Das Dataproc Ranger Cloud Storage-Plug-in, das mit Dataproc-Image-Versionen 1.5 und 2.0 verfügbar ist, aktiviert einen Autorisierungsdienst auf jeder Dataproc-Cluster-VM. Der Autorisierungsdienst wertet Anfragen vom Cloud Storage-Connector anhand von Ranger-Richtlinien aus und gibt, falls die Anfrage zulässig ist, ein Zugriffstoken für das VM-Dienstkonto des Clusters zurück.
Das Ranger Cloud Storage-Plug-in basiert auf Kerberos für die Authentifizierung und lässt sich in die Cloud Storage-Connectorunterstützung für Delegierungstokens einbinden. Delegierungstokens werden in einer MySQL-Datenbank auf dem Masterknoten des Clusters gespeichert. Das Root-Passwort für die Datenbank wird über Clustereigenschaften angegeben, wenn Sie den Dataproc-Cluster erstellen.
Hinweise
Weisen Sie dem Dataproc-VM-Dienstkonto in Ihrem Projekt die Rolle Ersteller von Dienstkonto-Tokens und die Rolle IAM-Rollenadministrator zu.
Ranger Cloud Storage-Plug-in installieren
Führen Sie die folgenden Befehle in einem lokalen Terminalfenster oder in Cloud Shell aus, um das Ranger Cloud Storage-Plug-in zu installieren, wenn Sie einen Dataproc-Cluster erstellen.
Umgebungsvariablen festlegen
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
Hinweise:
- CLUSTER_NAME: Der Name des neuen Clusters.
- REGION: Die Region, in der der Cluster erstellt wird, z. B.
us-west1. - KERBEROS_KMS_KEY_URI und KERBEROS_PASSWORD_URI: Weitere Informationen finden Sie unter Kerberos-Root-Hauptkonto-Passwort einrichten.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI und RANGER_ADMIN_PASSWORD_GCS_URI: Weitere Informationen finden Sie unter Ranger-Administratorpasswort einrichten.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI und RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: Richten Sie ein MySQL-Passwort nach demselben Verfahren ein, das Sie zum Einrichten eines Ranger-Administratorpassworts verwendet haben.
Dataproc-Cluster erstellen
Führen Sie den folgenden Befehl aus, um einen Dataproc-Cluster zu erstellen und das Ranger Cloud Storage-Plug-in auf dem Cluster zu installieren.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
Hinweise:
- Image-Version 1.5:Wenn Sie einen Cluster mit der Image-Version 1.5 erstellen (siehe Versionen auswählen), fügen Sie das Flag
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherhinzu, um die erforderliche Connector-Version zu installieren.
Installation des Ranger Cloud Storage-Plug-ins prüfen
Nachdem der Cluster erstellt wurde, wird in der Ranger-Admin-Weboberfläche ein Dienst vom Typ GCS mit dem Namen gcs-dataproc angezeigt.
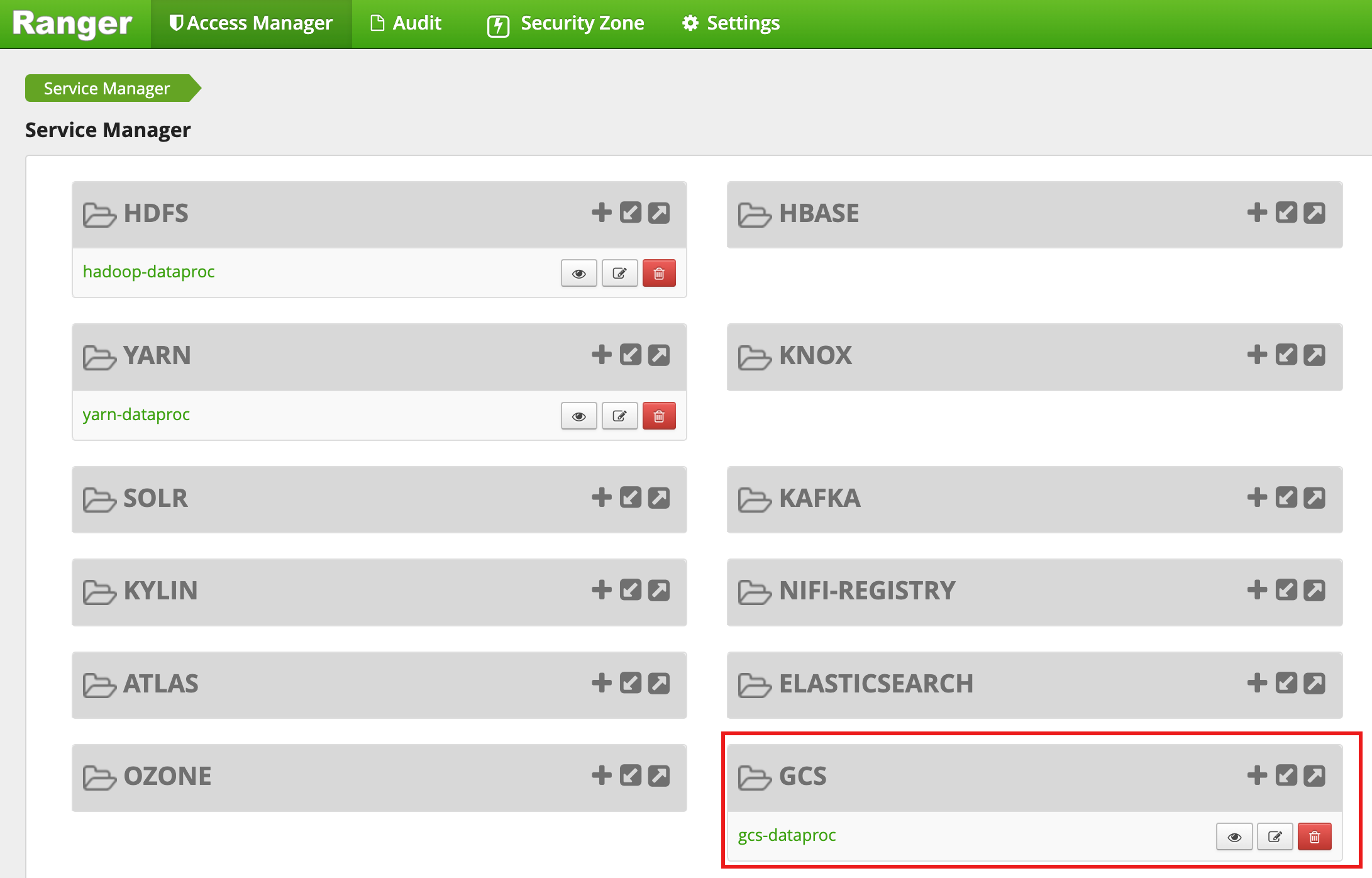
Standardrichtlinien für das Ranger Cloud Storage-Plug-in
Für den Standarddienst gcs-dataproc gelten die folgenden Richtlinien:
Richtlinien zum Lesen und Schreiben von Daten in den Staging- und temporären Buckets des Dataproc-Clusters
Eine
all - bucket, object-path-Richtlinie, die allen Nutzern den Zugriff auf Metadaten für alle Objekte ermöglicht. Dieser Zugriff ist erforderlich, damit der Cloud Storage-Connector HCFS-Vorgänge (Hadoop Compatible Filesystem) ausführen kann.
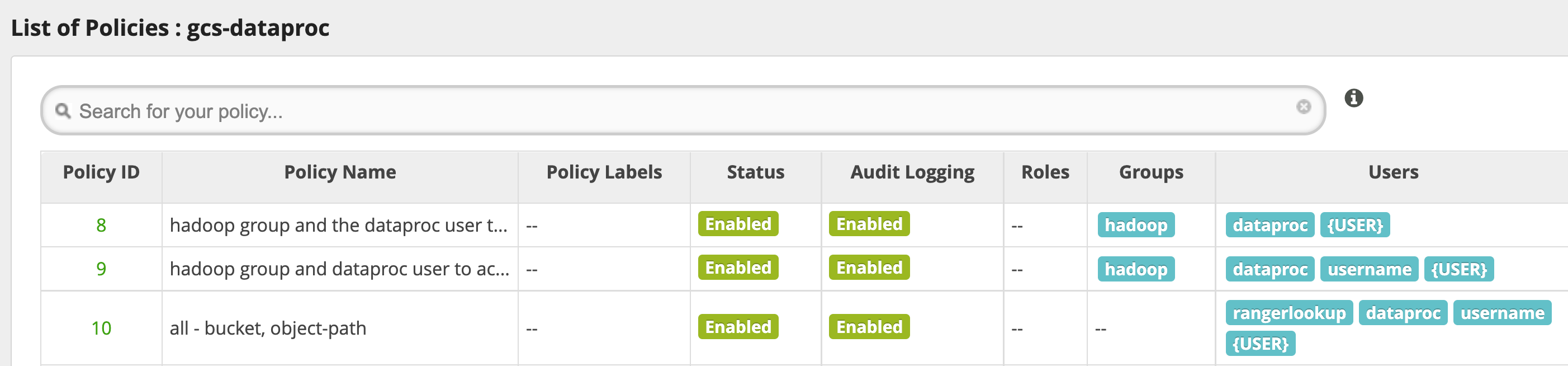
Tipps zur Nutzung
App-Zugriff auf Bucket-Ordner
Für Apps, die Zwischendateien in einem Cloud Storage-Bucket erstellen, können Sie die Berechtigungen Modify Objects, List Objects und Delete Objects für den Cloud Storage-Bucket-Pfad gewähren und dann den Modus recursive auswählen, um die Berechtigungen auf Unterpfade des angegebenen Pfads auszuweiten.
Schutzmaßnahmen
So verhindern Sie eine Umgehung des Plug-ins:
Gewähren Sie dem VM-Dienstkonto Zugriff auf die Ressourcen in Ihren Cloud Storage-Buckets, damit es mit eingeschränkten Zugriffstokens Zugriff auf diese Ressourcen gewähren kann (siehe IAM-Berechtigungen für Cloud Storage). Entfernen Sie außerdem den Zugriff von Nutzern auf Bucket-Ressourcen, um direkten Bucket-Zugriff durch Nutzer zu vermeiden.
Deaktivieren Sie
sudound andere Möglichkeiten für den Root-Zugriff auf Cluster-VMs, einschließlich der Aktualisierung der Dateisudoer, um Identitätsdiebstahl oder Änderungen an den Authentifizierungs- und Autorisierungseinstellungen zu verhindern. Weitere Informationen finden Sie in der Linux-Anleitung zum Hinzufügen/Entfernen vonsudo-Nutzerberechtigungen.Verwenden Sie
iptable, um direkte Zugriffsanfragen auf Cloud Storage von Cluster-VMs zu blockieren. Sie können beispielsweise den Zugriff auf den VM-Metadatenserver blockieren, um den Zugriff auf die Anmeldedaten oder das Zugriffstoken des VM-Dienstkontos zu verhindern, die zum Authentifizieren und Autorisieren des Zugriffs auf Cloud Storage verwendet werden (sieheblock_vm_metadata_server.sh, ein Initialisierungsskript, dasiptable-Regeln verwendet, um den Zugriff auf den VM-Metadatenserver zu blockieren).
Spark-, Hive-on-MapReduce- und Hive-on-Tez-Jobs
Um sensible Details zur Nutzerauthentifizierung zu schützen und die Last auf dem Key Distribution Center (KDC) zu reduzieren, verteilt der Spark-Treiber keine Kerberos-Anmeldedaten an Executors. Stattdessen ruft der Spark-Treiber ein Delegierungstoken vom Ranger Cloud Storage-Plug-in ab und verteilt es dann an die Executors. Executors verwenden das Delegierungstoken, um sich beim Ranger Cloud Storage-Plug-in zu authentifizieren. Sie tauschen es gegen ein Google-Zugriffstoken ein, das den Zugriff auf Cloud Storage ermöglicht.
Für Hive-on-MapReduce- und Hive-on-Tez-Jobs werden ebenfalls Tokens für den Zugriff auf Cloud Storage verwendet. Verwenden Sie die folgenden Properties, um Tokens für den Zugriff auf angegebene Cloud Storage-Buckets abzurufen, wenn Sie die folgenden Jobtypen einreichen:
Spark-Jobs:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Hive-on-MapReduce-Jobs:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Hive-on-Tez-Jobs:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Spark-Job-Szenario
Ein Spark-Wordcount-Job schlägt fehl, wenn er über ein Terminalfenster auf einer Dataproc-Cluster-VM ausgeführt wird, auf der das Ranger Cloud Storage-Plug-in installiert ist.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
Hinweise:
- FILE_BUCKET: Cloud Storage-Bucket für den Spark-Zugriff.
Fehlerausgabe:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
Hinweise:
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}ist in einer Kerberos-fähigen Umgebung erforderlich.
Fehlerausgabe:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
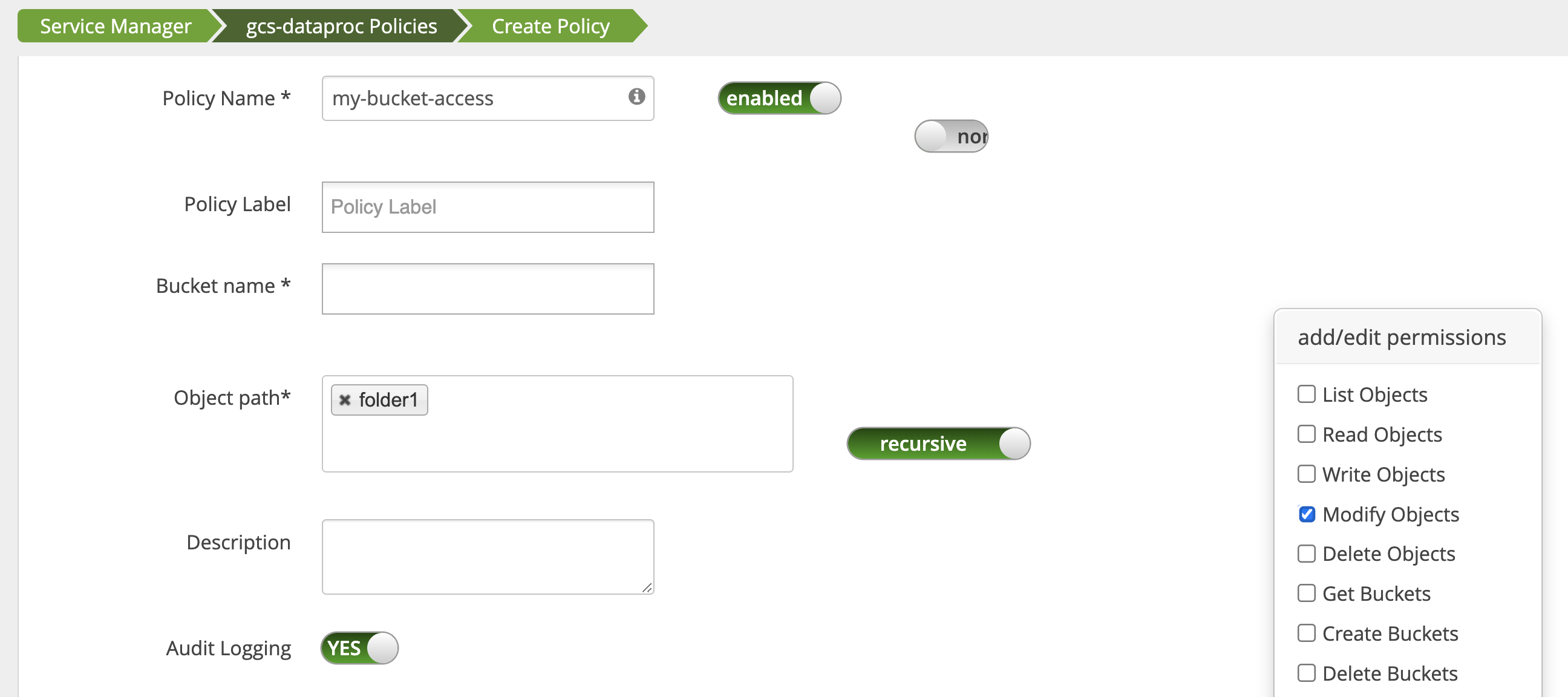
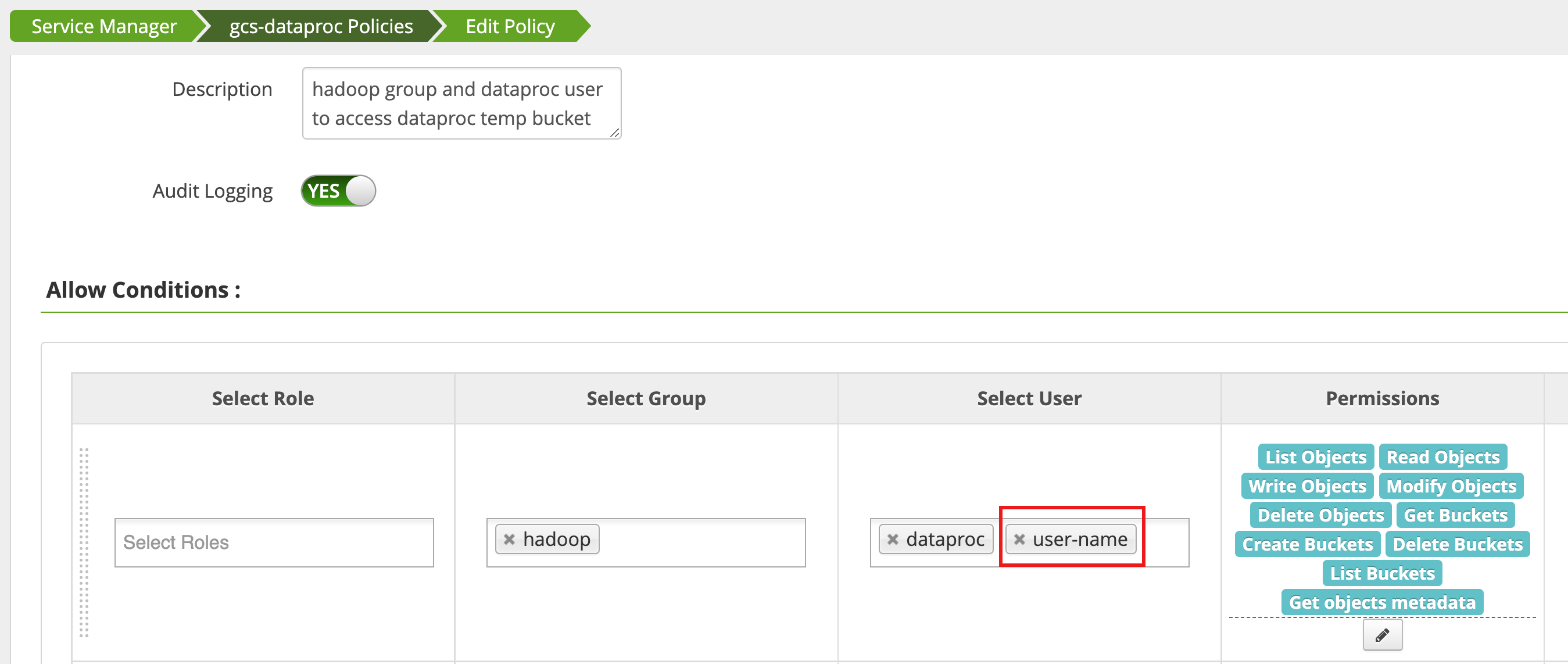
Eine Richtlinie wird über den Access Manager in der Ranger-Administrator-Weboberfläche bearbeitet, um username der Liste der Nutzer hinzuzufügen, die List Objects- und andere temp-Bucket-Berechtigungen haben.
Beim Ausführen des Jobs wird ein neuer Fehler generiert.
Fehlerausgabe:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
Es wird eine Richtlinie hinzugefügt, um dem Nutzer Lesezugriff auf den wordcount.textCloud Storage-Pfad zu gewähren.
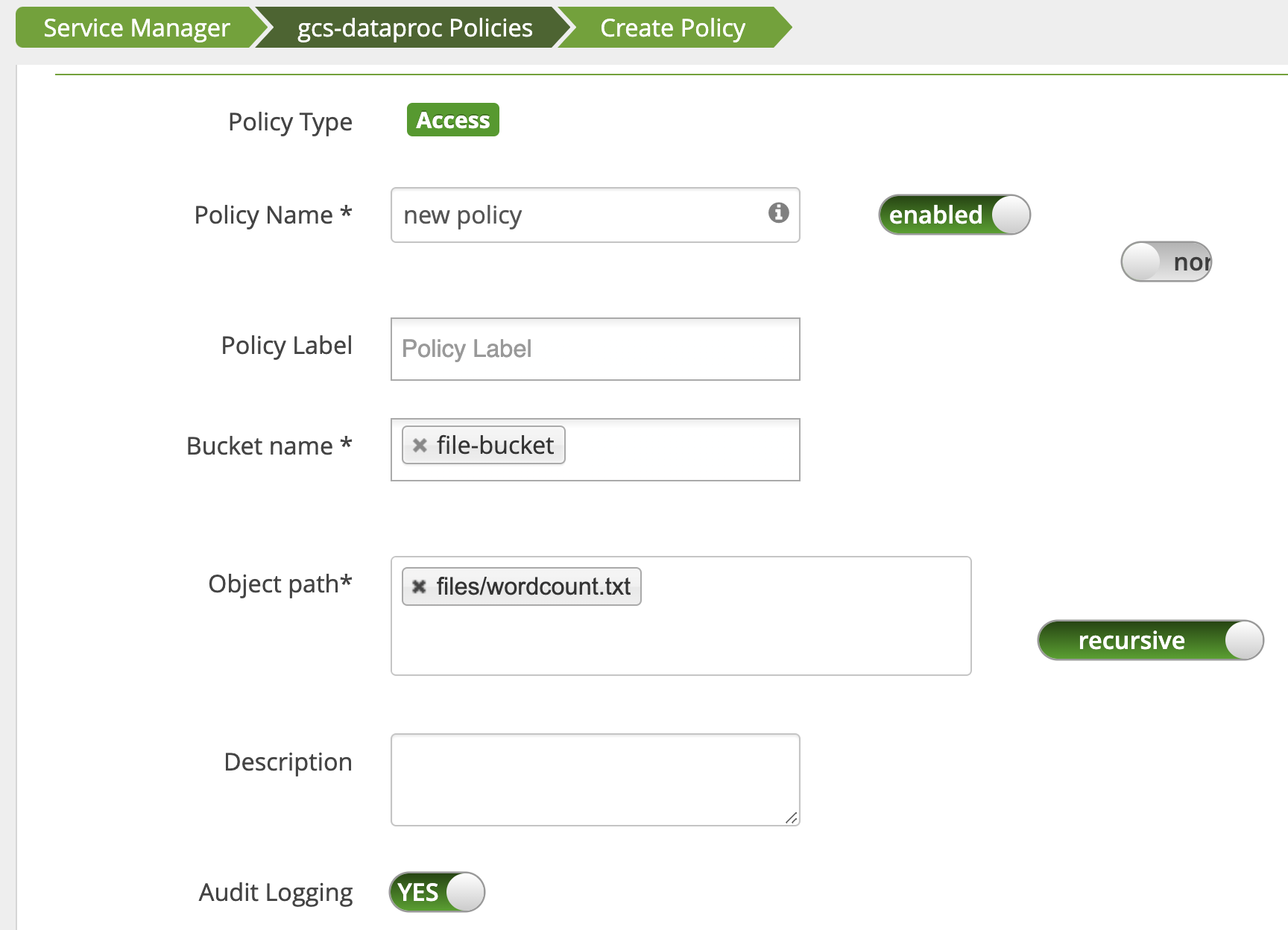
Der Job wird ausgeführt und abgeschlossen.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped