MySQL backup and restore
When the unexpected happens, your business can suffer. Hardware failures, database corruption, user mistakes, and even malicious attacks can create risk of data loss. Database backups help you recover and keep your business up and running–even if something goes wrong. And when things are going right, database backups help you meet compliance and audit requirements by letting you restore your database to a specific point in the past.
MySQL supports several options to back up your databases, each with different strengths. You can choose any combination of methods that best suit your needs.
Backup types
There are two main ways to backup a MySQL database: physical and logical. The physical backup copies the actual data files and logical backup generates statements such as CREATE TABLE and INSERT that can recreate the data.
Physical backup
A physical backup contains the raw copies of all of the files and directories as they exist on the disk. This type of backup is suitable for large databases because copying the raw files is much faster compared to taking a logical backup.
Advantages:
- Physical backups are straightforward and efficient; they don’t require much memory or many CPU cycles to run
- Physical backups don’t require any extra work to generate the raw files; all you need to do is simply copy the raw files and directories to the backup location
- Physical backups are faster to restore than logical backups because MySQL doesn’t have to recreate database objects and import the data
Disadvantages:
- Physical backups often take up much more space than logical backups because they contain transaction logs, undo logs, and others, in addition to InnoDB tablespaces (which are shared and per table.ibd files and usually have fragmented space)
- Physical backups aren’t always portable across platforms, operating systems, and MySQL versions
- Since physical backups copy the raw files, if those have any underlying corruption, that would copy to the backup files as well
Some common physical backup tools across the MySQL ecosystem
Logical backup
A logical backup contains the data in the database in a form that MySQL can interpret either as SQL or as delimited text. It is a representation of your database as a sequence of SQL statements that can be executed to recreate database objects and import data. This type of backup is suitable for small databases because logical backups can take substantially longer to restore than restoring a physical backup. This backup type is also useful when migrating to or from managed database services in the cloud.
Advantages:
- Logical backups are very flexible. They offer high granularity on backup and restore operations at the server level (all databases), database level (all tables in a particular database), table level, or even row level (table rows matching given WHERE condition).
- Logical backups are easier to restore—just pipe the backup file to the mysql client and use the LOAD DATA statement or the mysqlimport command to load the text delimited files.
- Logical backups can run remotely from a different machine, which allows you to backup and restore your database across a network. This is very useful for cloud databases such as Google Cloud SQL, Amazon RDS, and Microsoft Azure where users have no direct access to the virtual machine.
- Logical backups help avoid data corruption. Physical backups can be corrupted, which can go unnoticed until verification. Since logical backups are usually text files, it’s easier to review them with a text editor and spot any corruption. Logical backups are rarely corrupted.
- Unlike physical backups, logical backups are highly portable across platforms, operating systems, and MySQL versions.
- Logical backups are highly compressible.
Disadvantages:
- Logical backups are slower to create, as you need to query the MySQL server to obtain the schema and rows, and then convert to a logical format
- Logical backups are also slower to restore, since MySQL needs to execute SQL statements to create the table, import the rows, and rebuild the indexes
- Compared to physical backups, logical backups require more server resources (CPU, RAM, and disk I/O) for backup and restore operations
Some common logical backup tools
Point-in-time recovery (PITR)
As the name suggests, point-in-time recovery helps you recover an instance to a specific point in time. For example, if an error causes a loss of data, you can recover a database to its state before the error occurred.
PITR is a two step process, which relies on binary logs:
- Restore a full physical or logical backup to bring the server to the same state as it was at the time of backup
- Apply the binary logs to replay the changes between the time of backup and desired point in time
Binary logs contain any changes made to the database instance, such as create table, row insert/update/delete, and others. For example, say your daily backups run at 6:00 AM and you want to be able to recover your instance at any point until 10:15 AM. To recover your state at 10:15 AM, you would first restore the full backup from 6:00 AM, and then you would replay the binary log events from 6:00 AM until 10:15 AM. This will bring the server up to the desired state at the desired time.
Binary logs are required for replication and PITR; they are as important as the underlying data. Binary logs need to be backed up in real time for them to be effective in your recovery planning, and you can download them using the mysqlbinlog command.
For example:
mysqlbinlog --host=<hostname> --port=<port> --user=<user> --password=<password> --read-from-remote-server --raw --stop-never <binlog_filename> |
The <binlog_filename> will be the first file to download, and mysqlbinlog will automatically switch to the next file(s) afterward. Those binary logs get written in the current directory of the server which runs the mysqlbinlog command. You can change the file name and location using the --result-file option. You can also use the --stop-never option to enable mysqlbinlog binlog to remain connected to the server and download new changes as they are written.
You can learn more from the mysqlbinlog manual about how to connect to a remote server and download the binary logs as they are written.
Backup and restore in Cloud SQL for MySQL
As Google Cloud’s managed database service for MySQL, Cloud SQL offers automated backups and point-in-time-recovery (PITR) for data protection. These are enabled by default and required for enabling high availability (HA) on a Cloud SQL for MySQL instance.
Any Cloud SQL backup is a type of physical backup, as they are snapshots taken on Persistent Disk (PD). Cloud SQL offers the flexibility to make backups happen automatically, or you can take them on demand at any time. You can still take a logical backup by using the standard MySQL logical backup tools such as mysqldump, mydumper, mysqlpump, and others without interfering with your managed backups.
Let’s dig into how Cloud SQL’s backups work.
Understanding Cloud SQL snapshots
Cloud SQL uses Persistent Disk (PD) for storage, and every Cloud SQL instance has a persistent data disk attached for storing the database files and directories.
Cloud SQL uses PD snapshots for backups, and those snapshots refer to the state of the data disk at a given point in time. The first snapshot of a PD is a full snapshot that contains all the data on the PD, the subsequent snapshots are incremental and only contain any new data or modified data since the previous snapshot. You can think of these snapshots as cloud-managed physical copies of persistent data disks, and they are the basis of all of Cloud SQL’s backup and restore features, including PITR.
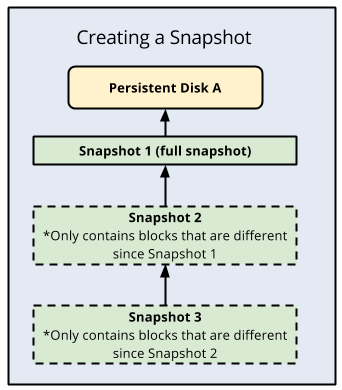
Cloud SQL backups
Cloud SQL performs two types of managed backups: automated, and on demand. Both types are stored in the closest multi-region location to the instance by default. For example, if your Cloud SQL instance is in us-central1, your backups are stored in the US multi-region by default. However, a default location like australia-southeast1 is outside of a multi-region and will be placed in the closest multi-region, which is asia. You can also choose a custom location for your backups.
Automated backups
Automated backups are taken daily during a 4-hour window of your choosing. The backup starts during the backup window and may continue outside the backup window until it completes. You can configure how many automated backups to retain, from 1 to 365. The default retention policy is to retain the seven most recent backups.
On-demand backups
You can also create on-demand backups anytime. These are useful if you need a backup and don’t want to wait for your backup window. Also, unlike automated backups, on-demand backups are not automatically deleted. They persist until you delete them or until their instance is deleted.
Restoring a Cloud SQL backup
You can restore a backup to the same instance where it was taken or to a different instance in the same project. Note that the target instance shouldn’t be a read replica itself, nor it should have read replica(s) at the time of restoring the backup, as read replicas are copies of a primary instance and creates the risk that the replicas would get out of sync with the primary. You can always add read replicas afterward.
Restoring the backup creates a new PD from that backup snapshot and attaches it to the instance. The database starts using the new disk and performs the standard MySQL crash recovery process before coming online as a full-fledged MySQL database freshly restored from the snapshot.
Restore to the same instance
When you restore from a backup to the same instance, you return the data on that instance to its state when you took the backup.
Restore to a different instance
When you restore from a backup to a different instance, you update the data on the target instance to the state of the source instance when you took the backup.
Important: Restoring a backup overwrites all the current data on the target instance, including previous point-in-time recovery logs. Overwritten data cannot be recovered.
Cloud SQL point-in-time recovery (PITR)
In Cloud SQL, PITR always creates a new instance which inherits the settings of the source instance, similar to the clone instance operation. This feature requires both automated backups and point-in-time recovery (binary logs) to be enabled on the source instance. The default retention policy on binary logs is 7 days, and you can configure the retention period to be anywhere from 1 to 7 days.
PITR is achieved by creating a new instance from backup of the original instance and replaying the binary logs stored on the original instance data disk to the given point.
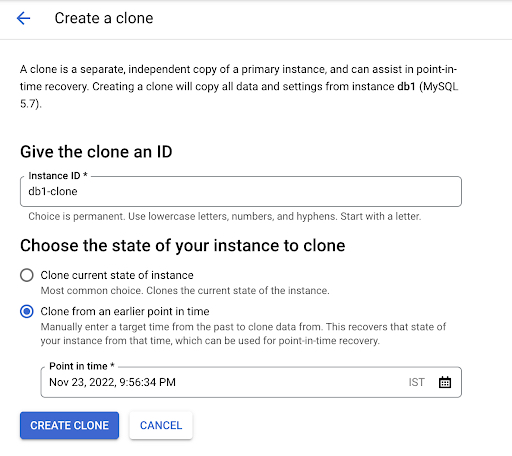
When performing PITR in Cloud SQL, customers can choose to either clone the current state of the instance or clone to a timestamp in the past.
The UI to perform the PITR looks like the following.
Related products and services
Google Cloud offers a managed MySQL database built to suit your business needs, from retiring your on-premises data center, to running SaaS applications, to migrating core business systems.
Take the next step
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Need help getting started?
Contact salesWork with a trusted partner
Find a partnerContinue browsing
See all products


















