Vous ne pouvez utiliser le cache de données qu'avec les clusters GKE Standard. Ce guide vous explique comment activer GKE Data Cache lorsque vous créez un cluster GKE Standard ou un pool de nœuds, et comment provisionner des disques associés à GKE avec l'accélération Data Cache.
À propos de GKE Data Cache
Avec GKE Data Cache, vous pouvez utiliser des disques SSD locaux sur vos nœuds GKE comme couche de cache pour votre stockage persistant, comme les disques persistants ou les hyperdisques. L'utilisation de disques SSD locaux réduit la latence de lecture des disques et augmente les requêtes par seconde (RPS) pour vos charges de travail avec état, tout en minimisant les besoins en mémoire. GKE Data Cache est compatible avec tous les types de Persistent Disk ou d'Hyperdisk en tant que disques sous-jacents.
Pour utiliser le cache de données GKE pour votre application, configurez votre pool de nœuds GKE avec des disques SSD locaux associés. Vous pouvez configurer GKE Data Cache pour qu'il utilise tout ou partie du disque SSD local associé. Les SSD locaux utilisés par la solution GKE Data Cache sont chiffrés au repos à l'aide du chiffrement standard Google Cloud .
Avantages
GKE Data Cache offre les avantages suivants :
- Augmentation du nombre de requêtes traitées par seconde pour les bases de données conventionnelles, comme MySQL ou Postgres, et les bases de données vectorielles.
- Amélioration des performances de lecture pour les applications avec état en minimisant la latence du disque.
- L'hydratation et la réhydratation des données sont plus rapides, car les SSD sont locaux au nœud. L'hydratation des données désigne le processus initial de chargement des données nécessaires à partir du stockage persistant sur le SSD local. La réhydratation des données désigne le processus de restauration des données sur les disques SSD locaux après le recyclage d'un nœud.
Architecture de déploiement
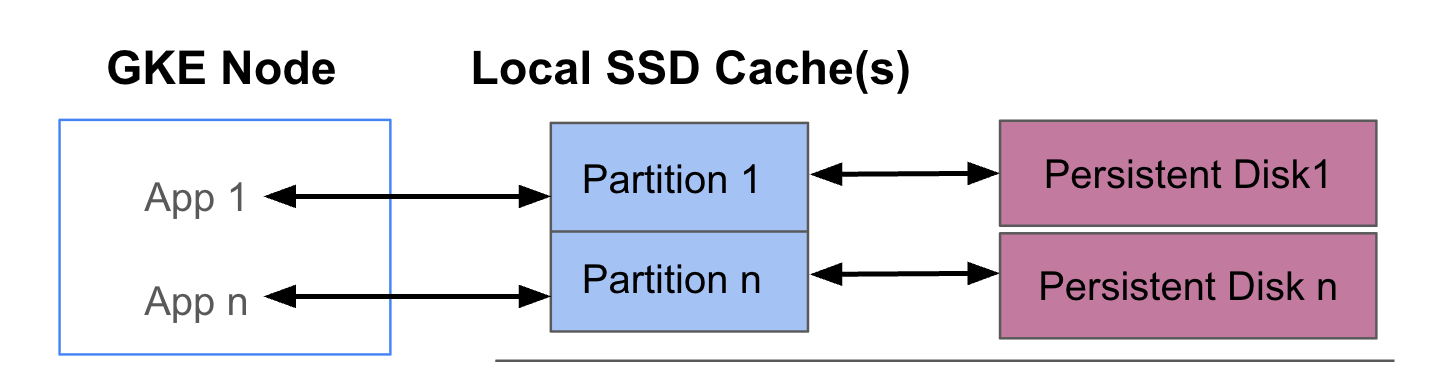
Le schéma suivant montre un exemple de configuration GKE Data Cache avec deux pods exécutant chacun une application. Les pods s'exécutent sur le même nœud GKE. Chaque pod utilise un disque SSD local distinct et un disque persistant de sauvegarde.
Modes de déploiement
Vous pouvez configurer GKE Data Cache de deux manières :
- Écriture différée (recommandé) : lorsque votre application écrit des données, celles-ci sont écrites de manière synchrone dans le cache et sur le disque persistant sous-jacent. Le mode
writethroughempêche la perte de données et convient à la plupart des charges de travail de production. - Écriture différée : lorsque votre application écrit des données, elles ne sont écrites que dans le cache. Les données sont ensuite écrites sur le disque persistant de manière asynchrone (en arrière-plan). Le mode
writebackaméliore les performances d'écriture et convient aux charges de travail qui dépendent de la vitesse. Toutefois, ce mode affecte la fiabilité. Si le nœud s'arrête de manière inattendue, les données du cache non vidées seront perdues.
Objectifs
Dans ce guide, vous allez apprendre à :
- Créez une infrastructure GKE sous-jacente pour utiliser GKE Data Cache.
- Créez un pool de nœuds dédié avec des disques SSD locaux associés.
- Créez une StorageClass pour provisionner dynamiquement un PersistentVolume (PV) lorsqu'un pod le demande via un PersistentVolumeClaim (PVC).
- Créez un PVC pour demander un PV.
- Créez un déploiement qui utilise un PVC pour vous assurer que votre application a accès au stockage persistant même après le redémarrage d'un pod et lors de la replanification.
Exigences et planification
Assurez-vous de remplir les conditions suivantes pour utiliser GKE Data Cache :
- Votre cluster GKE doit exécuter la version 1.32.3-gke.1440000 ou ultérieure.
- Vos pools de nœuds doivent utiliser des types de machines compatibles avec les SSD locaux. Pour en savoir plus, consultez Assistance pour les séries de machines.
Planifier
Tenez compte des aspects suivants lorsque vous planifiez la capacité de stockage pour le cache de données GKE :
- Nombre maximal de pods par nœud qui utiliseront le cache de données GKE simultanément.
- Exigences concernant la taille du cache des pods qui utiliseront GKE Data Cache.
- Capacité totale des disques SSD locaux disponibles sur vos nœuds GKE. Pour savoir quels types de machines sont associés à des SSD locaux par défaut et quels types de machines nécessitent que vous associiez des SSD locaux, consultez Choisir un nombre valide de disques SSD locaux.
- Pour les types de machines de troisième génération ou ultérieurs (qui ont un nombre par défaut de disques SSD locaux associés), notez que les disques SSD locaux pour le cache de données sont réservés sur le nombre total de disques SSD locaux disponibles sur cette machine.
- La surcharge du système de fichiers peut réduire l'espace utilisable sur les disques SSD locaux. Par exemple, même si vous disposez d'un nœud doté de deux SSD locaux d'une capacité brute totale de 750 Gio, l'espace disponible pour tous les volumes de cache de données peut être inférieur en raison de la surcharge du système de fichiers. Une certaine capacité des disques SSD locaux est réservée à un usage système.
Limites
Incompatibilité avec Sauvegarde pour GKE
Pour préserver l'intégrité des données dans des scénarios tels que la reprise après sinistre ou la migration d'applications, vous devrez peut-être sauvegarder et restaurer vos données. Si vous utilisez Sauvegarde pour GKE pour restaurer un PVC configuré pour utiliser le cache de données, le processus de restauration échoue. Cet échec se produit, car le processus de restauration ne propage pas correctement les paramètres de cache de données nécessaires à partir de la StorageClass d'origine.
Tarifs
La capacité totale provisionnée de vos disques SSD locaux et des disques persistants associés vous est facturée. Vous êtes facturé par Gio et par mois.
Pour en savoir plus, consultez la section Tarifs des disques dans la documentation Compute Engine.
Avant de commencer
Avant de commencer, effectuez les tâches suivantes :
- Activez l'API Google Kubernetes Engine. Activer l'API Google Kubernetes Engine
- Si vous souhaitez utiliser Google Cloud CLI pour cette tâche, installez puis initialisez gcloud CLI. Si vous avez déjà installé la gcloud CLI, obtenez la dernière version en exécutant la commande
gcloud components update. Il est possible que les versions antérieures de gcloud CLI ne permettent pas d'exécuter les commandes de ce document.
- Consultez les types de machines compatibles avec les SSD locaux pour votre pool de nœuds.
Configurer les nœuds GKE pour utiliser le cache de données
Pour commencer à utiliser GKE Data Cache pour accélérer le stockage, vos nœuds doivent disposer des ressources SSD locales nécessaires. Cette section présente des commandes permettant de provisionner des SSD locaux et d'activer GKE Data Cache lorsque vous créez un cluster GKE ou ajoutez un pool de nœuds à un cluster existant. Vous ne pouvez pas mettre à jour un pool de nœuds existant pour utiliser le cache de données. Si vous souhaitez utiliser le cache de données sur un cluster existant, ajoutez-y un pool de nœuds.
Sur un nouveau cluster
Pour créer un cluster GKE avec le cache de données configuré, utilisez la commande suivante :
gcloud container clusters create CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Remplacez les éléments suivants :
CLUSTER_NAME: nom du cluster. Attribuez un nom unique au cluster GKE que vous créez.LOCATION: région ou zone Google Cloud du nouveau cluster.MACHINE_TYPE: type de machine à utiliser à partir d'une série de machines de deuxième, troisième ou génération ultérieure pour votre cluster, par exemplen2-standard-2ouc3-standard-4-lssd. Ce champ est obligatoire, car le disque SSD local ne peut pas être utilisé avec le typee2-mediumpar défaut. Pour en savoir plus, consultez les séries de machines disponibles.DATA_CACHE_COUNT: nombre de volumes SSD locaux à dédier exclusivement au cache de données sur chaque nœud du pool de nœuds par défaut. Chacun de ces disques SSD locaux a une capacité de 375 Gio. Le nombre maximal de volumes varie selon le type de machine et la région. Notez qu'une certaine capacité des disques SSD locaux est réservée à un usage système.(Facultatif)
LOCAL_SSD_COUNT: nombre de volumes SSD locaux à provisionner pour d'autres besoins de stockage éphémère. Utilisez l'option--ephemeral-storage-local-ssd countsi vous souhaitez provisionner des disques SSD locaux supplémentaires qui ne sont pas utilisés pour le cache de données.Notez les points suivants pour les types de machines de troisième génération ou ultérieurs :
- Les types de machines de troisième génération ou ultérieure sont associés par défaut à un nombre spécifique de SSD locaux. Le nombre de disques SSD locaux associés à chaque nœud dépend du type de machine que vous spécifiez.
- Si vous prévoyez d'utiliser l'indicateur
--ephemeral-storage-local-ssd countpour un stockage éphémère supplémentaire, assurez-vous de définir la valeur deDATA_CACHE_COUNTsur un nombre inférieur au nombre total de disques SSD locaux disponibles sur la machine. Le nombre total de SSD locaux disponibles inclut les disques associés par défaut et tous les nouveaux disques que vous ajoutez à l'aide de l'indicateur--ephemeral-storage-local-ssd count.
Cette commande crée un cluster GKE qui s'exécute sur un type de machine de deuxième, troisième ou génération ultérieure pour son pool de nœuds par défaut, provisionne des SSD locaux pour le cache de données et, si spécifié, provisionne éventuellement des SSD locaux supplémentaires pour d'autres besoins de stockage éphémère.
Ces paramètres ne s'appliquent qu'au pool de nœuds par défaut.
Sur un cluster existant
Pour utiliser le cache de données sur un cluster existant, vous devez créer un pool de nœuds avec le cache de données configuré.
Pour créer un pool de nœuds GKE avec le cache de données configuré, utilisez la commande suivante :
gcloud container node-pool create NODE_POOL_NAME \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--machine-type=MACHINE_TYPE \
--data-cache-count=DATA_CACHE_COUNT \
# Optionally specify additional Local SSDs, or skip this flag
--ephemeral-storage-local-ssd count=LOCAL_SSD_COUNT
Remplacez les éléments suivants :
NODE_POOL_NAME: nom du pool de nœuds. Attribuez un nom unique au pool de nœuds que vous créez.CLUSTER_NAME: nom d'un cluster GKE existant dans lequel vous souhaitez créer le pool de nœuds.LOCATION: la même région ou zone Google Cloud que votre cluster.MACHINE_TYPE: type de machine à utiliser à partir d'une série de machines de deuxième, troisième ou génération ultérieure pour votre cluster, par exemplen2-standard-2ouc3-standard-4-lssd. Ce champ est obligatoire, car le disque SSD local ne peut pas être utilisé avec le typee2-mediumpar défaut. Pour en savoir plus, consultez les séries de machines disponibles.DATA_CACHE_COUNT: nombre de volumes SSD locaux à dédier exclusivement au cache de données sur chaque nœud du pool de nœuds. Chacun de ces disques SSD locaux a une capacité de 375 Gio. Le nombre maximal de volumes varie selon le type de machine et la région. Notez qu'une certaine capacité des disques SSD locaux est réservée à un usage système.(Facultatif)
LOCAL_SSD_COUNT: nombre de volumes SSD locaux à provisionner pour d'autres besoins de stockage éphémère. Utilisez l'option--ephemeral-storage-local-ssd countsi vous souhaitez provisionner des disques SSD locaux supplémentaires qui ne sont pas utilisés pour le cache de données.Notez les points suivants pour les types de machines de troisième génération ou ultérieurs :
- Les types de machines de troisième génération ou ultérieure sont associés par défaut à un nombre spécifique de SSD locaux. Le nombre de disques SSD locaux associés à chaque nœud dépend du type de machine que vous spécifiez.
- Si vous prévoyez d'utiliser l'indicateur
--ephemeral-storage-local-ssd countpour un stockage éphémère supplémentaire, assurez-vous de définirDATA_CACHE_COUNTsur less (moins) que le total des disques SSD locaux disponibles sur la machine. Le nombre total de SSD locaux disponibles inclut les disques associés par défaut et tous les nouveaux disques que vous ajoutez à l'aide de l'indicateur--ephemeral-storage-local-ssd count.
Cette commande crée un pool de nœuds GKE qui s'exécute sur un type de machine de deuxième, troisième ou génération ultérieure, provisionne des SSD locaux pour le cache de données et, si spécifié, provisionne éventuellement des SSD locaux supplémentaires pour d'autres besoins de stockage éphémère.
Provisionner le cache de données pour le stockage persistant sur GKE
Cette section fournit un exemple d'activation des avantages en termes de performances du cache de données GKE pour vos applications avec état.
Créer un pool de nœuds avec des disques SSD locaux pour le cache de données
Commencez par créer un pool de nœuds avec des disques SSD locaux associés dans votre cluster GKE. GKE Data Cache utilise les disques SSD locaux pour accélérer les performances des disques persistants associés.
La commande suivante crée un pool de nœuds qui utilise une machine de deuxième génération, n2-standard-2 :
gcloud container node-pools create datacache-node-pool \
--cluster=CLUSTER_NAME \
--location=LOCATION \
--num-nodes=2 \
--data-cache-count=1 \
--machine-type=n2-standard-2
Remplacez les éléments suivants :
CLUSTER_NAME: nom du cluster. Spécifiez le cluster GKE dans lequel vous créez le pool de nœuds.LOCATION: la même région ou zone Google Cloud que votre cluster.
Cette commande crée un pool de nœuds avec les spécifications suivantes :
--num-nodes=2: définit le nombre initial de nœuds dans ce pool sur deux.--data-cache-count=1: spécifie un SSD local par nœud dédié à GKE Data Cache.
Le nombre total de SSD locaux provisionnés pour ce pool de nœuds est de deux, car chaque nœud est provisionné avec un SSD local.
Créer une StorageClass de cache de données
Créez un StorageClass Kubernetes qui indique à GKE comment provisionner dynamiquement un volume persistant utilisant le cache de données.
Utilisez le manifeste suivant pour créer et appliquer un StorageClass nommé pd-balanced-data-cache-sc :
kubectl apply -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pd-balanced-data-cache-sc
provisioner: pd.csi.storage.gke.io
parameters:
type: pd-balanced
data-cache-mode: writethrough
data-cache-size: "100Gi"
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
EOF
Les paramètres StorageClass pour le cache de données incluent les suivants :
type: spécifie le type de disque sous-jacent pour le volume persistant. Pour plus d'options, consultez les types de disques persistants ou les types d'Hyperdisques acceptés.data-cache-mode: utilise le modewritethroughrecommandé. Pour en savoir plus, consultez Modes de déploiement.data-cache-size: définit la capacité du SSD local sur 100 Gio, qui est utilisé comme cache de lecture pour chaque PVC.
Demander un espace de stockage avec un PersistentVolumeClaim (PVC)
Créez un PVC qui référence la StorageClass pd-balanced-data-cache-sc que vous avez créée. La PVC demande un volume persistant avec le cache de données activé.
Utilisez le fichier manifeste suivant pour créer un PVC nommé pvc-data-cache qui demande un volume persistant d'au moins 300 Gio avec un accès ReadWriteOnce.
kubectl apply -f - <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-data-cache
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 300Gi
storageClassName: pd-balanced-data-cache-sc
EOF
Créer un déploiement qui utilise le PVC
Créez un déploiement nommé postgres-data-cache qui exécute un pod utilisant le PVC pvc-data-cache que vous avez créé précédemment. Le sélecteur de nœuds cloud.google.com/gke-data-cache-count garantit que le pod est planifié sur un nœud disposant des ressources SSD locales nécessaires à l'utilisation du cache de données GKE.
Créez et appliquez le fichier manifeste suivant pour configurer un pod qui déploie un serveur Web Postgres à l'aide du PVC :
kubectl apply -f - <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres-data-cache
labels:
name: database
app: data-cache
spec:
replicas: 1
selector:
matchLabels:
service: postgres
app: data-cache
template:
metadata:
labels:
service: postgres
app: data-cache
spec:
nodeSelector:
cloud.google.com/gke-data-cache-disk: "1"
containers:
- name: postgres
image: postgres:14-alpine
volumeMounts:
- name: pvc-data-cache-vol
mountPath: /var/lib/postgresql/data2
subPath: postgres
env:
- name: POSTGRES_USER
value: admin
- name: POSTGRES_PASSWORD
value: password
restartPolicy: Always
volumes:
- name: pvc-data-cache-vol
persistentVolumeClaim:
claimName: pvc-data-cache
EOF
Vérifiez que le déploiement a bien été créé :
kubectl get deployment
Le provisionnement du conteneur Postgres peut prendre quelques minutes et afficher l'état READY.
Vérifier le provisionnement du cache de données
Une fois votre déploiement créé, vérifiez que le stockage persistant avec cache de données est correctement provisionné.
Pour vérifier que votre
pvc-data-cacheest correctement lié à un volume persistant, exécutez la commande suivante :kubectl get pvc pvc-data-cacheLe résultat ressemble à ce qui suit :
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE pvc-data-cache Bound pvc-e9238a16-437e-45d7-ad41-410c400ae018 300Gi RWO pd-balanced-data-cache-sc <unset> 10mPour vérifier que le groupe Logical Volume Manager (LVM) pour le cache de données a été créé sur le nœud, procédez comme suit :
Obtenez le nom du pod du pilote PDCSI sur ce nœud :
NODE_NAME=$(kubectl get pod --output json | jq '.items[0].spec.nodeName' | sed 's/\"//g') kubectl get po -n kube-system -o wide | grep ^pdcsi-node | grep $NODE_NAMEDans le résultat, copiez le nom du pod
pdcsi-node.Affichez les journaux du pilote PDCSI pour la création du groupe LVM :
PDCSI_POD_NAME="PDCSI-NODE_POD_NAME" kubectl logs -n kube-system $PDCSI_POD_NAME gce-pd-driver | grep "Volume group creation"Remplacez
PDCSI-NODE_POD_NAMEpar le nom réel du pod que vous avez copié à l'étape précédente.Le résultat ressemble à ce qui suit :
Volume group creation succeeded for LVM_GROUP_NAME
Ce message confirme que la configuration LVM du cache de données est correctement configurée sur le nœud.
Effectuer un nettoyage
Pour éviter que des frais ne soient facturés sur votre compte Google Cloud , supprimez les ressources de stockage que vous avez créées dans ce guide.
Supprimez le déploiement.
kubectl delete deployment postgres-data-cacheSupprimez le PersistentVolumeClaim.
kubectl delete pvc pvc-data-cacheSupprimez le pool de nœuds.
gcloud container node-pools delete datacache-node-pool \ --cluster CLUSTER_NAMERemplacez
CLUSTER_NAMEpar le nom du cluster dans lequel vous avez créé le pool de nœuds qui utilise le cache de données.
Étapes suivantes
- Consultez Résoudre les problèmes de stockage dans GKE.
- En savoir plus sur le pilote CSI Persistent Disk sur GitHub.