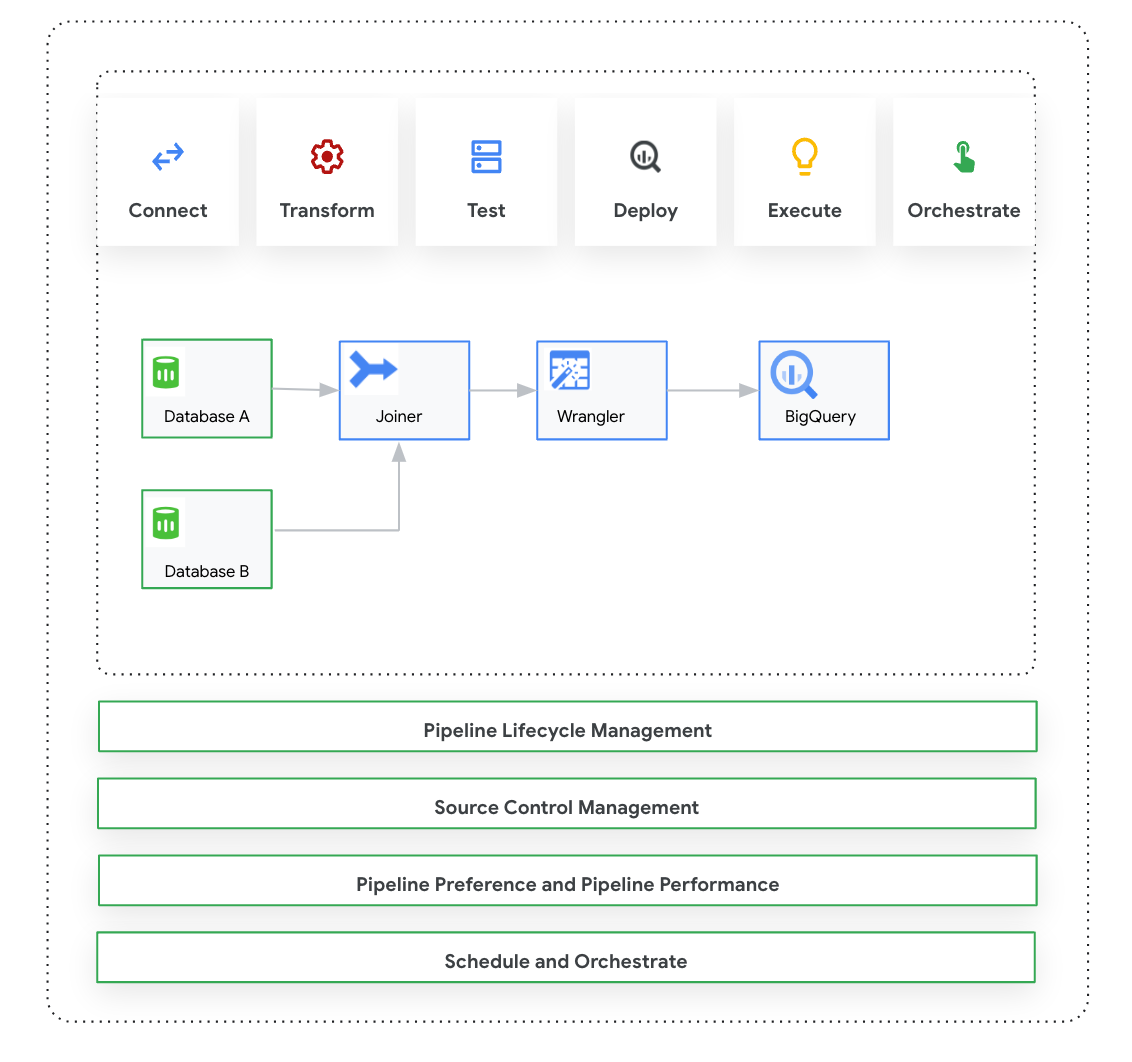
このページでは、Cloud Data Fusion: Studio について説明します。これは、事前構築されたプラグインのライブラリからデータ パイプラインを構築するための視覚的なクリック&ドラッグ インターフェースであり、パイプラインの構成、実行、管理を行うインターフェースです。Studio でパイプラインを構築するプロセスは通常次のとおりです。
- オンプレミスまたはクラウドのデータソースに接続します。
- データを準備して変換します。
- 宛先に接続します。
- パイプラインをテストします。
- パイプラインを実行します。
- パイプラインをスケジュール設定しトリガーします。
パイプラインを設計して実行したら、Cloud Data Fusion の [Pipeline Studio] ページでパイプラインを管理できます。
- 設定とランタイム引数でパイプラインをパラメータ化し、パイプラインを再利用します。
- コンピューティング プロファイルをカスタマイズし、リソースを管理し、パイプラインのパフォーマンスを微調整して、パイプラインの実行を管理します。
- パイプラインを編集して、パイプラインのライフサイクルを管理します。
- Git 統合を使用してパイプラインのソース コントロールを管理します。
始める前に
- Cloud Data Fusion API を有効にします。
- Cloud Data Fusion インスタンスを作成する。
- Cloud Data Fusion のアクセス制御について理解します。
- Cloud Data Fusion の主なコンセプトと用語を理解します。
Cloud Data Fusion: Studio の概要
Studio には次のコンポーネントが含まれています。
管理
Cloud Data Fusion では、各インスタンスに複数の 名前空間を設定できます。Studio 内で、管理者はすべての名前空間を集中的に管理することも、名前空間ごとに個別に管理することもできます。
Studio では、次の管理者コントロールが提供されます。
- システム管理
- Studio の [システム管理] モジュールを使用すると、新しい名前空間を作成し、そのインスタンス内の各名前空間に適用される中央のコンピューティング プロファイル構成をシステム レベルで定義できます。詳しくは、Studio の管理を管理するをご覧ください。
- 名前空間の管理
- Studio の [名前空間管理] モジュールを使用すると、特定の名前空間の構成を管理できます。名前空間ごとに、コンピューティング プロファイル、ランタイム設定、ドライバ、サービス アカウント、git 構成を定義できます。詳細については、Studio の管理を管理するをご覧ください。
Pipeline Design Studio
パイプラインの設計と実行は、Cloud Data Fusion ウェブ インターフェースの Pipeline Design Studio で行います。データ パイプラインの設計と実行には、次の手順が含まれます。
- ソースに接続する: Cloud Data Fusion では、オンプレミス データソースとクラウド データソースに接続できます。Studio インターフェースには、Studio にプリインストールされているデフォルトのシステム プラグインがあります。追加のプラグインは、Hub と呼ばれるプラグイン リポジトリからダウンロードできます。詳細については、プラグインの概要をご覧ください。
- データ準備: Cloud Data Fusion では、強力なデータ準備プラグインである Wrangler を使用してデータを準備できます。Wrangler を使用すると、Studio でデータセット全体に対してロジックを実行する前に、データの小さなサンプルを 1 か所で表示、探索、変換できます。これにより、変換をすばやく適用して、データセット全体に与える影響を把握できます。複数の変換を作成してレシピに追加できます。詳細については、Wrangler の概要をご覧ください。
- 変換: 変換プラグインは、データがソースから読み込まれた後にデータを変更します。たとえば、レコードのクローンを作成したり、ファイル形式を JSON に変更したり、JavaScript プラグインを使用してカスタム変換を作成したりできます。詳細については、プラグインの概要をご覧ください。
- 宛先に接続する: データを準備して変換を適用したら、データを読み込む宛先に接続できます。Cloud Data Fusion は、複数の宛先への接続をサポートしています。詳細については、プラグインの概要をご覧ください。
- プレビュー: パイプラインを設計したら、パイプラインをデプロイして実行する前に問題をデバッグするために、プレビュー ジョブを実行します。エラーが発生した場合は、ドラフトモードで修正できます。Studio は、ソースデータセットの最初の 100 行を使用してプレビューを生成します。Studio に、プレビュー ジョブのステータスと所要時間が表示されます。ジョブはいつでも停止できます。 プレビュー ジョブの実行中にログイベントをモニタリングすることもできます。詳細については、データをプレビューするをご覧ください。
パイプライン構成を管理する: データをプレビューしたら、パイプラインをデプロイし、次のパイプライン構成を管理できます。
- コンピューティング構成: パイプラインを実行するコンピューティング プロファイルを変更できます。たとえば、デフォルトの Dataproc クラスタではなく、カスタマイズされた Dataproc クラスタに対してパイプラインを実行する場合などです。
- パイプラインの構成: パイプラインごとに、タイミング指標などの計測を有効または無効にできます。デフォルトでは、計測が有効になっています。
- エンジンの構成: Spark がデフォルトの実行エンジンです。Spark のカスタム パラメータを渡すことができます。
- リソース: Spark ドライバとエグゼキュータのメモリと CPU 数を指定できます。ドライバは Spark ジョブをオーケストレートします。エグゼキュータは、Spark でのデータ処理を処理します。
- パイプライン アラート: パイプラインの実行が完了した後にアラートを送信し、後処理タスクを開始するようにパイプラインを構成できます。パイプライン アラートは、パイプラインを設計するときに作成します。パイプラインをデプロイすると、アラートを表示できます。アラート設定を変更するには、パイプラインを編集します。
- 変換のプッシュダウン: パイプラインで BigQuery で特定の変換を実行する場合は、変換のプッシュダウンを有効にできます。
詳細については、パイプラインの構成を管理するをご覧ください。
マクロ、設定、ランタイム パラメータを使用してパイプラインを再利用する: Cloud Data Fusion では、データ パイプラインを再利用できます。再利用可能なデータ パイプラインを使用すると、さまざまなユースケースとデータセットにデータ統合パターンを適用できる単一のパイプラインを作成できます。再利用可能なパイプラインを使用すると、管理性が向上します。これにより、設計時にハードコードするのではなく、実行時にパイプラインの構成のほとんどを設定できます。Pipeline Design Studio では、マクロを使用してプラグイン構成に変数を追加し、ランタイムで変数の置換を指定できます。詳細については、マクロ、設定、ランタイムの引数を管理するをご覧ください。
実行: パイプライン構成を確認したら、パイプラインの実行を開始できます。パイプライン実行の各フェーズにおいて、ステータスがプロビジョニング、開始、実行、成功と変わることが確認できます。
スケジュールとオーケストレーション: バッチデータ パイプラインは、指定したスケジュールと頻度で実行するように設定できます。パイプラインを作成してデプロイしたら、スケジュールを作成できます。Pipeline Design Studio では、バッチデータ パイプラインにトリガーを作成して、1 つ以上のパイプラインの実行が完了したときに実行するようにパイプラインをオーケストレートできます。これらはダウンストリーム パイプラインとアップストリーム パイプラインと呼ばれます。ダウンストリーム パイプラインにトリガーを作成して、1 つ以上のアップストリーム パイプラインの完了に基づいて実行されるようにします。
推奨: Composer を使用して Cloud Data Fusion でパイプラインをオーケストレートすることもできます。詳細については、パイプラインをスケジュール設定するとパイプラインをオーケストレートするをご覧ください。
パイプラインを編集する: Cloud Data Fusion では、デプロイされたパイプラインを編集できます。デプロイされたパイプラインを編集すると、同じ名前の新しいバージョンのパイプラインが作成され、最新バージョンとしてマークされます。これにより、パイプラインを複製して別の名前の新しいパイプラインを作成するのではなく、パイプラインを反復的に開発できます。詳細については、パイプラインを編集するをご覧ください。
ソース コントロール管理: Cloud Data Fusion では、GitHub を使用したパイプラインのソース コントロール管理により、開発環境と本番環境間のパイプラインをより適切に管理できます。
ロギングとモニタリング: パイプラインの指標とログをモニタリングするには、Stackdriver ロギング サービスを有効にして、Cloud Data Fusion パイプラインで Cloud Logging を使用することをおすすめします。
次のステップ
- Studio の管理の管理の詳細を学習する。