이 문서에서는 온라인 트랜잭션 처리(OLTP) 데이터베이스를 MySQL에서 Spanner로 마이그레이션하는 방법을 설명합니다.
마이그레이션 제약조건
Spanner는 특정 개념을 다른 엔터프라이즈 데이터베이스 관리 도구와 다르게 사용하므로 기능을 최대한 활용하려면 애플리케이션의 아키텍처를 조정해야 할 수 있습니다. 또한 요구사항을 충족하기 위해 Google Cloud의 다른 서비스로 Spanner를 보완해야 할 수도 있습니다.
저장 프로시저 및 트리거
Spanner는 데이터베이스 수준에서 사용자 코드 실행을 지원하지 않으므로, 마이그레이션의 일환으로 데이터베이스 수준 저장 프로시저 및 트리거로 구현된 비즈니스 로직을 애플리케이션으로 이동해야 합니다.
시퀀스
Spanner에서는 UUID 버전 4를 기본 방법으로 사용하여 기본 키 값을 생성하는 것이 좋습니다. GENERATE_UUID() 함수(GoogleSQL, PostgreSQL)는 STRING 유형으로 표시되는 UUID 버전 4 값을 반환합니다.
정수 값을 생성해야 하는 경우 Spanner는 비트 반전 포지티브 시퀀스(GoogleSQL, PostgreSQL)를 지원하며, 이러한 시퀀스는 양의 64비트 숫자 공간에 균등하게 분산되는 값을 생성합니다. 부하 집중 문제를 방지하기 위해 이러한 수치를 사용할 수 있습니다.
자세한 내용은 기본 키 기본값 전략을 참조하세요.
액세스 제어
Spanner에서는 테이블 및 열 수준에서 세분화된 액세스 제어를 지원합니다. 뷰에 대한 세분화된 액세스 제어는 지원되지 않습니다. 자세한 내용은 세분화된 액세스 제어 정보를 참조하세요.
데이터 유효성 검사 제약조건
Spanner는 데이터베이스 레이어에서 데이터 유효성 검사 제약조건을 제한적으로 지원합니다. 더 복잡한 데이터 제약조건이 필요하다면 애플리케이션 계층에서 해당 제약조건을 구현해야 합니다.
다음 표에서는 MySQL 데이터베이스에서 흔히 볼 수 있는 제약조건 유형과 Spanner에서 이를 구현하는 방법이 제시되어 있습니다.
| 제약조건 | Spanner로 구현 |
|---|---|
| null 아님 | NOT NULL 열 제약조건 |
| 고유 | UNIQUE 제약조건을 가진 보조 색인 |
Foreign key(일반 테이블용) |
외래 키 관계 만들기 및 관리를 참조하세요. |
외래 키 ON DELETE/ON UPDATE 작업 |
인터리브 처리된 테이블에서만 가능함. 그렇지 않으면 애플리케이션 계층에서 구현됨. |
CHECK 제약조건을 통한 값 확인 및 유효성 검사 |
확인 제약조건 만들기 및 관리를 참조하세요. |
| 트리거를 통한 값 확인 및 유효성 검사 | 애플리케이션 계층에서 구현됨 |
생성된 열
Spanner는 생성된 열을 지원합니다. 이때 열 값은 항상 테이블 정의의 일부로 제공된 함수에 의해 생성됩니다. MySQL에서와 같이 생성된 열은 DML 문에서 제공된 값으로 명시적으로 설정할 수 없습니다.
생성된 열은 CREATE TABLE 또는 ALTER TABLE 데이터 정의 언어(DDL) 문 실행 중에 열 정의의 일부로 정의됩니다. AS 키워드 뒤에 유효한 SQL 함수와 필요한 서픽스 키워드 STORED가 이어집니다. STORED 키워드는 ANSI SQL 사양의 일부이며 함수 결과가 테이블의 다른 열과 함께 저장되었음을 나타냅니다.
SQL 함수인 생성 표현식에서 모든 결정론적 표현식, 함수, 연산자를 포함할 수 있으며 보조 색인에서 사용하거나 외래 키로 사용할 수 있습니다.
생성된 열 만들기 및 관리를 검토하여 이 열 유형을 관리하는 방법을 자세히 알아보세요.
지원되는 데이터 유형
MySQL과 Spanner는 서로 다른 데이터 유형 집합을 지원합니다. 다음 표에는 MySQL 데이터 유형 및 그에 해당하는 Spanner 데이터 유형이 나열되어 있습니다. 각 Spanner 데이터 유형의 자세한 정의는 데이터 유형을 참조하세요.
MySQL 데이터를 Spanner 데이터베이스에 맞게 만들기 위해 참고 열의 설명처럼 데이터를 추가로 변환해야 할 수도 있습니다. 예를 들어 큰 BLOB을 데이터베이스가 아닌 Cloud Storage 버킷에 객체로 저장한 후 Cloud Storage 객체에 대한 URI 참조를 데이터베이스에 STRING으로 저장할 수 있습니다.
| MySQL 데이터 유형 | 대응하는 Spanner 데이터 유형 | 참고 |
|---|---|---|
INTEGER, INT, BIGINT MEDIUMINT, SMALLINT |
INT64 |
|
TINYINT, BOOL, BOOLEAN |
BOOL, INT64 |
TINYINT(1) 값은 'true'(0이 아닌 값) 또는 'false'(0)의 부울 값을 나타내는 데 사용됩니다. |
FLOAT, DOUBLE |
FLOAT64 |
|
DECIMAL, NUMERIC |
NUMERIC, STRING
|
MySQL에서 NUMERIC 및 DECIMAL 데이터 유형은 열 선언에 정의된 대로 최대 65자리의 정밀도와 척도를 지원합니다.
Spanner NUMERIC 데이터 유형은 최대 38자리의 정밀도와 소수점 9자리의 척도를 지원합니다.더 높은 정밀도가 필요한 경우 다른 메커니즘에 대해 임의 정밀도 숫자 데이터 저장을 참조하세요. |
BIT |
BYTES |
|
DATE |
DATE |
Spanner와 MySQL 모두 날짜에 'yyyy-mm-dd' 형식을 사용하므로 변환할 필요가 없습니다. 날짜를 형식이 지정된 문자열로 전환할 수 있는 SQL 함수가 제공됩니다. |
DATETIME, TIMESTAMP |
TIMESTAMP |
Spanner는 시간대와 관계없이 시간을 저장합니다. 시간대를 저장해야 하는 경우에는 별도의 STRING 열을 사용해야 합니다.
타임스탬프를 표준 시간대를 사용한 형식이 지정된 문자열로 전환할 수 있는 SQL 함수가 제공됩니다. |
CHAR, VARCHAR |
STRING |
참고: Spanner는 전체적으로 유니코드 문자열을 사용합니다. VARCHAR는 최대 길이 65,535바이트를 지원하지만 Cloud Spanner는 최대 2,621,440자(영문 기준)를 지원합니다. |
BINARY, VARBINARY, BLOB, TINYBLOB |
BYTES |
작은 객체(10MiB 미만)를 BYTES로 저장할 수 있습니다. 더 큰 객체를 저장하려면 Cloud Storage와 같은 다른 Google Cloud 서비스를 사용해야 합니다. |
TEXT, TINYTEXT, ENUM |
STRING
|
작은 TEXT 값(10MiB 미만)을 STRING으로 저장할 수 있습니다. 더 큰 TEXT 값을 저장하려면 Cloud Storage와 같은 다른 Google Cloud 서비스를 사용해야 합니다. |
ENUM |
STRING |
ENUM 값의 유효성 검사는 애플리케이션에서 수행해야 합니다. |
SET |
ARRAY<STRING> |
SET 요소 값의 유효성 검사는 애플리케이션에서 수행해야 합니다. |
LONGBLOB, MEDIUMBLOB |
BYTES 또는 STRING(객체 URI 포함)
|
작은 객체(10MiB 미만)를 BYTES로 저장할 수 있습니다. 더 큰 객체를 저장하려면 Cloud Storage와 같은 다른 Google Cloud 서비스를 사용해야 합니다. |
LONGTEXT, MEDIUMTEXT |
STRING(데이터 또는 외부 객체의 URI 포함)
|
작은 객체(2,621,440자 미만(영문 기준))를 STRING으로 저장할 수 있습니다. 더 큰 객체를 저장하려면 Cloud Storage와 같은 다른 Google Cloud 서비스를 사용해야 합니다. |
JSON |
JSON
|
작은 JSON 문자열(2,621,440자 미만(영문 기준))을 JSON으로 저장할 수 있습니다. 더 큰 객체를 저장하려면 Cloud Storage와 같은 다른 Google Cloud 서비스를 사용해야 합니다. |
GEOMETRY, POINT, LINESTRING, POLYGON, MULTIPOINT, MULTIPOLYGON, GEOMETRYCOLLECTION |
Spanner는 지리정보 데이터 유형을 지원하지 않습니다. 이 데이터를 표준 데이터 형식으로 저장하고 애플리케이션 계층에서 검색/필터링 로직을 구현해야 합니다. |
이전 프로세스
이전 프로세스의 전체 과정은 다음과 같습니다.
- 스키마와 데이터 모델을 전환합니다.
- 모든 SQL 쿼리를 변환합니다.
- MySQL 이외에 Spanner를 사용하도록 애플리케이션을 마이그레이션합니다.
- MySQL에서 데이터를 일괄적으로 내보내고 Dataflow를 사용하여 Spanner로 데이터를 가져옵니다.
- 마이그레이션 중에는 두 데이터베이스 간의 일관성을 유지합니다.
- MySQL에서 애플리케이션을 이전합니다.
1단계: 데이터베이스 및 스키마 변환
기존 스키마를 Spanner 스키마로 전환하여 데이터를 저장합니다. 애플리케이션을 보다 간단하게 수정하려면 전환된 스키마가 기존 MySQL 스키마와 최대한 일치해야 합니다. 하지만 기능 차이로 인해 일부 변경이 필요할 수 있습니다.
스키마 설계 권장사항을 따르면 처리량을 높이고 Spanner 데이터베이스의 부하 집중 문제를 줄일 수 있습니다.
기본 키
Spanner에서 행을 2개 이상 저장해야 하는 모든 테이블은 하나 이상의 열을 가진 테이블로 구성된 기본 키가 있어야만 합니다. 테이블의 기본 키는 테이블에 있는 각 행을 고유하게 식별하고 Spanner는 기본 키를 사용해서 테이블 행을 정렬합니다. Spanner는 고도로 분산되어 있으므로 데이터 증가에 맞춰 확장되는 기본 키 생성 기술을 선택하는 것이 중요합니다. 자세한 내용은 기본 키 마이그레이션 전략을 참조하세요.
기본 키를 지정한 후에는 테이블을 삭제하고 다시 만들어야 기본 키 열을 추가 또는 제거하거나 나중에 기본 키 값을 변경할 수 없습니다. 기본 키 지정 방법에 대한 자세한 내용은 스키마 및 데이터 모델 - 기본 키를 참조하세요.
테이블 인터리브 처리
Spanner에는 테이블 2개를 일대다 상위-하위 관계로 정의할 수 있는 기능이 있습니다. 이 기능은 스토리지의 상위 행 옆에 있는 하위 데이터 행을 인터리브 처리하므로, 상위 테이블과 하위 테이블을 함께 쿼리하면 테이블이 미리 효과적으로 결합되어 데이터 검색 효율성이 향상됩니다.
하위 테이블의 기본 키는 상위 테이블의 기본 키 열로 시작해야 합니다. 하위 행에서 볼 때 상위 행의 기본 키는 외래 키입니다. 상위-하위 관계를 최대 6단계까지 정의할 수 있습니다.
하위 테이블에 대한 삭제 시 작업을 정의하여 상위 행이 삭제되면 수행할 작업을 결정할 수 있습니다. 즉, 모든 하위 행을 삭제하거나 하위 행이 존재하는 동안에 상위 행 삭제를 차단할 수 있습니다.
다음은 앞에서 정의한 상위 Singers 테이블에 인터리브 처리된 Albums 테이블을 만드는 예입니다.
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
) PRIMARY KEY (SingerId, AlbumId)
INTERLEAVE IN PARENT (Singers)
ON DELETE CASCADE;
보조 색인 만들기
또한 보조 색인을 만들어 테이블 내에서 기본 키 밖에 있는 데이터의 색인을 생성할 수 있습니다. Spanner는 테이블과 동일한 방식으로 보조 색인을 구현하므로, 색인 키로 사용할 열 값에는 테이블의 기본 키와 동일한 제약조건이 있습니다. 이는 또한 색인의 일관성이 Spanner 테이블과 동일하게 보장됨을 의미합니다.
보조 색인을 사용한 값 조회는 테이블 조인을 사용하는 쿼리와 실제로 동일합니다. STORING 절을 사용하여 보조 색인에 원래 테이블의 열 값을 복사하여 저장함으로써 커버링 색인을 만들 수 있으므로, 색인을 사용하여 쿼리 성능을 향상시킬 수 있습니다.
Spanner의 쿼리 최적화 도구는 색인 자체가 쿼리되는 모든 열을 저장하고 있는 경우에만(적용되는 쿼리) 보조 색인을 자동으로 사용합니다. 원래 테이블의 열 쿼리 시 색인을 사용하게 만들려면 SQL 문에서 FORCE INDEX 지시문을 사용해야 합니다. 예를 들면 다음과 같습니다.
SELECT *
FROM MyTable@{FORCE_INDEX=MyTableIndex}
WHERE IndexedColumn=@value
색인을 사용하면 테이블 열에 UNIQUE 색인을 정의하여 해당 열 내의 값을 고유하게 만들 수 있습니다. 중복 값 추가는 색인에 의해 방지됩니다.
다음은 Albums 테이블에 대한 보조 색인을 만드는 DDL 문의 예입니다.
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
데이터가 로드된 후에 추가 색인을 만들면 색인을 채우는데 다소 시간이 걸릴 수 있습니다. 추가 속도를 하루에 평균 3회로 제한하는 것이 좋습니다. 보조 색인 만들기에 대한 자세한 내용은 보조 색인을 참조하세요. 색인 생성 시 제한사항에 대한 자세한 내용은 스키마 업데이트를 참조하세요.
2단계: 모든 SQL 쿼리 변환
Spanner는 ANSI 2011 SQL 언어(확장 포함)를 사용하며 데이터를 변환하고 집계하는 데 유용한 다양한 함수 및 연산자를 포함합니다. MySQL 관련 언어, 함수, 유형을 사용하는 모든 SQL 쿼리를 Spanner와 호환되도록 전환해야 합니다.
Spanner는 구조화된 데이터를 열 정의로 지원하지 않습니다. 하지만 ARRAY<> 및 STRUCT<> 유형을 사용하여 SQL 쿼리에서 구조화된 데이터를 사용할 수 있습니다. 예를 들어, 사전 결합된 데이터를 활용하여 STRUCT의 ARRAY를 사용하는 아티스트의 모든 앨범을 반환하는 쿼리를 작성할 수 있습니다. 자세한 내용은 문서의 하위 쿼리 섹션을 참조하세요.
Google Cloud 콘솔의 Spanner 스튜디오 페이지에서 SQL 쿼리를 프로파일링하여 쿼리를 실행할 수 있습니다. 일반적으로 큰 테이블에 전체 테이블 검색을 수행하는 쿼리의 비용이 비싸므로 아껴서 사용해야 합니다. SQL 쿼리 최적화에 대한 자세한 내용은 SQL 권장사항 문서를 참조하세요.
3단계: Spanner를 사용하도록 애플리케이션 마이그레이션
Spanner는 다양한 언어에 대한 클라이언트 라이브러리 집합과 함께 Cloud Spanner 관련 API 호출, SQL 쿼리, DML(Data Modification Language) 문을 사용하여 데이터를 읽고 쓸 수 있는 기능을 제공합니다. SQL 문을 변환할 필요가 없으므로, 키로 행 직접 읽기와 같은 일부 쿼리에 대해서는 API 호출을 사용하는 것이 더 빠를 수 있습니다.
Spanner는 Java 애플리케이션을 위한 JDBC 드라이버를 제공합니다.
마이그레이션 프로세스의 일부로 위에서 언급된 Spanner에서 사용할 수 없는 기능을 애플리케이션에 구현해야 합니다. 예를 들어 데이터 값을 확인하고 관련 테이블을 업데이트하는 트리거는 애플리케이션에서 읽기/쓰기 트랜잭션을 사용하여 기존 행을 읽고 제약조건을 확인한 후 두 테이블에 업데이트된 행을 쓰도록 구현되어야 합니다.
Spanner는 읽기/쓰기 및 읽기 전용 트랜잭션을 제공하여 데이터의 외부 일관성을 보장합니다. 또한 읽기 트랜잭션에 타임스탬프 경계를 적용할 수 있어 다음 중 하나에서 일관된 버전의 데이터를 읽을 수 있습니다.
- 과거의 정확한 시점(최대 1시간 전)
- 미래(해당 시간에 도달할 때까지 읽기가 차단됨)
- 허용된 양의 제한된 비활성이 지난 후. 이 시간이 지나면 다른 복제본에서 나중에 데이터를 사용할 수 있는지 확인하지 않고도 과거의 일정 시간까지 일관된 뷰가 반환됩니다. 이 경우 비활성 데이터를 희생시키는 대신 성능상의 이점을 얻을 수 있습니다.
4단계: MySQL에서 Spanner로 데이터 전송
MySQL에서 Spanner로 데이터를 전송하려면 MySQL 데이터베이스를 포팅이 가능한 파일 형식(예: XML)으로 내보낸 후 Dataflow를 사용하여 Spanner로 해당 데이터를 가져와야 합니다.
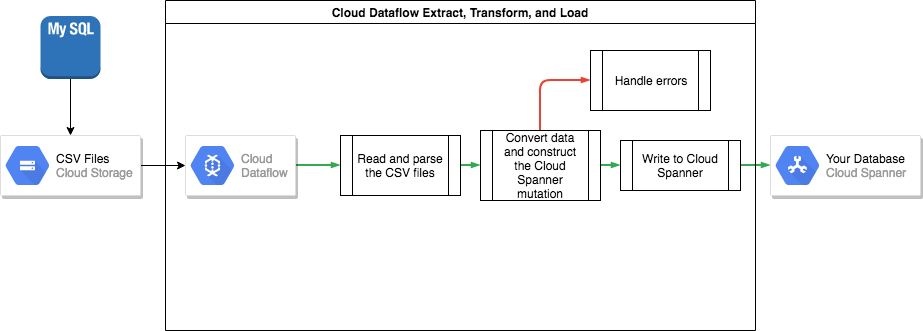
MySQL에서 일괄 내보내기
MySQL에 포함된 mysqldump 도구는 전체 데이터베이스를 올바른 형식의 XML 파일로 내보낼 수 있습니다.
또는 SELECT ... INTO OUTFILE SQL 문을 사용하여 각 테이블에 대해 CSV 파일을 만들 수 있습니다. 그러나 이 방법은 한 번에 테이블 하나만 내보낼 수 있다는 단점이 있습니다. 즉, 데이터베이스를 내보내기 상태로 일관되게 유지하려면 애플리케이션을 일시 중지하거나 데이터베이스를 정지해야 합니다.
이러한 데이터 파일을 내보낸 후에는 가져올 수 있도록 Cloud Storage 버킷에 업로드하는 것이 좋습니다.
Spanner로 일괄 가져오기
MySQL과 Spanner 간에 데이터베이스 스키마가 다를 수 있으므로, 일부 데이터 전환을 가져오기 프로세스의 일부로 만들어야 할 수도 있습니다. 이러한 데이터 전환을 수행하고 Spanner로 데이터를 가져오는 가장 쉬운 방법은 Dataflow를 사용하는 것입니다. Dataflow는 Google Cloud 분산 추출, 변환, 로드(ETL) 서비스로, Apache Beam SDK로 작성된 데이터 파이프라인을 실행하여 대량의 데이터를 여러 머신에서 병렬로 읽고 처리하기 위한 플랫폼입니다.
Apache Beam SDK를 사용하려면 데이터 읽기, 변환, 쓰기를 설정하는 간단한 Java 프로그램을 작성해야 합니다. Cloud Storage 및 Spanner용 Beam Connector가 제공되므로, 데이터 변환 자체에 대한 코드만 작성하면 됩니다.
CSV 파일에서 읽고 Spanner에 쓰는 간단한 파이프라인의 예시는 샘플 코드 저장소를 참조하세요.
Spanner 스키마에서 상위-하위 인터리브 처리된 테이블을 사용하는 경우, 가져오기 프로세스에서 하위 행 앞에 상위 행이 생성되는지 주의해야 합니다. Spanner 가져오기 파이프라인 코드는 먼저 루트 수준 테이블의 모든 데이터를 가져온 후 모든 수준 1 하위 테이블과 모든 수준 2 하위 테이블 등의 데이터를 차례로 가져오는 방식으로 이를 처리합니다.
Spanner 가져오기 파이프라인을 직접 사용하여 데이터를 일괄적으로 가져올 수 있습니다. 하지만 이 방법을 사용하려면 데이터가 올바른 스키마를 사용하여 Avro 파일에 있어야 합니다.
5단계: 두 데이터베이스 간의 일관성 유지
대부분의 애플리케이션에는 가용성 요구사항이 있으므로, 데이터를 내보내고 가져오는 데 필요한 시간 동안 애플리케이션을 오프라인 상태로 유지할 수 없습니다. 따라서 데이터를 Spanner로 전송하는 동안 애플리케이션이 기존 데이터베이스를 계속 수정합니다. 따라서 애플리케이션이 실행되는 동안 Spanner 데이터베이스에 업데이트를 중복시켜야 합니다.
변경 데이터 캡처, 애플리케이션에서 동시 업데이트 구현 등 두 데이터베이스를 동기화 상태로 유지할 수 있는 다양한 방법이 있습니다.
변경 데이터 캡처
MySQL에는 변경 데이터 캡처(CDC) 유틸리티가 기본으로 제공되지 않습니다. 하지만 MySQL binlogs를 받아서 CDC 스트림으로 전환할 수 있는 다양한 오픈소스 프로젝트가 있습니다. 예를 들어 Maxwell의 데몬은 데이터베이스에 CDC 스트림을 제공할 수 있습니다.
이 스트림을 구독하고 Spanner 데이터베이스에 동일한 수정 사항(물론 데이터 변환 후)을 적용하는 애플리케이션을 작성할 수 있습니다.
애플리케이션에서 두 데이터베이스 모두 동시 업데이트
또 다른 방법은 두 데이터베이스 모두에 쓰기 작업을 수행하도록 애플리케이션을 수정하는 방법입니다. 데이터베이스 하나(처음에는 MySQL)가 정보 소스로 간주되고 각 데이터베이스 쓰기 후에 전체 행이 읽혀지고 전환되어 Spanner 데이터베이스에 작성됩니다. 이러한 방법으로 애플리케이션이 Spanner 행을 최신 데이터로 계속 덮어씁니다.
모든 데이터가 올바르게 전송되었다고 확신하면 정보 소스를 Spanner 데이터베이스로 전환할 수 있습니다. 이러한 메커니즘을 통해 Spanner로 전환 시 문제가 발견되면 롤백 경로를 제공합니다.
데이터 일관성 확인
데이터가 Spanner 데이터베이스로 스트리밍되는 과정에서 Spanner 데이터와 MySQL 데이터를 정기적으로 비교하여 데이터 일관성을 유지할 수 있습니다. 두 데이터 소스 모두 쿼리하고 결과를 비교하여 일관성을 확인할 수 있습니다.
Dataflow에서 조인 변환을 통해 대규모 데이터세트를 자세히 비교할 수 있습니다. 이 변환은 키가 지정된 데이터 세트 2개를 취해 키별로 값을 일치시킵니다. 그런 다음 일치된 값이 동일한지 비교할 수 있습니다. 일관성 수준이 비즈니스 요구사항에 부합될 때까지 이러한 확인을 정기적으로 실행할 수 있습니다.
6단계: Spanner를 애플리케이션의 정보 근원으로 전환
데이터 마이그레이션에 확신이 서면 Spanner를 정보 소스로 사용하도록 애플리케이션을 전환할 수 있습니다. MySQL 데이터베이스에 변경사항을 계속해서 작성하면 MySQL 데이터베이스가 최신 상태로 유지되므로, 문제 발생 시 롤백 경로가 제공됩니다.
마지막으로 MySQL 데이터베이스 업데이트 코드를 중지 및 삭제한 후 현재 사용하지 않는 MySQL 데이터베이스를 종료할 수 있습니다.
Spanner 데이터베이스 내보내기 및 가져오기
Dataflow 템플릿으로 내보내기를 수행하여 Spanner에서 Cloud Storage 버킷으로 테이블을 선택적으로 내보낼 수 있습니다. 결과 폴더에는 내보낸 테이블이 있는 여러 개의 JSON 매니페스트 파일과 Avro 파일이 포함됩니다. 이들 파일은 다음과 같은 다양한 용도로 사용됩니다.
- 데이터 보관 정책 규정 준수 또는 재해 복구를 위한 데이터베이스 백업
- Avro 파일을 BigQuery와 같은 다른 Google Cloud 제품으로 가져오기
내보내기 및 가져오기 프로세스에 대한 자세한 내용은 데이터베이스 내보내기와 데이터베이스 가져오기를 참조하세요.
다음 단계
- Spanner 스키마 최적화 방법 알아보기
- 더 복잡한 상황에서 Dataflow를 사용하는 방법 알아보기