En esta página se describe cómo funciona Cloud TPU con Google Kubernetes Engine (GKE), incluida la terminología, las ventajas de las unidades de procesamiento de tensor (TPUs) y las consideraciones sobre la programación de cargas de trabajo. Las TPUs son circuitos integrados para aplicaciones específicas (ASIC) desarrollados a medida por Google que agilizan las cargas de trabajo de aprendizaje automático que usan frameworks como TensorFlow, PyTorch y JAX.
Esta página está dirigida a administradores y operadores de la plataforma, así como a especialistas en datos e IA que ejecutan modelos de aprendizaje automático (ML) con características como la gran escala, la larga duración o el predominio de los cálculos matriciales. Para obtener más información sobre los roles habituales y las tareas de ejemplo a las que hacemos referencia en el contenido de Google Cloud, consulta Roles y tareas habituales de los usuarios de GKE.
Antes de leer esta página, asegúrate de que sabes cómo funcionan los aceleradores de aprendizaje automático. Para obtener más información, consulta el artículo Introducción a Cloud TPU.
Ventajas de usar TPUs en GKE
GKE ofrece compatibilidad total con la gestión del ciclo de vida de los nodos y los grupos de nodos de TPU, lo que incluye la creación, la configuración y la eliminación de máquinas virtuales de TPU. GKE también admite máquinas virtuales de Spot y el uso de TPUs de Cloud reservadas. Para obtener más información, consulta las opciones de consumo de TPU de Cloud.
Entre las ventajas de usar TPUs en GKE se incluyen las siguientes:
- Entorno operativo coherente: puedes usar una sola plataforma para todas las cargas de trabajo de aprendizaje automático y de otro tipo.
- Actualizaciones automáticas: GKE automatiza las actualizaciones de versiones, lo que reduce la sobrecarga operativa.
- Balanceo de carga: GKE distribuye la carga, lo que reduce la latencia y mejora la fiabilidad.
- Escalado adaptable: GKE escala automáticamente los recursos de TPU para satisfacer las necesidades de tus cargas de trabajo.
- Gestión de recursos: con Kueue, un sistema de colas de trabajos nativo de Kubernetes, puedes gestionar recursos en varios arrendatarios de tu organización mediante colas, apropiación, priorización y uso compartido equitativo.
- Opciones de entorno aislado: GKE Sandbox te ayuda a proteger tus cargas de trabajo con gVisor. Para obtener más información, consulta GKE Sandbox.
Ventajas de usar TPU Trillium
Trillium es la TPU de sexta generación de Google. Trillium tiene las siguientes ventajas:
- Trillium aumenta el rendimiento computacional por chip en comparación con la versión 5e de TPU.
- Trillium aumenta la capacidad y el ancho de banda de la memoria de alto ancho de banda (HBM), así como el ancho de banda de la interconexión entre chips (ICI) con respecto a la TPU v5e.
- Trillium está equipada con SparseCore de tercera generación, un acelerador especializado para procesar inserciones ultragrandes habituales en cargas de trabajo de ranking y recomendaciones avanzadas.
- Trillium es más de un 67% más eficiente que la versión 5e de TPU.
- Trillium puede escalar hasta 256 TPUs en una sola porción de TPU de gran ancho de banda y baja latencia.
- Trillium admite la programación de la recogida. La programación de colecciones te permite declarar un grupo de TPUs (grupos de nodos de slices de TPU de un solo host y de varios hosts) para asegurar una alta disponibilidad para las demandas de tus cargas de trabajo de inferencia.
En todas las superficies técnicas, como las APIs y los registros, y en partes específicas de la documentación de GKE, usamos v6e o TPU Trillium (v6e) para referirnos a las TPUs Trillium. Para obtener más información sobre las ventajas de Trillium, consulta la entrada de blog del anuncio de Trillium. Para empezar a configurar las TPUs, consulta el artículo Planificar TPUs en GKE.
Terminología relacionada con las TPUs en GKE
En esta página se usa la siguiente terminología relacionada con las TPUs:
- Tipo de TPU: el tipo de TPU de Cloud, como v5e.
- Nodo de segmento de TPU: un nodo de Kubernetes representado por una sola VM que tiene uno o varios chips de TPU interconectados.
- Grupo de nodos de segmento de TPU: un grupo de nodos de Kubernetes dentro de un clúster que tienen la misma configuración de TPU.
- Topología de la TPU: número y disposición física de los chips de TPU en una porción de TPU.
- Atómico: GKE trata todos los nodos interconectados como una sola unidad. Durante las operaciones de escalado, GKE escala todo el conjunto de nodos a 0 y crea nodos nuevos. Si una máquina del grupo falla o finaliza, GKE vuelve a crear todo el conjunto de nodos como una unidad nueva.
- Inmutables: no puedes añadir manualmente nodos nuevos al conjunto de nodos interconectados. Sin embargo, puedes crear un nuevo pool de nodos que tenga la topología de TPU que quieras y programar cargas de trabajo en él.
Tipos de grupos de nodos de slices de TPU
GKE admite dos tipos de grupos de nodos de TPU:
El tipo y la topología de TPU determinan si el nodo de segmento de TPU puede ser de varios hosts o de un solo host. Te recomendamos que hagas lo siguiente:
- En el caso de los modelos a gran escala, usa nodos de segmento de TPU de varios hosts.
- En el caso de los modelos a pequeña escala, usa nodos de segmento de TPU de un solo host.
- Para el entrenamiento o la inferencia a gran escala, usa Pathways. Pathways simplifica los cálculos de aprendizaje automático a gran escala al permitir que un solo cliente JAX coordine las cargas de trabajo en varios sectores de TPU grandes. Para obtener más información, consulta Pathways.
Grupos de nodos de slices de TPU de varios hosts
Un grupo de nodos de segmento de TPU multihost es un grupo de nodos que contiene dos o más VMs de TPU interconectadas. Cada VM tiene un dispositivo TPU conectado. Las TPUs de una porción de TPU multihost están conectadas a través de una interconexión de alta velocidad (ICI). Una vez que se ha creado un grupo de nodos de un segmento de TPU de varios hosts, no se pueden añadir nodos. Por ejemplo, no puedes crear un grupo de nodos v4-32
y, más adelante, añadir un nodo de Kubernetes (VM de TPU) al grupo de nodos. Para añadir un slice de TPU a un clúster de GKE, debes crear un grupo de nodos.
Las VMs de un grupo de nodos de un segmento de TPU multihost se tratan como una sola unidad atómica. Si GKE no puede desplegar un nodo en el segmento, no se desplegará ningún nodo en el nodo del segmento de TPU.
Si es necesario reparar un nodo de una porción de TPU de varios hosts, GKE cierra todas las VMs de la porción de TPU, lo que obliga a expulsar todos los pods de Kubernetes de la carga de trabajo. Una vez que todas las VMs de la porción de TPU estén en funcionamiento, los pods de Kubernetes se podrán programar en las VMs de la nueva porción de TPU.
En el siguiente diagrama se muestra un segmento de TPU v5litepod-16 (v5e) de varios hosts. Esta
porción de TPU tiene cuatro VMs. Cada VM de la porción de TPU tiene cuatro chips de TPU v5e conectados con interconexiones de alta velocidad (ICI), y cada chip de TPU v5e tiene un Tensor Core:
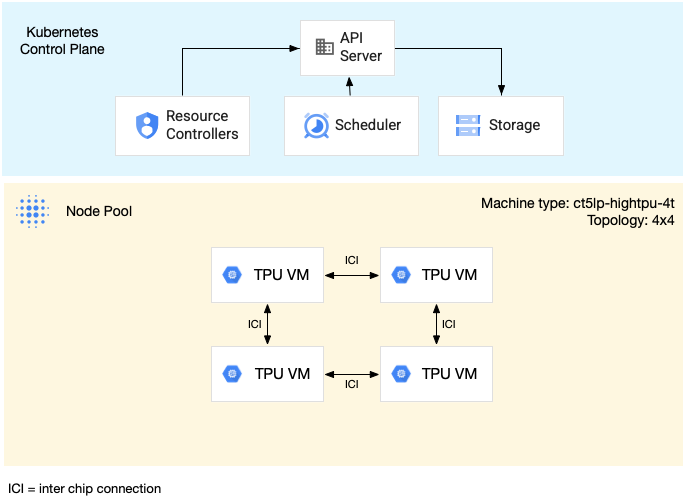
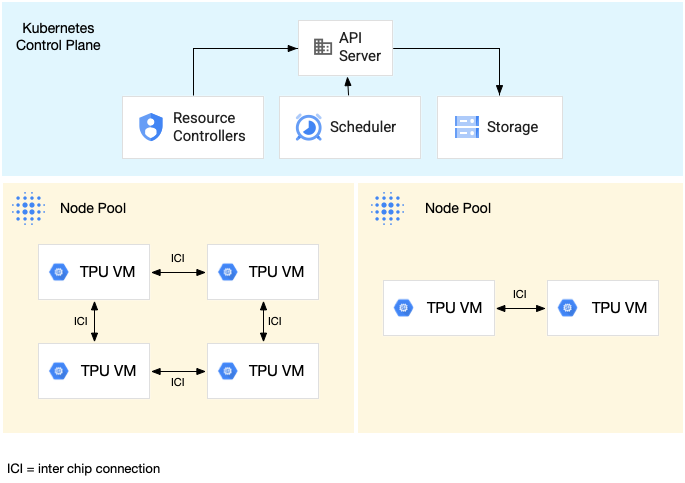
En el siguiente diagrama se muestra un clúster de GKE que contiene un segmento de TPU v5litepod-16 (v5e) (topología: 4x4) y un segmento de TPU v5litepod-8 (v5e) (topología: 2x4):
Grupos de nodos de slices de TPU de un solo host
Un grupo de nodos de slice de un solo host es un grupo de nodos que contiene una o varias máquinas virtuales de TPU independientes. Cada VM tiene un dispositivo TPU conectado. Aunque las VMs de un pool de nodos de una sola porción de host pueden comunicarse a través de la red del centro de datos (DCN), las TPUs conectadas a las VMs no están interconectadas.
En el siguiente diagrama se muestra un ejemplo de un segmento de TPU de un solo host que contiene siete máquinas v4-8:
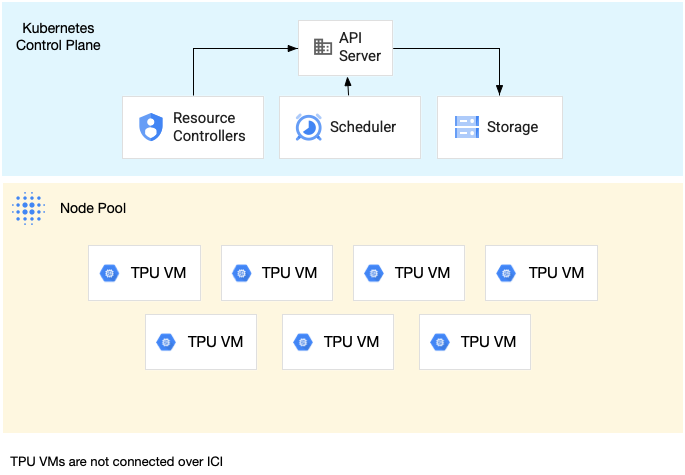
Características de las TPUs en GKE
Las TPU tienen características únicas que requieren una planificación y una configuración especiales.
Consumo de TPUs
Para optimizar el uso de recursos y los costes, al tiempo que se equilibra el rendimiento de las cargas de trabajo, GKE admite las siguientes opciones de consumo de TPU:
- Inicio flexible: para aprovisionar máquinas virtuales de inicio flexible durante un máximo de siete días, GKE asigna automáticamente el hardware de la mejor forma posible en función de la disponibilidad. Para obtener más información, consulta Información sobre el aprovisionamiento de GPUs y TPUs con el modo de aprovisionamiento de inicio flexible.
- Máquinas virtuales de acceso puntual: para aprovisionar máquinas virtuales de acceso puntual, puedes obtener descuentos significativos, pero estas máquinas se pueden interrumpir en cualquier momento con un aviso de 30 segundos. Para obtener más información, consulta Máquinas virtuales de acceso puntual.
- Reserva futura de hasta 90 días (en modo de calendario): para aprovisionar recursos de TPU durante un periodo de hasta 90 días. Para obtener más información, consulta Solicitar TPUs con reserva futura en modo de calendario.
- Reservas de TPU: para solicitar una reserva futura de un año o más.
Para elegir la opción de consumo que se adapte a los requisitos de tu carga de trabajo, consulta Acerca de las opciones de consumo de aceleradores para cargas de trabajo de IA y aprendizaje automático en GKE.
Antes de usar las TPUs en GKE, elige la opción de consumo que mejor se adapte a los requisitos de tu carga de trabajo.
Topología
La topología define la disposición física de las TPUs en un segmento de TPU. GKE aprovisiona un segmento de TPU en topologías bidimensionales o tridimensionales, según la versión de la TPU. Para especificar una topología, indica el número de chips de TPU en cada dimensión de la siguiente manera:
En el caso de las versiones 4 y 5p de TPU programadas en grupos de nodos de segmentos de TPU multihost, la topología se define en tuplas de 3 elementos ({A}x{B}x{C}), como 4x4x4. El producto de
{A}x{B}x{C} define el número de chips de TPU del pool de nodos. Por ejemplo, puedes definir topologías pequeñas que tengan menos de 64 chips de TPU con formas de topología como 2x2x2, 2x2x4 o 2x4x4. Si usas topologías más grandes que tengan más de 64 chips de TPU, los valores que asignes a {A}, {B} y {C} deben cumplir las siguientes condiciones:
- {A}, {B} y {C} deben ser múltiplos de cuatro.
- La topología más grande admitida en la versión 4 es
12x16x16y en la versión 5p es16x16x24. - Los valores asignados deben seguir el patrón A ≤ B ≤ C. Por ejemplo,
4x4x8o8x8x8.
Tipo de máquina
Los tipos de máquina que admiten recursos de TPU siguen una convención de nomenclatura que incluye la versión de TPU y el número de chips de TPU por segmento de nodo, como ct<version>-hightpu-<node-chip-count>t. Por ejemplo, el tipo de máquina ct5lp-hightpu-1t admite la versión 5e de TPU y contiene un solo chip de TPU.
Modo con privilegios
Si usas versiones de GKE anteriores a la 1.28, debes configurar tus contenedores con funciones especiales para acceder a las TPUs. En los clústeres en modo Estándar, puedes usar el modo Privilegiado para conceder este acceso. El modo con privilegios
anula muchos de los otros ajustes de seguridad de la securityContext. Para obtener más información, consulta Ejecutar contenedores sin modo privilegiado.
Las versiones 1.28 y posteriores no requieren el modo con privilegios ni funciones especiales.
Cómo funcionan las TPUs en GKE
La gestión y la priorización de recursos de Kubernetes tratan las máquinas virtuales en TPUs de la misma forma que otros tipos de máquinas virtuales. Para solicitar chips de TPU, usa el nombre del recurso google.com/tpu:
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
Cuando uses TPUs en GKE, ten en cuenta las siguientes características de las TPU:
- Una VM puede acceder a un máximo de 8 chips de TPU.
- Una porción de TPU contiene un número fijo de chips de TPU, que depende del tipo de máquina de TPU que elijas.
- El número de
google.com/tpusolicitados debe ser igual al número total de chips de TPU disponibles en el nodo de la porción de TPU. Cualquier contenedor de un pod de GKE que solicite TPUs debe consumir todos los chips de TPU del nodo. De lo contrario, la implementación fallará porque GKE no puede consumir parcialmente los recursos de TPU. Considera las siguientes situaciones:- El tipo de máquina
ct5lp-hightpu-4tcon una topología2x4contiene dos nodos de segmento de TPU con cuatro chips de TPU cada uno, lo que hace un total de ocho chips de TPU. Con este tipo de máquina, puedes hacer lo siguiente: - No se puede desplegar un pod de GKE que requiera ocho chips de TPU en los nodos de este grupo de nodos.
- Puede desplegar dos pods que requieran cuatro chips de TPU cada uno, y cada pod en uno de los dos nodos de este grupo de nodos.
- La versión 5e de TPU con topología 4x4 tiene 16 chips de TPU en cuatro nodos. La carga de trabajo de Autopilot de GKE que seleccione esta configuración debe solicitar cuatro chips de TPU en cada réplica, de una a cuatro réplicas.
- El tipo de máquina
- En los clústeres estándar, se pueden programar varios pods de Kubernetes en una máquina virtual, pero solo un contenedor de cada pod puede acceder a los chips de TPU.
- Para crear pods kube-system, como kube-dns, cada clúster estándar debe tener al menos un grupo de nodos de segmento que no sea de TPU.
- De forma predeterminada, los nodos de las slices de TPU tienen el
google.com/tputaint que impide que las cargas de trabajo que no son de TPU se programen en los nodos de las slices de TPU. Las cargas de trabajo que no usan TPUs se ejecutan en nodos que no son de TPU, lo que libera recursos de computación en los nodos de los sectores de TPU para el código que usa TPUs. Ten en cuenta que la marca no garantiza que los recursos de TPU se utilicen por completo. - GKE recoge los registros emitidos por los contenedores que se ejecutan en los nodos de las slices de TPU. Para obtener más información, consulta Registro.
- Las métricas de utilización de TPU, como el rendimiento del tiempo de ejecución, están disponibles en Cloud Monitoring. Para obtener más información, consulta Observabilidad y métricas.
- Puedes usar GKE Sandbox para crear un entorno aislado para tus cargas de trabajo de TPU. GKE Sandbox funciona con los modelos de TPU v4 y versiones posteriores. Para obtener más información, consulta GKE Sandbox.
Cómo funciona la programación de colecciones
En TPU Trillium, puedes usar la programación de colecciones para agrupar nodos de slices de TPU. Al agrupar estos nodos de segmento de TPU, es más fácil ajustar el número de réplicas para satisfacer la demanda de la carga de trabajo. Google Cloud controla las actualizaciones de software para asegurarse de que siempre haya suficientes segmentos disponibles en la colección para servir el tráfico.
TPU Trillium admite la programación de recolecciones para grupos de nodos de un solo host y de varios hosts que ejecutan cargas de trabajo de inferencia. A continuación, se describe cómo se comporta la programación de la recogida en función del tipo de segmento de TPU que utilices:
- Slice de TPU de varios hosts: GKE agrupa los slices de TPU de varios hosts para formar una colección. Cada grupo de nodos de GKE es una réplica de esta colección. Para definir una colección, crea un segmento de TPU multihost y asigna un nombre único a la colección. Para añadir más slices de TPU a la colección, crea otro grupo de nodos de slice de TPU multihost con el mismo nombre de colección y tipo de carga de trabajo.
- Slice de TPU de un solo host: GKE considera todo el grupo de nodos del slice de TPU de un solo host como una colección. Para añadir más porciones de TPU a la colección, puedes cambiar el tamaño del grupo de nodos de la porción de TPU de un solo host.
La programación de colecciones tiene las siguientes limitaciones:
- Solo puedes programar colecciones para TPU Trillium.
- Solo puedes definir colecciones durante la creación del grupo de nodos.
- No se admiten las VMs de Spot.
- Las colecciones que contengan grupos de nodos de slices de TPU multihost deben usar el mismo tipo de máquina, topología y versión para todos los grupos de nodos de la colección.
Puedes configurar la programación de la recogida en los siguientes casos:
- Al crear un grupo de nodos de segmento de TPU en GKE Standard
- Al desplegar cargas de trabajo en Autopilot de GKE
- Al crear un clúster que habilita el aprovisionamiento automático de nodos
Siguientes pasos
Para obtener información sobre cómo configurar las TPU de Cloud en GKE, consulta las siguientes páginas:
- Planifica las TPUs en GKE para empezar a configurarlas.
- Desplegar cargas de trabajo de TPUs en Autopilot de GKE
- Desplegar cargas de trabajo de TPU en GKE Standard
- Consulta las prácticas recomendadas para usar las TPU de Cloud en tus tareas de aprendizaje automático.
- Vídeo: Crea aprendizaje automático a gran escala en TPU de Cloud con GKE
- Servir modelos de lenguaje extensos con KubeRay en TPUs
- Información sobre el aislamiento de cargas de trabajo de GPU con GKE Sandbox