Conocer el rendimiento
En esta página se describe el rendimiento aproximado que puede ofrecer Bigtable en condiciones óptimas, los factores que pueden afectar al rendimiento y consejos para probar y solucionar problemas de rendimiento de Bigtable.
Rendimiento para cargas de trabajo habituales
Bigtable ofrece un rendimiento muy predecible que se puede escalar de forma lineal. Si evitas las causas de un rendimiento más lento que se describen en esta página, cada nodo de Bigtable puede proporcionar el siguiente rendimiento aproximado, en función del tipo de almacenamiento que utilice el clúster:
| Tipo de almacenamiento | Lecturas | Escrituras | Análisis | ||
|---|---|---|---|---|---|
| SSD | hasta 17.000 filas por segundo | o | Hasta 14.000 filas por segundo | o | hasta 220 MB/s |
| HDD | Hasta 500 filas por segundo | o | Hasta 10.000 filas por segundo | o | Hasta 180 MB/s |
| Almacenamiento de acceso poco frecuente | hasta 100 filas por segundo | o | Hasta 10.000 filas por segundo | o | Hasta 36 MB/s |
Estas estimaciones parten de la base de que cada fila contiene 1 KB.
En general, el rendimiento de un clúster se escala de forma lineal a medida que se añaden nodos al clúster. Por ejemplo, si crea un clúster SSD con 10 nodos, el clúster puede admitir hasta 140.000 filas por segundo para una carga de trabajo típica de solo lectura o solo escritura.
Planificar la capacidad de Bigtable
Cuando planifiques tus clústeres de Bigtable, decide si quieres optimizar la latencia o el rendimiento. Por ejemplo, en el caso de un trabajo de procesamiento de datos por lotes, puede que te interese más el rendimiento y menos la latencia. Por el contrario, en el caso de un servicio online que atiende solicitudes de usuarios, puede que prefieras priorizar una latencia más baja que el rendimiento. Puedes alcanzar las cifras de la sección Rendimiento de las cargas de trabajo típicas cuando optimices el rendimiento.
Uso de CPU
En casi todos los casos, te recomendamos que utilices el escalado automático, que permite a Bigtable añadir o quitar nodos en función del uso. Para obtener más información, consulta Escalado automático.
Sigue estas directrices al configurar tus objetivos de autoescalado o si eliges la asignación manual de nodos. Estas directrices se aplican independientemente del número de clústeres que tenga tu instancia. En el caso de los clústeres con asignación manual de nodos, debes monitorizar el uso de CPU del clúster para que se mantenga por debajo de estos valores y así conseguir un rendimiento óptimo.
| Objetivo de optimización | Uso máximo de CPU |
|---|---|
| Rendimiento | 90 % |
| Latencia | 60 % |
Para obtener más información sobre la monitorización, consulta Monitorización.
Uso de almacenamiento
El almacenamiento es otro factor que se debe tener en cuenta en la planificación de la capacidad. La capacidad de almacenamiento de un clúster se determina en función del tipo de almacenamiento y del número de nodos del clúster. Cuando aumenta la cantidad de datos almacenados en un clúster, Bigtable optimiza el almacenamiento distribuyendo los datos entre todos los nodos del clúster.
Para determinar el uso del almacenamiento por nodo, divide la utilización del almacenamiento (bytes) del clúster entre el número de nodos del clúster. Por ejemplo, imagina un clúster que tiene tres nodos de HDD y 9 TB de datos. Cada nodo almacena unos 3 TB, lo que supone el 18,75% del límite de almacenamiento en HDD por nodo, que es de 16 TB.
Cuando aumenta la utilización del almacenamiento, las cargas de trabajo pueden experimentar un incremento de la latencia de procesamiento de consultas, aunque el clúster tenga suficientes nodos para satisfacer las necesidades generales de CPU. Esto se debe a que, cuanto mayor sea el almacenamiento por nodo, más trabajo en segundo plano se requerirá, como la indexación. El aumento del trabajo en segundo plano para gestionar más almacenamiento puede provocar una mayor latencia y un menor rendimiento.
Empieza con lo siguiente al configurar los ajustes de autoescalado. Si eliges la asignación manual de nodos, monitoriza el uso del almacenamiento del clúster y añade o quita nodos para mantener lo siguiente.
| Objetivo de optimización | Utilización máxima del almacenamiento |
|---|---|
| Rendimiento | 70 % |
| Latencia | 60 % |
Para obtener más información, consulta Almacenamiento por nodo.
Ejecutar cargas de trabajo en Bigtable
Cuando planifiques la capacidad, ejecuta siempre tus cargas de trabajo en un clúster de Bigtable para determinar la mejor asignación de recursos para tus aplicaciones.
PerfKit Benchmarker de Google usa YCSB para comparar servicios en la nube. Puedes seguir el tutorial de PerfKitBenchmarker para Bigtable para crear pruebas de tus cargas de trabajo. Cuando lo hagas, ajusta los parámetros de los archivos YAML de configuración de las pruebas comparativas para asegurarte de que la prueba comparativa generada refleje las siguientes características de producción:
- El tamaño total de la tabla (proporcional, pero al menos 100 GB).
- Formato de los datos de las filas (tamaño de la clave de fila, número de columnas, tamaños de los datos de las filas, etc.)
- Patrón de acceso a datos (distribución de claves de fila)
- Mezcla de lecturas y escrituras
Consulta más prácticas recomendadas para probar el rendimiento con Bigtable.
Causas de un rendimiento más lento
Los siguientes factores pueden provocar que Bigtable funcione más lento de lo estimado:
- Lees un gran número de claves de fila o intervalos de filas no contiguos en una sola solicitud de lectura. Bigtable analiza la tabla y lee las filas solicitadas de forma secuencial. Esta falta de paralelismo afecta a la latencia general y las lecturas que llegan a un nodo activo pueden aumentar la latencia de cola. Consulta Lecturas y rendimiento para obtener más información.
- El esquema de la tabla no está diseñado correctamente. Para que Bigtable funcione bien, es fundamental diseñar un esquema que permita distribuir las lecturas y las escrituras de forma uniforme en cada tabla. Además, los puntos de acceso de una tabla pueden afectar al rendimiento de otras tablas de la misma instancia. Consulta las prácticas recomendadas para el diseño de esquemas para obtener más información.
- Las filas de tu tabla de Bigtable contienen grandes cantidades de datos. Las estimaciones de rendimiento parten de la base de que cada fila contiene 1 KB de datos. Puedes leer y escribir mayores cantidades de datos por fila, pero si aumentas la cantidad de datos por fila, también se reducirá el número de filas por segundo.
- Las filas de tu tabla de Bigtable contienen un número muy elevado de celdas. Bigtable tarda en procesar cada celda de una fila. Además, cada celda añade una sobrecarga a la cantidad de datos almacenados en la tabla y enviados a través de la red. Por ejemplo, si almacenas 1 KB (1024 bytes) de datos, es mucho más eficiente en cuanto al espacio almacenar esos datos en una sola celda que distribuirlos en 1024 celdas que contengan 1 byte cada una. Si divides los datos en más celdas de las necesarias, es posible que no obtengas el mejor rendimiento posible. Si las filas contienen un gran número de celdas porque las columnas contienen varias versiones de datos con marca de tiempo, considera la posibilidad de conservar solo el valor más reciente. Otra opción para una tabla es enviar una eliminación de todas las versiones anteriores con cada reescritura.
El clúster no tiene suficientes nodos. Los nodos de un clúster proporcionan recursos de computación para que el clúster gestione las lecturas y escrituras entrantes, haga un seguimiento del almacenamiento y realice tareas de mantenimiento, como la compactación. Debes asegurarte de que tu clúster tenga suficientes nodos para cumplir los límites recomendados de computación y almacenamiento. Usa las herramientas de monitorización para comprobar si el clúster está sobrecargado.
- Computación: si la CPU de tu clúster de Bigtable está sobrecargada, añadir más nodos mejora el rendimiento, ya que la carga de trabajo se distribuye entre más nodos.
- Almacenamiento: si el uso del almacenamiento por nodo es superior al recomendado, añade más nodos para mantener una latencia y un rendimiento óptimos, aunque el clúster tenga suficiente CPU para procesar las solicitudes. Esto se debe a que, al aumentar la cantidad de almacenamiento por nodo, también aumenta la cantidad de trabajo de mantenimiento en segundo plano por nodo. Para obtener más información, consulta Ventajas e inconvenientes del uso del almacenamiento y el rendimiento.
El clúster de Bigtable se ha escalado o reducido recientemente. Después de que el autoescalado aumente el número de nodos de un clúster, pueden pasar hasta 20 minutos con carga antes de que el rendimiento mejore significativamente. Bigtable escala los nodos de clúster en función de la carga que experimentan.
Cuando disminuyas el número de nodos de un clúster para reducir la escala, intenta no reducir el tamaño del clúster en más de un 10% en un periodo de 10 minutos para minimizar los picos de latencia.
El clúster de Bigtable usa discos HDD. En la mayoría de los casos, el clúster debe usar discos SSD, que tienen un rendimiento significativamente mejor que los discos HDD. Consulta más información en Elegir entre almacenamiento SSD y HDD.
Hay problemas con la conexión de red. Los problemas de red pueden reducir el rendimiento y provocar que las lecturas y escrituras tarden más de lo habitual. En concreto, puede que tengas problemas si tus clientes no se ejecutan en la misma zona que tu clúster de Bigtable o si se ejecutan fuera de Google Cloud.
Estás usando la replicación, pero tu aplicación usa una biblioteca de cliente obsoleta. Si observas un aumento de la latencia después de habilitar la replicación, asegúrate de que la biblioteca de cliente de Cloud Bigtable que usa tu aplicación esté actualizada. Es posible que las versiones anteriores de las bibliotecas de cliente no estén optimizadas para admitir la replicación. Consulta las bibliotecas de cliente de Cloud Bigtable para encontrar el repositorio de GitHub de tu biblioteca de cliente, donde puedes comprobar la versión y actualizarla si es necesario.
Has habilitado la réplica, pero no has añadido más nodos a tus clústeres. En una instancia que usa la replicación, cada clúster debe gestionar el trabajo de replicación, además de la carga que recibe de las aplicaciones. Los clústeres con pocos recursos pueden provocar un aumento de la latencia. Para comprobarlo, consulta los gráficos de uso de CPU de la instancia en la consola de Google Cloud .
Como las diferentes cargas de trabajo pueden provocar que el rendimiento varíe, realiza pruebas con tus cargas de trabajo para obtener las métricas más precisas.
Arranques en frío y QPS bajo
Los arranques en frío y las consultas por segundo bajas pueden aumentar la latencia. Bigtable funciona mejor con tablas grandes a las que se accede con frecuencia. Por este motivo, si empiezas a enviar solicitudes después de un periodo de inactividad (un inicio en frío), es posible que observes una latencia alta mientras Bigtable restablece las conexiones. La latencia también es mayor cuando el número de consultas por segundo es bajo.
Si tu QPS es bajo o sabes que a veces enviarás solicitudes a una tabla de Bigtable después de un periodo de inactividad, prueba las siguientes estrategias para mantener la conexión activa y evitar una latencia alta.
- Envía una tasa baja de tráfico artificial a la tabla en todo momento.
- Configura el grupo de conexiones para asegurarte de que el QPS constante mantiene el grupo activo.
Durante los periodos de baja QPS, el número de errores que devuelve Bigtable es más relevante que el porcentaje de operaciones que devuelven un error.
Arranque en frío en el momento de la inicialización del cliente. Si usas una versión del cliente de Cloud Bigtable para Java anterior a la 2.18.0, puedes habilitar la actualización de canales. En versiones posteriores, la actualización de canales está habilitada de forma predeterminada. Al actualizar el canal, se hacen dos cosas:
- Cuando el cliente se inicializa, prepara el canal antes de enviar las primeras solicitudes.
- El servidor desconecta las conexiones de larga duración cada hora. El cebado de canales sustituye de forma preventiva los canales que van a caducar.
Sin embargo, esto no mantiene el canal activo cuando hay periodos de inactividad.
Cómo optimiza Bigtable tus datos a lo largo del tiempo
Para almacenar los datos subyacentes de cada una de tus tablas, Bigtable fragmenta los datos en varias tablets, que se pueden mover entre los nodos de tu clúster de Bigtable. Este método de almacenamiento permite que Bigtable use dos estrategias para optimizar los datos a lo largo del tiempo:
- Bigtable almacena aproximadamente la misma cantidad de datos en cada nodo de Bigtable.
- Bigtable distribuye las lecturas y las escrituras por igual entre todos los nodos de Bigtable.
A veces, estas estrategias entran en conflicto. Por ejemplo, si las filas de una tablet se leen con mucha frecuencia, Bigtable puede almacenar esa tablet en su propio nodo, aunque esto provoque que algunos nodos almacenen más datos que otros.
Como parte de este proceso, Bigtable puede dividir una tablet en dos o más tablets más pequeñas para reducir su tamaño o aislar las filas activas dentro de una tablet.
En las siguientes secciones se explica cada una de estas estrategias con más detalle.
Distribuir la cantidad de datos entre los nodos
Cuando escribes datos en una tabla de Bigtable, Bigtable fragmenta los datos de la tabla en tablets. Cada tablet contiene un intervalo contiguo de filas de la tabla.
Si has escrito menos de varios GB de datos en la tabla, Bigtable almacena todas las tablets en un solo nodo de tu clúster:
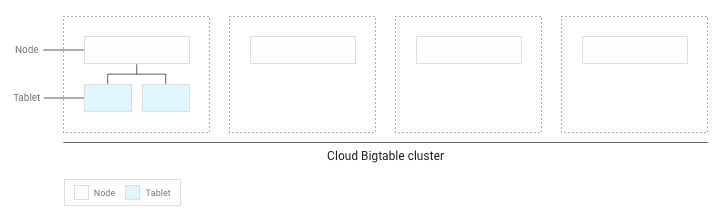
A medida que se acumulan más tablets, Bigtable mueve algunas a otros nodos del clúster para equilibrar la cantidad de datos de forma más uniforme en todo el clúster:
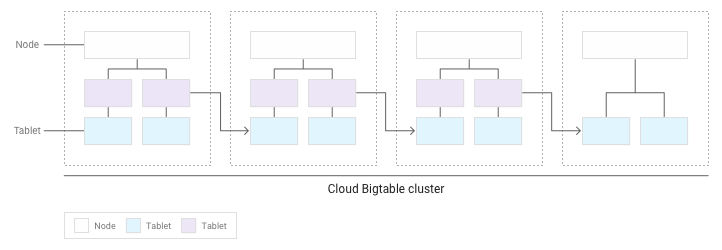
Distribuir las lecturas y escrituras de forma uniforme entre los nodos
Si has diseñado tu esquema correctamente, las lecturas y escrituras deberían distribuirse de forma bastante uniforme en toda la tabla. Sin embargo, hay algunos casos en los que no puedes evitar acceder a determinadas filas con más frecuencia que a otras. Bigtable te ayuda a gestionar estos casos teniendo en cuenta las lecturas y las escrituras al equilibrar las tablets entre los nodos.
Por ejemplo, supongamos que el 25% de las lecturas se dirigen a un número reducido de tablets de un clúster y que las lecturas se distribuyen de forma uniforme entre el resto de las tablets:
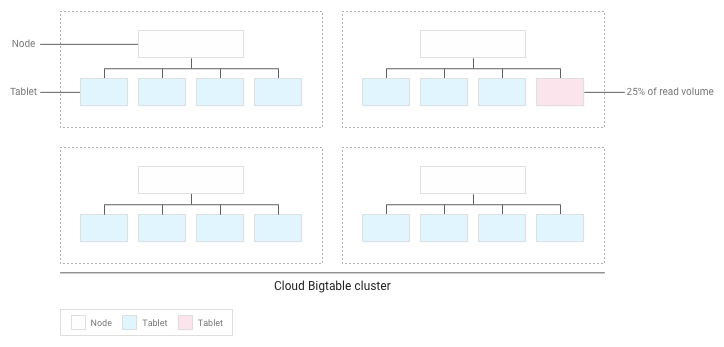
Bigtable redistribuirá los tablets existentes para que las lecturas se distribuyan de la forma más uniforme posible en todo el clúster:
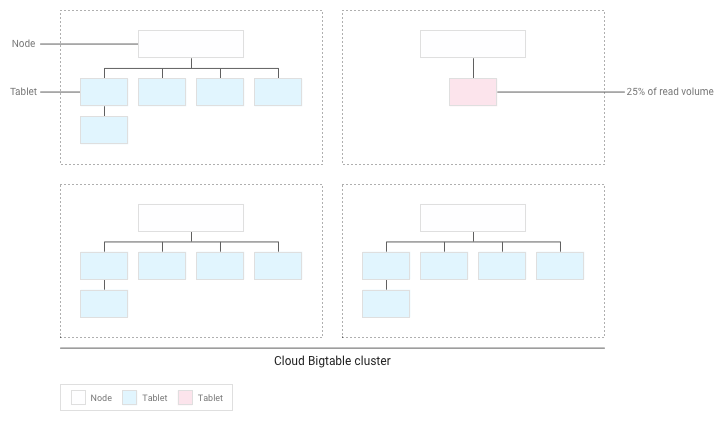
Probar el rendimiento con Bigtable
Si vas a realizar una prueba de rendimiento de una aplicación que depende de Bigtable, sigue estas directrices al planificar y ejecutar la prueba:
- Prueba con suficientes datos.
- Si las tablas de su instancia de producción contienen un total de 100 GB de datos o menos por nodo, haga pruebas con una tabla que contenga la misma cantidad de datos.
- Si las tablas contienen más de 100 GB de datos por nodo, haga pruebas con una tabla que contenga al menos 100 GB de datos por nodo. Por ejemplo, si tu instancia de producción tiene un clúster de cuatro nodos y las tablas de la instancia contienen un total de 1 TB de datos, ejecuta la prueba con una tabla de al menos 400 GB.
- Hacer pruebas con una sola tabla.
- No superes la utilización de almacenamiento recomendada por nodo. Para obtener más información, consulta Uso del almacenamiento por nodo.
- Antes de hacer la prueba, haz una prueba preliminar pesada durante varios minutos. Este paso permite que Bigtable equilibre los datos entre los nodos en función de los patrones de acceso que observe.
- Ejecuta la prueba durante al menos 10 minutos. Este paso permite que Bigtable optimice aún más tus datos y te ayuda a asegurarte de que probarás las lecturas del disco, así como las lecturas en caché de la memoria.
Solucionar problemas de rendimiento
Si crees que Bigtable puede estar creando un cuello de botella en el rendimiento de tu aplicación, asegúrate de comprobar todo lo siguiente:
- Examina los análisis de Key Visualizer de tu tabla. La herramienta Key Visualizer de Bigtable genera nuevos datos de análisis cada 15 minutos, que muestran los patrones de uso de cada tabla de un clúster. Key Visualizer te permite comprobar si tus patrones de uso están provocando resultados no deseados, como puntos de acceso en filas específicas o un uso excesivo de la CPU. Para obtener más información, consulta Usar Key Visualizer.
- Comenta el código que realiza lecturas y escrituras de Bigtable. Si el problema de rendimiento desaparece, es probable que estés usando Bigtable de una forma que no es óptima. Si el problema de rendimiento persiste, probablemente no esté relacionado con Bigtable.
Crea el menor número de clientes posible. Crear un cliente para Bigtable es una operación relativamente costosa. Por lo tanto, debes crear el menor número posible de clientes:
- Si usas la replicación o los perfiles de aplicación para identificar diferentes tipos de tráfico a tu instancia, crea un cliente por cada perfil de aplicación y comparte los clientes en toda tu aplicación.
- Si no usas la replicación ni los perfiles de aplicación, crea un solo cliente y compártelo en toda la aplicación.
Si usas el cliente de HBase para Java, creas un objeto
Connectionen lugar de un cliente, por lo que debes crear el menor número de conexiones posible.Asegúrate de leer y escribir muchas filas diferentes en tu tabla. Bigtable funciona mejor cuando las lecturas y escrituras se distribuyen de forma uniforme por toda la tabla, lo que ayuda a Bigtable a distribuir la carga de trabajo entre todos los nodos del clúster. Si las lecturas y escrituras no se pueden distribuir entre todos los nodos de Bigtable, el rendimiento se verá afectado.
Si observas que solo lees y escribes un número reducido de filas, puede que tengas que rediseñar tu esquema para que las lecturas y escrituras se distribuyan de forma más uniforme.
Verifica que el rendimiento de las lecturas y las escrituras sea aproximadamente el mismo. Si detecta que las lecturas son mucho más rápidas que las escrituras, es posible que esté intentando leer claves de fila que no existen o un intervalo grande de claves de fila que solo contenga un número reducido de filas.
Para hacer una comparación válida entre lecturas y escrituras, procura que al menos el 90% de tus lecturas devuelvan resultados válidos. Además, si lees un intervalo grande de claves de fila, mide el rendimiento en función del número real de filas de ese intervalo, en lugar del número máximo de filas que podrían existir.
Usa el tipo de solicitudes de escritura adecuado para tus datos. Elegir la forma óptima de escribir tus datos te ayuda a mantener un rendimiento alto.
Consulta la latencia de una sola fila. Si observas una latencia inesperada al enviar solicitudes
ReadRows, puedes comprobar la latencia de la primera fila de la solicitud para acotar la causa. De forma predeterminada, la latencia general de una solicitudReadRowsincluye la latencia de cada fila de la solicitud, así como el tiempo de procesamiento entre filas. Si la latencia general es alta, pero la latencia de la primera fila es baja, esto sugiere que la latencia se debe al número de solicitudes o al tiempo de procesamiento, en lugar de a un problema con Bigtable.Si usas la [biblioteca de cliente de Bigtable para Java] [java-client], puedes ver la métrica
read_rows_first_row_latencyen el Google Cloud explorador de métricas de la consola después de habilitar las métricas del lado del cliente.Usa un perfil de aplicación independiente para cada carga de trabajo. Si experimentas problemas de rendimiento después de añadir una nueva carga de trabajo, crea un nuevo perfil de aplicación para la nueva carga de trabajo. Después, puedes monitorizar las métricas de tus perfiles de aplicación por separado para solucionar problemas. Consulta Cómo funcionan los perfiles de aplicaciones para obtener más información sobre por qué es una práctica recomendada usar varios perfiles de aplicaciones.
Habilita las métricas del lado del cliente. Puedes configurar métricas del lado del cliente para optimizar el rendimiento y solucionar problemas. Por ejemplo, como Bigtable funciona mejor con una distribución uniforme y un número elevado de consultas por segundo, el aumento de la latencia P100 (máxima) en un pequeño porcentaje de solicitudes no indica necesariamente un problema de rendimiento mayor con Bigtable. Las métricas del lado del cliente pueden proporcionarle información valiosa sobre qué parte del ciclo de vida de la solicitud puede estar causando latencia.
Asegúrate de que tu aplicación consuma las solicitudes de lectura antes de que se agote el tiempo de espera. Si tu aplicación procesa datos durante una transmisión de lectura, corres el riesgo de que la solicitud agote el tiempo de espera antes de que hayas recibido todas las respuestas de la llamada. Esto provoca un mensaje
ABORTED. Si ves este error, reduce la cantidad de procesamiento durante el flujo de lectura.
Siguientes pasos
- Consulta cómo diseñar un esquema de Bigtable.
- Consulta cómo monitorizar el rendimiento de Bigtable.
- Consulta cómo solucionar problemas con Key Visualizer.
- Consulta cómo solucionar problemas de latencia.
- Consulta el código de muestra para añadir nodos a un clúster de Bigtable mediante programación.