Ce tutoriel vous explique comment effectuer la migration d'Amazon DynamoDB vers Spanner. Il est principalement destiné aux propriétaires d'applications qui souhaitent passer d'un système NoSQL à Spanner, un système de base de données SQL entièrement relationnel, tolérant aux pannes et hautement évolutif prenant en charge les transactions. Si vous utilisez de manière cohérente les tables Amazon DynamoDB en termes de types et de mise en page, la mise en correspondance vers Spanner est simple. Si vos tables Amazon DynamoDB contiennent des valeurs et des types de données arbitraires, il peut être plus simple de passer à d'autres services NoSQL, tels que Datastore ou Firestore.
Ce tutoriel part du principe que vous maîtrisez les schémas de base de données, les types de données, les bases de NoSQL et les systèmes de bases de données relationnelles. Le tutoriel repose sur l'exécution de tâches prédéfinies pour effectuer un exemple de migration. Après avoir suivi ce tutoriel, vous serez en mesure de modifier le code et les étapes fournis en fonction de votre environnement.
Le diagramme d'architecture suivant décrit les composants utilisés dans le tutoriel pour migrer les données :

Objectifs
- Migrer des données depuis Amazon DynamoDB vers Spanner
- Créer une table de migration et une base de données Spanner
- Mettre en correspondance un schéma NoSQL avec un schéma relationnel
- Créer et exporter un exemple d'ensemble de données qui utilise Amazon DynamoDB
- Transférer des données entre Amazon S3 et Cloud Storage
- Charger des données dans Spanner à l'aide de Dataflow
Coûts
Ce tutoriel utilise les composants facturables suivants de Google Cloud :
Les frais Spanner sont basés sur la quantité de capacité de calcul dans votre instance et la quantité de données stockées au cours du cycle de facturation mensuel. Au cours de ce tutoriel, vous utilisez une configuration minimale de ces ressources, qui sont nettoyées à la fin. Dans la réalité, vous estimez vos besoins en termes de débit et de stockage, puis utilisez la documentation relative aux instances Spanner pour déterminer la capacité de calcul dont vous avez besoin.
En plus des ressources Google Cloud , ce tutoriel utilise les ressources Amazon Web Services (AWS) suivantes :
- AWS Lambda
- Amazon S3
- Amazon DynamoDB
Ces services ne sont nécessaires que lors du processus de migration. Au terme du tutoriel, suivez les instructions pour nettoyer toutes les ressources afin d'éviter des frais inutiles. Utilisez le simulateur de coût AWS pour estimer ces frais.
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Spanner, Pub/Sub, Compute Engine, and Dataflow APIs.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
- Définissez la zone Compute Engine par défaut. Par exemple,
us-central1-b. gcloud config set compute/zone us-central1-b - Clonez le dépôt GitHub contenant l'exemple de code. git clone https://github.com/GoogleCloudPlatform/dynamodb-spanner-migration.git
- Accédez au répertoire cloné. cd dynamodb-spanner-migration
- Créez un environnement virtuel Python. pip3 install virtualenv virtualenv env
- Activez l'environnement virtuel. source env/bin/activate
- Installez les modules Python requis. pip3 install -r requirements.txt
- Dans la console AWS, accédez à la section IAM, cliquez sur Roles (Rôles), puis sélectionnez Create role (Créer un rôle).
- Sous Type d'entité de confiance, assurez-vous que l'option Service AWS est sélectionnée.
- Sous Cas d'utilisation, sélectionnez Lambda, puis cliquez sur Suivant.
- Dans la zone de filtre Règles d'autorisation, saisissez
AWSLambdaDynamoDBExecutionRoleet sélectionnezReturnpour effectuer une recherche. - Cochez la case AWSLambdaDynamoDBExecutionRole, puis cliquez sur Next (Suivant).
- Dans la zone Role name (Nom du rôle), saisissez
dynamodb-spanner-lambda-role, puis cliquez sur Create role (Créer le rôle). - Vous êtes toujours dans la section IAM de la console AWS. Cliquez sur Users (Utilisateurs), puis sélectionnez Add users (Ajouter des utilisateurs).
- Dans la zone User name (Nom d'utilisateur), saisissez
dynamodb-spanner-migration. Sous Type d'accès, cochez la case située à gauche de Clé d'accès - Accès automatisé.
Cliquez sur Next: Permissions (Suivant : Autorisations).
Cliquez sur Associer directement les stratégies existantes et, en utilisant le champ Rechercher pour filtrer, cochez la case en regard de chacune des trois règles suivantes:
AmazonDynamoDBFullAccessAmazonS3FullAccessAWSLambda_FullAccess
Cliquez sur Suivant : Tags, Suivant : Vérification, puis sur Créer un utilisateur.
Cliquez sur Afficher pour afficher les identifiants. L'ID de la clé d'accès et la clé d'accès secrète sont affichés pour l'utilisateur nouvellement créé. Laissez cette fenêtre ouverte, car ces identifiants vous seront demandés dans la section suivante. Stockez ces identifiants de manière sécurisée, dans la mesure où ils vous permettent de modifier le compte et d'affecter l'environnement. À la fin de ce tutoriel, vous pourrez supprimer l'utilisateur IAM.
Dans Cloud Shell, configurez l'interface de ligne de commande (CLI) AWS.
aws configure
Le résultat suivant s'affiche :
AWS Access Key ID [None]: PASTE_YOUR_ACCESS_KEY_ID AWS Secret Access Key [None]: PASTE_YOUR_SECRET_ACCESS_KEY Default region name [None]: us-west-2 Default output format [None]:
- Saisissez les valeurs
ACCESS KEY IDetSECRET ACCESS KEYà partir du compte AWS IAM que vous avez créé. - Dans le champ Default region name (Nom de la région par défaut), saisissez
us-west-2. Conservez les valeurs par défaut pour les autres champs.
- Saisissez les valeurs
Fermez la fenêtre de la console AWS IAM.
Dans Cloud Shell, créez une table Amazon DynamoDB qui utilise les attributs de l'exemple de table.
aws dynamodb create-table --table-name Migration \ --attribute-definitions AttributeName=Username,AttributeType=S \ --key-schema AttributeName=Username,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=75,WriteCapacityUnits=75Vérifiez que l'état de la table est
ACTIVE.aws dynamodb describe-table --table-name Migration \ --query 'Table.TableStatus'Remplissez la table avec des exemples de données.
python3 make-fake-data.py --table Migration --items 25000
Créez une instance Spanner dans la même région que celle où vous avez défini la zone Compute Engine par défaut. Par exemple,
us-central1.gcloud beta spanner instances create spanner-migration \ --config=regional-us-central1 --processing-units=100 \ --description="Migration Demo"Créez une base de données dans l'instance Spanner avec l'exemple de table.
gcloud spanner databases create migrationdb \ --instance=spanner-migration \ --ddl "CREATE TABLE Migration ( \ Username STRING(1024) NOT NULL, \ PointsEarned INT64, \ ReminderDate DATE, \ Subscribed BOOL, \ Zipcode INT64, \ ) PRIMARY KEY (Username)"Dans Cloud Shell, activez les flux Amazon DynamoDB sur la table source.
aws dynamodb update-table --table-name Migration \ --stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGESConfigurez un sujet Pub/Sub pour recevoir les modifications.
gcloud pubsub topics create spanner-migration
Le résultat suivant s'affiche :
Created topic [projects/your-project/topics/spanner-migration].
Créez un compte de service IAM pour envoyer les mises à jour de la table au sujet Pub/Sub.
gcloud iam service-accounts create spanner-migration \ --display-name="Spanner Migration"Le résultat suivant s'affiche :
Created service account [spanner-migration].
Créez une liaison de stratégie IAM pour autoriser le compte de service à publier sur Pub/Sub. Remplacez
GOOGLE_CLOUD_PROJECTpar le nom de votre projet Google Cloud .gcloud projects add-iam-policy-binding GOOGLE_CLOUD_PROJECT \ --role roles/pubsub.publisher \ --member serviceAccount:spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comLe résultat suivant s'affiche :
bindings: (...truncated...) - members: - serviceAccount:spanner-migration@solution-z.iam.gserviceaccount.com role: roles/pubsub.publisher
Créez des identifiants pour le compte de service.
gcloud iam service-accounts keys create credentials.json \ --iam-account spanner-migration@GOOGLE_CLOUD_PROJECT.iam.gserviceaccount.comLe résultat suivant s'affiche :
created key [5e559d9f6bd8293da31b472d85a233a3fd9b381c] of type [json] as [credentials.json] for [spanner-migration@your-project.iam.gserviceaccount.com]
Préparez et empaquetez la fonction AWS Lambda pour envoyer les modifications de la table Amazon DynamoDB au sujet Pub/Sub.
pip3 install --ignore-installed --target=lambda-deps google-cloud-pubsub cd lambda-deps; zip -r9 ../pubsub-lambda.zip *; cd - zip -g pubsub-lambda.zip ddbpubsub.py
Créez une variable pour capturer le nom ARN (Amazon Resource Name) du rôle d'exécution Lambda créé précédemment.
LAMBDA_ROLE=$(aws iam list-roles \ --query 'Roles[?RoleName==`dynamodb-spanner-lambda-role`].[Arn]' \ --output text)Utilisez le package
pubsub-lambda.zippour créer la fonction AWS Lambda.aws lambda create-function --function-name dynamodb-spanner-lambda \ --runtime python3.9 --role ${LAMBDA_ROLE} \ --handler ddbpubsub.lambda_handler --zip fileb://pubsub-lambda.zip \ --environment Variables="{SVCACCT=$(base64 -w 0 credentials.json),PROJECT=GOOGLE_CLOUD_PROJECT,TOPIC=spanner-migration}"Le résultat suivant s'affiche :
{ "FunctionName": "dynamodb-spanner-lambda", "LastModified": "2022-03-17T23:45:26.445+0000", "RevisionId": "e58e8408-cd3a-4155-a184-4efc0da80bfb", "MemorySize": 128, ... truncated output... "PackageType": "Zip", "Architectures": [ "x86_64" ] }Create a variable to capture the ARN of the Amazon DynamoDB stream for your table.
STREAMARN=$(aws dynamodb describe-table \ --table-name Migration \ --query "Table.LatestStreamArn" \ --output text)Associez la fonction Lambda à la table Amazon DynamoDB.
aws lambda create-event-source-mapping --event-source ${STREAMARN} \ --function-name dynamodb-spanner-lambda --enabled \ --starting-position TRIM_HORIZONPour optimiser la réactivité lors des tests, ajoutez
--batch-size 1à la fin de la commande précédente. Cela déclenche la fonction chaque fois que vous créez, mettez à jour ou supprimez un élément.Un résultat semblable aux lignes suivantes s'affichera :
{ "UUID": "44e4c2bf-493a-4ba2-9859-cde0ae5c5e92", "StateTransitionReason": "User action", "LastModified": 1530662205.549, "BatchSize": 100, "EventSourceArn": "arn:aws:dynamodb:us-west-2:accountid:table/Migration/stream/2018-07-03T15:09:57.725", "FunctionArn": "arn:aws:lambda:us-west-2:accountid:function:dynamodb-spanner-lambda", "State": "Creating", "LastProcessingResult": "No records processed" ... truncated output...Dans Cloud Shell, créez une variable pour un nom de bucket que vous utiliserez dans plusieurs des sections suivantes.
BUCKET=${DEVSHELL_PROJECT_ID}-dynamodb-spanner-exportCréez un bucket Amazon S3 destiné à recevoir l'exportation DynamoDB.
aws s3 mb s3://${BUCKET}Dans AWS Management Console, accédez à DynamoDB, puis cliquez sur Tables.
Cliquez sur la table
Migration.Dans l'onglet Exportations et flux, cliquez sur Exporter vers la table S3.
Si vous y êtes invité, activez
point-in-time-recovery(PITR).Cliquez sur Parcourir S3 pour choisir le bucket S3 que vous avez créé précédemment.
Cliquez sur Exporter.
Cliquez sur l'icône Actualiser pour mettre à jour l'état du job d'exportation. La tâche prend plusieurs minutes pour terminer l'exportation.
Une fois le processus terminé, examinez le bucket de sortie.
aws s3 ls --recursive s3://${BUCKET}Cette étape prend environ cinq minutes. Une fois l'opération terminée, résultat semblable à celui-ci s'affiche :
2022-02-17 04:41:46 0 AWSDynamoDB/01645072900758-ee1232a3/_started 2022-02-17 04:46:04 500441 AWSDynamoDB/01645072900758-ee1232a3/data/xygt7i2gje4w7jtdw5652s43pa.json.gz 2022-02-17 04:46:17 199 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.json 2022-02-17 04:46:17 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-files.md5 2022-02-17 04:46:17 639 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.json 2022-02-17 04:46:18 24 AWSDynamoDB/01645072900758-ee1232a3/manifest-summary.md5
Dans Cloud Shell, créez un bucket Cloud Storage destiné à recevoir les fichiers exportés d'Amazon S3.
gcloud storage buckets create gs://${BUCKET}Synchronisez les fichiers d'Amazon S3 dans Cloud Storage. La commande
rsyncest efficace pour la plupart des opérations de copie. Si vos fichiers d'exportation sont volumineux (plusieurs Go ou plus), utilisez le service de transfert Cloud Storage pour gérer le transfert en arrière-plan.gcloud storage rsync s3://${BUCKET} gs://${BUCKET} --recursive --delete-unmatched-destination-objectsPour écrire les données des fichiers exportés dans la table Spanner, exécutez une tâche Dataflow avec un exemple de code Apache Beam.
cd dataflow mvn compile mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerBulkWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --importBucket=$BUCKET \ --runner=DataflowRunner \ --region=us-central1"Pour surveiller la progression de la tâche d'importation, accédez à Dataflow dans la console Google Cloud .
Pendant que la tâche s'exécute, vous pouvez consulter le graphique d'exécution pour examiner les journaux. Cliquez sur la tâche pour laquelle l'état Running (En cours d'exécution) est indiqué à l'écran.
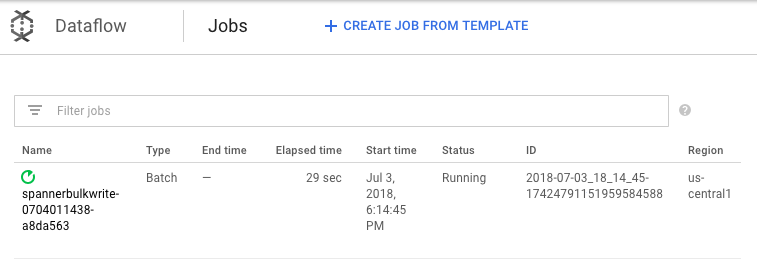
Cliquez sur chaque étape pour voir combien d'éléments ont été traités. L'importation est terminée lorsque toutes les étapes indiquent Succeeded (Effectuée). Un nombre d'éléments traités identique au nombre d'éléments créés dans la table Amazon DynamoDB s'affiche à chaque étape.
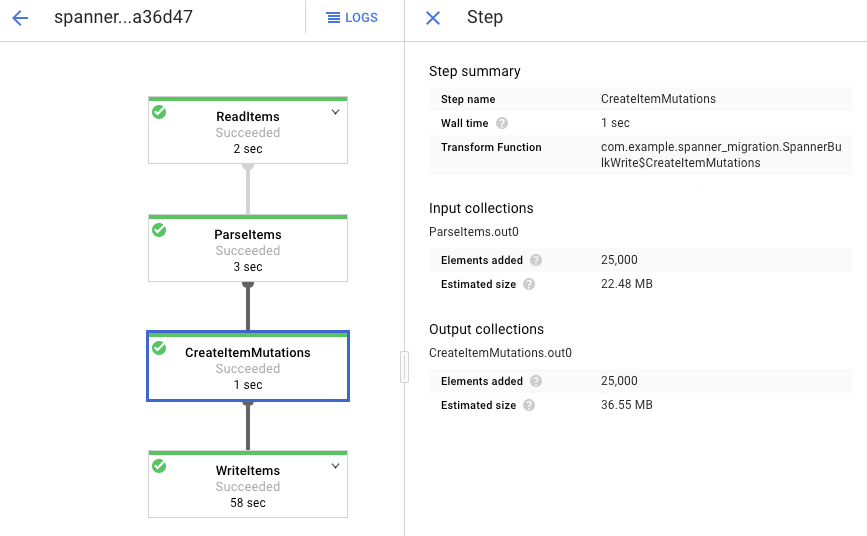
Vérifiez que le nombre d'enregistrements dans la table Spanner de destination correspond au nombre d'éléments dans la table Amazon DynamoDB.
aws dynamodb describe-table --table-name Migration --query Table.ItemCount gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration --sql="select count(*) from Migration"
Le résultat suivant s'affiche :
$ aws dynamodb describe-table --table-name Migration --query Table.ItemCount 25000 $ gcloud spanner databases execute-sql migrationdb --instance=spanner-migration --sql="select count(*) from Migration" 25000
Sélectionnez des entrées aléatoires dans chaque table pour vérifier que les données sont cohérentes.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="select * from Migration limit 1"Le résultat suivant s'affiche :
Username: aadams4495 PointsEarned: 5247 ReminderDate: 2022-03-14 Subscribed: True Zipcode: 58057
Interrogez la table Amazon DynamoDB avec le même
Usernameque celui renvoyé par la requête Cloud Spanner à l'étape précédente. Exemple :aallen2538. La valeur est spécifique aux exemples de données de votre base de données.aws dynamodb get-item --table-name Migration \ --key '{"Username": {"S": "aadams4495"}}'Les valeurs des autres champs doivent correspondre à celles du résultat Spanner. Le résultat suivant s'affiche :
{ "Item": { "Username": { "S": "aadams4495" }, "ReminderDate": { "S": "2018-06-18" }, "PointsEarned": { "N": "1606" }, "Zipcode": { "N": "17303" }, "Subscribed": { "BOOL": false } } }Créez un abonnement au sujet Pub/Sub auquel AWS Lambda envoie des événements.
gcloud pubsub subscriptions create spanner-migration \ --topic spanner-migrationLe résultat suivant s'affiche :
Created subscription [projects/your-project/subscriptions/spanner-migration].
Pour diffuser les modifications à venir dans Pub/Sub afin d'écrire dans la table Spanner, exécutez la tâche Dataflow à partir de Cloud Shell.
mvn exec:java \ -Dexec.mainClass=com.example.spanner_migration.SpannerStreamingWrite \ -Pdataflow-runner \ -Dexec.args="--project=GOOGLE_CLOUD_PROJECT \ --instanceId=spanner-migration \ --databaseId=migrationdb \ --table=Migration \ --experiments=allow_non_updatable_job \ --subscription=projects/GOOGLE_CLOUD_PROJECT/subscriptions/spanner-migration \ --runner=DataflowRunner \ --region=us-central1"Comme pour l'étape de chargement par lot, pour suivre l'avancement de la tâche dans la console Google Cloud , accédez à Dataflow.
Cliquez sur la tâche qui affiche l'état de l'exécution.
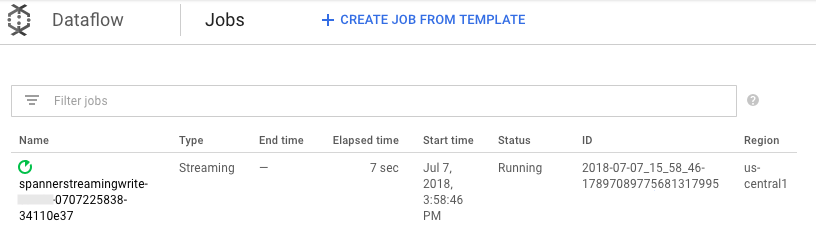
Le graphique de traitement affiche un résultat semblable au précédent, mais chaque élément traité est compté dans la fenêtre d'état. Le temps de latence du système est une estimation approximative du délai d'attente avant que les modifications n'apparaissent dans la table Spanner.
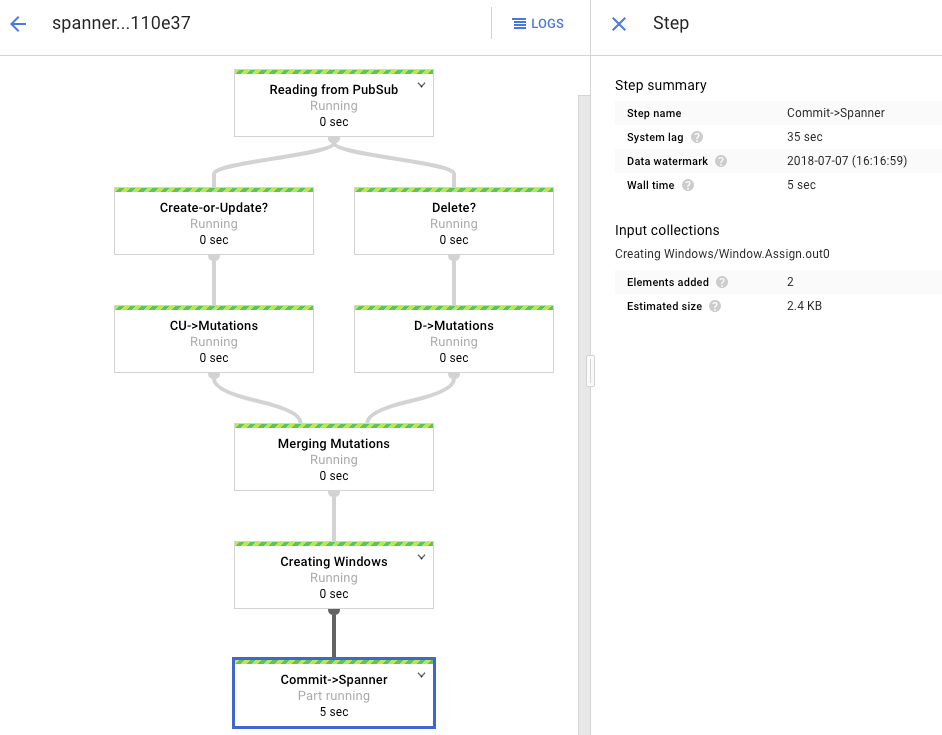
Interrogez une ligne absente dans Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"L'opération ne renverra aucun résultat.
Créez un enregistrement dans Amazon DynamoDB avec la même clé que celle utilisée dans la requête Spanner. Si la commande s'exécute correctement, il n'y a aucun résultat.
aws dynamodb put-item \ --table-name Migration \ --item '{"Username" : {"S" : "my-test-username"}, "Subscribed" : {"BOOL" : false}}'Exécutez à nouveau la même requête pour vérifier que la ligne se trouve maintenant dans Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Le résultat comporte la ligne insérée :
Username: my-test-username PointsEarned: None ReminderDate: None Subscribed: False Zipcode:
Modifiez certains attributs dans l'élément d'origine et mettez à jour la table Amazon DynamoDB.
aws dynamodb update-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}' \ --update-expression "SET PointsEarned = :pts, Subscribed = :sub" \ --expression-attribute-values '{":pts": {"N":"4500"}, ":sub": {"BOOL":true}}'\ --return-values ALL_NEWUn résultat semblable aux lignes suivantes s'affichera :
{ "Attributes": { "Username": { "S": "my-test-username" }, "PointsEarned": { "N": "4500" }, "Subscribed": { "BOOL": true } } }Vérifiez que les modifications sont propagées dans la table Spanner.
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Le résultat est le suivant :
Username PointsEarned ReminderDate Subscribed Zipcode my-test-username 4500 None True
Supprimez l'élément de test de la table source Amazon DynamoDB.
aws dynamodb delete-item \ --table-name Migration \ --key '{"Username": {"S":"my-test-username"}}'Vérifiez que la ligne correspondante est supprimée de la table Spanner. Si la modification est propagée, la commande suivante ne renvoie aucune ligne :
gcloud spanner databases execute-sql migrationdb \ --instance=spanner-migration \ --sql="SELECT * FROM Migration WHERE Username='my-test-username'"Accédez à Spanner.
Cliquez sur Spanner Studio.
Dans le champ Query (Requête), entrez la requête suivante, puis cliquez sur Run query (Exécuter la requête).
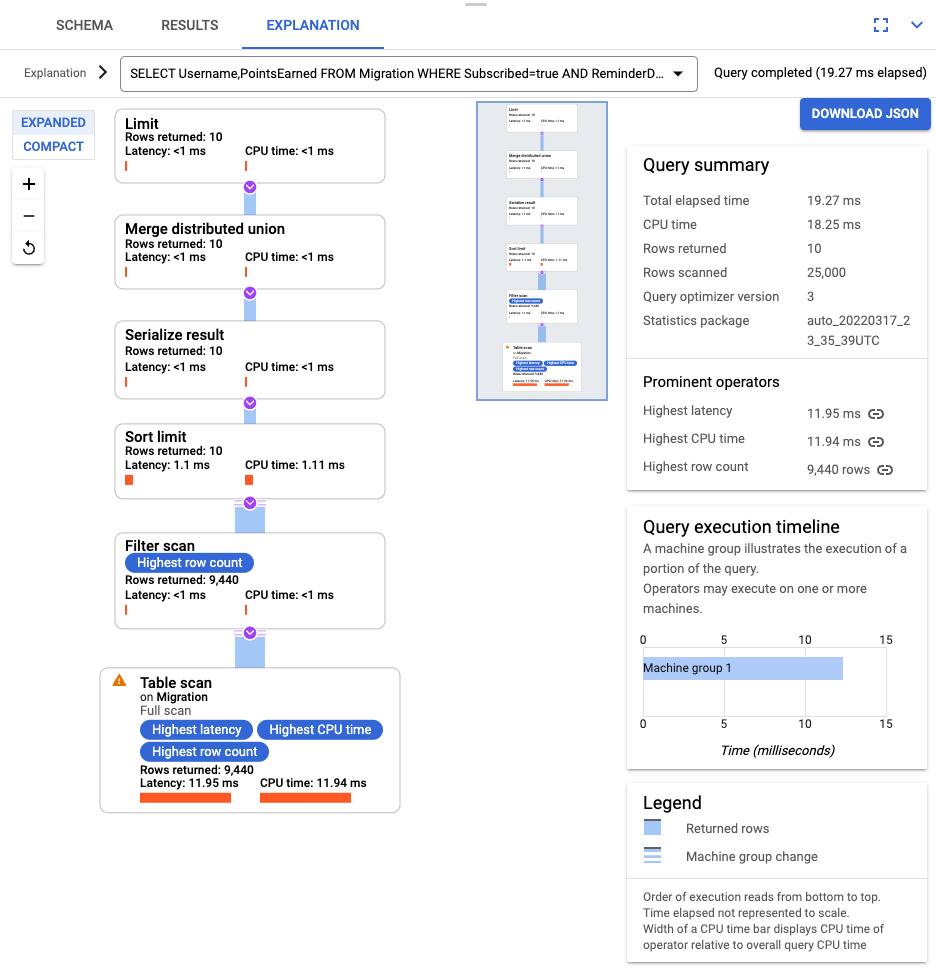
SELECT Username,PointsEarned FROM Migration WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10
Une fois la requête exécutée, cliquez sur Explanation (Explication) et notez le nombre de Rows scanned (Lignes analysées) par rapport au nombre de Rows returned (Lignes renvoyées). Sans index, Spanner analyse la totalité de la table pour renvoyer un petit sous-ensemble de données correspondant à la requête.
Si cela représente une requête fréquente, créez un index composite sur les colonnes Subscribed et ReminderDate. Dans la console Spanner, sélectionnez Index dans le volet de gauche, puis cliquez sur Créer un index.
Dans la zone de texte, saisissez la définition de l'index.
CREATE INDEX SubscribedDateDesc ON Migration ( Subscribed, ReminderDate DESC )
Pour commencer la création de la base de données en arrière-plan, cliquez sur Créer.
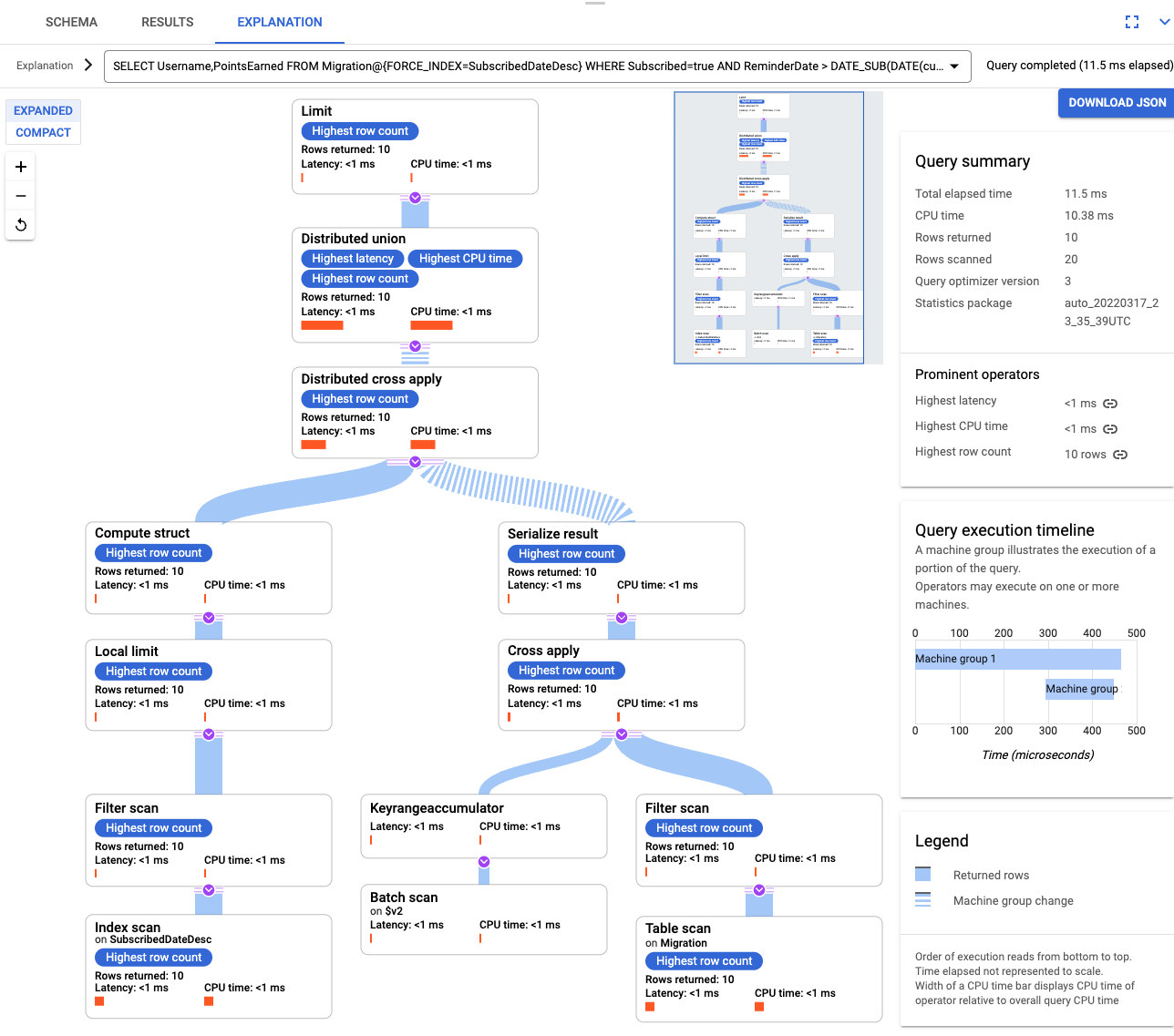
Une fois l'index créé, exécutez à nouveau la requête et ajoutez-le.
SELECT Username,PointsEarned FROM Migration@{FORCE_INDEX=SubscribedDateDesc} WHERE Subscribed=true AND ReminderDate > DATE_SUB(DATE(current_timestamp()), INTERVAL 14 DAY) ORDER BY ReminderDate DESC LIMIT 10Examinez à nouveau l'explication de la requête. Notez que le nombre de Rows scanned (Lignes analysées) a diminué. Le nombre de Rows returned (Lignes renvoyées) à chaque étape correspond au nombre renvoyé par la requête.
Pour analyser le JSON entrant et compiler des mutations, utilisez GSON. Ajustez la définition JSON pour qu'elle corresponde aux données.
Ajustez la mise en correspondance JSON correspondante.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Supprimez la table DynamoDB appelée Migration.
- Supprimez le bucket Amazon S3 et la fonction Lambda que vous avez créés au cours des étapes de la migration.
- Enfin, supprimez l'utilisateur AWS IAM créé au cours de ce tutoriel.
- Découvrez comment optimiser le schéma Cloud Spanner.
- Découvrez comment utiliser Dataflow dans des situations plus complexes.
Une fois que vous avez terminé les tâches décrites dans ce document, vous pouvez éviter de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Préparer votre environnement
Dans ce tutoriel, vous exécutez des commandes dans Cloud Shell. Cloud Shell vous donne accès à la ligne de commande dans Google Cloudet inclut la Google Cloud CLI ainsi que d'autres outils dont vous avez besoin pour le développement dans Google Cloud . L'initialisation de Cloud Shell peut prendre quelques minutes.
Configurer l'accès à AWS
Dans ce tutoriel, vous créez et supprimez des tables Amazon DynamoDB, des buckets Amazon S3 et d'autres ressources. Pour accéder à ces ressources, vous devez d'abord créer les autorisations AWS IAM (Identity and Access Management) requises. Vous pouvez utiliser un compte AWS bac à sable ou test pour ne pas affecter les ressources de production du même compte.
Créer un rôle AWS IAM pour AWS Lambda
Dans cette section, vous allez créer un rôle AWS IAM utilisé par AWS Lambda au cours d'une étape ultérieure du tutoriel.
Créer un utilisateur AWS IAM
Procédez comme suit pour créer un utilisateur AWS IAM avec accès automatisé aux ressources AWS, qui sont utilisées tout au long de ce tutoriel.
Configurer l'interface de ligne de commande AWS
Comprendre le modèle de données
La section suivante décrit les similitudes et les différences entre les types de données, les clés et les index d'Amazon DynamoDB et de Spanner.
Types de données
Spanner utilise des types de données GoogleSQL. Le tableau suivant décrit les correspondances entre les types de données d'Amazon DynamoDB et les types de données de Spanner.
| Amazon DynamoDB | Spanner |
|---|---|
| Nombre | Selon la précision ou l'utilisation prévue, peut être mis en correspondance avec INT64, FLOAT64, TIMESTAMP ou DATE. |
| String | String |
| Boolean | BOOL |
| Null | Aucun type explicite. Les colonnes peuvent contenir des valeurs "null". |
| Binary | Bytes |
| Sets | Array |
| Map et list | "Struct" si la structure est cohérente et peut être décrite à l'aide de la syntaxe DDL de la table. |
Clé primaire
Une clé primaire Amazon DynamoDB établit l'unicité. Il peut s'agir d'une clé de hachage ou de la combinaison d'une clé de hachage et d'une clé de plage. Ce tutoriel commence par la démonstration de la migration d'une table Amazon DynamoDB dont la clé primaire est une clé de hachage. Cette clé de hachage devient la clé primaire de la table Spanner. Plus loin, dans la section sur les tables entrelacées, vous modéliserez une situation dans laquelle une table Amazon DynamoDB utilise une clé primaire composée d'une clé de hachage et d'une clé de plage.
Index secondaires
Amazon DynamoDB et Spanner prennent en charge la création d'un index sur un attribut de clé non primaire. Notez tous les index secondaires de la table Amazon DynamoDB afin de pouvoir les créer dans la table Spanner, qui est traitée plus en détail dans une section ultérieure de ce tutoriel.
Exemple de table
Pour faciliter ce tutoriel, vous allez migrer l'exemple de table suivant d'Amazon DynamoDB vers Spanner :
| Amazon DynamoDB | Spanner | |
|---|---|---|
| Nom de la table |
Migration
|
Migration
|
| Clé primaire |
"Username" : String
|
"Username" : STRING(1024)
|
| Type de clé | Hachage | Non disponible |
| Autres champs |
Zipcode: Number
Subscribed: Boolean
ReminderDate: String
PointsEarned: Number
|
Zipcode: INT64
Subscribed: BOOL
ReminderDate: DATE
PointsEarned: INT64
|
Préparer la table Amazon DynamoDB
Dans la section suivante, vous créez une table source Amazon DynamoDB et la remplissez avec des données.
Créer une base de données Spanner
Vous créez une instance Spanner avec la capacité de calcul la plus faible possible : 100 unités de traitement. Cette capacité de calcul est suffisante pour réaliser ce tutoriel. Pour un déploiement en production, reportez-vous à la documentation relative aux instances Spanner pour déterminer la capacité de calcul appropriée afin de répondre aux exigences de performances de la base de données.
Dans cet exemple, vous créez un schéma de table en même temps que la base de données. Il est également possible et courant d'effectuer des mises à jour du schéma après avoir créé la base de données.
Préparer la migration
Les sections suivantes expliquent comment exporter la table source Amazon DynamoDB et définir la réplication Pub/Sub afin de capturer toutes les modifications apportées à la base de données lors de son exportation.
Diffuser les flux en streaming vers Pub/Sub
Vous utilisez une fonction AWS Lambda pour diffuser les modifications de la base de données dans Pub/Sub.
Exporter la table Amazon DynamoDB vers Amazon S3
Effectuer la migration
Maintenant que la livraison Pub/Sub est en place, vous pouvez transférer toutes les modifications apportées à la table après l'exportation.
Copier la table exportée vers Cloud Storage
Importer les données par lot
Répliquer les nouvelles modifications
Une fois la tâche d'importation par lot terminée, vous configurez une tâche de diffusion en continu pour écrire les mises à jour en cours de la table source dans Spanner. Vous vous abonnez aux événements de Pub/Sub et les écrivez dans Spanner.
La fonction Lambda créée est configurée de manière à capturer les modifications apportées à la table source Amazon DynamoDB et à les publier dans Pub/Sub.
La tâche Dataflow exécutée lors de la phase de chargement par lot était un ensemble fini d'entrées, également appelé "ensemble de données limité". Cette tâche Dataflow utilise Pub/Sub comme source de diffusion et est considéré comme illimitée. Pour plus d'informations sur ces deux types de sources, consultez la section PCollections du guide de programmation d'Apache Beam. La tâche Dataflow de cette étape est conçue pour rester active. Elle ne se termine donc pas lorsque vous avez terminé. La tâche Dataflow de diffusion conserve l'état Running (En cours d'exécution), au lieu de Succeeded (Effectuée).
Vérifier la réplication
Apportez des modifications à la table source pour vérifier que les modifications sont répliquées dans la table Spanner.
Utiliser des tables entrelacées
Spanner est compatible avec le concept de tables entrelacées. Il s'agit d'un modèle de conception dans lequel un élément de premier niveau comporte plusieurs éléments imbriqués se rapportant à cet élément de premier niveau, tels qu'un client et ses commandes, ou un joueur et ses scores de jeu. Si la table source Amazon DynamoDB utilise une clé primaire composée d'une clé de hachage et d'une clé de plage, vous pouvez modéliser un schéma de tables entrelacées, comme illustré dans le schéma suivant. Cette structure vous permet d'interroger efficacement la table entrelacée tout en joignant des champs de la table parente.

Appliquer des index secondaires
Il est recommandé d'appliquer des index secondaires aux tables Spanner après le chargement des données. Maintenant que la réplication fonctionne, configurez un index secondaire pour accélérer les requêtes. Comme les tables Spanner, les index secondaires Spanner sont parfaitement cohérents. Ils ne sont pas cohérents à terme, ce qui est courant dans de nombreuses bases de données NoSQL. Cette fonctionnalité peut faciliter la conception de l'application.
Exécutez une requête qui n'utilise aucun index. Recherchez les N premières occurrences, en fonction d'une valeur de colonne particulière. Il s'agit d'une requête courante dans Amazon DynamoDB pour l'efficacité de la base de données.
Index entrelacés
Vous pouvez configurer des index entrelacés dans Spanner. Les index secondaires décrits dans la section précédente se trouvent à la racine de la hiérarchie de la base de données et utilisent les index de la même manière qu'une base de données classique. Un index entrelacé se trouve dans le contexte de sa ligne entrelacée. Consultez les options d'index pour en savoir plus sur les endroits où appliquer les index entrelacés.
Ajuster le modèle de données
Pour adapter la partie migration de ce tutoriel à votre propre situation, modifiez les fichiers source d'Apache Beam. Il est important de ne pas modifier le schéma source pendant la fenêtre de migration réelle au risque de perdre des données.
Au cours des étapes précédentes, vous avez modifié le code source d'Apache Beam pour une importation groupée. Modifiez le code source de la partie diffusion du pipeline de la même manière. Enfin, ajustez les scripts de création de table, les schémas et les index de la base de données cible Spanner.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel ne soient facturées sur votre compte Google Cloud , supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
Supprimer les ressources AWS
Si le compte AWS est utilisé en dehors de ce tutoriel, soyez prudent lorsque vous supprimez les ressources suivantes :