Par défaut, l'agent Ops et l'ancien agent Monitoring sont configurés pour collecter des métriques qui capturent des informations sur les processus s'exécutant sur vos machines virtuelles (VM) Compute Engine. Vous pouvez également collecter ces métriques sur des VM Amazon Elastic Compute Cloud (EC2) à l'aide de l'agent Monitoring.
Cet ensemble de métriques, appelé métriques de processus, est identifiable par le préfixe agent.googleapis.com/processes. Ces métriques ne sont pas collectées sur Google Kubernetes Engine (GKE).
À compter du 6 août 2021, des frais seront facturés pour ces métriques, comme décrit dans la section sur les métriques facturables de la page Tarifs de Google Cloud Observability. L'ensemble de métriques de processus est classé comme payante, mais les frais n'ont jamais été mis en œuvre.
Ce document décrit les outils de visualisation des métriques de processus, et explique comment déterminer la quantité de données ingérées à partir de ces métriques et comment réduire les frais associés.
Utiliser des métriques de processus
Vous pouvez visualiser vos données de métriques de processus avec des graphiques créés à l'aide de l'Explorateur de métriques ou de tableaux de bord personnalisés. Pour en savoir plus, consultez la page Utiliser des tableaux de bord et des graphiques. En outre, Cloud Monitoring inclut les données des métriques de processus dans deux tableaux de bord prédéfinis :
- Tableau de bord Instances de VM dans Monitoring
- Tableau de bord Détails de l'instance de VM dans Compute Engine
Les sections suivantes décrivent ces tableaux de bord.
Monitoring : afficher les métriques de processus agrégées
Pour afficher les métriques de processus agrégées dans un champ d'application des métriques, accédez à l'onglet Processus du tableau de bord Instances de VM :
-
Dans la console Google Cloud , accédez à la page
 Tableaux de bord :
Tableaux de bord :
Accéder à la page Tableaux de bord
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
Sélectionnez le tableau de bord VM Instances (Instances de VM) dans la liste.
Cliquez sur Processes (Processus).
La capture d'écran suivante montre un exemple de la page Processes (Processus) de Monitoring :
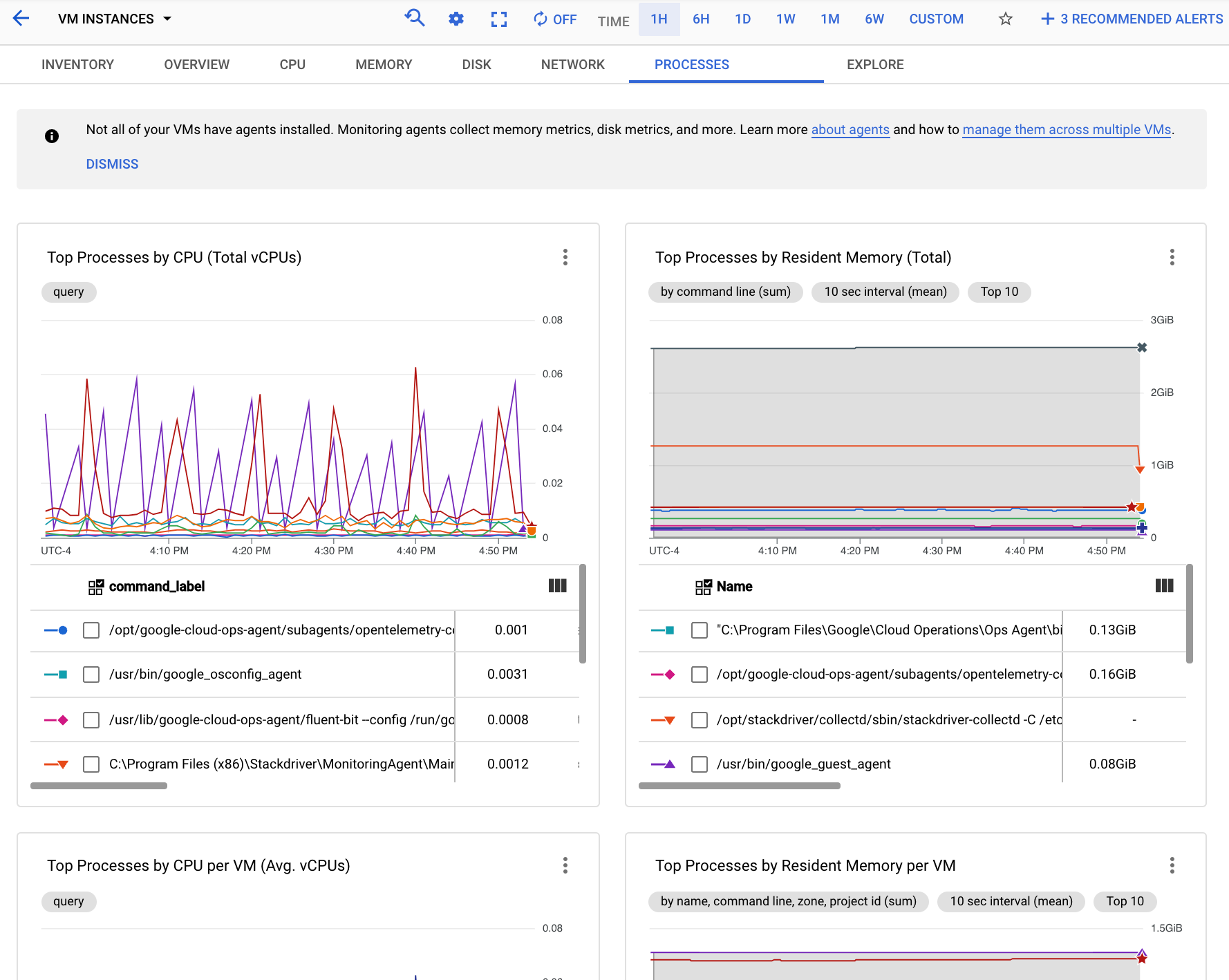
Vous pouvez utiliser les graphiques de l'onglet Processus pour identifier les processus de votre champ d'application de métriques qui consomment le plus de processeurs et de mémoire, et qui utilisent le plus de disque.
Compute Engine : afficher les métriques de performances pour les VM les plus gourmandes en ressources
Pour afficher les graphiques de performances montrant les cinq VM consommant le plus de ressources dans votre projet Google Cloud , accédez à l'onglet Observabilité de vos instances de VM :
-
Dans la console Google Cloud , accédez à la page Instances de VM.
Accéder à la page Instances de VM
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Compute Engine.
- Cliquez sur Observabilité.
La capture d'écran suivante montre un exemple de la page Observability (Observabilité) de Compute Engine.
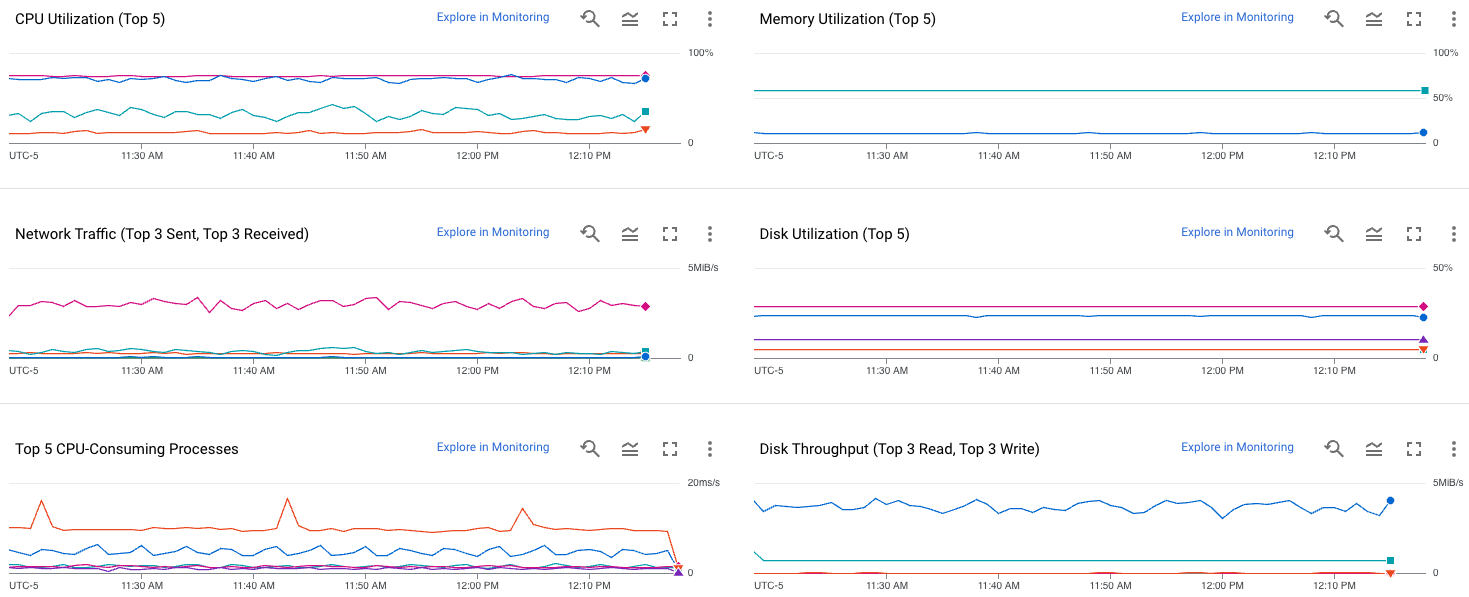
Pour savoir comment utiliser ces métriques afin de diagnostiquer les problèmes liés à vos VM, consultez Résoudre les problèmes de performances des VM.
Compute Engine : Afficher les métriques de processus par VM
Pour afficher la liste des processus exécutés sur une seule machine virtuelle (VM) Compute Engine et des graphiques pour les processus présentant la consommation de ressources la plus élevée, accédez à l'onglet Observabilité de la VM. :
-
Dans la console Google Cloud , accédez à la page Instances de VM.
Accéder à la page Instances de VM
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Compute Engine.
Dans l'onglet Instances, cliquez sur le nom d'une VM à inspecter.
Cliquez sur Observability (Observabilité) pour afficher les métriques de cette VM.
Dans le volet de navigation de l'onglet Observability (Observabilité), sélectionnez Processes (Processus).
La capture d'écran suivante montre un exemple de la page Processes (Processus) de Compute Engine :
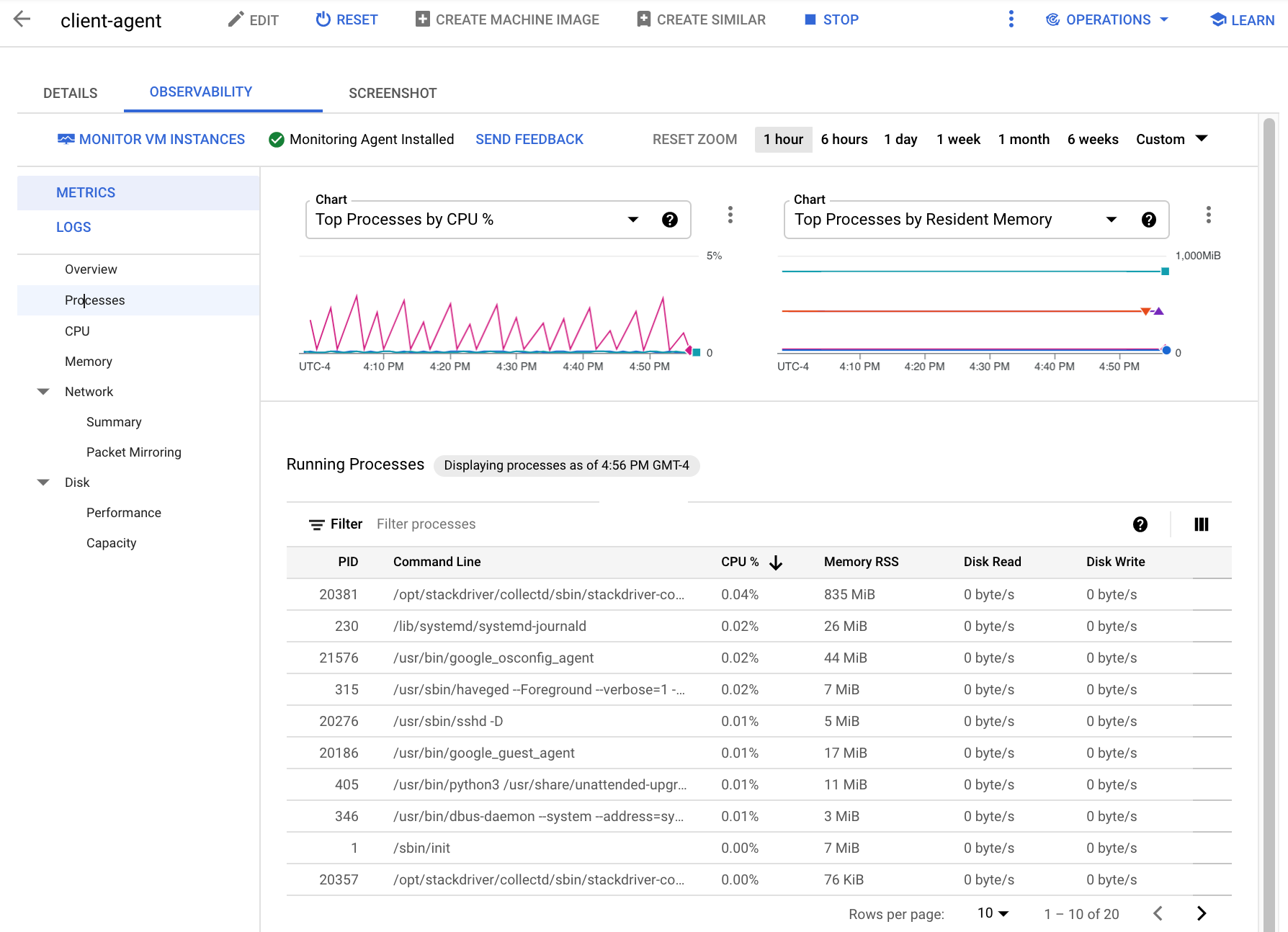
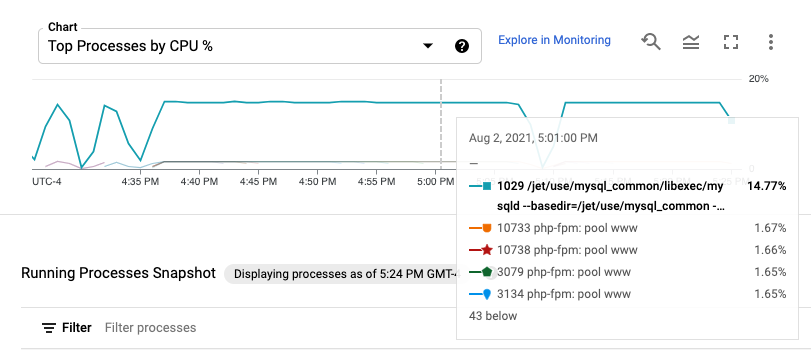
Les métriques de processus sont conservées pendant 24 heures au maximum. Vous pouvez donc les utiliser pour remonter dans le temps et attribuer des anomalies dans la consommation de ressources à des processus spécifiques, ou identifier les utilisateurs de ressources les plus coûteux. Par exemple, le graphique suivant illustre les processus consommant les pourcentages les plus élevés de ressources de processeur. Vous pouvez utiliser le sélecteur de période pour modifier la période du graphique. Le sélecteur de période propose des valeurs prédéfinies, comme la dernière heure, et vous permet également de saisir une période personnalisée.
Le tableau Processus en cours d'exécution fournit une liste de consommation de ressources semblable à la sortie de la commande Linux top.
Par défaut, le tableau affiche un instantané des données les plus récentes.
Toutefois, si vous sélectionnez une période dans un graphique qui se termine dans le passé, le tableau affiche les processus en cours d'exécution à la fin de cette période.
Pour savoir comment utiliser ces métriques afin de diagnostiquer les problèmes liés à vos VM, consultez Résoudre les problèmes de performances des VM.
Traiter les métriques collectées par l'agent
Les agents Linux collectent toutes les métriques répertoriées dans le tableau suivant à partir de processus exécutés sur des VM Compute Engine et, à l'aide de l'agent Monitoring, sur des VM Amazon Elastic Compute Cloud (EC2). Vous pouvez désactiver leur collecte par l'agent Ops (versions 2.0.0 et ultérieures) et par l'ancien agent Monitoring.
Vous pouvez également désactiver la collecte de métriques de processus pour l'agent Ops (versions 2.0.0 et ultérieures) exécuté sur des VM Windows.
Pour plus d'informations, consultez la section Désactiver les métriques de processus.
Si vous souhaitez désactiver la collecte de ces métriques sous Windows, nous vous recommandons de passer à la version 2.0.0 ou ultérieure de l'agent Ops. Pour en savoir plus, consultez la page Installer l'agent Ops.
Tableau des métriques de processus
Les chaînes "Type de métrique" de ce tableau doivent être précédées du préfixe agent.googleapis.com/processes/. Ce préfixe a été omis dans les entrées du tableau.
Lorsque vous interrogez une étiquette, utilisez le préfixe metric.labels. (par exemple, metric.labels.LABEL="VALUE").
| Type de métrique Étape de lancement (Niveaux de la hiérarchie des ressources) Nom à afficher |
|
|---|---|
| Genre, type, unité Ressources surveillées |
Description Libellés |
count_by_state
GA
(projet)
Processus |
|
GAUGE, DOUBLE, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Nombre de processus dans l'état donné. Linux uniquement. Échantillonné toutes les 60 secondes.
state : En marche, en sommeil, en zombie, etc.
|
cpu_time
GA
(projet)
CPU du processus |
|
CUMULATIVE, INT64, us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Temps CPU du processus donné. Échantillonné toutes les 60 secondes.
process : nom du processus.
user_or_syst : indique si c'est un processus utilisateur ou système.
command : commande du processus.
command_line : ligne de commande de processus, 1 024 caractères maximum.
owner: Propriétaire du processus.
pid : ID du processus
|
disk/read_bytes_count
GA
(projet)
E/S de lecture des disques de processus |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
E/S de lecture du disque de processus. Linux uniquement. Échantillonné toutes les 60 secondes.
process : nom du processus.
command : commande du processus.
command_line : la ligne de commande du processus (1 024 caractères maximum).
owner: Propriétaire du processus.
pid : ID du processus
|
disk/write_bytes_count
GA
(projet)
E/S d'écriture des disques de processus |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
E/S d'écriture du disque de processus Linux uniquement. Échantillonné toutes les 60 secondes.
process : nom du processus.
command : commande du processus.
command_line : la ligne de commande du processus (1 024 caractères maximum).
owner: Propriétaire du processus.
pid : ID du processus
|
fork_count
GA
(projet)
Nombre de duplications |
|
CUMULATIVE, INT64, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Nombre total de processus dupliqués. Linux uniquement. Échantillonné toutes les 60 secondes. |
rss_usage
GA
(projet)
Mémoire résidente du processus |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Utilisation de la mémoire résidente du processus donné. Linux uniquement. Échantillonné toutes les 60 secondes.
process : nom du processus.
command : commande du processus.
command_line : la ligne de commande du processus (1 024 caractères maximum).
owner: Propriétaire du processus.
pid : ID du processus
|
vm_usage
GA
(projet)
Mémoire virtuelle du processus |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Utilisation de la VM du processus donné. Échantillonné toutes les 60 secondes.
process : nom du processus.
command : commande du processus.
command_line : la ligne de commande du processus (1 024 caractères maximum).
owner: Propriétaire du processus.
pid : ID du processus
|
Tableau généré le 08-08-2025 à 23:40:45 UTC.
Déterminer l'ingestion actuelle
Vous pouvez utiliser l'explorateur de métriques pour connaître la quantité de données que vous ingérez pour les métriques de processus. Procédez comme suit:
-
Dans la console Google Cloud , accédez à la page leaderboard Explorateur de métriques :
Accéder à l'explorateur de métriques
Si vous utilisez la barre de recherche pour trouver cette page, sélectionnez le résultat dont le sous-titre est Monitoring.
Dans la barre d'outils du volet de création de requêtes, sélectionnez le bouton nommé code MQL ou code PromQL.
Vérifiez que MQL est sélectionné dans le bouton d'activation Langage. Le bouton de langage se trouve dans la barre d'outils qui vous permet de mettre en forme votre requête.
Pour afficher le nombre total de points de métriques de processus pour vos ressources
gce_instanceetaws_ec2_instance, procédez comme suit:Saisissez la requête suivante :
def tagged_process_metric name = metric 'agent.googleapis.com/processes/'$name | add [metric_suffix: $name]; def process_metrics resource_type = fetch $resource_type | { @tagged_process_metric 'cpu_time' ; @tagged_process_metric 'disk/read_bytes_count' ; @tagged_process_metric 'disk/write_bytes_count' ; @tagged_process_metric 'rss_usage' ; @tagged_process_metric 'vm_usage' ; @tagged_process_metric 'count_by_state' ; @tagged_process_metric 'fork_count' } | within 1d | group_by [metric_suffix], 1m, [row_count: row_count()] | union; { @process_metrics 'gce_instance' ; @process_metrics 'aws_ec2_instance' } | outer_join 0, 0 | { rename [], [out: val(0)] | add [resource_type: 'gce_instance'] ; rename [], [out: val(1)] | add [resource_type: 'aws_ec2_instance'] } | union | group_by drop[metric_suffix], 1d, .sumCliquez sur Exécuter la requête (Run Query). Le graphique obtenu indique les valeurs de chaque type de ressource.
Estimer le coût des métriques
Les exemples de tarification Monitoring vous montrent comment estimer le coût d'ingestion de métriques. Ces exemples peuvent être appliqués aux métriques de processus.
Toutes les métriques de processus sont échantillonnées toutes les 60 secondes. Elles écrivent toutes des points de données comptabilisés comme huit octets à des fins de tarification.
La tarification des métriques de processus est définie sur 5% du coût du volume standard utilisé dans les exemples de tarification. Par conséquent, si vous supposez que toutes les métriques des scénarios décrits dans ces exemples sont des métriques de processus, vous pouvez alors utiliser 5% du coût total pour chaque scénario comme estimation du coût de métriques du processus.
Désactiver la collecte des métriques de processus
Il existe plusieurs façons de désactiver la collecte de ces métriques par l'agent Ops (versions 2.0.0 et ultérieures) et par l'ancien agent Monitoring sous Linux.
Les agents ne s'exécutent que sur les VM Compute Engine et, pour l'agent Monitoring, sur les VM Amazon Elastic Compute Cloud (EC2). Ces procédures ne s'appliquent qu'à ces plates-formes.
Vous ne pouvez pas désactiver la collecte par l'agent Ops si vous exécutez des versions antérieures à la version 2.0.0 ou l'ancien agent Monitoring sous Windows. Si vous souhaitez désactiver la collecte de ces métriques sous Windows, nous vous recommandons de passer à la version 2.0.0 ou ultérieure de l'agent Ops. Pour en savoir plus, consultez la page Installer l'agent Ops.
La procédure générale se présente comme suit :
Connectez-vous à la VM.
Créez une copie du fichier de configuration existant en tant que sauvegarde. Stockez la copie de sauvegarde en dehors du répertoire de configuration de l'agent afin que celui-ci ne tente pas de charger les deux fichiers. Par exemple, la commande suivante crée une copie du fichier de configuration pour l'agent Monitoring sous Linux :
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
Modifiez la configuration à l'aide de l'une des options décrites dans les éléments suivants :
Redémarrez l'agent pour récupérer la nouvelle configuration:
- Agent Monitoring :
sudo service stackdriver-agent restart - Agent Ops :
sudo service google-cloud-ops-agent restart
- Agent Monitoring :
Vérifiez que les métriques de processus ne sont plus collectées pour cette VM:
Sélectionnez l'Explorateur de métriques.
Cliquez sur MQL.
Pour une ressource
gce_instance, saisissez la requête suivante, en remplaçant VM_NAME par le nom de cette VM:fetch gce_instance | metric 'agent.googleapis.com/processes/cpu_time' | filter (metadata.system_labels.name == 'VM_NAME') | align rate(1m) | every 1m
Pour une ressource
aws_ec2_instance, remplacezgce_instancedans la requête.Cliquez sur Exécuter la requête (Run Query).
Agent Ops sous Linux ou Windows
L'emplacement du fichier de configuration pour l'agent Ops dépend du système d'exploitation :
- Pour Linux :
/etc/google-cloud-ops-agent/config.yaml - Pour Windows :
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
Pour désactiver la collecte de toutes les métriques de processus par l'agent Ops, ajoutez les éléments suivants à votre fichier config.yaml :
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
Cela exclut les métriques de processus de la collecte dans le processeur metrics_filter qui s'applique au pipeline par défaut du service metrics.
Pour en savoir plus sur les options de configuration de l'agent Ops, consultez la section Configurer l'agent Ops.
Agent Monitoring sous Linux
Vous disposez des options suivantes pour désactiver la collecte de métriques de processus avec l'ancien agent Monitoring:
Les sections suivantes décrivent chaque option et répertorient les avantages et les risques qui lui sont associés.
Modifier le fichier de configuration de l'agent
Avec cette option, vous modifiez directement le fichier de configuration principal de l'agent, /etc/stackdriver/collectd.conf, pour supprimer les sections qui permettent de collecter les métriques de processus.
Procédure
Il existe trois groupes de suppressions que vous devez effectuer sur le fichier collectd.conf:
Supprimez la directive
LoadPluginet la configuration du plug-in suivante:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>Supprimez la directive
PostCacheChainsuivante et la configuration de la chaînePostCache:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>Supprimez la chaîne
MaybeThrottleProcessesutilisée par la chaînePostCache:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
Avantages et risques
- Avantages
- Vous réduisez les ressources consommées par l'agent, car les métriques ne sont jamais collectées.
- Si vous avez apporté d'autres modifications à votre fichier
collectd.conf, vous pouvez facilement les conserver.
- Risques
- Vous devez utiliser le compte
rootpour modifier ce fichier de configuration. - Vous risquez d'introduire des erreurs typographiques dans le fichier.
- Vous devez utiliser le compte
Remplacer le fichier de configuration de l'agent
Cette option vous permet de remplacer le fichier de configuration principal de l'agent par une version prédéfinie avec les sections pertinentes supprimées pour vous.
Procédure
Téléchargez le fichier prédéfini
collectd-no-process-metrics.conf, du dépôt GitHub vers le répertoire/tmp, puis procédez comme suit:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.confRemplacez le fichier
collectd.confexistant par le fichier prédéfini :cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
Avantages et risques
- Avantages
- Vous réduisez les ressources consommées par l'agent, car les métriques ne sont jamais collectées.
- Vous n'avez pas besoin de modifier manuellement le fichier en tant que
root. - Les outils de gestion de la configuration peuvent facilement remplacer un fichier.
- Risques
- Si vous avez apporté d'autres modifications au fichier
collectd.conf, vous devez les fusionner dans le fichier de remplacement.
- Si vous avez apporté d'autres modifications au fichier
Dépannage
Les procédures décrites dans ce document sont des modifications de la configuration de l'agent. Les problèmes suivants se produiront donc probablement :
- Droits insuffisants pour modifier les fichiers de configuration. Les fichiers de configuration doivent être modifiés à partir du compte
root. - Présentation des erreurs typographiques dans le fichier de configuration, si vous le modifiez directement
Pour en savoir plus sur la résolution d'autres problèmes, consultez la section Dépanner l'agent Monitoring.
Agent Monitoring sous Windows
Vous ne pouvez pas désactiver la collecte de métriques de processus par l'ancien agent Monitoring exécuté sur les VM Windows. Cet agent n'est pas configurable. Si vous souhaitez désactiver la collecte de ces métriques sous Windows, nous vous recommandons de passer à la version 2.0.0 ou ultérieure de l'agent Ops. Pour en savoir plus, consultez la page Installer l'agent Ops.
Si vous exécutez l'agent Ops, consultez la section Agent Ops sous Linux ou Windows.