden.
Das folgende Diagramm zeigt die große geplante Erhöhung der Last, wobei dem Autoscaling vorab Kapazität für die direkte Methode bereitgestellt wurde.
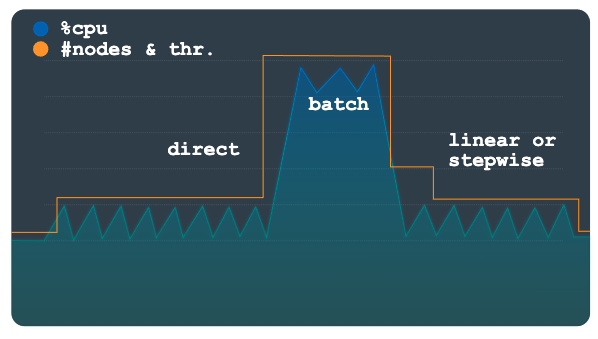
Sobald die Batcharbeitslast abgeschlossen ist und die Auslastung wieder auf dem normalen Niveau ist, wird je nach Konfiguration die lineare oder schrittweise Skalierung angewendet, um die Instanz automatisch herunterzuskalieren.
Konfiguration
Das Autoscaling-Tool bietet verschiedene Konfigurationsoptionen, mit denen Sie die Skalierung Ihrer Spanner-Bereitstellungen verwalten können. Die Parameter für Cloud Run Functions und GKE sind zwar ähnlich, werden aber unterschiedlich bereitgestellt. Weitere Informationen zum Konfigurieren des Autoscaler-Tools finden Sie unter Bereitstellung von Cloud Run Functions konfigurieren und GKE-Bereitstellung konfigurieren.
Erweiterte Konfiguration
Das Autoscaling-Tool bietet erweiterte Konfigurationsoptionen, mit denen Sie präziser steuern können, wann und wie Ihre Spanner-Instanzen verwaltet werden. In den folgenden Abschnitten wird eine Auswahl dieser Steuerelemente vorgestellt.
Benutzerdefinierte Grenzwerte
Das Autoscaling-Tool bestimmt anhand der empfohlenen Spanner-Schwellenwerte für die folgenden Lademesswerte die Anzahl der Knoten oder Verarbeitungseinheiten, die einer Instanz hinzugefügt oder subtrahiert werden sollen:
- CPU mit hoher Priorität
- Gleitender 24-Stunden-Durchschnitt der CPU
- Speicherauslastung
Es wird empfohlen, die unter Benachrichtigungen für Spanner-Messwerte erstellen beschriebenen Standardgrenzwerte zu verwenden. In einigen Fällen können Sie jedoch die vom Autoscaling-Tool verwendeten Grenzwerte ändern. Beispielsweise können Sie niedrigere Grenzwerte verwenden, damit das Autoscaling-Tool schneller reagiert als bei höheren Grenzwerten. Durch diese Änderung wird verhindert, dass Benachrichtigungen bei höheren Grenzwerten ausgelöst werden.
Benutzerdefinierte Messwerte
Während die Standardmesswerte im Autoscaling-Tool an die meisten Leistungs- und Skalierungsszenarien angepasst werden, müssen Sie in einigen Fällen manchmal eigene Messwerte festlegen, um zu bestimmen, wann eine Skalierung erfolgt. In diesen Szenarien definieren Sie benutzerdefinierte Messwerte in der Konfiguration mithilfe des Attributs metrics.
Ränder
Eine Marge definiert eine obere und eine untere Grenze um den Grenzwert. Das Autoscaling-Tool löst nur dann ein Autoscaling-Ereignis aus, wenn der Messwert über oder unter dem unteren Grenzwert liegt.
Das Ziel dieses Parameters besteht darin, Autoscaling-Ereignisse zu vermeiden, die bei kleinen Arbeitslastschwankungen um den Grenzwert ausgelöst werden. So werden die Schwankungen der Autoscaling-Aktionen reduziert. Der Grenzwert und die Marge zusammen definieren den Bereich so, wie der Messwert sein soll:
[threshold - margin, threshold + margin]
Je kleiner die Marge, desto enger ist der Bereich. Dies führt zu einer höheren Wahrscheinlichkeit, dass ein Autoscaling-Ereignis ausgelöst wird.
Die Angabe eines Margenparameters für einen Messwert ist optional und standardmäßig auf fünf Prozentpunkte sowohl ober- als auch unterhalb des Parameters eingestellt.
Datenaufteilungen
Cloud Spanner weist Knoten oder Unterteilungen eines Knotens, die als Verarbeitungseinheiten bezeichnet werden, Datenbereiche zu, die als Splits bezeichnet werden. Die Knoten oder Verarbeitungseinheiten verwalten und liefern Daten unabhängig in den aufgeteilten Splits. Datenaufteilungen werden auf der Grundlage verschiedener Faktoren erstellt, wie z. B. Datenvolumen und Zugriffsmuster. Weitere Informationen finden Sie unter Spanner – Schema und Datenmodell.
Daten werden in Aufteilungen organisiert und Spanner verwaltet die Aufteilungen automatisch. Wenn das Autoscaling-Tool also Knoten oder Verarbeitungseinheiten hinzufügt oder entfernt, muss das Spanner-Backend genügend Zeit haben, die Aufteilungen neu zuzuweisen und neu zu ordnen, wenn Kapazität den Instanzen hinzugefügt oder von ihnen entfernt wird.
Das Autoscaling-Tool verwendet Cooldown-Zeiten für das Hoch- und Herunterskalieren, um zu steuern, wie schnell Knoten oder Verarbeitungseinheiten zu einer Instanz hinzugefügt oder daraus entfernt werden können. Diese Methode ermöglicht der Instanz die erforderliche Zeit, um die Beziehungen zwischen Compute-Hinweisen oder Verarbeitungseinheiten und Datenaufteilungen neu zu organisieren. Standardmäßig werden die Cooldown-Zeiträume für vertikale Skalierung und horizontale Skalierung auf die folgenden Mindestwerte festgelegt:
- Wert für die vertikale Skalierung: 5 Minuten
- Wert für das Herunterskalieren: 30 Minuten
Weitere Informationen zu Skalierungsempfehlungen und Cooldown-Zeiträumen finden Sie unter Spanner-Instanzen skalieren.
Preise
Die Ressourcennutzung des Autoscaling-Tools ist in Bezug auf Rechenleistung, Arbeitsspeicher und Speicher gering. Je nach Konfiguration des Autoscalers liegt die Ressourcennutzung des Autoscalers bei der Bereitstellung in Cloud Run-Funktionen in der Regel im kostenlosen Kontingent der zugehörigen Dienste (Cloud Run-Funktionen, Cloud Scheduler, Pub/Sub und Firestore).
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre Umgebungen auf Grundlage Ihrer voraussichtlichen Nutzung erstellen.
Nächste Schritte
- Informationen zum Bereitstellen des Autoscaler-Tools für Cloud Run Functions
- Autoscaling-Tool in GKE bereitstellen
- Weitere Informationen zu den empfohlenen Schwellenwerten für Spanner
- Weitere Informationen zu CPU-Auslastungsmesswerten und Latenzmesswerten in Spanner
- Best Practices für das Schemadesign von Spanner, um Hotspots zu vermeiden und Daten in Spanner zu laden.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center