In diesem Artikel wird erläutert, wie Sie Ihre Datenbank von Oracle® Online Transaction Processing (OLTP) zu Spanner migrieren.
Die Art und Weise, wie Spanner bestimmte Konzepte verwendet, unterscheidet sich von anderen Verwaltungstools für Unternehmensdatenbanken. Daher müssen Sie Ihre Anwendung möglicherweise anpassen, um die Funktionen optimal nutzen zu können. Eventuell müssen Sie Spanner auch mit anderen Diensten von Google Cloud ergänzen, damit Ihre Anforderungen erfüllt werden.
Migrationseinschränkungen
Beim Migrieren der Anwendung zu Spanner müssen die verschiedenen verfügbaren Funktionen berücksichtigt werden. Die Anwendungsarchitektur muss unter Umständen so umgestaltet werden, dass sie mit den Spanner-Funktionen kompatibel ist und in zusätzliche Google Cloud -Dienste eingebunden werden kann.
Gespeicherte Prozeduren und Trigger
Spanner unterstützt nicht die Ausführung von Nutzercode auf Datenbankebene. Daher muss die Geschäftslogik, die durch gespeicherte Prozeduren und Trigger auf Datenbankebene implementiert wird, im Rahmen der Migration in die Anwendung verschoben werden.
Sequenzen
Wir empfehlen, UUID Version 4 als Standardmethode zum Generieren von Primärschlüsselwerten zu verwenden.
Die Funktion GENERATE_UUID() (GoogleSQL, PostgreSQL) gibt UUID-Werte der Version 4 als STRING-Typ zurück.
Wenn Sie 64-Bit-Ganzzahlwerte generieren müssen, unterstützt Spanner positive bitumgekehrte Sequenzen (GoogleSQL, PostgreSQL), die Werte erzeugen, die gleichmäßig über den positiven 64-Bit-Zahlenbereich verteilt sind. Mit diesen Zahlen können Sie Probleme mit Hotspotting vermeiden.
Weitere Informationen finden Sie unter Strategien für Standardwerte für Primärschlüssel.
Zugriffssteuerung
Mit Identity and Access Management (IAM) können Sie den Nutzer- und Gruppenzugriff auf Spanner-Ressourcen für Projekte, Spanner-Instanzen und Spanner-Datenbanken steuern. Weitere Informationen finden Sie in der IAM-Übersicht.
Prüfen und implementieren Sie IAM-Richtlinien gemäß dem Prinzip der geringsten Berechtigung für alle Nutzer und Dienstkonten, die auf Ihre Datenbank zugreifen. Wenn die Anwendung eingeschränkten Zugriff auf bestimmte Tabellen, Spalten, Ansichten oder Änderungsstreams erfordert, implementieren Sie eine detaillierte Zugriffssteuerung (Fine-Grained Access Control, FGAC). Weitere Informationen finden Sie unter Detaillierte Zugriffssteuerung.
Einschränkungen bei der Datenvalidierung
Spanner kann auf Datenbankebene eine begrenzte Anzahl von Einschränkungen bei der Datenvalidierung unterstützen.
Wenn Sie komplexere datenbezogene Einschränkungen benötigen, implementieren Sie diese auf der Anwendungsebene.
In der folgenden Tabelle werden die in Oracle®-Datenbanken häufig vorkommenden Arten von Einschränkungen und ihre Implementierung mit Spanner erläutert.
| Einschränkung | Implementierung mit Spanner |
|---|---|
| Nicht null | Spalteneinschränkung NOT NULL |
| Unique | Sekundärer Index mit UNIQUE-Einschränkung |
| Fremdschlüssel (für normale Tabellen) | Weitere Informationen finden Sie unter Fremdschlüsselbeziehungen erstellen und verwalten. |
Fremdschlüsselaktionen ON DELETE/ON UPDATE |
Nur für verschränkte Tabellen möglich, ansonsten auf Anwendungsebene implementiert |
Wertprüfung und Validierung über CHECK-Einschränkungen oder Trigger |
Auf Anwendungsebene implementiert |
Unterstützte Datentypen
Oracle®-Datenbanken und Spanner unterstützen unterschiedliche Datentypen. In der folgenden Tabelle sind die Oracle-Datentypen und ihre Entsprechungen in Spanner aufgeführt. Detaillierte Definitionen für jeden Spanner-Datentyp finden Sie unter Datentypen.
Möglicherweise müssen Sie, wie in der Spalte "Hinweise" beschrieben, weitere Transformationen an Ihren Daten vornehmen, um die Oracle-Daten auf die Spanner-Datenbank abzustimmen.
Beispiel: Sie können ein großes BLOB als Objekt in einem Cloud Storage-Bucket statt in der Datenbank speichern und den URI-Verweis auf das Cloud Storage-Objekt anschließend in der Datenbank als STRING speichern.
| Oracle-Datentyp | Entsprechung für Spanner | Hinweise |
|---|---|---|
Zeichentypen (CHAR, VARCHAR, NCHAR, NVARCHAR) |
STRING
|
Hinweis: Spanner verwendet durchgehend Unicode-Strings. Oracle unterstützt (abhängig vom Typ) eine maximale Länge von 32.000 Byte oder Zeichen. Spanner unterstützt hingegen bis zu 2.621.440 Zeichen. |
BLOB, LONG RAW, BFILE |
BYTES oder STRING mit URI zum Objekt |
Kleine Objekte (kleiner als 10 MiB) können als BYTES gespeichert werden.Zum Speichern größerer Objekte werden alternative Google Cloud Lösungen wie Cloud Storage empfohlen. |
CLOB, NCLOB, LONG
|
STRING (entweder mit Daten oder URI zum externen Objekt)
|
Kleine Objekte (weniger als 2.621.440 Zeichen) können als STRING gespeichert werden. Zum Speichern größerer Objekte werden alternative Google Cloud Lösungen wie Cloud Storage empfohlen.
|
NUMBER, NUMERIC, DECIMAL
|
STRING, FLOAT64, INT64
|
Der Oracle-Datentyp NUMBER entspricht dem GoogleSQL-Datentyp NUMERIC. Beide unterstützen eine Genauigkeit von 38 Ziffern und eine Skalierung von 9 Ziffern: (P,S) = (38,9). Der PostgreSQL-Datentyp NUMERIC speichert numerische Daten mit beliebiger Genauigkeit.
Der GoogleSQL-Datentyp FLOAT64 unterstützt eine Genauigkeit von bis zu 16 Stellen. |
INT, INTEGER, SMALLINT
|
INT64
|
|
BINARY_FLOAT, BINARY_DOUBLE |
FLOAT64
|
|
DATE
|
DATE
|
Die standardmäßige STRING-Darstellung des Spanner-Typs DATE ist yyyy-mm-dd und somit nicht mit dem Oracle-Typ identisch. Daher ist bei automatischen Konvertierungen von Datumsangaben in und aus STRING-Darstellungen Vorsicht geboten. SQL-Funktionen werden bereitgestellt, um Datumsangaben in einen formatierten String zu konvertieren.
|
DATETIME
|
TIMESTAMP
|
Spanner speichert die Uhrzeit unabhängig von der Zeitzone. Wenn Sie eine Zeitzone speichern möchten, müssen Sie eine separate STRING-Spalte verwenden.
SQL-Funktionen werden bereitgestellt, um Zeitstempel in formatierte Strings mit Zeitzone zu konvertieren.
|
XML
|
STRING (entweder mit Daten oder URI zum externen Objekt) |
Kleine XML-Objekte (weniger als 2.621.440 Zeichen) können als STRING gespeichert werden. Zum Speichern größerer Objekte werden alternative Google Cloud -Lösungen wie Cloud Storage empfohlen. |
URI, DBURI, XDBURI, HTTPURI |
STRING
|
|
ROWID
|
PRIMARY KEY
|
Spanner verwendet den Primärschlüssel der Tabelle, um Zeilen intern zu sortieren und zu referenzieren. In Cloud Spanner entspricht er also faktisch dem Datentyp ROWID. |
SDO_GEOMETRY, SDO_TOPO_GEOMETRY_SDO_GEORASTER |
Geospatiale Datentypen werden von Spanner nicht unterstützt. Sie müssen diese Daten als Standarddatentypen speichern und Such-/Filterlogik auf der Anwendungsebene implementieren. | |
ORDAudio, ORDDicom, ORDDoc,
ORDImage, ORDVideo, ORDImageSignature |
Medien-Datentypen werden von Spanner nicht unterstützt. Erwägen Sie die Verwendung von Cloud Storage zum Speichern von Mediendaten. |
Migrationsprozess
Ein allgemeiner Zeitplan für Ihren Migrationsprozess würde folgendermaßen aussehen:
- Schema und Datenmodell migrieren
- Alle SQL-Abfragen übersetzen
- Anwendung migrieren, um Spanner zusätzlich zu Oracle zu verwenden
- Bulk-Export der Daten aus Oracle und Import in Spanner mithilfe von Dataflow
- Während der Migration beide Datenbanken konsistent halten
- Anwendung von Oracle wegmigrieren
Schritt 1: Datenbank und Schema konvertieren
Konvertieren Sie Ihr vorhandenes Schema in ein Spanner-Schema, um Ihre Daten zu speichern. Das Schema sollte möglichst genau mit dem vorhandenen Oracle-Schema übereinstimmen, um Anpassungen der Anwendung zu vereinfachen. Aufgrund der unterschiedlichen Funktionen sind jedoch einige Änderungen erforderlich.
Der Leitfaden Best Practices beim Schemadesign kann dabei helfen, den Durchsatz zu erhöhen und Hotspots in Ihrer Spanner-Datenbank zu reduzieren.
Primärschlüssel
In Spanner muss jede Tabelle, in der mehr als eine Zeile gespeichert werden soll, einen Primärschlüssel haben, der aus einer oder mehreren Spalten der Tabelle besteht. Der Primärschlüssel Ihrer Tabelle identifiziert jede Zeile in einer Tabelle eindeutig. Die Tabellenzeilen sind nach dem Primärschlüssel sortiert. Da Spanner stark verteilt ist, ist es wichtig, dass Sie eine Methode zur Generierung von Primärschlüsseln auswählen, die gut mit dem Wachstum Ihrer Daten skaliert. Weitere Informationen finden Sie unter Empfohlene Strategien für die Migration von Primärschlüsseln.
Hinweis: Nachdem Sie den Primärschlüssel festgelegt haben, können Sie keine Primärschlüsselspalte hinzufügen oder entfernen und keinen Primärschlüsselwert ändern, ohne die Tabelle zu löschen und neu zu erstellen. Weitere Informationen zum Zuweisen des Primärschlüssels finden Sie unter Schema und Datenmodell – Primärschlüssel.
Tabellen verschränken
Spanner bietet eine Funktion, mit der Sie zwei Tabellen als 1:n-Beziehung mit hierarchischer Struktur definieren können. Die untergeordneten Datenzeilen werden mit der jeweils übergeordneten Zeile im Speicher verschränkt. Hierdurch wird die Tabelle vorab verknüpft und der Datenabruf erfolgt effizienter, wenn untergeordnete und übergeordnete Tabellen gemeinsam abgefragt werden.
Der Primärschlüssel der untergeordneten Tabelle muss mit der bzw. den Primärschlüsselspalte(n) der übergeordneten Tabelle beginnen. Aus der Perspektive der untergeordneten Zeile wird der Primärschlüssel der übergeordneten Zeile als Fremdschlüssel bezeichnet. Sie können bis zu 6 Ebenen an hierarchischen Beziehungen definieren.
Sie können für untergeordnete Tabellen "On Delete"-Aktionen definieren, um zu bestimmen, was passiert, wenn die übergeordnete Zeile gelöscht wird: Entweder werden alle untergeordneten Zeilen gelöscht oder die übergeordnete Zeile kann nicht gelöscht werden, solange untergeordnete Zeilen vorhanden sind.
Hier sehen Sie anhand eines Beispiels, wie eine Album-Tabelle erstellt wird, die in der zuvor definierten übergeordneten Tabelle mit den Interpreten verschränkt ist:
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
Sekundäre Indexe erstellen
Sie können auch sekundäre Indexe erstellen, um Daten in der Tabelle außerhalb des Primärschlüssels zu indexieren.
Spanner implementiert sekundäre Indexe auf dieselbe Weise wie Tabellen. Daher haben die Spaltenwerte, die als Indexschlüssel verwendet werden, die gleichen Einschränkungen wie die Primärschlüssel von Tabellen. Dies bedeutet auch, dass Indexe die gleichen Konsistenzgarantien wie Spanner-Tabellen haben.
Werte-Zuordnungen mit sekundären Indexen entsprechen praktisch einer Abfrage mit Tabellenverknüpfung. Sie können die Leistung von Abfragen mithilfe von Indexen verbessern. Speichern Sie dazu Kopien der Spaltenwerte aus der Originaltabelle mithilfe der STORING-Klausel im sekundären Index, was einem abdeckenden Index (Covering Index) entspricht.
Die Abfrageoptimierung von Spanner verwendet nur dann automatisch einen sekundären Index, wenn im Index selbst alle abgefragten Spalten gespeichert sind (eine abgedeckte Abfrage). Wenn Sie erzwingen möchten, dass beim Abfragen von Spalten in der ursprünglichen Tabelle ein Index verwendet wird, müssen Sie in der SQL-Anweisung eine FORCE INDEX-Anweisung verwenden. Beispiel:
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
Mit Indexen können eindeutige Werte in einer Tabellenspalte erzwungen werden. Dazu wird ein UNIQUE-Index für diese Spalte definiert. Der Index verhindert das Hinzufügen doppelter Werte.
Hier ist ein Beispiel für eine DDL-Anweisung, die einen sekundären Index für die Album-Tabelle erstellt:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Wenn Sie nach dem Laden Ihrer Daten zusätzliche Indexe erstellen, kann das Auffüllen des Indexes einige Zeit in Anspruch nehmen. Daher wird empfohlen, maximal drei Indexe pro Tag hinzuzufügen. Eine ausführliche Anleitung zum Erstellen von sekundären Indexen finden Sie unter Sekundäre Indexe. Weitere Informationen zu den Einschränkungen bei der Indexerstellung finden Sie unter Schemaaktualisierungen.
Schritt 2: SQL-Abfragen übersetzen
Spanner verwendet den ANSI 2011-Dialekt von SQL mit Erweiterungen und bietet viele Funktionen und Operatoren zum Übersetzen und Zusammenfassen von Daten. Alle SQL-Abfragen, die Oracle-spezifische Syntax, Funktionen und Typen verwenden, müssen konvertiert werden, um mit Spanner kompatibel zu sein.
Spanner unterstützt zwar keine strukturierten Daten als Spaltendefinitionen, strukturierte Daten können jedoch in SQL-Abfragen mit den Typen ARRAY und STRUCT verwendet werden.
Sie können beispielsweise eine Abfrage schreiben, die in einer einzelnen Abfrage ein ARRAY aus STRUCTs verwendet, um alle Alben eines Interpreten zurückzugeben. Hierbei werden die vorab verknüpften Daten genutzt.
Weitere Informationen finden Sie im Abschnitt Hinweise zu Unterabfragen der Dokumentation.
SQL-Abfragen können mithilfe der Spanner Studio-Seite in der Google Cloud Console profiliert werden, um die Abfrage auszuführen. Im Allgemeinen sollten Abfragen, die vollständige Tabellenscans großer Tabellen ausführen, sparsam verwendet werden, da sie mit hohen Kosten verbunden sind.
Weitere Informationen zum Optimieren von SQL-Abfragen finden Sie unter Best Practices für SQL.
Schritt 3: Anwendung migrieren, um Spanner zu verwenden
Spanner bietet eine Reihe von Clientbibliotheken für verschiedene Sprachen und die Möglichkeit, Daten mit Spanner-spezifischen API-Aufrufen sowie mit SQL-Abfragen und DML-Anweisungen (Data Modification Language) zu lesen und zu schreiben. Die Verwendung von API-Aufrufen kann für einige Abfragen schneller sein, z. B. für das direkte Lesen der Zeilen nach Schlüssel, da die SQL-Anweisung nicht übersetzt werden muss.
Sie können auch den JDBC-Treiber (Java Database Connectivity) verwenden, um eine Verbindung zu Spanner herzustellen und dabei vorhandene Tools und Infrastrukturen einzubinden, die keine native Integration haben.
Im Rahmen des Migrationsprozesses müssen Funktionen, die in Spanner nicht verfügbar sind, in der Anwendung implementiert werden. Ein Trigger, um Datenwerte zu überprüfen und eine verbundene Tabelle zu aktualisieren, müsste beispielsweise in der Anwendung mithilfe einer Lese-Schreib-Transaktion implementiert werden, die die vorhandene Zeile liest, die Einschränkungen überprüft und die aktualisierten Zeilen in beide Tabellen schreibt.
Spanner bietet Lese-/Schreibtransaktionen und schreibgeschützte Transaktionen, die für eine externe Konsistenz der Daten sorgen. Außerdem können für Lesetransaktionen Zeitstempelgrenzen angewendet werden, bei denen eine konsistente Version der angegeben Daten gelesen wird. Entweder:
- zu einem bestimmten Zeitpunkt in der Vergangenheit (bis zu 1 Stunde zuvor),
- in der Zukunft (der Lesevorgang wird bis zu diesem Zeitpunkt blockiert) oder
- mit einer akzeptablen begrenzten Veralterung, die eine konsistente Darstellung bis zu einem früheren Zeitpunkt liefert. Hierbei muss nicht geprüft werden, ob spätere Daten auf einem anderen Replikat verfügbar sind. Dies kann Leistungsvorteile mit sich bringen, aber die Daten sind unter Umständen veraltet.
Schritt 4: Daten von Oracle nach Spanner übertragen
Wenn Sie Ihre Daten von Oracle nach Spanner übertragen möchten, müssen Sie die Oracle-Datenbank in ein portables Dateiformat (z. B. CSV) exportieren und die Daten anschließend mit Dataflow in Spanner importieren.
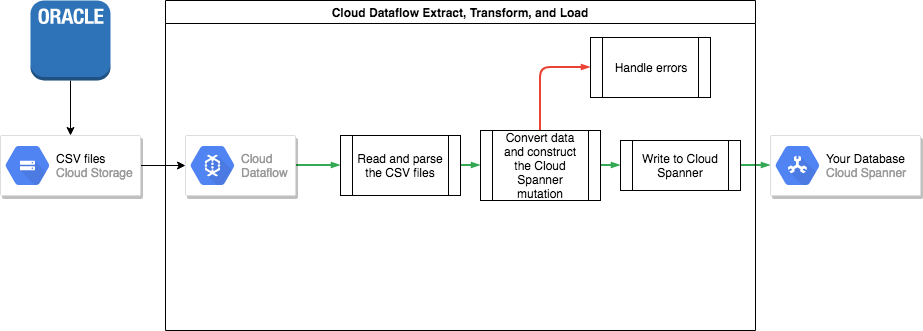
Bulk-Export aus Oracle
Oracle bietet keine integrierten Dienstprogramme zum Exportieren oder Entladen der gesamten Datenbank in ein portables Dateiformat.
Einige Methoden zum Ausführen eines Exports finden Sie in den FAQ zu Oracle.
Dazu gehören:
- Verwenden von SQL*plus oder SQLcl, um eine Abfrage in eine Textdatei zu übertragen
- Schreiben einer PL/SQL-Funktion mithilfe von UTL_FILE, um eine Tabelle parallel in Textdateien zu entladen
- Verwenden von Funktionen in Oracle APEX oder Oracle SQL Developer, um eine Tabelle in eine CSV- oder XML-Datei zu entladen
Diese Ansätze haben jedoch den Nachteil, dass jeweils nur eine Tabelle exportiert werden kann. Sie müssen also die Anwendung anhalten oder die Datenbank stilllegen, damit die Datenbank für den Export in einem konsistenten Zustand bleibt.
Die in den FAQ zu Oracle aufgelisteten Drittanbietertools sind eine weitere Möglichkeit. Mit einigen dieser Tools kann eine konsistente Ansicht der gesamten Datenbank bereitgestellt werden.
Nachdem diese Datendateien entladen wurden, können Sie sie in einen Cloud Storage-Bucket hochladen, damit sie für den Import verfügbar sind.
Bulk-Import in Spanner
Da sich die Datenbankschemas von Oracle und Spanner voraussichtlich unterscheiden werden, müssen Sie im Rahmen des Importvorgangs möglicherweise einige Datenkonvertierungen vornehmen.
Dataflow ist die einfachste Methode, um diese Datenkonvertierungen durchzuführen und die Daten in Spanner zu importieren.
Dataflow ist der Google Cloud Dienst zum Extrahieren, Transformieren und Laden. Dieser Dienst bietet eine Plattform zum Ausführen von Datenpipelines, die mit dem Apache Beam SDK geschrieben wurden. So können große Datenmengen parallel auf mehreren Maschinen gelesen und verarbeitet werden.
Für das Apache Beam SDK benötigen Sie ein einfaches Java-Programm, um die Daten lesen, transformieren und schreiben zu können. Für Cloud Storage und Spanner gibt es Beam-Connectors. Der einzige Code, den Sie schreiben müssen, ist die Datentransformation selbst.
Ein Beispiel für eine einfache Pipeline, die CSV-Dateien liest und in Spanner schreibt, finden Sie im Beispielcode-Repository zu diesem Beitrag.
Wenn Sie in Ihrem Spanner-Schema verschachtelte übergeordnete und untergeordnete Tabellen verwenden, müssen Sie beim Importieren darauf achten, dass die übergeordnete Zeile zeitlich vor der untergeordneten Zeile erstellt wird. Zu diesem Zweck importiert der Code der Spanner-Importpipeline zuerst alle Daten für Tabellen auf Stammebene, dann alle untergeordneten Tabellen der Ebene 1, dann alle untergeordneten Tabellen der Ebene 2 usw.
Die Spanner-Importpipeline kann direkt für den Bulk-Import Ihrer Daten verwendet werden. Dafür müssen die Daten jedoch in Avro-Dateien mit dem richtigen Schema vorliegen.
Schritt 5: Beide Datenbanken konsistent halten
Da viele Anwendungen Anforderungen bezüglich der Verfügbarkeit haben, ist es oftmals nicht möglich, die Anwendung für den Zeitraum des Exports und Imports der Daten im Offline-Modus zu halten. Während die Daten an Spanner übertragen werden, nimmt die Anwendung zusätzliche Änderungen an der vorhandenen Datenbank vor. Aus diesem Grund müssen Aktualisierungen in die Spanner-Datenbank kopiert werden, während die Anwendung ausgeführt wird.
Es gibt verschiedene Methoden, um eine kontinuierliche Synchronisierung beider Datenbanken zu ermöglichen, darunter Change Data Capture und die Implementierung von gleichzeitigen Aktualisierungen in der Anwendung.
Change Data Capture
Oracle GoldenGate kann einen CDC-Stream (Change Data Capture) für die Oracle-Datenbank bereitstellen. Alternativ können für die Oracle-Datenbank die Schnittstellen LogMiner oder Oracle XStream Out genutzt werden, um unabhängig von Oracle GoldenGate einen CDC-Stream zu erhalten.
Sie können eine Anwendung schreiben, die einen dieser Streams abonniert und (nach der Datenkonvertierung) dieselben Änderungen an der Spanner-Datenbank vornimmt. In eine solche Anwendung zur Streamverarbeitung müssen mehrere Funktionen implementiert werden:
- Verbindung zur Oracle-Datenbank herstellen (Quelldatenbank).
- Verbindung zu Cloud Spanner herstellen (Zieldatenbank).
- Wiederholtes Ausführen der folgenden Schritte:
- Daten empfangen, die von einem der CDC-Streams der Oracle-Datenbank erzeugt wurden.
- Die vom CDC-Stream erzeugten Daten interpretieren.
- Daten in Spanner-
INSERT-Anweisungen konvertieren. - Spanner-
INSERT-Anweisungen ausführen.
Die Datenbankmigrationstechnologie ist eine Middleware-Technologie, in die die erforderlichen Funktionen implementiert sind. Die Datenbankmigrationsplattform wird je nach Kundenanforderungen entweder am Quell- oder am Zielspeicherort als separate Komponente installiert. In der Datenbankmigrationsplattform muss lediglich die Verbindungskonfiguration der betroffenen Datenbanken vorgenommen werden, um die kontinuierliche Datenübertragung von der Quell- zur Zieldatenbank festzulegen und zu starten.
Striim ist eine Technologieplattform für die Datenbankmigration, die inGoogle Cloudverfügbar ist. Sie ermöglicht eine Verbindung von Oracle GoldenGate sowie von Oracle LogMiner und Oracle XStream Out zu CDC-Streams. Striim stellt ein grafisches Tool bereit, mit dem Sie die Datenbankkonnektivität und alle Transformationsregeln konfigurieren können, die erforderlich sind, um Daten von Oracle an Spanner zu übertragen.
Sie können Striim aus dem Google Cloud Marketplace installieren, eine Verbindung zwischen den Quell- und Zieldatenbanken herstellen, Transformationsregeln implementieren und mit der Übertragung von Daten beginnen, ohne selbst eine Anwendung zur Streamverarbeitung erstellen zu müssen.
Gleichzeitige Aktualisierungen beider Datenbanken über die Anwendung
Eine weitere Methode besteht darin, die Anwendung so anzupassen, dass Schreibvorgänge in beiden Datenbanken ausgeführt werden. Eine der Datenbanken (anfangs Oracle) wird als "Source of Truth" (Quelle der Wahrheit) angesehen. Nach jedem Schreibvorgang in die Datenbank wird die gesamte Zeile gelesen, konvertiert und in die Spanner-Datenbank geschrieben.
Auf diese Weise überschreibt die Anwendung die Spanner-Zeilen kontinuierlich mit den aktuellen Daten.
Wenn Sie sicher sind, dass alle Daten richtig übertragen wurden, können Sie die Spanner-Datenbank als "Source of Truth" festlegen.
Dieser Mechanismus bietet einen Rollback-Pfad für den Fall, dass beim Wechsel zu Spanner Probleme auftreten.
Datenkonsistenz prüfen
Während Daten in ihre Spanner-Datenbank gestreamt werden, können Sie regelmäßig einen Vergleich zwischen Ihren Spanner-Daten und Ihren Oracle-Daten vornehmen, um sicherzustellen, dass die Daten konsistent sind.
Dafür fragen Sie beide Datenquellen ab und vergleichen die Ergebnisse.
Sie können Dataflow verwenden, um mithilfe der Join-Transformation einen detaillierten Vergleich großer Datasets vorzunehmen. Diese Transformation prüft anhand der Schlüssel von zwei Datasets, ob die Werte übereinstimmen. Die zugeordneten Werte können dann verglichen werden.
Sie können diese Prüfung regelmäßig vornehmen, bis die Konsistenz Ihren Geschäftsanforderungen entspricht.
Schritt 6: Spanner als „Source of Truth“ für die Anwendung festlegen
Wenn Sie sicher sind, dass die Datenmigration ordnungsgemäß funktioniert hat, können Sie Spanner für Ihre Anwendung als "Source of Truth" festlegen. Schreiben Sie Änderungen kontinuierlich in die Oracle-Datenbank zurück, um die MySQL-Datenbank auf dem neuesten Stand zu halten und bei Problemen einen Rollback-Pfad zu haben.
Abschließend können Sie den Code zur Aktualisierung der Oracle-Datenbank deaktivieren und entfernen sowie die inzwischen veraltete MySQL-Datenbank herunterfahren.
Spanner-Datenbanken exportieren und importieren
Optional können Sie Ihre Tabellen mithilfe einer Dataflow-Vorlage aus Spanner in einen Cloud Storage-Bucket exportieren. Der dabei erstellte Ordner enthält eine Reihe von Avro-Dateien und JSON-Manifestdateien mit den exportierten Tabellen. Diese Dateien dienen verschiedenen Zwecken, darunter:
- Sichern der Datenbank für die Einhaltung der Datenaufbewahrungsrichtlinie oder zur Notfallwiederherstellung
- Importieren der Avro-Datei in andere Google Cloud -Angebote wie BigQuery
Weitere Informationen zum Exportieren und Importieren finden Sie unter Datenbanken exportieren und Datenbanken importieren.
Nächste Schritte
- Spanner-Schema optimieren
- Dataflow für komplexere Situationen nutzen