Considerações importantes antes da migração do Aurora para o Cloud SQL para MySQL
A AWS e o Google Cloud da Amazon fornecem serviços de banco de dados MySQL totalmente gerenciados e baseados na nuvem. Os dois provedores de serviços de nuvem têm recursos exclusivos e diferenças nas respectivas configurações padrão. Essas diferenças podem levar a problemas operacionais ou de desempenho inesperados após a migração de um provedor para o outro. Neste artigo, você verá um resumo dos problemas que podem surgir durante essa migração e as soluções recomendadas. O foco será nas migrações de serviços de banco de dados MySQL do Aurora MySQL para o Cloud SQL para MySQL.
Considerações sobre a migração
Conjunto de caracteres: problema de desempenho
O Aurora usa o servidor de conjuntos de caracteres padrão latin1 (até o MySQL v 5.7). Isso é diferente da configuração padrão do Cloud SQL para MySQL para bancos de dados, tabelas, procedimentos armazenados e funções, que são criados com utf8 como o conjunto de caracteres padrão definido durante uma migração. Isso pode resultar em situações que levam a problemas de desempenho.
Por exemplo, um usuário pode acabar em uma situação em que as tabelas são criadas com o conjunto de caracteres latin1, e os procedimentos ou funções armazenados são criados com o conjunto de caracteres utf8 padrão do Cloud SQL. Nesses casos, se o procedimento ou a função armazenada esperar variáveis como parâmetros utf8 e comparar essa variável com o valor da coluna, que está no conjunto de caracteres latin1, isso resultará em problemas de desempenho por causa da comparação de dois conjuntos de caracteres e combinações diferentes.
É possível verificar o conjunto de caracteres das rotinas usando o comando abaixo:
mysql> selecione ROUTINE_NAME, ROUTINE_SCHEMA, CHARACTER_SET_NAME, COLLATION_NAME from information_schema.ROUTINES;
Se você estava usando o conjunto de caracteres padrão no Aurora (até a v 5.7), que é latin1, o conjunto de caracteres padrão deve ser alterado de utf8 para latin1 no Cloud SQL antes de importar os dados.
Outra solução pode ser mudar tudo para utf8. No entanto, nesse caso, os usuários precisam testar o aplicativo e o conjunto de dados completos, já que as alterações no conjunto de caracteres podem resultar em representações inesperadas de dados.
Os usuários podem editar essa configuração na instância do Cloud SQL na seção de sinalização, conforme ilustrado abaixo.
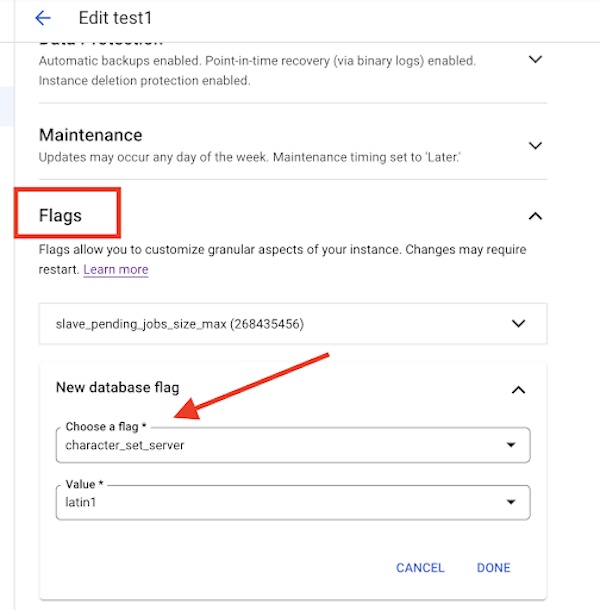
Conjunto de caracteres: problema de incompatibilidade
O Aurora MySQL 5.7 tem muitas compilações, por exemplo, utf8mb4_0900_ai_ci para o conjunto de caracteres utf8mb4, que atualmente estão disponíveis apenas no Cloud SQL para MySQL 8.0. Se você estiver usando essas compilações e importar os dados no Cloud SQL para MySQL 5.7, receberá uma mensagem de erro como "Erro 'O conjunto de caracteres '#255' não é um conjunto de caracteres compilado".
A solução é mudar essas compilações para as que estão disponíveis no MySQL versão 5.7.
Mecanismo de armazenamento: todas as tabelas precisam estar no InnoDB
Ao contrário do Aurora, o Cloud SQL para MySQL não é compatível com o mecanismo MyISAM. É aconselhável converter todas as tabelas em InnoDB antes de iniciar a migração do Aurora para o Cloud SQL.
Se houver uma tabela em um mecanismo diferente do InnoDB, os usuários poderão mudar o mecanismo da tabela usando o comando "ALTER":
mysql> alter table table_1 engine='Innodb' ;
Query OK, 0 rows affected (2.89 sec)
Registros: 0 Cópias: 0 Avisos: 0
Observação: o tempo de consulta depende do tamanho da tabela e pode bloquear outras operações na mesma tabela. Você também pode usar ferramentas de mudanças de esquema on-line, como pt-online-schema-change ou gh-ost para alterar a tabela sem bloquear outras operações.
Endpoints para conexões de leitura
No Aurora, os usuários podem configurar vários leitores em um único endpoint. No entanto, os usuários do Cloud SQL para MySQL não têm esse recurso pronto para uso. Cada réplica de leitura no Cloud SQL para MySQL tem o próprio IP, e os usuários precisam usar algo como o ProxySQL para dividir o tráfego entre várias instâncias de réplica de leitura.
Veja neste guia como usar o ProxySQL para rotear o tráfego entre várias réplicas de leitura.
O Aurora não tem um buffer de alterações
O buffer de alterações é uma estrutura de dados especial que armazena em cache as alterações nas páginas de índice secundárias quando elas não estão no pool de buffers e são mescladas mais tarde quando essas páginas são carregadas no pool por outras operações de leitura. Para saber mais, leia Buffer de alterações.
Para o caso de uso em que a carga de trabalho tem muitas gravações nas tabelas com índices secundários, o Aurora pode ter um desempenho mais lento do que o Cloud SQL para MySQL, que usa o recurso de buffer de alterações do InnoDB padrão para adiar essas atualizações para etapas posteriores. Os usuários precisam comparar o desempenho de acordo com a carga de trabalho do app.
O cache de consultas pode afetar o desempenho
O cache de consultas armazena o comando "select" junto com o resultado em uma camada de armazenamento intermediária. Se uma declaração idêntica for recebida depois, o servidor vai verificar e recuperar os resultados do cache de consulta em vez de executar esse comando novamente. O cache de consultas é compartilhado entre as sessões para que todas as sessões possam se beneficiar dos resultados armazenados em cache com instruções já executadas de outras sessões. Leia mais sobre o cache de consultas.
O Aurora ativa o cache de consultas por padrão. No entanto, a comunidade do MySQL desativou o cache de consultas na versão 5.7 e o removeu completamente na versão 8.0. O Cloud SQL para MySQL também fez o mesmo. Se as consultas dependerem do recurso de cache de consultas do Aurora, o desempenho poderá variar no Cloud SQL para MySQL. É recomendável testar o desempenho das consultas no Cloud SQL para MySQL comparando o tempo de execução com o Aurora.
O mecanismo de replicação pode afetar o desempenho
No caso de réplicas de leitura em uma região, Aurora usa o conceito de volume de cluster, que tem cópias dos dados em três zonas de disponibilidade nessa região. O atraso da replicação no Aurora geralmente é muito menor que 100 milissegundos porque a instância primária e as réplicas no mesmo cluster do banco de dados veem os dados no volume do cluster como um único volume lógico. Além disso, no caso da réplica de leitura entre regiões, o Aurora usa a sincronização de dados baseada em disco entre regiões em vez de replicação baseada em registros binários.
Em resumo, a replicação é processada pela camada de armazenamento no Aurora, enquanto no Cloud SQL para MySQL é usado o mecanismo padrão de replicação de transferência do registro binário para a instância de réplica e, depois, a reprodução desses logs nas instâncias de réplica do MySQL. É possível melhorar o desempenho da replicação configurando a replicação paralela no Cloud SQL. Leia detalhes sobre como configurar a replicação paralela.
O atraso da replicação depende da quantidade de dados alterados pelo aplicativo e pela rede entre as instâncias principal e de réplica, mas a maioria dos aplicativos funciona bem sem um atraso perceptível tanto no Aurora quanto no Cloud SQL para MySQL. No entanto, se a gravação do aplicativo for pesada e ele estiver lendo nas réplicas, sugerimos comparar o atraso de replicação no AWS Aurora e no Cloud SQL para MySQL antes da migração.
Replicação baseada em identificador de transação global (GTID, na sigla em inglês)
O Cloud SQL para MySQL usa a replicação GTID, ao contrário do AWS Aurora, que utiliza a sincronização de dados baseada em disco. Os usuários precisam verificar as limitações do GTID listadas abaixo antes da migração e fazer as alterações necessárias no aplicativo se o fluxo de trabalho do aplicativo depender de um destes recursos:
- As instruções CREATE TABLE ... SELECT não são permitidas ao usar a replicação baseada em GTID.
- As instruções CREATE TEMPORARY TABLE e Drop TEMPORARY TABLE não são compatíveis com transações, procedimentos, funções e gatilhos. É possível usar essas instruções com GTIDs ativados, mas apenas fora de qualquer transação e apenas com autocommit=1.
Para saber mais sobre as limitações baseadas no GTID, consulte Limitações no GTID.
Produtos e serviços relacionados
O Google Cloud oferece um banco de dados MySQL gerenciado para atender às suas necessidades de negócios, desde a desativação de um data center local até a execução de aplicativos SaaS e a migração dos principais sistemas de negócios.
Vá além
Comece a criar no Google Cloud com US$ 300 em créditos e mais de 20 produtos do programa Sempre gratuito.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos


















